什么LangChain
LangChain:一个让你的LLM变得更强大的开源框架
LangChain六大主要领域
- 管理和优化prompt。不同的任务使用不同prompt,如何去管理和优化这些prompt是langchain的主要功能之一。
- 链,初步理解为一个具体任务中不同子任务之间的一个调用。
- 数据增强的生成,数据增强生成涉及特定类型的链,它首先与外部数据源交互以获取数据用于生成步骤。这方面的例子包括对长篇文字的总结和对特定数据源的提问/回答。
- 代理,根据不同的指令采取不同的行动,直到整个流程完成为止。
- 评估,生成式模型是出了名的难以用传统的指标来评估。评估它们的一个新方法是使用语言模型本身来进行评估。LangChain提供了一些提示/链来协助这个工作。
- 内存:在整个流程中帮我们管理一些中间状态。
总的来说LongChain可以理解为:在一个流程的整个生命周期中,管理和优化prompt,根据prompt使用不同的代理进行不同的动作,在这期间使用内存管理中间的一些状态,然后使用链将不同代理之间进行连接起来,最终形成一个闭环。
LangChain的主要价值组件
- 组件:用于处理语言模型的抽象概念,以及每个抽象概念的实现集合。无论你是否使用LangChain框架的其他部分,组件都是模块化的,易于使用。
- 现成的链:用于完成特定高级任务的组件的结构化组合。现成的链使人容易上手。对于更复杂的应用和细微的用例,组件使得定制现有链或建立新链变得容易。
LangChain组件
- model I/O:语言模型接口
- data connection:与特定任务的数据接口
- chains:构建调用序列
- agents:给定高级指令,让链选择使用哪些工具
- memory:在一个链的运行之间保持应用状态
- callbacks:记录并流式传输任何链的中间步骤
- indexes:索引指的是结构化文件的方法,以便LLM能够与它们进行最好的交互
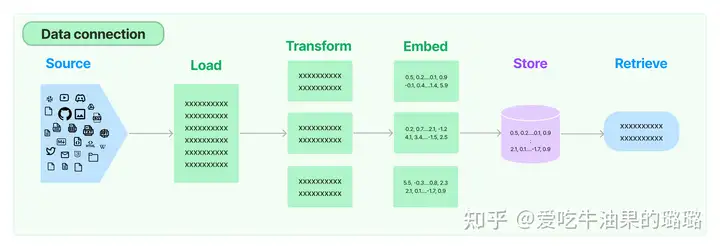
数据连接组件data connection
LLM应用需要用户特定的数据,这些数据不属于模型的训练集。LangChain通过以下方式提供了加载、转换、存储和查询数据的构建模块:
- 文档加载器:从许多不同的来源加载文档
- 文档转换器:分割文档,删除多余的文档等
- 文本嵌入模型:采取非结构化文本,并把它变成一个浮点数的列表 矢量存储:存储和搜索嵌入式数据
- 检索器:查询你的数据
data connection整体流程
data connection——文档加载器
python安装包命令:
pip install langchain
pip install unstructured
pip install jqCSV基本用法
import os
from pathlib import Path
from langchain.document_loaders import UnstructuredCSVLoader
from langchain.document_loaders.csv_loader import CSVLoader
EXAMPLE_DIRECTORY = file_path = Path(__file__).parent.parent / "examples"
def test_unstructured_csv_loader() -> None:
"""Test unstructured loader."""
file_path = os.path.join(EXAMPLE_DIRECTORY, "stanley-cups.csv")
loader = UnstructuredCSVLoader(str(file_path))
docs = loader.load()
print(docs)
assert len(docs) == 1
def test_csv_loader():
file_path = os.path.join(EXAMPLE_DIRECTORY, "stanley-cups.csv")
loader = CSVLoader(file_path)
docs = loader.load()
print(docs)
test_unstructured_csv_loader()
test_csv_loader()文件目录用法
from langchain.document_loaders import DirectoryLoader, TextLoader
text_loader_kwargs={'autodetect_encoding': True}
loader = DirectoryLoader('../examples/',
glob="**/*.txt", # 遍历txt文件
show_progress=True, # 显示进度
use_multithreading=True, # 使用多线程
loader_cls=TextLoader, # 使用加载数据的方式
silent_errors=True, # 遇到错误继续
loader_kwargs=text_loader_kwargs) # 可以使用字典传入参数
docs = loader.load()
print("\n")
print(docs[0])HTML用法
from langchain.document_loaders import UnstructuredHTMLLoader, BSHTMLLoader
loader = UnstructuredHTMLLoader("../examples/example.html")
docs = loader.load()
print(docs[0])
loader = BSHTMLLoader("../examples/example.html")
docs = loader.load()
print(docs[0])JSON用法
import json
from pathlib import Path
from pprint import pprint
file_path='../examples/facebook_chat.json'
data = json.loads(Path(file_path).read_text())
pprint(data)
"""
{'image': {'creation_timestamp': 1675549016, 'uri': 'image_of_the_chat.jpg'},
'is_still_participant': True,
'joinable_mode': {'link': '', 'mode': 1},
'magic_words': [],
'messages': [{'content': 'Bye!',
'sender_name': 'User 2',
'timestamp_ms': 1675597571851},
{'content': 'Oh no worries! Bye',
'sender_name': 'User 1',
'timestamp_ms': 1675597435669},
{'content': 'No Im sorry it was my mistake, the blue one is not '
'for sale',
'sender_name': 'User 2',
'timestamp_ms': 1675596277579},
{'content': 'I thought you were selling the blue one!',
'sender_name': 'User 1',
'timestamp_ms': 1675595140251},
{'content': 'Im not interested in this bag. Im interested in the '
'blue one!',
'sender_name': 'User 1',
'timestamp_ms': 1675595109305},
{'content': 'Here is $129',
'sender_name': 'User 2',
'timestamp_ms': 1675595068468},
{'photos': [{'creation_timestamp': 1675595059,
'uri': 'url_of_some_picture.jpg'}],
'sender_name': 'User 2',
'timestamp_ms': 1675595060730},
{'content': 'Online is at least $100',
'sender_name': 'User 2',
'timestamp_ms': 1675595045152},
{'content': 'How much do you want?',
'sender_name': 'User 1',
'timestamp_ms': 1675594799696},
{'content': 'Goodmorning! $50 is too low.',
'sender_name': 'User 2',
'timestamp_ms': 1675577876645},
{'content': 'Hi! Im interested in your bag. Im offering $50. Let '
'me know if you are interested. Thanks!',
'sender_name': 'User 1',
'timestamp_ms': 1675549022673}],
'participants': [{'name': 'User 1'}, {'name': 'User 2'}],
'thread_path': 'inbox/User 1 and User 2 chat',
'title': 'User 1 and User 2 chat'}
"""
使用langchain加载数据:
```python
from langchain.document_loaders import JSONLoader
loader = JSONLoader(
file_path='../examples/facebook_chat.json',
jq_schema='.messages[].content' # 会报错Expected page_content is string, got <class 'NoneType'> instead.
page_content=False, # 报错后添加这一行)
data = loader.load()
print(data[0])PDF用法
'''
第一种用法
'''
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("../examples/layout-parser-paper.pdf")
pages = loader.load_and_split()
print(pages[0])
'''
第二种用法
'''
from langchain.document_loaders import MathpixPDFLoader
loader = MathpixPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
print(data[0])
'''
第三种用法
'''
from langchain.document_loaders import UnstructuredPDFLoader
loader = UnstructuredPDFLoader("../examples/layout-parser-paper.pdf")
data = loader.load()
print(data[0])data connection——文档转换
加载了文件后,经常会需要转换它们以更好地适应应用。最简单的例子是,你可能想把一个长的文档分割成较小的块状,以适应你的模型的上下文窗口。LangChain有许多内置的文档转换工具,可以很容易地对文档进行分割、组合、过滤和其他操作。
通过字符进行文本分割
state_of_the_union = """
斗之力,三段!”
望着测验魔石碑上面闪亮得甚至有些刺眼的五个大字,少年面无表情,唇角有着一抹自嘲,紧握的手掌,因为大力,而导致略微尖锐的指甲深深的刺进了掌心之中,带来一阵阵钻心的疼痛…
“萧炎,斗之力,三段!级别:低级!”测验魔石碑之旁,一位中年男子,看了一眼碑上所显示出来的信息,语气漠然的将之公布了出来…
中年男子话刚刚脱口,便是不出意外的在人头汹涌的广场上带起了一阵嘲讽的骚动。
“三段?嘿嘿,果然不出我所料,这个“天才”这一年又是在原地踏步!”
“哎,这废物真是把家族的脸都给丢光了。”
“要不是族长是他的父亲,这种废物,早就被驱赶出家族,任其自生自灭了,哪还有机会待在家族中白吃白喝。”
“唉,昔年那名闻乌坦城的天才少年,如今怎么落魄成这般模样了啊?”
"""
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator = "\n\n",
chunk_size = 128, # 分块长度
chunk_overlap = 10, # 重合的文本长度
length_function = len,
)
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
# 这里metadatas用于区分不同的文档
metadatas = [{"document": 1}, {"document": 2}]
documents = text_splitter.create_documents([state_of_the_union, state_of_the_union], metadatas=metadatas)
pprint(documents)
# 获取切割后的文本
print(text_splitter.split_text(state_of_the_union)[0])对代码进行分割
from langchain.text_splitter import (
RecursiveCharacterTextSplitter,
Language,
)
print([e.value for e in Language]) # 支持语言
print(RecursiveCharacterTextSplitter.get_separators_for_language(Language.PYTHON)) # 分割符号
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
# Call the function
hello_world()
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=50, chunk_overlap=0
)
python_docs = python_splitter.create_documents([PYTHON_CODE])
python_docs
"""
[Document(page_content='def hello_world():\n print("Hello, World!")', metadata={}),
Document(page_content='# Call the function\nhello_world()', metadata={})]
"""通过markdownheader进行分割
举个例子:md = # Foo\n\n ## Bar\n\nHi this is Jim \nHi this is Joe\n\n ## Baz\n\n Hi this is Molly' .我们定义分割头:[("#", "Header 1"),("##", "Header 2")]文本应该被公共头进行分割,最终得到:`{'content': 'Hi this is Jim \nHi this is Joe', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Bar'}} {'content': 'Hi this is Molly', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Baz'}}
from langchain.text_splitter import MarkdownHeaderTextSplitter
markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly"
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits
"""
[Document(page_content='Hi this is Jim \nHi this is Joe', metadata={'Header 1': 'Foo', 'Header 2': 'Bar'}),
Document(page_content='Hi this is Lance', metadata={'Header 1': 'Foo', 'Header 2': 'Bar', 'Header 3': 'Boo'}),
Document(page_content='Hi this is Molly', metadata={'Header 1': 'Foo', 'Header 2': 'Baz'})]
"""通过字符递归分割
默认列表为:["\n\n", "\n", " ", ""]
state_of_the_union = """
斗之力,三段!”
望着测验魔石碑上面闪亮得甚至有些刺眼的五个大字,少年面无表情,唇角有着一抹自嘲,紧握的手掌,因为大力,而导致略微尖锐的指甲深深的刺进了掌心之中,带来一阵阵钻心的疼痛…
“萧炎,斗之力,三段!级别:低级!”测验魔石碑之旁,一位中年男子,看了一眼碑上所显示出来的信息,语气漠然的将之公布了出来…
中年男子话刚刚脱口,便是不出意外的在人头汹涌的广场上带起了一阵嘲讽的骚动。
“三段?嘿嘿,果然不出我所料,这个“天才”这一年又是在原地踏步!”
“哎,这废物真是把家族的脸都给丢光了。”
“要不是族长是他的父亲,这种废物,早就被驱赶出家族,任其自生自灭了,哪还有机会待在家族中白吃白喝。”
“唉,昔年那名闻乌坦城的天才少年,如今怎么落魄成这般模样了啊?”
"""
from langchain.text_splitter import CharacterTextSplitter
from pprint import pprint
text_splitter = CharacterTextSplitter(
chunk_size = 128,
chunk_overlap = 10,
length_function = len,
)
texts = text_splitter.create_documents([state_of_the_union])
pprint(texts[0].page_content)
"""
('斗之力,三段!”\n'
'\n'
'望着测验魔石碑上面闪亮得甚至有些刺眼的五个大字,少年面无表情,唇角有着一抹自嘲,紧握的手掌,因为大力,而导致略微尖锐的指甲深深的刺进了掌心之中,带来一阵阵钻心的疼痛…')
['斗之力,三段!”\n'
'\n'
'望着测验魔石碑上面闪亮得甚至有些刺眼的五个大字,少年面无表情,唇角有着一抹自嘲,紧握的手掌,因为大力,而导致略微尖锐的指甲深深的刺进了掌心之中,带来一阵阵钻心的疼痛…',
'“萧炎,斗之力,三段!级别:低级!”测验魔石碑之旁,一位中年男子,看了一眼碑上所显示出来的信息,语气漠然的将之公布了出来…\n'
'\n'
'中年男子话刚刚脱口,便是不出意外的在人头汹涌的广场上带起了一阵嘲讽的骚动。']
"""通过tokens进行分割
我们知道,语言模型有一个令牌限制。不应该超过令牌的限制。因此,当你把你的文本分成几块时,计算标记的数量是一个好主意。有许多标记器。当你计算文本中的令牌时,你应该使用与语言模型中使用的相同的令牌器。
安装tiktoken安装包
pip install tiktokenpython代码实现如下:
state_of_the_union = """
斗之力,三段!”
望着测验魔石碑上面闪亮得甚至有些刺眼的五个大字,少年面无表情,唇角有着一抹自嘲,紧握的手掌,因为大力,而导致略微尖锐的指甲深深的刺进了掌心之中,带来一阵阵钻心的疼痛…
“萧炎,斗之力,三段!级别:低级!”测验魔石碑之旁,一位中年男子,看了一眼碑上所显示出来的信息,语气漠然的将之公布了出来…
中年男子话刚刚脱口,便是不出意外的在人头汹涌的广场上带起了一阵嘲讽的骚动。
“三段?嘿嘿,果然不出我所料,这个“天才”这一年又是在原地踏步!”
“哎,这废物真是把家族的脸都给丢光了。”
“要不是族长是他的父亲,这种废物,早就被驱赶出家族,任其自生自灭了,哪还有机会待在家族中白吃白喝。”
“唉,昔年那名闻乌坦城的天才少年,如今怎么落魄成这般模样了啊?”
"""
from langchain.text_splitter import CharacterTextSplitter
from pprint import pprint
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=128, chunk_overlap=10
)
texts = text_splitter.split_text(state_of_the_union)
pprint(texts)
for text in texts:
print(len(text))
"""
WARNING:langchain.text_splitter:Created a chunk of size 184, which is longer than the specified 128
['斗之力,三段!”',
'望着测验魔石碑上面闪亮得甚至有些刺眼的五个大字,少年面无表情,唇角有着一抹自嘲,紧握的手掌,因为大力,而导致略微尖锐的指甲深深的刺进了掌心之中,带来一阵阵钻心的疼痛…',
'“萧炎,斗之力,三段!级别:低级!”测验魔石碑之旁,一位中年男子,看了一眼碑上所显示出来的信息,语气漠然的将之公布了出来…',
'中年男子话刚刚脱口,便是不出意外的在人头汹涌的广场上带起了一阵嘲讽的骚动。',
'“三段?嘿嘿,果然不出我所料,这个“天才”这一年又是在原地踏步!”\n\n“哎,这废物真是把家族的脸都给丢光了。”',
'“要不是族长是他的父亲,这种废物,早就被驱赶出家族,任其自生自灭了,哪还有机会待在家族中白吃白喝。”',
'“唉,昔年那名闻乌坦城的天才少年,如今怎么落魄成这般模样了啊?”']
8
83
61
37
55
50
32
"""
'''
直接使用tiktoken
'''
from langchain.text_splitter import TokenTextSplitter
text_splitter = TokenTextSplitter(chunk_size=128, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])模型IO组件
模型包括LLM、聊天模型、文本嵌入模型。大型语言模型(LLM)是我们涵盖的第一种模型类型。这些模型接受一个文本字符串作为输入,并返回一个文本字符串作为输出。聊天模型是我们涵盖的第二种类型的模型。这些模型通常由一个语言模型支持,但它们的API更加结构化。具体来说,这些模型接受一个聊天信息的列表作为输入,并返回一个聊天信息。第三类模型是文本嵌入模型。这些模型将文本作为输入,并返回一个浮点数列表。
LangChain提供了连接任何语言模型的构建模块。
- 提示: 模板化、动态选择和管理模型输入
对模型进行编程的新方法是通过提示语。一个提示指的是对模型的输入。这种输入通常是由多个组件构成的。LangChain提供了几个类和函数,使构建和处理提示信息变得容易。常用的方法是:提示模板: 对模型输入进行参数化处;与例子选择器: 动态地选择要包含在提示中的例子。
一个提示模板可以包含:对语言模型的指示;一组少量的例子,以帮助语言模型产生一个更好的反应;一个对语言模型的问题。例如:
from langchain import PromptTemplate
template = """/
You are a naming consultant for new companies.
What is a good name for a company that makes {product}?
"""
prompt = PromptTemplate.from_template(template)
prompt.format(product="colorful socks")
"""
You are a naming consultant for new companies.
What is a good name for a company that makes colorful socks?
"""如果需要创建一个与角色相关的消息模板,则需要使用MessagePromptTemplate。
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)MessagePromptTemplate的类型:LangChain提供不同类型的MessagePromptTemplate。最常用的是AIMessagePromptTemplate、SystemMessagePromptTemplate和HumanMessagePromptTemplate,它们分别创建AI消息、系统消息和人类消息。
通用的提示模板:假设我们想让LLM生成一个函数名称的英文解释。为了实现这一任务,我们将创建一个自定义的提示模板,将函数名称作为输入,并对提示模板进行格式化,以提供该函数的源代码。
我们首先创建一个函数,它将返回给定的函数的源代码。
import inspect
def get_source_code(function_name):
# Get the source code of the function
return inspect.getsource(function_name)接下来,我们将创建一个自定义的提示模板,将函数名称作为输入,并格式化提示模板以提供函数的源代码。
from langchain.prompts import StringPromptTemplate
from pydantic import BaseModel, validator
class FunctionExplainerPromptTemplate(StringPromptTemplate, BaseModel):
"""A custom prompt template that takes in the function name as input, and formats the prompt template to provide the source code of the function."""
@validator("input_variables")
def validate_input_variables(cls, v):
"""Validate that the input variables are correct."""
if len(v) != 1 or "function_name" not in v:
raise ValueError("function_name must be the only input_variable.")
return v
def format(self, **kwargs) -> str:
# Get the source code of the function
source_code = get_source_code(kwargs["function_name"])
# Generate the prompt to be sent to the language model
prompt = f"""
Given the function name and source code, generate an English language explanation of the function.
Function Name: {kwargs["function_name"].__name__}
Source Code:
{source_code}
Explanation:
"""
return prompt
def _prompt_type(self):
return "function-explainer"- 语言模型: 通过通用接口调用语言模型
LLMs和聊天模型有微妙但重要的区别。LangChain中的LLM指的是纯文本完成模型。它们所包含的API将一个字符串提示作为输入并输出一个字符串完成。OpenAI的GPT-3是作为LLM实现的。聊天模型通常由LLM支持,但专门为进行对话而进行调整。而且,至关重要的是,他们的提供者API暴露了一个与纯文本完成模型不同的接口。它们不接受单一的字符串,而是接受一个聊天信息的列表作为输入。通常这些信息都标有说话者(通常是 "系统"、"AI "和 "人类 "中的一个)。它们会返回一个("AI")聊天信息作为输出。GPT-4和Anthropic的Claude都是作为聊天模型实现的。
为了使LLM和聊天模型的交换成为可能,两者都实现了基础语言模型接口。这暴露了常见的方法 "predict "和 "pred messages",前者接受一个字符串并返回一个字符串,后者接受消息并返回一个消息。如果你使用一个特定的模型,建议你使用该模型类的特定方法(例如,LLM的 "预测 "和聊天模型的 "预测消息"),但如果你正在创建一个应该与不同类型的模型一起工作的应用程序,共享接口会有帮助。
使用LLM的最简单方法是可调用:传入一个字符串,得到一个字符串完成。
generate: batch calls, richer outputs
generate让你可以用一串字符串调用模型,得到比文本更完整的响应。这个完整的响应可以包括像多个顶级响应和其他LLM提供者的特定信息,例如:
llm_result = llm.generate(["Tell me a joke", "Tell me a poem"]*15)
len(llm_result.generations)
'''
30
'''
llm_result.generations[0]
'''
[Generation(text='\n\nWhy did the chicken cross the road?\n\nTo get to the other side!'),
Generation(text='\n\nWhy did the chicken cross the road?\n\nTo get to the other side.')]
'''
llm_result.generations[-1]
'''
[Generation(text="\n\nWhat if love neverspeech\n\nWhat if love never ended\n\nWhat if love was only a feeling\n\nI'll never know this love\n\nIt's not a feeling\n\nBut it's what we have for each other\n\nWe just know that love is something strong\n\nAnd we can't help but be happy\n\nWe just feel what love is for us\n\nAnd we love each other with all our heart\n\nWe just don't know how\n\nHow it will go\n\nBut we know that love is something strong\n\nAnd we'll always have each other\n\nIn our lives."),
Generation(text='\n\nOnce upon a time\n\nThere was a love so pure and true\n\nIt lasted for centuries\n\nAnd never became stale or dry\n\nIt was moving and alive\n\nAnd the heart of the love-ick\n\nIs still beating strong and true.')]
You can also access provider specific information that is returned. This information is NOT standardized across providers.
'''
llm_result.llm_output
'''
{'token_usage': {'completion_tokens': 3903,
'total_tokens': 4023,
'prompt_tokens': 120}}
'''LongChain具体支持什么模型,不同模型是怎么使用的可以看官方文档:Language models | ️ Langchain
- 输出分析器: 从模型输出中提取信息
输出解析器是帮助结构化语言模型响应的类。有两个主要的方法是输出解析器必须实现的:
- "获取格式说明":该方法返回一个字符串,包含语言模型的输出应该如何被格式化的指示。
- "解析": 该方法接收一个字符串(假定是来自语言模型的响应)并将其解析为某种结构。
- "带提示的解析":该方法是可选方法,它接收一个字符串(假定是来自语言模型的响应)和一个提示(假定是产生这种响应的提示),并将其解析为一些结构。提示主要是在OutputParser想要重试或以某种方式修复输出的情况下提供的,并且需要从提示中获得信息来这样做。
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field, validator
from typing import List
model_name = 'text-davinci-003'
temperature = 0.0
model = OpenAI(model_name=model_name, temperature=temperature)
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# You can add custom validation logic easily with Pydantic.
@validator('setup')
def question_ends_with_question_mark(cls, field):
if field[-1] != '?':
raise ValueError("Badly formed question!")
return field
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
# And a query intented to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."
_input = prompt.format_prompt(query=joke_query)
output = model(_input.to_string())
parser.parse(output)
Joke(setup='Why did the chicken cross the road?', punchline='To get to the other side!')具体参见:Output parsers | ️ Langchain
Chain链组件
更复杂的应用需要将LLM串联起来--要么相互串联,要么与其他组件串联。这时就需要用到Chain链组件。
LangChain为这种 "链式 "应用提供了Chain接口。其基本接口很简单:
class Chain(BaseModel, ABC):
"""Base interface that all chains should implement."""
memory: BaseMemory
callbacks: Callbacks
def __call__(
self,
inputs: Any,
return_only_outputs: bool = False,
callbacks: Callbacks = None,
) -> Dict[str, Any]:
...使用不同链功能的演示,可参见官方文档:How to | ️ Langchain
最受欢迎的链可以参见:Popular | ️ Langchain
链允许我们将多个组件结合在一起,创建一个单一的、连贯的应用程序。例如,我们可以创建一个链,接受用户输入,用PromptTemplate格式化,然后将格式化的响应传递给LLM。我们可以通过将多个链组合在一起,或将链与其他组件组合在一起,建立更复杂的链。LLMChain是最基本的构建块链。它接受一个提示模板,用用户输入的格式化它,并从LLM返回响应。
我们首先要创建一个提示模板:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)然后,创建一个非常简单的链,它将接受用户的输入,用它来格式化提示,然后将其发送到LLM。
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
Colorful Toes Co.
'''
如果有多个变量,可以用一个字典一次输入它们。
'''
prompt = PromptTemplate(
input_variables=["company", "product"],
template="What is a good name for {company} that makes {product}?",
)
chain = LLMChain(llm=llm, prompt=prompt)
print(chain.run({
'company': "ABC Startup",
'product': "colorful socks"
}))
Socktopia Colourful Creations.也可以在LLMChain中使用一个聊天模型:
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
human_message_prompt = HumanMessagePromptTemplate(
prompt=PromptTemplate(
template="What is a good name for a company that makes {product}?",
input_variables=["product"],
)
)
chat_prompt_template = ChatPromptTemplate.from_messages([human_message_prompt])
chat = ChatOpenAI(temperature=0.9)
chain = LLMChain(llm=chat, prompt=chat_prompt_template)
print(chain.run("colorful socks"))
Rainbow Socks Co.链的序列化,保存链到磁盘,从磁盘加载链:
总结
LangChain 为特定用例提供了多种组件,例如个人助理、文档问答、聊天机器人、查询表格数据、与 API 交互、提取、评估和汇总。通过提供模块化和灵活的方法简化了构建高级语言模型应用程序的过程。通过了解组件、链、提示模板、输出解析器、索引、检索器、聊天消息历史记录和代理等核心概念,可以创建适合特定需求的自定义解决方案。LangChain 能够释放语言模型的全部潜力,并在广泛的用例中创建智能的、上下文感知的应用程序。