AI从2012年开始快速发展,在人脸识别、广告、个性化推荐等领域大规模商用后,陆续出现了一些通用的平台来加速模型训练和模型部署流程,例如:
- AWS SageMaker :通过完全托管的基础设施、工具和工作流程为任何用例构建、训练和部署机器学习 (ML) 模型
- Google Vertex AI :使用全代管式机器学习工具更快地构建、部署和扩缩机器学习 (ML) 模型,以用于任何使用场景
- 华为云ModelArts:面向开发者的一站式 AI 平台,为机器学习与深度学习提供海量数据预处理及交互式智能标注、大规模分布式训练、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期 AI 工作流
- 阿里云PAI平台:提供企业级数据建模服务,基于机器学习算法,快速满足您对数据化运营的需求
- 百度飞桨BML: BML 全功能 AI 开发平台是一个面向企业和个人开发者的机器学习集成开发环境,为经典机器学习和深度学习提供了从数据处理、模型训练、模型管理到模型推理的全生命周期管理服务,帮助用户更快的构建、训练和部署模型
开源平台:
- 微众银行Prophecis:Prophecis 是微众银行自研的一站式机器学习平台,集成多种开源机器学习框架,具备机器学习计算集群的多租户管理能力,提供生产环境全栈化容器部署与管理服务
- 飞桨 PaddlePaddle:飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个自主研发、功能完备、 开源开放的产业级深度学习平台,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体
- 之江天枢开源平台: 平台面向人工智能研究中的数据处理、算法开发、模型训练、算力管理和推理应用等各个流程的技术难点,研发了包括一站式算法开发平台、高性能分布式深度学习框架、先进算法模型库、视觉模型炼知平台、数据可视化分析平台等一系列平台及工具
- 腾讯 Cube Studio:cube是 腾讯音乐 开源的一站式云原生机器学习平台,包含数据管理、在线开发、训练编排、推理服务、资源统筹等
商用平台在模型训练阶段:以 SaaS 平台通常提供了托管的Jupyter Notebook或JupyterLab平台,简化了开发环境软件和硬件的搭建,加速了模型训练过程。
而在模型部署阶段:提供了类似 Serverless 领域 Function as a Service的能力,自动化在线服务部署和API封装,简化了模型部署的流程。
对于数据准备阶段:自2019年,GO-JEK(一家SaaS解决方案公司)开源 Feast ——第一个提出 Feature Store 概念的平台后,各厂商陆续推出了自己的 Feature Store,它们的目标都在于提高数据准备阶段的效率:
- Databricks Announces the First Feature Store Co-designed with a Data and MLOps Platform - The Databricks Blog
- Feature Store | Vertex AI | Google Cloud
- 全新推出 Amazon SageMaker Feature Store – 完全托管的存储库,用于存储、发现、共享和提供机器学习特征
- 还有一些非通用的Feature Store在各种会议、技术论坛上被报道,可参考 Feature Store for ML
特征平台(feature store)的需求层次
特征平台的理解参考:《Feature Stores - A Hierarchy of Needs》(翻译总结版见《特征平台需求层次理论》)
业界实践资料:https://github.com/eugeneyan/applied-ml#feature-stores
特征平台的需求层次
如马斯洛需求层次理论,认为人类有五个层次的需求(生理需求、安全需求、社交需求、尊严需求、自我实现需求),呈金字塔形。该理论认为,人会首先满足最大最基本的需求(金字塔底),才会考虑更高层次的要求(金字塔顶)
同样,特征平台会首先满足最必要和急迫的需求(包括特征读取和特征服务),再去考虑高阶需求,如下图:

其中:
1、最底层是访问(access)的需求:这一层需求包括特征可读取、特征转换逻辑透明和特征血缘可溯。它们使得特征能被发现、分享和复用,减少重复。
- 从前,算法工程师进行机器学习开发时,60%的时间都花在编写特征转换逻辑上。—— Airbnb
2、其次是服务(serving)的需求:这一层的核心需求是为线上服务提供高吞吐、低延迟的特征读取能力,而无需通过 SQL 去数据仓库读取。其它需求还包括:与已有的离线特征存储集成,使得特征能够从离线特征存储同步到在线特征存储(例如 Redis);实时的特征转换等。
- 通常,数据工程师会将数据科学家实现的特征重新实现为可以在生产环境运行的特征管道。这个重复实现的过程会让项目推迟数月交付,让跨团队合作极为复杂。—— GoJek
3、诉诸准确(integrity)需求:最常见的需求是最小化 train-serve skew,确保特征在训练和服务环境下是一致的。另一个常见需求是 point-in-time correctness(又称 time-travel),以确保历史特征和标签被用于训练和评估时不存在 data leaks。
- 训练通常是离线的,而服务通常是实时的。保证训练和服务环境下的数据一致性极为重要。—— Uber
4、再往上,是便利的需求:特征平台需要足够简单好入手,例如提供简单直观的接口、易交互、易 debug 等,才能让大家采纳和受益。
- 记住,我们是个平台组。我们要搭建工具把提供给用户,让他们能够自己动手丰衣足食。—— Uber
5、最后是自治(autopilot)的需求:包括自动回填特征、对特征的分布进行监控和报警等。我知道有些公司有做这一层的事情,但我没怎么读到相关材料。
- 特征回填是训练集迭代最主要的瓶颈。解决这一问题能极大地加速数据科学家的工作流。—— Airbnb
并非所有团队都有全部五层需求,对大部分团队而言,满足第一、二层和部分第三层的需求就很受益了。不同团队对于每一层需求的程度要求也不同。在线场景少的团队相比每秒需要处理几百万请求的的 DoorDash 团队,当然更少关心特征服务的需求;
特征平台的能力
1、特征(Feature)创建:从各类原始数据,例如日志、记录、表,经过关联、统计、转化、聚集等操作得到的一系列值
- 例如,对于电商领域,从用户行为日志,可以计算得到用户最近30天购买商品列表、最近1小时浏览商品列表、平均订单金额等特征。特征是特征平台上最基础的概念。
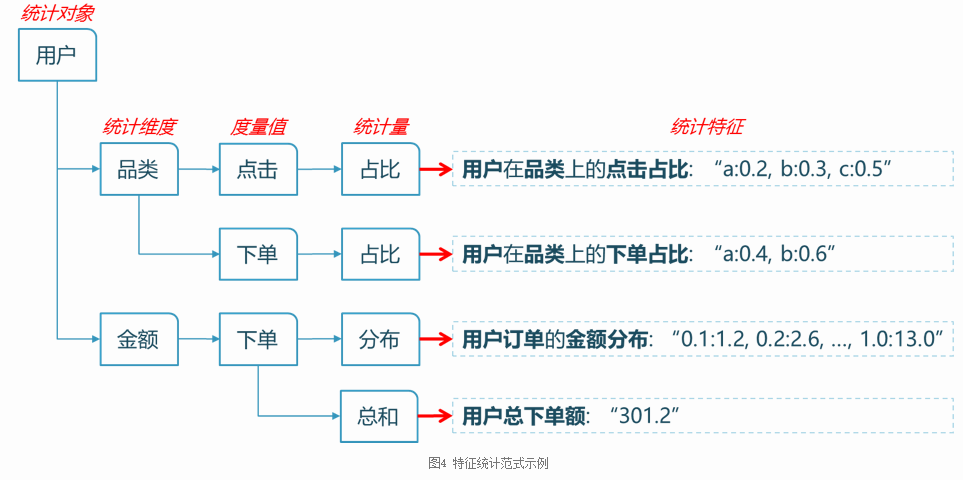
其中:
- 统计对象、统计维度、度量值对应于Hive表中的字段(维度一般来自维度表,度量值一般来自事实表,主要是曝光、点击、下单)。
- 为了增加灵活性,我们还允许对原始Hive字段做加工,加工后的值作为统计维度、度量值(加工的接口我们分别称为维度算子和度量算子)
- 统计量基于度量值做的一些聚合操作,如累加、求均值、拼接、求占比、算分位点(分布)。前两者输出一个数值,后三者输出形如”Key1:Value1,Key2:Value2”的KeyValue列表。
另外,统计通常是在一定时间窗口内进行的,由于不同时期的数据价值不同(新数据比老数据更有价值),我们引入了时间衰减,对老数据降权。 基于以上考虑,整个统计流程可以分解为(基于Spark):
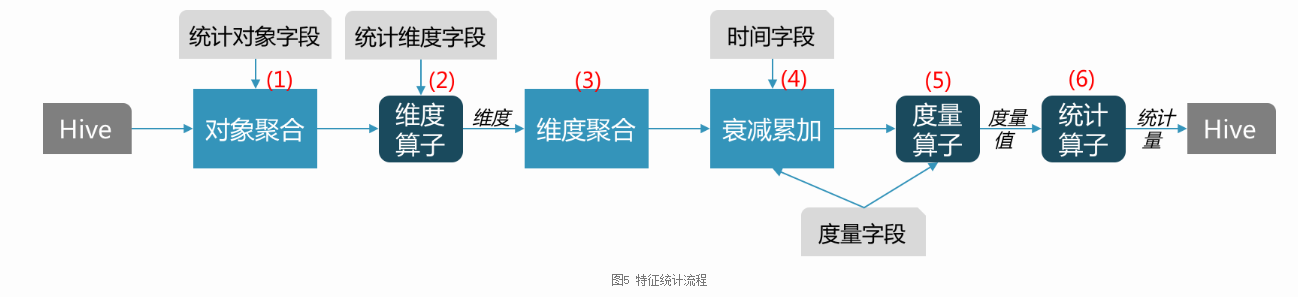
1)、按统计对象字段做聚合(GROUP BY)。统计对象字段由配置给定。对于外卖排序主要为uuid、poi_id。这一步可能会有数据倾斜,需要更多优化。
2)、计算维度。支持维度算子,可以对原始维度字段做处理,如对金额字段做分段处理,以分段后的金额作为维度。
3)、按统计维度聚合(GROUP BY)。这是在对象聚合的基础上做的二次聚合。维度字段由配置给定,可以有多个字段,表示交叉特征统计,如不同时段的品类偏好,维度字段为:时段、品类。
4)、时间衰减并累加。衰减各个时间的度量值,并把所有时间的度量值累加,作为加权后的度量值。时间字段和度量字段由配置给定。时间字段主要为日期,度量字段主要为曝光、点击、下单。经过维度聚合后,度量值都在特定维度值对应的记录集上做累加,每个维度对应一个度量值
5)、计算度量值。度量字段也可以通过度量算子做进一步处理,算子得到的结果作为度量值。也可以有多个字段,如点击和曝光字段,配合除法算子,可以得到点击率作为度量值。
6)、计算统计量。经过对象和维度聚合后,对象、维度、度量值建立了二级映射关系:对象维度度量值,相当于一个二维Map:Map<对象, Map<维度, 度量值>>。统计量是对Map<维度, 度量值>做一个聚合操作。每个统计量对应输出Hive表中的一个字段。现在主要支持如下几种算子:
- 累加:对该维度的所有度量值求和;
- 求均值:该维度所有取值情况对应的度量值的均值;
- 拼接:把Map<维度, 度量值>序列化为”Key1:Value1, Key2:Value2”形式,以便以字符串的形式存储于一个输出字段内。为了防止序列化串太长,可通过配置设定只保留度量值最大的top N;
- 求占比:该维度所有取值情况对应的度量值占度量值总和的比重,即Map<维度, 度量值/Sum(度量值)>。然后再做拼接输出;
- 算分位点:有时候想直到某些维度的分布情况,比如用户下单金额的分布以考察用户的消费能力。分位点可以作为分布的一种简单而有效的表示方法。该算子输出每个分位点的维度值,形如”分位点1:维度值1, 分位点2:维度值2”。此时,度量值只是用来算比值。
2、特征注册中心(Feature Registry): 通常以UI控制台暴露给用户使用,平台上所有特征均在此展示,方便平台用户进行探索、共享、复用。如下图:

3、特征离线存储&消费:离线存储&消费能力是为模型训练阶段服务的
- 对于广告、个性化推荐等使用过去信息来预测未来信息的算法模型,特征是随时间变化的。例如用户最近1小时浏览商品列表,会随着时间变化而发生变化。
- 进行模型训练时,我们需要预先生成训练数据。以电商场景为例,将一系列被标记的行为关联其对应的特征,即可生成训练数据。
4、特征在线存储&消费:在线存储&消费能力是为模型部署阶段服务的
- 算法模型部署成在线服务后,在进行推理(inference)时,需要快速取得特征,这要求我们将特征的最新的版本同步到高速缓存中,并提供便捷的查询API(例如按特征组查询),以便满足高并发、低延迟的特征在线消费要求;如下图:
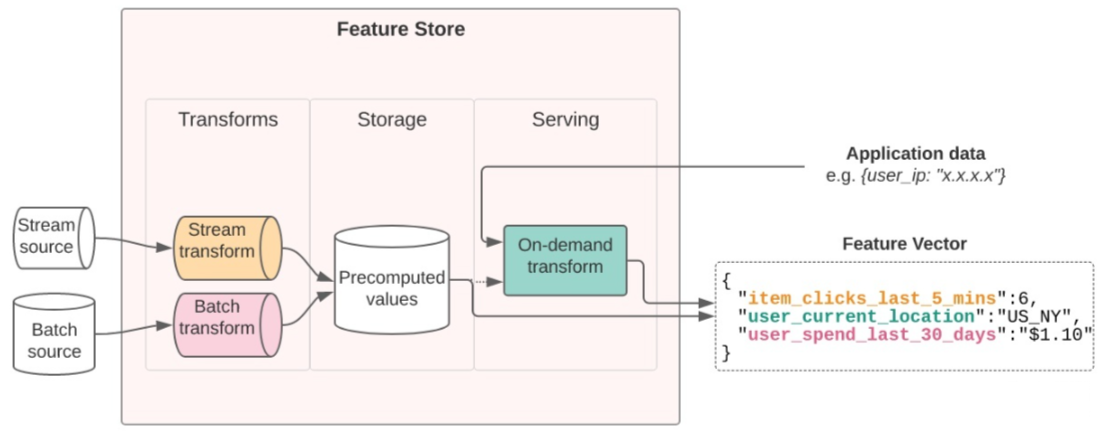
服务:在实时环境使用特征
常用批数据离线训练模型,然而在线模型服务需要实时读取这些特征。这难住了很多团队——应该如何为在线模型服务高吞吐、低延迟地提供(serve)这些特征?
- 我们在开发模型的过程中发现:很多用于训练的特征,并无法在生产环境中获取。—— Monzo Bank
Monzo Bank 能从离线分析环境(用于模型训练)中获取特征,但无法从生产环境(用于模型服务)中获取特征。Monzo Bank 采用了一个 轻量的解决方案,将离线分析存储(BigQuery)中的特征同步至在线存储(Cassandra)
- 首先,在离线分析环境的 SQL 建表语句中加入标签。这些表的更新频率在小时或天级别
- 特征平台中的 Go 服务检查特征表 schema 的正确性,例如必需的 subject_type 和 subject_id 列是否存在
- 有个 cron job 监听特征表的更新,将数据变动从 BigQuery 经过 Google Cloud Storage 的中转同步至 Cassandra
Uber 的 Palette 采取了类似的双存储设计。
- 离线存储(Hive)保存特征快照,用于训练。
- 在线存储(Cassandra)实时提供同样的特征。特征由 Flink 生成,写入 Cassandra。
- 两个存储之间会进行特征同步:添加到 Hive 的特征会被复制到 Cassandra,添加到 Cassandra 的特征会被 ETL 到 Hive。
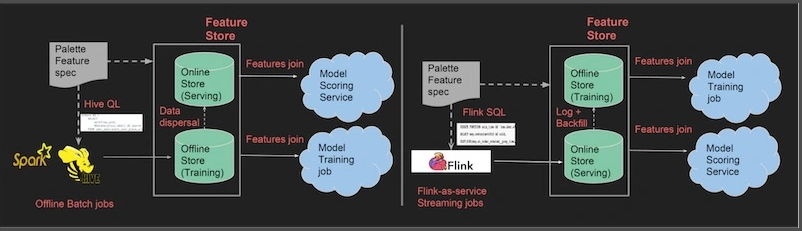
阿里巴巴的特征服务平台实时计算用户行为特征的统计量(点击、点赞、购买等),用于「猜你喜欢」实时推荐。
特征平台要解决的问题和方案
要解决的问题主要包含:
- 统一的特征管理中心:包括特征的各类元数据,计算逻辑,特征版本,数据血缘等,方便在组织内部管理和共享特征的使用
- 特征的生成支持:包括各类数据源的接入,特征自动化计算,持久化,backfill 等。很多时候业务都包含了batch, streaming两大类型的数据源,这部分感觉可以从lambda架构中学习一些经验。
- 特征的消费支持:也可以分为offline和online两大类。Offline就是训练阶段的特征提取支持,而online则是model serving时需要获取特征的支持。这里需要解决的一个比较重要的问题就是training-serving skew
- 特征的各类监控支持:包括特征生成的开销,特征的统计信息,数据质量,模型应用的精度,特征重要度等等。

技术架构设计:
1、在存储方面:大多数的解决方案都会区分提供offline和online服务的存储系统,因为两者的访问pattern分别是大批量获取和小批量低延迟获取。
- 例如Michelangelo里offline存储使用了Hive,而online的存储利用了Cassandra的KV查询能力。
- Hopsworks的offline存储用了Hudi,可以比较好的支持数据版本。
- Feast的offline和online存储分别是BigQuery和BigTable/Redis,不过这个选型对不同云平台的支持会有一些挑战。像一些新近的“湖仓一体”技术,或许未来也有机会成为Feature Store的底层技术支持。
2、在计算引擎方面:算法建模的同学最习惯的肯定还是Python生态,而batch和streaming两块比较流行的框架是Spark和Flink。如何保持算法建模的灵活性,同时又要兼顾线上运行的稳定和一致性已经是不小的挑战了,再加上batch和streaming计算逻辑的统一,难度就更大了。
- Feast在这方面利用了Apache Beam,可以同时支持Spark和Flink后端,但是构建feature的灵活度肯定就没有原生Python那么高了。
- 也有不少公司例如Uber,Pinterest,Twitter都开发了相应的DSL,也是一种思路。
3、数据版本方面:看起来用Delta Lake/Hudi/Iceberg等的解决方案还比较少,很多都是自行开发的支持。个人猜测跟复杂的serving pattern支持有一定关系,比如Delta Lake对于实时查询访问的支持就会比较困难。
4、数据格式的支持:相比于标准的结构化数据,算法训练过程中不同库需要消费的数据格式也不尽相同。像offline情况下可以选择parquet存储,支持更高效的数据压缩和传输,而online情况下可能需要json/protobuf之类便于API消费的数据格式
典型的架构如下:
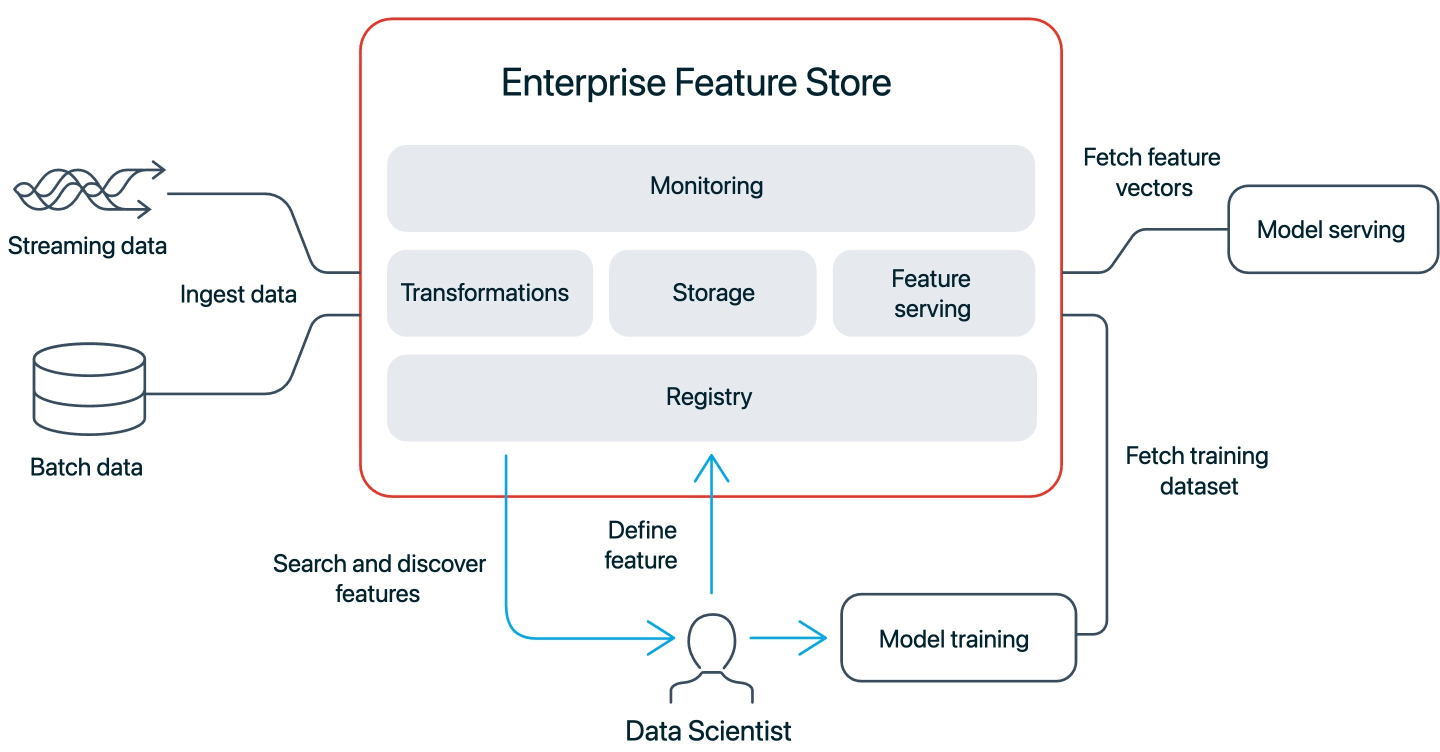
参考学习
- Uber 机器学习平台 Michelangelo实践
- 特征平台(Feature Store):Feast
- 特征平台(Feature Store):LinkedIn Feathr
- 特征平台(Feature Store):Databricks Feature Store
- 特征平台(Feature Store):Tecton
- 云音乐FeatureStore建设与实践
- 美团外卖特征平台的建设与实践
- 网易云音乐特征平台技术实践
- UU跑腿特征平台的探索
Flag:
- feature store以特征为基础概念,将特征生产、存储、消费从AI流程中解耦出来,封装成为公共的能力。提升多个AI模型间特征共享、复用的效率,解决特征消费中的诸多问题。
- 这一目标只在算法场景多样、迭代快、相关程度高的业务场景下,才能发挥其价值。如果算法需求简单、变化缓慢、无共享场景,则不必要引入feature store
- 特征平台 VS 指标系统?
参考资料: