easy_RE
先exeinfo
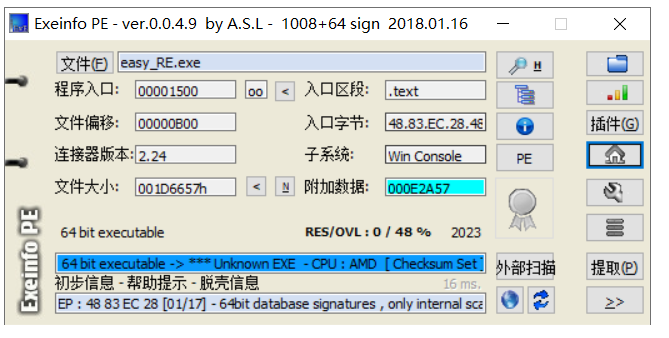
没有壳,直接上ida
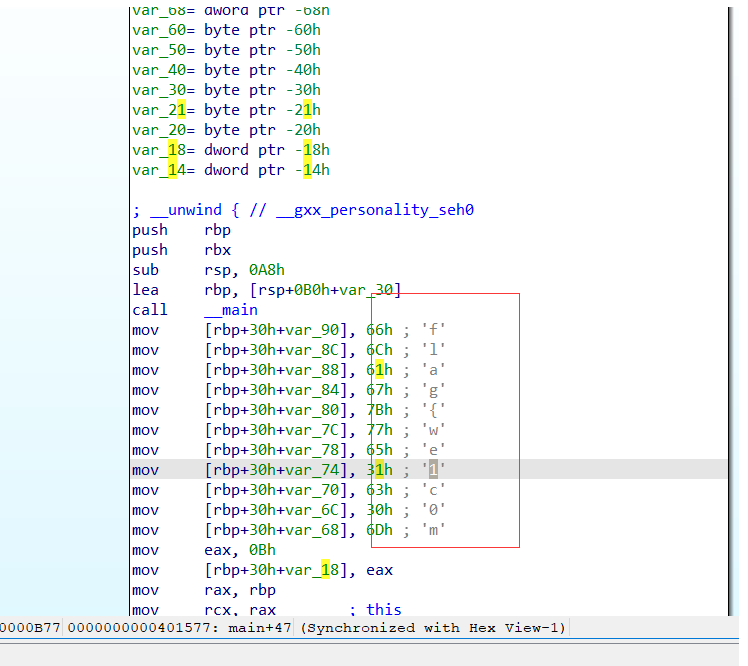
看到有关键信息,但没有显示完,按f5反编译一下
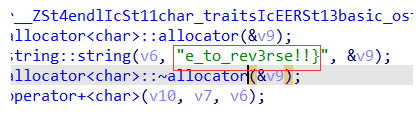
拼接一下输入,注意字符串的部分字母由近似数字代替,提交

KE

运行一下,看到是KE,想着可能是壳的意思?exeinfo看一下
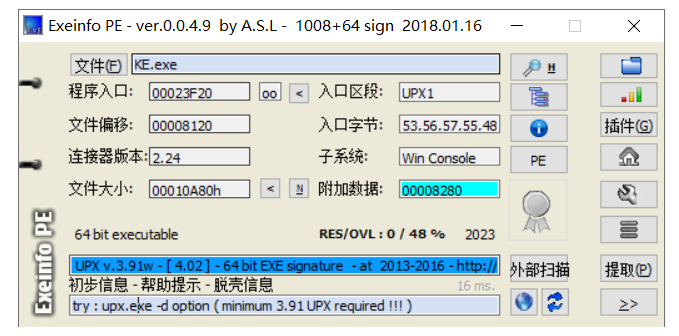
upx壳,尝试upx脱壳
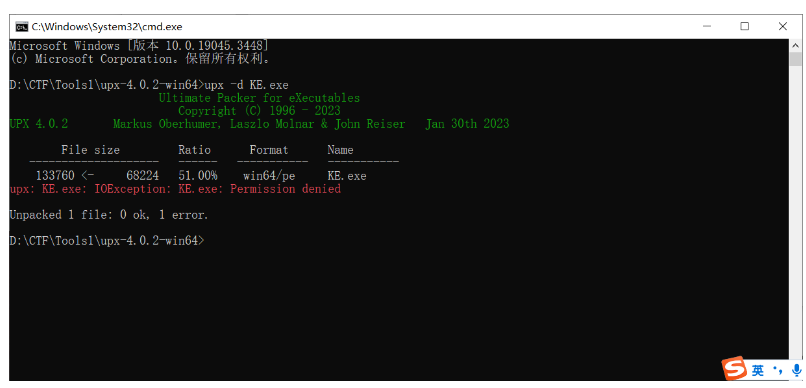
呃呃 权限好像不对 尝试了一下用管理员权限打开
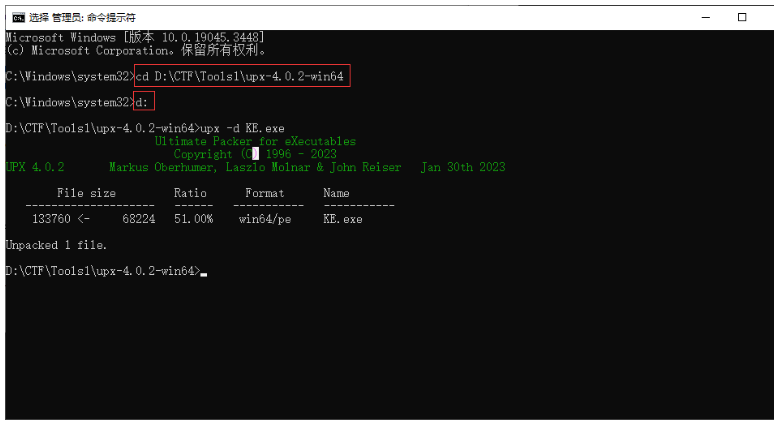
要记住先输入红框中的两行指令才可以打开目标文件夹。
打开之后可以看到成功脱壳了。
直接ida f5看看
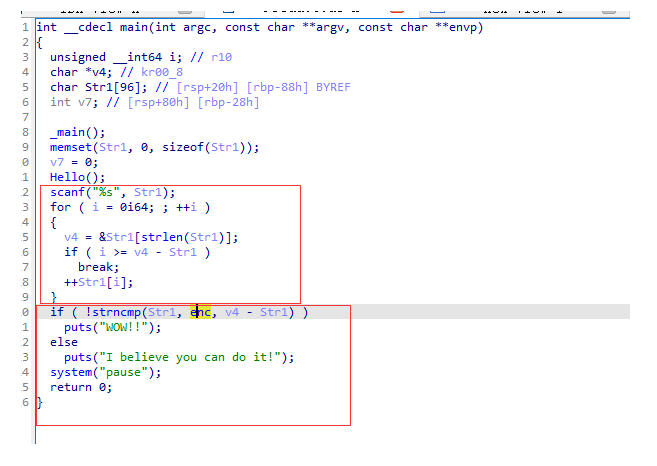
程序逻辑也很清晰了,第一个红框输入字符并且通过++Str1[i]把字符的ascii值往后推一个,第二个红框就是加密之后与字符串enc进行比较
enc:

写脚本吧
a="gmbh|D1ohsbuv2bu21ot1oQb332ohUifG2stuQ[HBMBYZ2fwf2~"
for i in a:
k=ord(i)-1
print(chr(k),end='')
出flag
flag{C0ngratu1at10ns0nPa221ngTheF1rstPZGALAXY1eve1}
segment
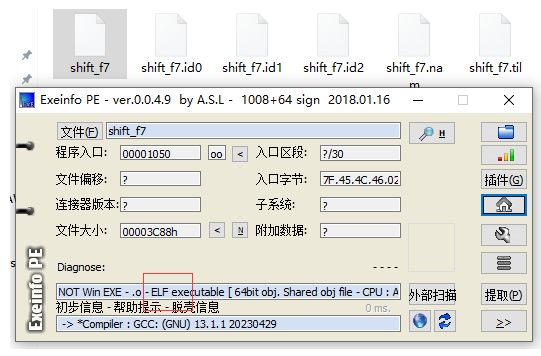
elf,那放到kali里面看看
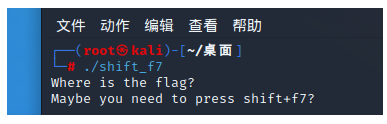
额,没啥信息,放ida里面吧,因为题目的信息也是这个
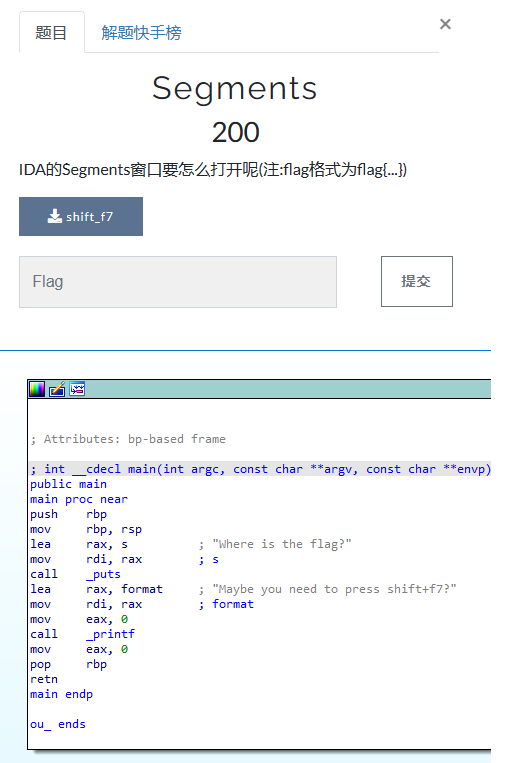
ok,啥也没有,按照提示shift f7打开段窗口
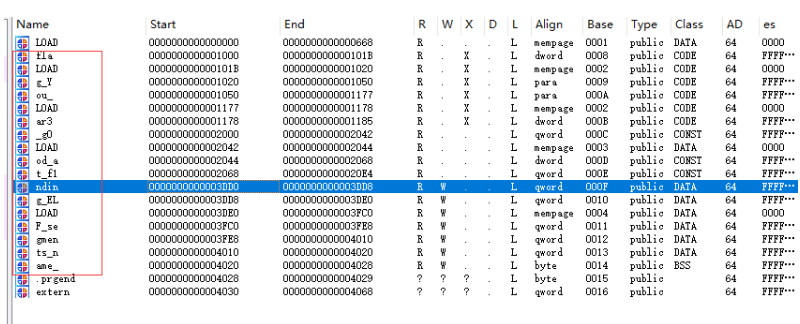
关键信息出来了,但是要注意的是flag后面的和name后面的__要换成{}
flag{You_ar3_g0od_at_f1nding_ELF_segments_name}
ELF
感觉没啥特殊的,扔kali里面看看
ida里面看看
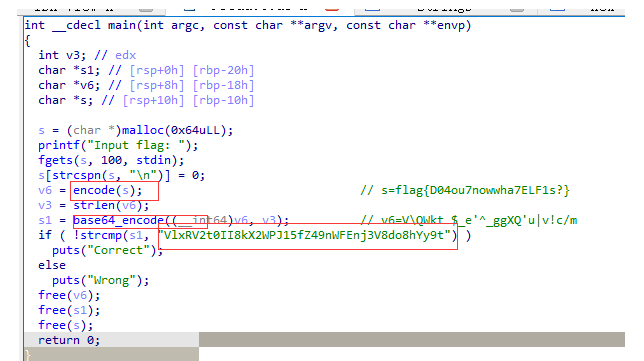
可以看到,我们输入的字符串先经过了两重加密,然后和Vlx…进行比较。
所以你想思路就是Vlx…先解base64,再解上面那个encode。
本来第一步解base64我用的就是在线网站
然后换了一个网站,发现还没什么,直接就进行下一步
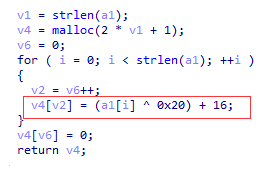
上面那个encode的逻辑就是先异或0x20,再减去16
那直接写就是了
flag{D04ou7nowwha7ELF1s?}
提交,不对。
后面我就觉得应该是上面有些不是标准字符,但是我错误的把他直接用来解密,就研究怎么直接在python里面,利用base64库,不用显示转义字符地得到字符串。直接告诉gpt需求,就写了
import base64
# 密文字符串
encrypted_string = "VlxRV2t0II8kX2WPJ15fZ49nWFEnj3V8do8hYy9t"
# Base64 替代字符集
altchars = b'@~'
# Base64 解码并使用替代字符集解析非标准字符
decoded_bytes = base64.b64decode(encrypted_string, altchars=altchars)
# 使用异或解密
decrypted_bytes = bytes([(c - 16) ^ 0x20 for c in decoded_bytes])
# 得到最初的字符串
original_string = decrypted_bytes.decode('utf-8')
print(original_string)
有了
flag{D0_4ou_7now_wha7_ELF_1s?}
Endian
endian是小端序的意思
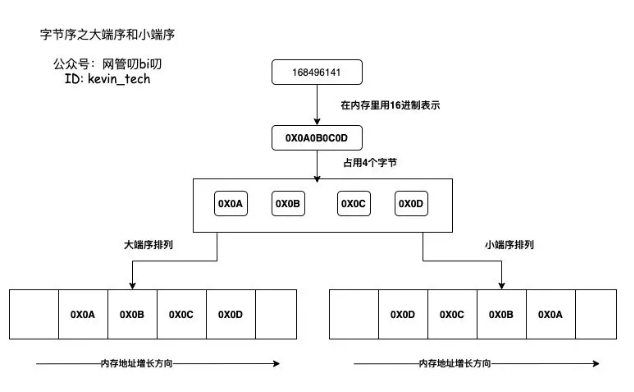
详细的自行百度
用exein看一看
没啥特殊的,直接ida

大概就是这样
很明显是我们输入的内容被覆给v5,然后v5和array这个数组的各个成员进行0x12345678异或
写个脚本
a=[0x75553A1E,0x7B583A03,0x4D58220C,0x7B50383D,0x736B3819]
b=[]
for i in a:
b.append(hex(i^0x12345678))
print(b)

大概就出了这些东西,简单看看第一个0x67616c66
根据小端序,先看66,66在ascii里面

再是6c

所以所说的小端序就是这里,flag分为5组,每组的字符按照小端序顺序存储,即前面的字符的asc码存在后面,写个脚本
a=[0x75553A1E,0x7B583A03,0x4D58220C,0x7B50383D,0x736B3819]
b=[]
for i in a:
b.append(hex(i^0x12345678))
print(b)
for m in b:
hex_str = m # 假设您的16进制数为0x12345678
for i in range(len(hex_str)-2, 1, -2): # 从后往前每次取2个字节
hex_byte = hex_str[i:i+2] # 取出2个字节的16进制数
ascii_code = int(hex_byte, 16) # 转换为整数
print(chr(ascii_code), end="") # 打印对应的ASCII码字符
flag{llittl_Endian_a
不知道为什么缺了个}
AndroXor
这是一道安卓题
愿意的话就自己弄个模拟器,或者安卓手机上面试试,我图个省事,就算了
安卓apk用jadx打开
通过搜索特定字符串(一般题目都会出wrong或者win或者success之类的字样,搜搜看)

框内的是比较可能,双击跟进。
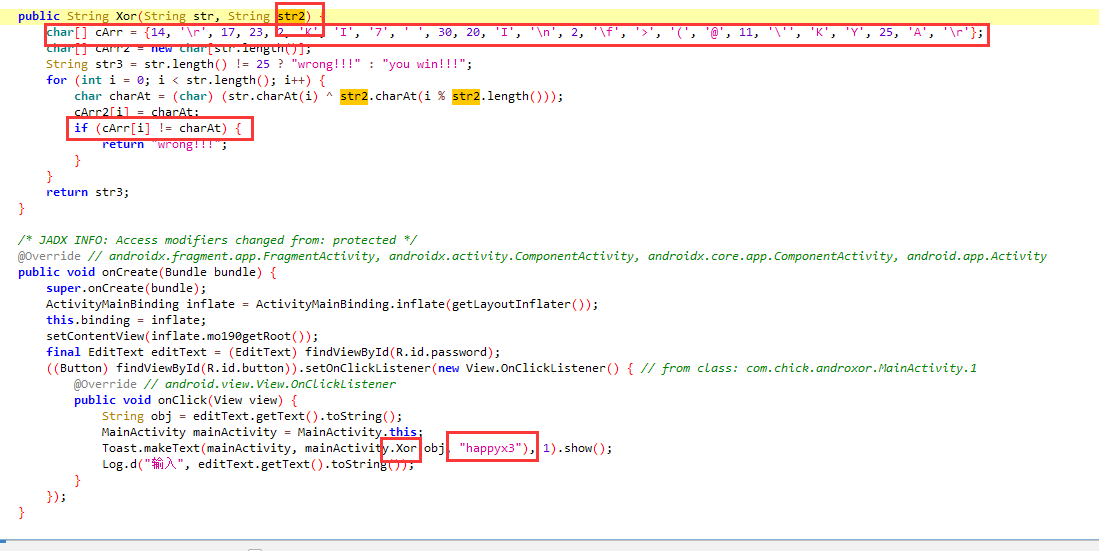
关键信息全都出现了,这个XOR方法有两个参数 str和str2
正向逻辑是我们输入的内容作为obj和happyx3进行异或,然后和本来的carr的内容比较,不对就报错
所以逆向也很简单了,carr和happyx3异或
c = [14,ord('\r'), 17, 23, 2, ord('K'), ord('I'), ord('7'), ord(' '), 30, 20, ord('I'), ord('\n'), 2, ord('\f'), ord('>'), ord('('), ord('@'), 11, ord('\''), ord('K'), ord('Y'), 25, ord('A'), ord('\r')]
key = b'happyx3'
xor(bytes(c),key)
#flag{3z_And0r1d_X0r_x1x1}
EzPE
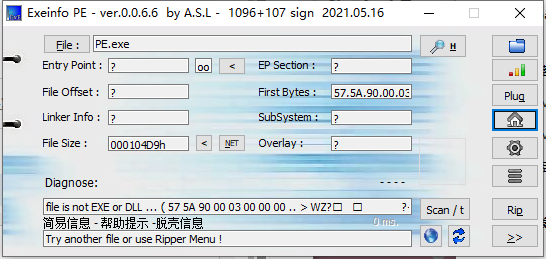

这题是比较难的一道题,从这里可以看出这个PE文件是有问题的,用010editor打开(这是一个二进制文件查看编辑器)

可以看到有让我们修复这个PE文件的信息,这涉及了PE文件结构体的各种知识,是挺复杂的东西,看了这题之后大家可以自行找点资料学学,结合本题,对PE文件有初步了解。
PE文件的DOS头里面有两个比较关键的点,一个是开头的MZ(PE文件作者的名字),另一个是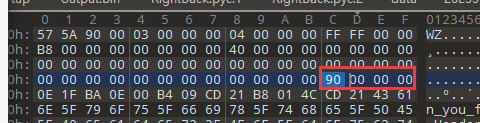
这个地方的下一个NT头的偏移。
可以看到这道题把MZ变成了WZ,先改回来
再是那个指向下个NT头的偏移
NT头有个比较重要的识别标志,即PE签名
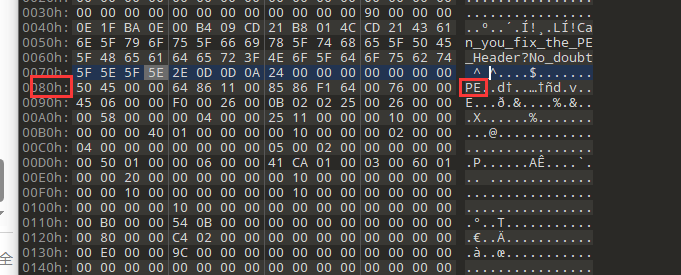
可以看到这个PE签名在80h的位置,而本来的NT头偏移指向90h,要改一下

可以看到现在
已经成功跑起来了,现在涉及程序逆向
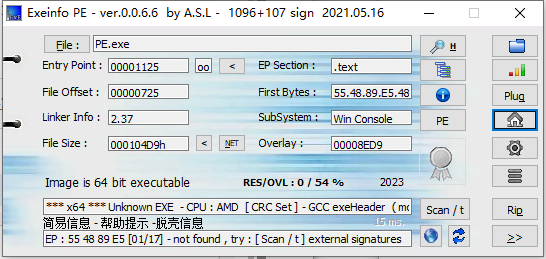
没啥问题,直接ida
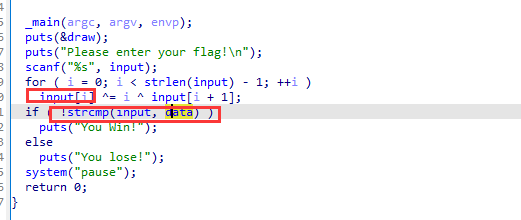
流程也很明显了,即我们输入的内容和自己再和序号和下一个异或,再和程序中本来的data进行比较
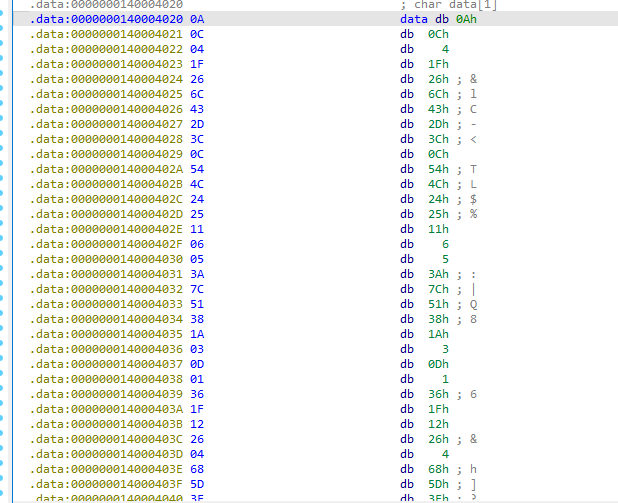
data如上,比较长一个
我就偷个懒了,data比较长直接用别人的脚本了
enc = bytes.fromhex('0A0C041F266C432D3C0C544C24251106053A7C51381A030D01361F122604685D3F2D372A7D')
flag = 'f'
for i in range(len(enc)):
for k in range(0x20,0x7f):
if ord(flag[i])^k^i == enc[i]:
flag += chr(k)
break
#flag{Y0u_kn0w_what_1s_PE_File_F0rmat}
lazy_activtiy
也是一个apk文件
不过这题没什么关键信息就只能一个个看
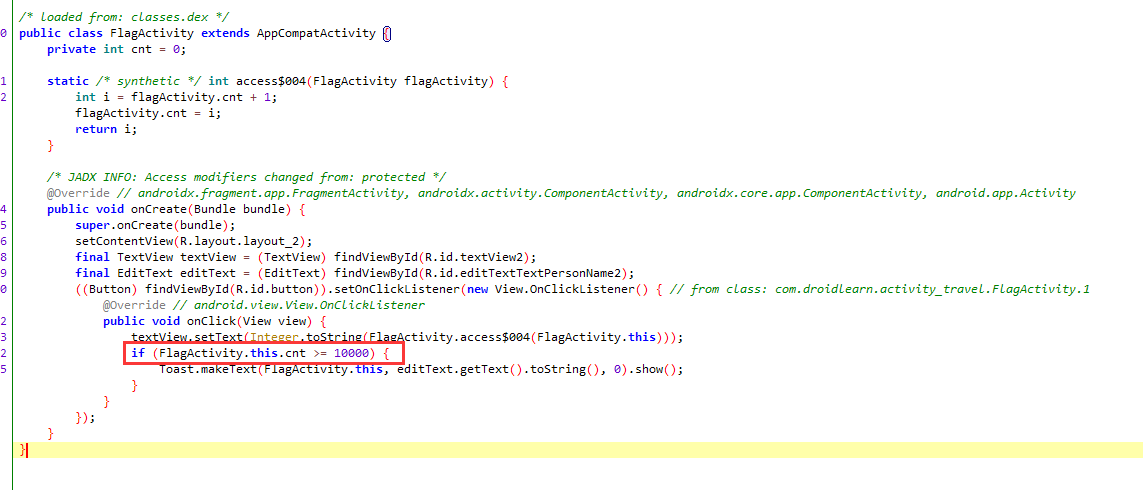
定位到这里,红框内容明显就是一个判断条件,这里是点击次数超过一万就成功。
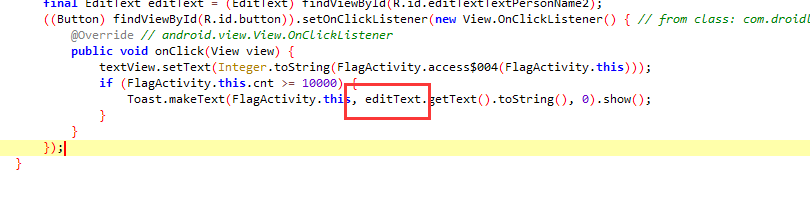
这里的edittext就是flag,这里是一个用户自定义的内容,根据上面字样layout_2

也找到了