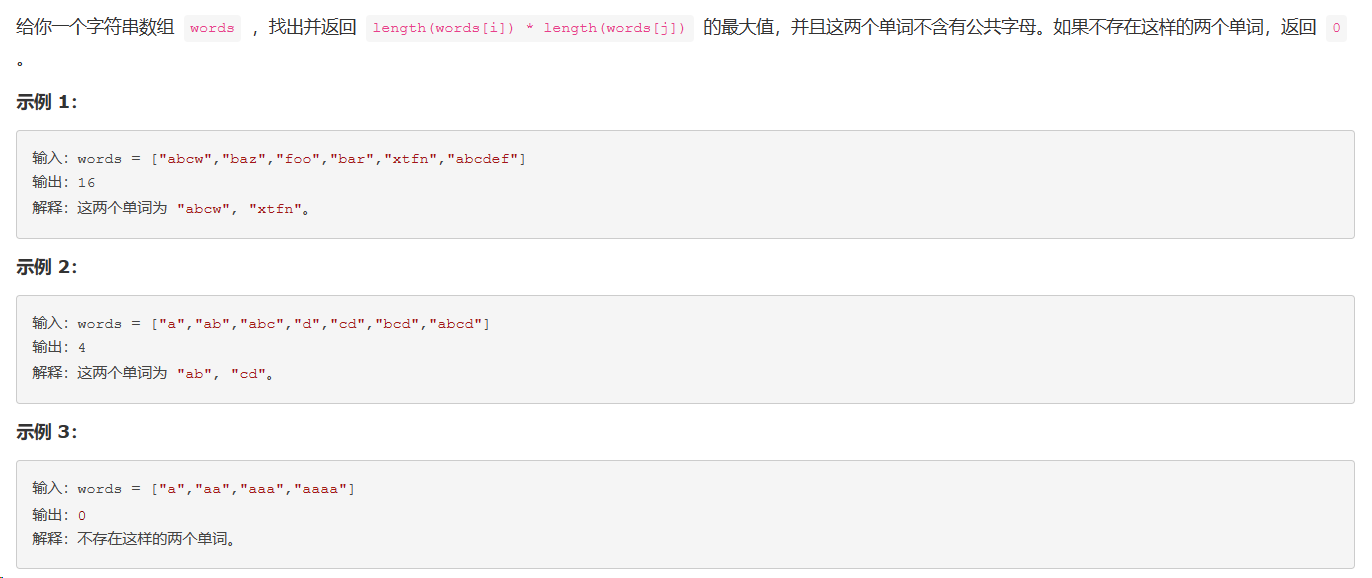
题目:
解答:
# 解法一(时间效率太低):较短的每个单词进行对长单词的逐一对比
# 解法二(时间复杂度较小)
words = eval(input())
def maxProduct(words):
mark = [0] * len(words) # 用来存放每个字符串的ASCII码的值(可用位运算比较两两字符串之间是否存在相同的字符),刚开始为0,方便进行一开始的或运算
max_num = 0 # 以max_num为比较对象,最终找到最大的结果
for i, v in enumerate(words): # 先存放与其它各字符串比较的字符串存放位置的下标和字符串
for k in v: # 遍历字符串各个位上的字符
mark[i] |= 1 << (ord(k) - ord("a"))
# "|"表示或运算(只要有一个为1,就都为1),先对每个字符串的二进制表示进行赋值在mark中,再遍历每个字符进行或运算,最终得到该字符串的最后的ASCII值(最终可观察每个字符串的ASCII值的二进制比较);位运算符“<<”表示向左移动,该运算符左边的数“1”表示原本的数(二进制中在1下方为1,其它位置上为0)对应的二进制:……32 16 8 4 2 1
for j, m in enumerate(words[:i]): # word[:i]的写法是因为i前面的的字符串已创建了ASCII码的比较条件,而后面的为创建好;j、m分别为被比较字符串的下标(单词存放的下标等于其ASCII码存放的下标)和字符串(方便对该字符串计算长度)
if (mark[i] & mark[j]) == 0: # & 表示与(只要二进制位有一个位0,结果就为0,即有相同的1则为有相同的字符,不符合条件)
max_num = max(max_num, len(v) * len(m)) # v为比较的字符串,m为被比较的字符串
return max_num
print(maxProduct(words))