上一篇博客介绍了 MySQL 的主从复制的搭建,为实现读写分离创造了条件。对于一个网站来说,80% 来源于读操作,绝大多数情况下的网站宕机,都是由于过多的读操作导致的,因此在实际的生产环境中,经常会搭建一主多从的架构,主库只负责写操作,多个从库用来负责读操作,对于少量需要实时获取信息的读操作,可以从主库进行读取。
本篇博客将使用 Sharding Jdbc 在主从复制的基础上和已经开发好的项目上,只需要进行配置,不需要写任何代码就可以实现读写分离。只有当需要强制从主库读取数据时,才需要写极少量的代码指定从主库读取。在本篇博客的最后会提供源代码下载。
一、Sharding Jdbc 简单介绍
Sharding Jdbc 是轻量级的 Java 框架,在 Java 的 Jdbc 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 Jdbc 驱动,完全兼容 Jdbc 和各种 ORM 框架。可以在程序中轻松的实现读写分离。
Sharding Jdbc 具有以下几个特点:
-
适用于任何基于 Jdbc 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring Jdbc Template 或直接使用 Jdbc。
-
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
-
支持任意实现 Jdbc 规范的数据库。支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
当然 Sharding Jdbc 也可以实现物理上的分库分表,由于物理上的分库分表自身也存在很多缺点,主要体现在人工处理问题时比较麻烦,如测试环境出现 bug 或生产环境出现问题时,需要人工排查问题时很麻烦,所以 Sharding Jdbc 逐渐很少在分库分表上发挥作用了,现在大多数使用分布式数据库在逻辑上使用分区表,物理上还是一张表,如 OceanBase 数据库。
二、搭建工程
搭建一个 SpringBoot 工程,具体结构如下:
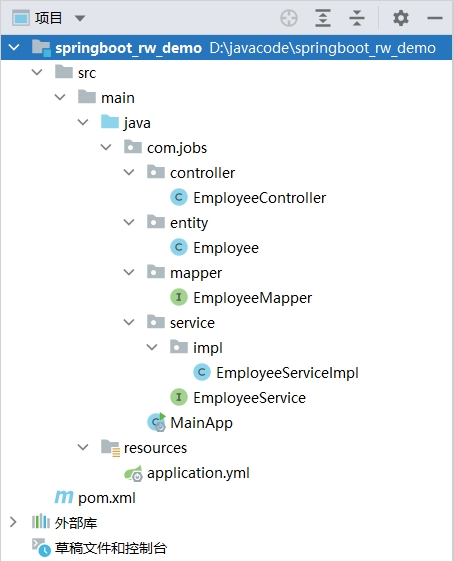
pom 文件中使用的 SpringBoot 版本和引入的 jar 包依赖如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.5</version>
<relativePath/>
</parent>
<groupId>com.jobs</groupId>
<artifactId>springboot_rw_demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
<!--sharding jdbc引入-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
从上面可以发现,如果想使用 sharding jdbc 只需要引入 sharding-jdbc-spring-boot-starter 即可,这里引入的是最新的 4.1.1 版本,需要注意的是:如果使用 durid 连接池的话,请使用 durid 包,不要使用 druid-spring-boot-starter 依赖包。
本篇博客做的是 Demo ,使用上篇博客搭建的 Mysql 一主一从结构作为演示,application.yml 配置如下:
server:
port: 8888
spring:
shardingsphere:
datasource:
# 数据源名称,以英文逗号分隔,需要跟下面的每个数据源配置对应上
names: master,slave
# 主库连接信息
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.216.128:3306/rw_demo?characterEncoding=utf-8
username: root
password: root
# 从库连接信息
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.216.129:3306/rw_demo?characterEncoding=utf-8
username: root
password: root
masterslave:
# 从库负载均衡算法,可选值为:round_robin 和 random
load-balance-algorithm-type: round_robin
# 最终的数据源名称(可以随便指定)
name: ds
# 主库数据源名称
master-data-source-name: master
# 从库数据源名称列表,多个逗号分隔
slave-data-source-names: slave
props:
sql:
#开启SQL显示,默认false
show: true
mybatis-plus:
configuration:
#在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射
map-underscore-to-camel-case: true
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
db-config:
id-type: ASSIGN_ID
配置文件的内容很简单,注释也很详细,应该很容易看懂。最主要就是把主库和从库的数据库连接信息配置好即可。
默认情况下 sharding jdbc 所有的写操作都是在主库上执行,所有的读操作都是在从库上执行。
对于从库的选择,有两种负载均衡算法:轮询和随机。
到此为止,Sharding Jdbc 的读写分离,就已经全部搞定了,下面要编写的业务代码,跟 Sharding Jdbc 没有什么关系了,只有想要强制从主库读取数据时,才需要编写一点点代码。下面就让我们快速把用于测试效果的业务代码堆起来吧。
三、代码细节展示
创建了一个实体类 Employee 具体细节如下:
package com.jobs.entity;
import lombok.Data;
import java.io.Serializable;
@Data
public class Employee implements Serializable {
private Long id;
private String name;
private Integer age;
}
由于使用 Mybatis Plus 框架,因此对于 Mapper 和 Service 等都是自动生成的,具体如下:
package com.jobs.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.jobs.entity.Employee;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface EmployeeMapper extends BaseMapper<Employee> {}
package com.jobs.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.jobs.entity.Employee;
public interface EmployeeService extends IService<Employee> {}
package com.jobs.service.impl;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.jobs.entity.Employee;
import com.jobs.mapper.EmployeeMapper;
import com.jobs.service.EmployeeService;
import org.springframework.stereotype.Service;
@Service
public class EmployeeServiceImpl extends ServiceImpl<EmployeeMapper, Employee>
implements EmployeeService {}
下面就是用于对外提供接口测试的 EmployeeController 代码:
package com.jobs.controller;
import com.jobs.entity.Employee;
import com.jobs.service.EmployeeService;
import org.apache.shardingsphere.api.hint.HintManager;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RequestMapping("/emp")
@RestController
public class EmployeeController {
@Autowired
private EmployeeService employeeService;
//主库添加
@PostMapping
public Employee addEmployee(@RequestBody Employee employee) {
employeeService.save(employee);
return employee;
}
//从库读取
@GetMapping("/{id}")
public Employee getEmployee(@PathVariable("id") Long id) {
Employee employee = employeeService.getById(id);
return employee;
}
//如果必须要及时拿到最新结果的话,可以强制从主库读取
@GetMapping("/list")
public List<Employee> getList() {
HintManager.clear();
//HintManager 实现了 AutoCloseable 接口,因此使用 try 可以自动释放资源
try (HintManager hintManager = HintManager.getInstance()) {
hintManager.setMasterRouteOnly();
List<Employee> list = employeeService.list();
return list;
}
}
}
四、验证效果
我们使用 Postman 工具来请求结果,在 IDEA 的控制台中,查看日志结果来验证读写分离的效果。
(1)调用添加 Employee 的接口
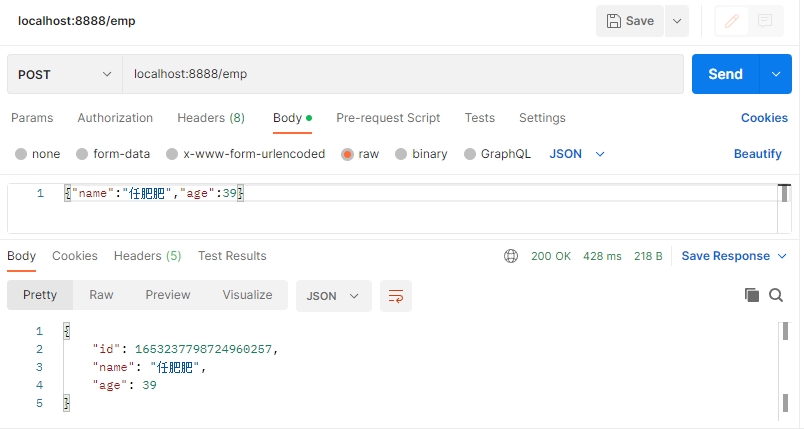
控制台打印的日志如下,由于原始控制台的信息换行过多,因此我复制到文本文件中进行展示:

从 Actual SQL:master 可以看出,添加操作是访问主库进行操作的。
(2)调用通过 id 获取 Employee 的接口
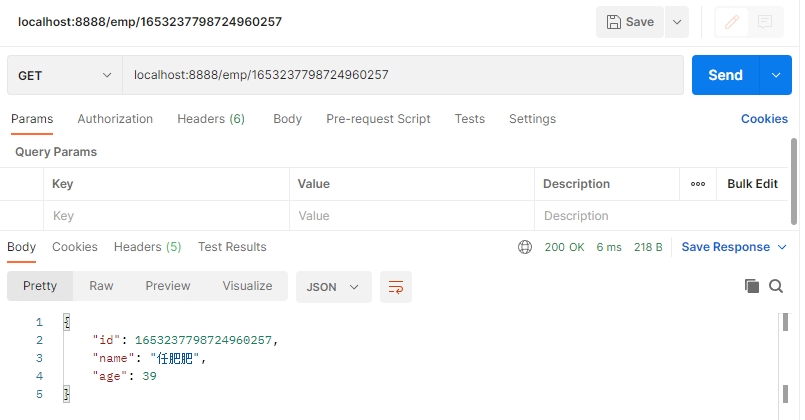
控制台打印的结果如下:
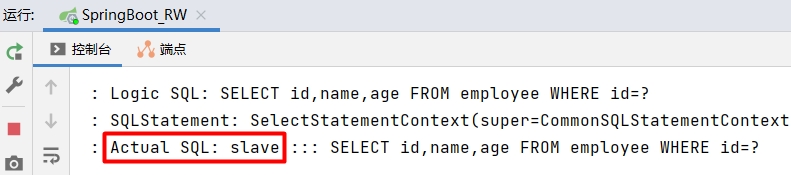
从 Actual SQL:slave 可以看出,读取数据是访问从库进行操作的。
(3)调用获取员工列表接口,代码中强制从主库中获取数据
由于主从复制需要一定的时间,尽管时间很短暂,为了能够实时获取数据,我们希望强制从主库获取数据,此时只需要添加一下代码,通过 HintManager 指定从主库获取即可。需要注意的是一定要提前调用 HintManager.clear() 方法。
HintManager.clear();
//HintManager 实现了 AutoCloseable 接口,因此使用 try 可以自动释放资源
try (HintManager hintManager = HintManager.getInstance()) {
hintManager.setMasterRouteOnly();
//自己需要编写的操作主库的业务代码...
}
使用 Postman 调用获取员工列表接口如下:
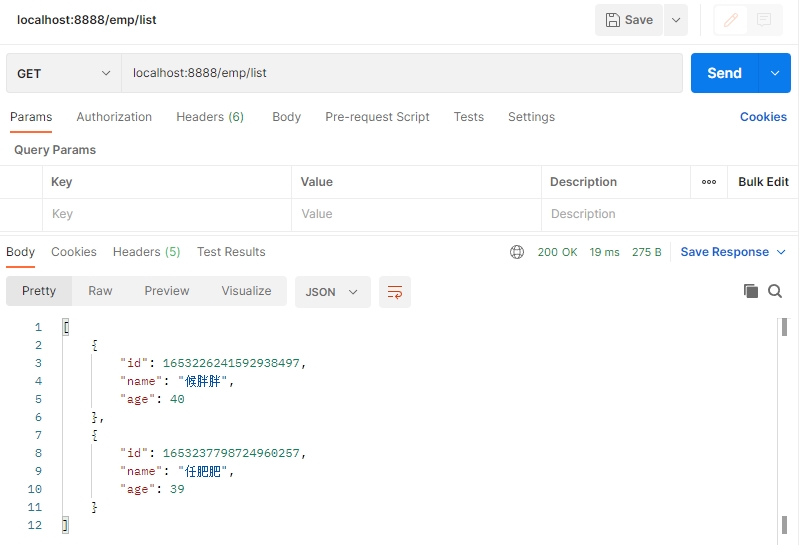
控制台打印的结果如下:
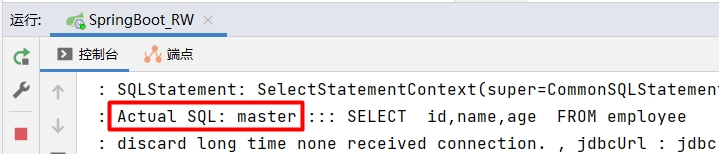
从上图中的 Actual SQL:master 可以发现,我们已经实现了从主库强制进行读取的操作。
本篇博客的源代码下载地址:https://files.cnblogs.com/files/blogs/699532/springboot_rw_demo.zip