- C/C++
- 编程技能
- 数据结构与算法
- ARM体系和结构
- 通信协议
- 应用编程和网络编程
- 应用编程
- 进程和线程的含义
- 进程、线程和协程的区别
- 进程调度算法即策略有哪些
- 有抢占式和非抢占式的区别
- 并发和并行的含义
- 多线程和多进程的特点
- 多线程和多进程的选择问题
- 创建进程的方式
- 守护进程的含义
- Fork wait exec函数的用法
- fork和vfork的区别
- 同步和异步的含义
- 进程的几种状态
- 进程间通信方式
- 进程间的通信中管道通信的实现原理
- 有名管道的通信方式
- 共享内存的操作方式
- 如何选择进程间的通信方式
- 僵尸进程、孤儿进程和守护进程的含义
- 僵尸进程的危害
- 如何杀死僵尸进程
- 如何实现守护进程
- 进程哪些情况会终止
- 系统包括哪些特殊进程
- 死锁的原因、产生条件和解决办法
- 内核线程和用户线程的含义
- 线程间的通信方式
- 信号量的含义和作用
- 线程和进程的同步方式有哪些?
- 进程和线程的中断切换过程
- 线程池创建原因和设计思路
- 线程池的线程数量和哪些相关
- 互斥锁的机制
- 互斥锁和读写锁的区别
- 单核机械上写多线程程序,是否考虑加锁?
- 多线程要注意什么
- 用什么样的方式可以减少数据竞争
- null
- 管道、信号量的实现方式和特性
- 有名管道和无名管道的区别
- 什么是线程的同步,什么是线程的异步,分别有什么样的使用场景
- 使用虚拟内存有什么样的优点
- 怎么建立虚拟地址和物理地址之间的映射
- 网络编程
- OSI网络模型
- HTTP的含义
- HTTP常见状态码
- GET 和 POST 有什么区别?
- HTTP有什么特点
- https用了什么机制来保证数据传输的安全性
- HTTP和HTTPS的区别
- 什么是TCP
- 什么是TCP连接
- TCP头部格式
- 为什么需要TCP
- 如何唯一确定一个 TCP 连接呢?
- 有一个 IP 的服务器监听了一个端口,它的 TCP 的最大连接数是多少?
- UDP 和 TCP 有什么区别呢?分别的应用场景是?
- TCP三次握手和四次挥手过程
- TCP2次握手,4次握手行不行,为什么要3次
- 第三次握手可以发送数据吗?
- 三次握手中每次握手信息对方没有收到会怎样?
- 三次挥手可以吗
- 为什么四次挥手时,客户端最后还要等待2MSL
- TCP头部结构
- TCP有什么样的特点
- Socket网络编程中使用函数
- TCP如何保证可靠性
- 阻塞的原因
- TCP阻塞控制
- TCP慢启动
- TCP滑动窗口(流量控制)和重传机制
- 滑动窗口过小会有什么影响
- TCP粘包和拆包的含义
- 粘包的原因
- 如何解决粘包和拆包
- TCP一次可以发一个数据包还是几个数据包
- UDP通信用到哪些函数,具体过程是怎样的
- TCP和UDP的区别
- TCP比UDP可靠的原因
- 什么时候使用TCP、什么时候用UDP
- IP地址的含义
- 子网掩码的含义
- 子网掩码的作用
- 如何判断两个IP地址释放在同一个网段
- IPv4和IPv6的区别
- 字节序有什么影响
- 应用编程
- Linux驱动
- 文件IO
- Linux内核
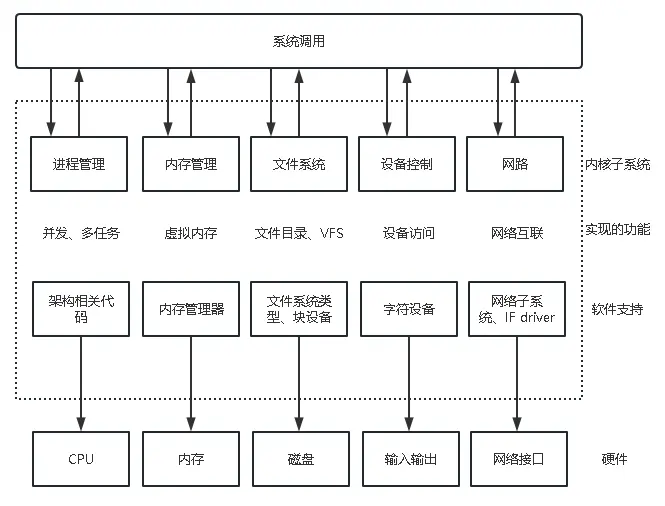
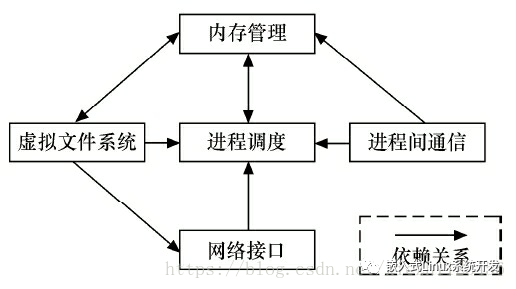
- Linux内核整体结构
- Linux内核的组成部分
- Linux系统的组成部分
- 用户空间与内核通信方式有哪些?
- 系统调用与普通函数调用的区别?
- 系统调用read()/write(),内核具体做了哪些事情
- 内核态,用户态的区别
- 什么是bootloader,uboot
- bootloader、内核 、根文件的关系
- Bootloader启动过程
- Bootloader启动的两个阶段
- 大小端的概念
- linux下检查内存状态的命令
- 一个程序从开始运行到结束的完整过程(四个过程)
- BSS段、数据段、代码段、堆和栈的含义
- 什么是堆,栈,内存泄漏,内存溢出和内存越界?
- 堆和栈的区别
- 死锁的原因、条件
- 死锁的四个条件及处理方法
- 硬链接与软链接
- linux下的文件有哪些组成?
- linux系统访问文件的步骤?
- 什么是inode
- inode大小
- 如何查看文件的inode等详细信息
- linux下文件类型和访问权限如何查看
- atime,mtime和ctime的含义
- inode有什么特别的作用吗?
- 虚拟内存,虚拟地址与物理地址的转换
- 计算机中,32bit与64bit有什么区别
- 中断和异常的区别
- 中断怎么发生,中断处理流程
- Linux 操作系统挂起、休眠、关机相关命令
- 说一个linux下编译优化选项
- 在有数据cache情况下,DMA数据链路为
- linux命令
- 硬实时系统和软实时系统
- MMU基础
- 项目
- 综合题
- 自我介绍
C/C++
C和C++的区别
答:
C是面向过程的编程语言,是一种结构化语言,偏重于数据结构与算法。
C++是面向对象的编程语言,偏重于构造对象模型并让该模型适配对应的问题。
关键字
continue和break的用法
答:
continue是用于跳过本次循环,并且只用于循环语句。而break是用于跳出本层循环语句或开关语句。但是在开关语句中case:后接break就是跳出开关语句,但完整的case语句后面接break不仅可以跳出开关语也可以跳出循环语句。
for(){switch case: break}//for循环不受影响
while(1)
{
switch(1)
case 1:printf("1\n");break;//跳出case语句和while循环
}
return的含义
答:
return就是main函数的返回值,是程序的退出状态码,用于指示程序的执行情况。在C语言中,main函数的返回值类型为int,可以返回任意整数值。
程序的退出状态码通常具有以下含义:
返回0表示程序正常结束。
返回正整数表示程序出现了错误或异常情况,具体的值可以表示不同的错误类型或错误码。
返回负整数表示程序被另一个进程或操作系统中止,具体的值也可以表示不同的中止原因或中止码。
程序的退出状态码可以被其他程序或操作系统捕捉并处理,例如Shell脚本可以根据程序的退出状态码来执行不同的操作。因此,main函数的返回值是程序的一个重要部分,应该根据程序的需求来选择合适的返回值。
另外需要注意的是,如果main函数没有显式地返回任何值,编译器会默认返回0作为程序的退出状态码。因此,即使程序没有显示地指定返回值,也应该在main函数中显式地返回0以表示程序正常结束。
goto的含义
答:
goto是无条件跳转语句,不建议使用。
Volatile的用法
答:
volatile是在预处理阶段告诉编译器:
1.该变量是随时都在变化
2.不用对其优化,每次取值都是从内存中取值而不是直接去取之前寄存器中的值
它常用于多线程编程、中断、硬件寄存器等。
//例子
int a=20,b,c;
b=a;//先从a的内存中取值存放到寄存器,再把寄存器的值给存到b的内存
C=a;//优化操作,把寄存器的值给存到c的内存
Volatile int a=20,b,c;
b=a;//先从a的内存中取值存放到寄存器,再把寄存器的值给存到b的内存
C=a;//不用优化操作,把内存中a的值给存到c的内存
/*
可以看出编译器对c=a这步进行优化,不再执行从a的内存中取值,而是直接从寄存器中取值,如果这段时间内a的发生变化,那么c就不能得到最新的值,这个时候就需要使用volatile告诉编译器,不要对变量a优化,每次都是从内存中取a的值
*/
const可以和volatile一起使用吗
答:
可以,const和volatile这两个类型限定符不矛盾。
volatile告诉编译器,该变量是容易变的(并不代表就一定会变)、不用优化的。
const则是说明只读变量,无法修改。这并不矛盾。
const表示(运行时)常量语义:被const修饰的对象在所在的作用域无法进行修改操作,编译器对于试图直接修改const对象的表达式会产生编译错误。
volatile表示“易变的”,即在运行期对象可能在当前程序上下文的控制流以外被修改(例如多线程中被其它线程修改;对象所在的存储器可能被多个硬件设备随机修改等情况):被volatile修饰的对象,编译器不会对这个对象的操作进行优化。
一个对象可以同时被const和volatile修饰,表明这个对象体现常量语义,但同时可能被当前对象所在程序上下文以外的情况修改。另外,LS错误,const可以修饰左值,修饰的对象本身也可以作为左值(例如数组)。
union和struct的区别
答:
联合体union的所有成员都是共享一块内存,而结构体struct是所有内存的叠加,有时候还需要考虑内存对齐的问题。对于联合体来说,修改某一个成员的数据就会导致其他成员的数据被修改,而结构体的成员之间是互不影响的。
union和struct的内存对齐问题
答:
在计算union和struct的占用多少内存时,需要考虑内存对齐的问题。
结构体:先看整体是多少(最大的数据类型字节)的整倍数,再看每个变量的偏移量是多少(必须是该变量类型的整数倍)
联合体:先看整体是多少(最大的数据类型字节)的整倍数,再看是否能容纳其他成员
结构体内存对齐的规则:
1.整体所占空间必须是成员变量中字节最大的整数倍;
2.每个变量类型的偏移量必须是该变量类型的整数倍;
3.如程序中有#pragma pack(n)预编译指令,则所有成员对齐以n字节为准(即偏移量是n的整数倍),不再考虑当前类型以及最大结构体内类型。
联合体内存对齐的规则:
1.union整体的字节数必须是占用字节最多的成员的字节的倍数,而且需要能够容纳其他的成员
2.对于联合体,由于所有变量都是共用一块内存,还需要注意数组占用最大内存,需要找到占用字节最多的成员。
比如:
Typedef union {double I;int k[5];char c;} DATE;
在联合体中成员变量最大的double为8个字节,所以最终大小必须是8的整数倍(1.所占空间必须是成员变量中字节最大的整数倍);又因为联合体是共占内存空间,即int*5=20字节(对于联合体,由于所有变量都是共用一块内存,还需要注意数组占用最大内存),所以最终为24个字节
Typedef struct data {int cat;DATE cow; double dog;}too;求sizeof(too);
解:在结构体里面联合体为24,联合体的最大类型为8字节,所以联合体的起始位置必须满足偏移量为8的倍数(4.如果里面有联合体,该联合体的起始位置要满足该联合体里面的最大长度类型的偏移量)(这里的起始位置为8),即4+(4)+24+8=40计算如下:
Cat:1-4 +(4)
DATE cow 8+24
Double dog 32+8=40
为什么要内存对齐?
答:
需要字节对齐的根本原因在于CPU访问数据的效率问题。
union判断大小端
答:
union是联合体,所有成员共享同一块内存。
大小端指的是大端字节序和小端字节序。其中,大端字节序是指数据的高字节存放在低地址、低字节存放在高地址,小端字节序是指数据的低字节存放在低地址、高字节存放在高地址。
我们通常可以使用联合体union数据之间共享内存的特点判断大小端:
//新建一个联合体,这个联合体由short和char数组组成
union my{
short t;
char b[2];
};
typedef union my MY;
int main(){
MY test;//建立联合体
test.t = 0x0102;//给short赋一个值
//判断存放规则
if(test.b[0] == 0x01 && test.b[1] == 0x02){//高字节存放低地址
printf("这是大端字节序\n");
}
if(test.b[0] == 0x02 && test.b[1] == 0x01){//高字节存放高地址
printf("这是小端字节序\n");
}
return 0;
}
大小端转换
大小端的不同之处在于数据的存放方式不同。那么大小端转换问题其实只需要改变数据的存放位置。一般常用位移操作移动数据,比如:
value&(需要移动的位置1)<<(位左移)或>>(位右移) | value&(需要移动的位置2)<<(位左移)或>>(位右移)
/*
把0-7位移动到24-31位
8-15位移动到16-23位
16-23位移动到8-15位
24-31位移动到0-7位
*/
value=((value & 0x000000ff)<<24)|
((value & 0x0000ff00)<<8)|
((value & 0x00ff0000)>>8)|
((value & 0xff000000)>>24);
空的struct
答:
C++ 中大小为1,而C中为0
在C++ 中修改大小为1:
空结构体(不含数据成员)的sizeof值为1。试想一个“不占空间“的变量如何被取地址、两个不同的“空结构体”变量又如何得以区分呢,于是,“空结构体”变量也得被存储,这样编译器也就只能为其分配一个字节的空间用于占位了。
struct在C和C++的区别
答:
1.C中struct中不允许有函数,C++可以
2.C中struct不可以继承,C++可以
3.C中结构体是必须加上struct ,C++可以省略
4.C中权限默认是公有的,C++可以修改
5.C中不可以初始化数据成员,C++可以。
struct和class的区别
答:
从访问权限来看:class作为对象的实现体,默认是私有访问;而struct是作为数据结构的实现体,默认是共有访问
从继承权限来看:class默认是私有;而struct默认是公有
class可以定义模板,而struct不能。
enum的含义
答:
enum是枚举变量类型,它会自动给变量赋值,该值是上一个枚举变量值+1。
typedef的含义
答:
typedef是关键字,在编译时处理。在作用域内给一个数据类型起一个别名。
typedef和#define的区别
答:
typedef是关键字,在编译时处理。在作用域内给一个数据类型起一个别名。它拥有类型检查功能。而#define是预处理指令,在预处理时进行简单的字符替换,不作正确性检查,只有在编译时才可能报错。
const的用法
答:
const是常量(只读变量)。它常用于修饰变量、函数的参数、函数的返回值、指针等。
1.修饰变量、函数参数、函数返回值。表示该变量、函数参数、函数返回值是不可修改的,是只读的。
2.修饰指针。需要注意修饰的是指针本身还是指向的内存空间。
3.不是真正意义上的常量,是只读变量。不可作为数组索引和跟着case。
4.修饰类中的函数和对象。常对象只能调用常函数,常函数不能是虚函数。
5.变量存放的位置。局部变量存放在栈中、全局变量存放在只读数据段(静态区)。
extern ”C“的含义
答:
extern是在链接阶段告诉编译器在其他文件定义了该变量,类似函数声明,不能初始化。
而extern "C"的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上extern "C"后,会指示编译器这部分代码按C语言(而不是C++)的方式进行编译。
C和C++编译方式不同举例:
由于C++支持函数重载,因此编译器编译函数的过程中会将函数的参数类型也加到编译后的代码中,而不仅仅是函数名;而C语言并不支持函数重载,因此编译C语言代码的函数时不会带上函数的参数类型,一般只包括函数名。
Register的含义
答:
变量存在寄存器里面,即cpu,该值不能取地址操作,并且是整数,不能是浮点数。
Auto的含义
答:
一般情况下我们没有特别说明的局部变量都是默认为auto类型,存储在栈中。
static的用法
答:
static可以修饰变量、函数。
1.修饰变量。
它分为静态全局变量和静态局部变量。静态全局变量和全局变量差不多,可以被初始化,也有记忆,但是却被限定了只能在本文件中使用。静态局部变量和局部变量不一样,static修饰的静态局部变量是不会随函数结束而结束,是保留记忆的,但是该变量只能在该函数中使用,虽然它存在,但是别人不能使用,因为它毕竟是局部变量,限定了作用域。
另外,还可以修饰类中的成员变量。类中的静态成员变量拥有一块独立的内存空间,不会占用类中的空间,所有对象都共享该静态成员变量。需要注意的是,它不能在类中初始化(防止每次创建对象都被重新初始化)。可以用this访问。
2.修饰函数。
可以在函数的返回值前加上static关键字,定义为静态函数,它只能在本文件使用。
另外,还可以修饰类中的成员函数。静态成员函数是类的一部分,但是不是对象的一部分,所有对象的静态数据成员都共享这一块静态存储空间。需要注意的是,静态成员函数不属于任何一个对象,因此C++规定静态成员函数没有this指针。既然它没有指向某一对象,也就无法对一个对象中的非静态成员进行访问,即不能在静态函数里面使用this指针。(静态成员函数只能访问静态成员变量。)
静态局部变量和静态全局变量的区别
答:
静态局部变量是由关键字static修饰定义的。它是局部变量,其作用域只在定义的函数体内。其次,它是由static修饰的静态变量,只初始化一次,在函数结束运行后它依然存在。
静态全局变量和全局变量差不多。但是作用域只是本文件,不可使用extern引入到其他文件。
sizeof和strlen()
答:
sizeof是关键字,它是用来计算占用内存大小,算\0,编译时计算。
strlen()是函数,它是用来计算字符串的长度,不计算\0,运行时计算。
sizeof的用法
1.strlen(“\0”) 与 sizeof(“\0”);
printf("%d\n",sizeof("\0"));//2 因为这里有\0\0
printf("%d\n",strlen("\0"));//0
printf("%d\n",sizeof("\0"));//2
printf("%d\n",strlen("\0"));//0
printf("%d\n",sizeof('\0'));//4
//printf("%d\n",strlen('\0'));//报错
2.sizeof(a++)
int a = 2;
printf("%d\n",sizeof(a++)); //4
printf("%d\n",a); // a = 2
//sizeof只会求所占内存大小,不会进行表达式运算
3.sizeof(void)
出错或为1,看编译器。
explicit的用法
答:
- 指定构造函数或转换函数 (C++11起)为显式, 即它不能用于隐式转换和复制初始化。
- 可以与常量表达式一同使用. 当该常量表达式为 true 才为显式转换(C++20起)。
类和对象
什么是面向对象
答:
面向对象是种编程思想,把一切东西看成一个对象,这个对象拥有自己的属性,我们把对象拥有的属性变量和操作这些属性变量的函数打包成一个类来表示。
面向过程和面向对象的区别
答:
面向过程是按照业务逻辑从上到下的写代码,它强调流程化,线性化,步骤化的思考方式。也就是解决一个问题,我们需要按照逻辑一步一步的去解决。
而面向对象是将数据和函数绑定在一起,进行封装。它将任何事物看做一个有机统一的整体来研究,然后通过派生的方式实现差异性来降低高耦合的可能性;这样就可以快速的开发程序,减少了重复代码。
面向对象的三大特征是哪些?有什么特点?
答:
面向对象的三大特征是继承、封装和多态。
1.继承是指一个新类可以从现有的类中派生。派生类保留了基类的特性,它很好的解决了代码重用性问题。我们还可以在派生类里添加符合自己需求的成员变量或函数。
(1)其中,类的继承方式包括三种公有、保护和私有。根据继承方式的不同,派生类对基类成员的访问权限也不同。基类的私有成员,派生类无论如何都无法访问;根据继承方式的不同,派生类对基类保护和公有成员的访问权限发生对应变化(私有继承->全变私有成员,保护继承->全变保护成员)。
(2)另外,类的继承方式影响对应对象的访问权限。类中可以直接访问自己的所有成员,类对应对象只能访问自己类的公有成员。只有公有继承方式,子类对象才可以访问基类的公有成员,其他均不可。
2.封装是指将数据和操作数据的反复结合起来,隐藏实现细节,仅对外提供交互接口。它很好的保护了模块的独立性,利用后续的维护修改。
3.多态是指用父类的指针指向子类的实例,然后通过父类的指针调用子类的成员函数。一般有重载和重写。
(1)重载(静态多态):是类中有多个同名函数,但是参数的数量或类型不同。在编译期完成。重载不关心函数返回类型。
(2)重写(动态多态):是派生类对基类的同名函数进行覆盖,由virtual修饰。基类必须有虚函数,派生类必须覆盖虚函数;通过基类类型的指针或者引用来调用虚函数。override关键字可强调该函数被派生类重写了。
空的类都有哪些函数
(1)无参的构造函数
(2)构造拷贝函数
(3)析构函数
(4)赋值运算符
(5)取址运算符
(6)const取址运算符
没有参数的函数能不能被重载
答:
可以。没有参数的函数也是可以被重载的,定义为常量函数。只不过要想使用,那么对象也必须是const。
class A
{
public:
void f()
{
cout << 1 << endl;
}
void f() const //没有参数的函数也是我可以被重载的,只不过要想使用,那么对象也必须是const
{
cout << 2 << endl;
}
};
int main()
{
A a;
const A b;
a.f(); //1
b.f(); //2
return 0;
}
基类的构造函数和析构函数能不能被继承?
答:
不能。构造函数和析构函数是跟对象的创建与消亡的善后工作相关。我们所创建派生类的对象,虽然和基类的对象有相同之处,但是仍然是不同的对象。所以,适用于基类的构造函数和析构函数不可能完全满足派生类对象的创建和消亡的善后工作。因此,构造函数和析构函数不被继承。
阻止类被实例化???
答:
可以通过使用抽象类(抽象类不能生成对象),或者将构造函数声明为private。抽象类之所以能被实例化,是因为抽象类不能代表一类具体的事物,它是对多种相似的具体事物的共同特征的一种抽象。
什么函数不能被声明为虚函数
答:
非成员函数,构造函数,内联成员函数,静态成员函数,友元函数。
因为非成员函数,也就是普通函数,只能被重载,不能被重写,而且普通函数也没必要声明为虚函数,所以编译器在编译时绑定函数(所以普通函数是静态绑定)。
因为从定义来看,定义成虚函数就是在不完全了解细节的情况下处理对象,而构造函数不就是明确初始化对象成员,顺序是不对的,相违背的。
因为内联函数是在编译时就展开,而虚函数是动态绑定的,在运行时才动态的绑定函数。时间上不允许。
因为静态成员函数是对于每个类只有一份代码,所有对象共享这一份代码,没必要进行动态绑定。
因为友元函数没有继承特性。
友元的含义
答:
一种可以访问private和protect权限的成员的方法。
私有成员只能在类的成员函数内部访问,如果想在别处访问对象的私有成员,只能通过类提供的接口(成员函数)间接地进行,这固然能够带来数据隐藏的好处,利于将来程序的扩充,但也会增加程序书写的麻烦。
友元有两种形式,友元类和友元函数。
通过friend定义,友元函数可以直接访问类中的私有和保护成员。
通过friend定义,友元类可以直接对应类中的私有和保护成员。
破坏了类的封装性和数据的透明性。
另外,需要注意的是:
(1) 友元关系不能被继承。
(2) 友元关系是单向的,不具有交换性。若类B是类A的友元,类A不一定是类B的友元,要看在类中是否有相应的声明。
(3) 友元关系不具有传递性。若类B是类A的友元,类C是B的友元,类C不一定是类A的友元,同样要看类中是否有相应的申明。
友元函数为什么不能继承
答:
友元只是能访问指定类的私有和保护成员的自定义函数,不是被指定类的成员,自然不能继承。
纯虚函数的含义
答:
它代表函数没有被实现。定义纯虚函数是为了实现一个接口,起到一个规范的作用,规范继承这个类的程序员必须实现这个函数。纯虚函数永远不会被调用。
含有纯虚函数的类称为抽象类,抽象类不能生成对象。
抽象类的含义
答:
抽象类是指在一个类中包含纯虚函数,这样的类不能被直接实例化。
抽象类只能作为基类使用,它的纯虚函数(方法)均由派生类进行实现。抽象类是一种特殊的类,它是为抽象和设计的目的建立。通常位于类继承层次结构的上层,为下面的派生类提供一个通用的接口,仅用来输出不同的结果。而具体的实现与操作由它的子类进行实现。
浅拷贝和深拷贝的含义
答:
浅拷贝是指编译系统在没有自己定义拷贝构造函数的时候,会调用默认拷贝构造函数。但是当该类持有特殊的资源时,比如动态分配的内存、指向其他数据的指针等,自动生成的拷贝构造函数就不会拷贝这些资源。这个时候,就需要我们手动并显式地定义可以拷贝这些资源的拷贝构造函数,即进行深拷贝。
深拷贝是指自己显式地定义拷贝构造函数,将对象所持有的其它资源一并拷贝的行为叫做深拷贝。
简单理解就是浅拷贝就是对指针本身拷贝(拷贝地址),而深拷贝不仅拷贝指针还拷贝指针指向的内容(拷贝内容)。注意的是经浅拷贝后两个指针指向同一个内存空间,经深拷贝后的指针是指向两个不同地址的指针。
如何区分浅拷贝和深拷贝
答:
简单点来说,就是定义两个指针A和B,假设B复制了A,当修改A指针时,看B指针指向的内容是否会发生变化,如果B指针指向的内容也跟着变了,说明这是浅拷贝; 如果B指针指向的内容没变,那就是深拷贝。
成员变量初始化顺序
C++标准规定:
1.类成员变量通过构造函数体初始化时,初始化顺序由构造函数体中的变量初始化顺序决定,与类成员变量的定义顺序无关系。
2.类成员变量通过初始化列表初始化时,与构造函数中的初始化列表中的变量顺序无关,只与定义成员变量的顺序有关。因为成员变量的初始化次序是根据变量在内存的次序有关系,而变量的内存排列顺序,早在编译期就根据变量的定义次序决定了。
3.在类构造函数中,如果初始化列表和构造函数体同时对一个变量进行了初始化,列表初始化会优先得到执行,接着才会执行构造函数体中的变量初始化。
4.C++11类内部初始化,优先于任何构造函数初始化成员变量。内部初始化后,如果构造函数不显示重新初始化成员变量默认值,成员变量将保持内部初始化值默认值;如果构造函数显示重新初始化成员变量默认值,成员变量将保持构造函数重新赋值。
内部初始化->初始化列表初始化(按定义时变量的次序)->构造函数初始化(函数体内定义顺序)
静态static成员变量:
1.静态成员变量不应该在内部初始化,需要在内外部显示初始化,除非声明此静态成员变量为static const或constexpr类型,但初始值必须是常量或常量表达式。
哪些情况只能初始化列表,不能赋值?
答:
在c++中赋值就是删除原值,赋予新值,初始化列表是开辟空间和初始化同时完成。
1.类中的const ,引用成员变量时,只能初始化
2.若成员类型是没有默认构造函数的类,只能使用初始化列表
3.派生类在构造函数中要对自己的自身成员初始化,也要对继承过来的基类成员进行初始化,当基类没有默认构造函数的时候,通过在派生类的构造函数初始化列表中调用基类的构造函数初始化。
STL
vector的底层实现原理
答:
vector定义了三个指针start(表示目前使用空间的头)、finish(表示目前使用空间的尾)、end_of_storage(表示目前可用空间的尾)。vector中判断是否要开辟空间的条件就是“finish == end_of_storage”,但满足这个条件的时候用户还想插入新的元素就需要调用reserve函数开辟空间来存放新的元素。
函数
strcat、strncat、strcmp、strcpy哪些函数会导致内存溢出?如何改进?
答:
strcpy函数会导致内存溢出。
strcpy拷贝函数不安全,他不做任何的检查措施,也不判断拷贝大小,不判断目的地址内存是否够用。
char *strcpy(char *strDest,const char *strSrc)
strncpy拷贝函数,虽然计算了复制的大小,但是也不安全,没有检查目标的边界。
strncpy(dest, src, sizeof(dest));
strncpy_s是安全的
strcmp(str1,str2),是比较函数,若str1=str2,则返回零;若str1<str2,则返回负数;若str1>str2,则返回正数。(比较字符串)
strncat()主要功能是在字符串的结尾追加n个字符。
char * strncat(char *dest, const char *src, size_t n);
strcat()函数主要用来将两个char类型连接。例如:
char d[20]="Golden";
char s[20]="View";
strcat(d,s);
//打印d
printf("%s",d);
输出 d 为 GoldenView (中间无空格)
延伸:
memcpy拷贝函数,它与strcpy的区别就是memcpy可以拷贝任意类型的数据,strcpy只能拷贝字符串类型。
memcpy 函数用于把资源内存(src所指向的内存区域)拷贝到目标内存(dest所指向的内存区域);有一个size变量控制拷贝的字节数;
函数原型:
void *memcpy(void *dest, void *src, unsigned int count);
空的类都有哪些函数
(1)无参的构造函数
(2)构造拷贝函数
(3)析构函数
(4)赋值运算符
(5)取址运算符
(6)const取址运算符
构造函数有几种?
答:
默认构造函数、有参构造函数、拷贝构造函数、移动构造函数、复制赋值运算符、移动赋值运算符
默认构造函数是如果没有定义构造函数,则编译器会自动提供默认构造函数。
有参构造函数带参数的构造函数可以用来初始化对象的成员变量,可以接受一个或多个参数。是对默认构造函数的重载。
拷贝构造函数是拷贝其他对象的构造函数。如果没有定义拷贝构造函数,则编译器会自动提供默认拷贝构造函数。参数是同类型的另一个对象的引用。
移动构造函数是将一个临时对象转移给一个新对象,避免不必要的拷贝操作。参数是同类型的另一个对象的右值引用。
1.默认构造函数
没有任何参数的构造函数被称为默认构造函数。如果没有定义构造函数,则编译器会自动提供默认构造函数。默认构造函数可以用来创建对象,但是不能传递任何参数。
class MyClass {
public:
MyClass() {
// 这里可以对成员变量进行初始化
}
};
2.带参数的构造函数
带有一个或多个参数的构造函数被称为带参数的构造函数。带参数的构造函数可以用来初始化对象的成员变量,可以接受一个或多个参数。
class MyClass {
public:
MyClass(int a, int b) {
// 这里可以对成员变量进行初始化,使用参数a和b
}
};
3.拷贝构造函数
(拷贝其他对象的构造函数)
用于从一个已经存在的对象中创建一个新的对象的构造函数被称为拷贝构造函数。拷贝构造函数接受一个参数,这个参数是同类型的另一个对象的引用。它通常用于在函数参数传递或返回对象时,或者在对象赋值时进行对象的拷贝。
class MyClass {
public:
MyClass(const MyClass& otherClass) {
// 这里可以从另一个同类型的对象other中拷贝成员变量的值
}
};
4.移动构造函数
用于从一个已经存在的临时对象中创建一个新的对象的构造函数被称为移动构造函数。它通常用于在对象的值被转移(比如将一个临时对象转移给一个新对象)时,避免不必要的拷贝操作,从而提高代码的性能。
class MyClass {
public:
MyClass(MyClass&& otherClass) {
// 这里可以从另一个同类型的临时对象other中移动成员变量的值
}
};
5.复制赋值运算符
复制赋值运算符用于将一个对象的值赋给另一个对象。它是一个函数,它接受一个同类型的参数,并返回一个同类型的引用。如果没有定义复制赋值运算符,则编译器会自动生成一个默认的复制赋值运算符。
class MyClass {
public:
MyClass& operator=(const MyClass& otherClass) {
// 这里可以将另一个同类型的对象other的值赋给自己的成员变量
return *this;
}
};
6.移动赋值运算符
移动赋值运算符用于将一个临时对象的值转移到一个新的对象中。它是一个函数,它接受一个同类型的参数,并返回一个同类型的引用。它通常用于在对象的值被转移时,避免不必要的拷贝操作,从而提高代码的性能。
class MyClass {
public:
MyClass& operator=(MyClass&& otherClass) {
// 这里可以从另一个同类型的临时对象other中移动成员变量的值到自己的成员变量
return *this;
}
};
多重继承情况下的类对象的初始化顺序
答:
父类构造函数–>成员类对象构造函数–>自身构造函数
成员变量初始化顺序
答:
C++标准规定:
1.类成员变量通过构造函数体初始化时,初始化顺序由构造函数体中的变量初始化顺序决定,与类成员变量的定义顺序无关系。
2.类成员变量通过初始化列表初始化时,与构造函数中的初始化列表中的变量顺序无关,只与定义成员变量的顺序有关。因为成员变量的初始化次序是根据变量在内存的次序有关系,而变量的内存排列顺序,早在编译期就根据变量的定义次序决定了。
3.在类构造函数中,如果初始化列表和构造函数体同时对一个变量进行了初始化,列表初始化会优先得到执行,接着才会执行构造函数体中的变量初始化。
4.C++11类内部初始化,优先于任何构造函数初始化成员变量。内部初始化后,如果构造函数不显示重新初始化成员变量默认值,成员变量将保持内部初始化值默认值;如果构造函数显示重新初始化成员变量默认值,成员变量将保持构造函数重新赋值。
内部初始化->初始化列表初始化(按定义时变量的次序)->构造函数初始化(函数体内定义顺序)
静态static成员变量:
1.静态成员变量不应该在内部初始化,需要在内外部显示初始化,除非声明此静态成员变量为static const或constexpr类型,但初始值必须是常量或常量表达式。
为什么析构函数最好必须是虚函数
答;
主要是考虑继承时子类内存释放问题。
比如,将可能会被继承的父类的析构函数设置为虚函数,可以保证当我们new一个子类,然后使用基类指针指向该子类对象,释放基类指针时可以释放掉子类的空间,防止内存泄漏。
比如:
当A为基类,B为A的继承类,考虑如下情况:
A *p = new B();
.....
delete p;
如果此时A的析构函数不是虚函数,那么在delete p的时候就会调用A的析构函数,而不会调用B的析构函数,这样就会造成B的资源没有释放。
而如果A的析构函数为虚函数,那么就会调用B的析构函数,一切正常。
为什么默认析构函数不是虚函数
答:
当一个类中有虚函数时,类会自动生成一个虚函数表和虚指针。虚函数表保存虚函数的地址,虚指针指向虚函数表,这会占据一定内存。当默认定义的类没有被其他类继承时,是不需要这种内存开销的。所以默认析构函数没必要是虚函数。
静态函数和虚函数的区别
答:
静态函数在编译时就已经确定。
虚函数是在运行的时候动态绑定,而且使用了虚函数表机制,调用的时候会新建虚函数表和虚函数指针,额外增加一次内存开销。
虚函数表如何实现运行是多态
答:
主要是通过虚函数表。首先虚函数表是一个类的虚函数的地址,每个对象在创建时,都会有一个虚函数指针指向该类的虚函数表,每一个类的虚函数表按照函数声明的顺序,会将函数地址存在虚函数表里,当子类对象重写父类的虚函数时,父类的虚函数表中对应的虚函数的地址就会被子类的虚函数地址覆盖。
内联函数和宏函数的区别
答:
内联函数:
(1)本质上是一个函数,它一般用于函数体代码比较简单的函数,并且不能递归。
(2)在编译的时候进行代码插入,编译器会在每处调用内联函数的地 方直接把内联函数的内容展开,这样可以省去函数的调用的开销,提高效率。
(3)编译时进行类型检查。
宏函数:
(1)是宏定义,它不是函数。
(2)宏函数在预处理的时候把所有的宏名用宏体替换,只是简单的字符替换。
(3)没有类型检查。
内联函数和普通函数的区别
答:
内联函数:
(1)不需要寻址,直接原地将函数张开
(2)函数代码可能会有很多次复制。
普通函数:
(1)在调用时会寻址到函数入口,执行函数,返回返回值
(2)函数代码只有一个复制。
空对象指针为什么能调用函数
简单地说就是,给函数传递了this参数并设为NULL,但在该函数内部并没有使用该参数,所以不影响函数的运行。只要你不访问 this 指针,就不会报错。
具体来说就是,空对象指针在调用非虚成员函数时,在编译器编译时就静态绑定了,而在运行期才查看指针是否是空指针(使用指针)。
内存管理
内存模型是怎么样的
C++的内存管理方式
答:
在c++中虚拟内存分为代码段、数据段(静态全局存储区)、BSS段、堆、映射区(共享区)、栈。
1.代码段:包括只读存储区和文本区,其中只读存储区存储字符串常量,文本区存储程序的机械代码
2.数据段(静态全局存储区):全局变量、静态变量(全局、局部)
3.BSS段:未初始化的全局变量和静态变量(全局、局部),以及所有被初始化为0的全局变量和静态变量
4.堆:调用new/malloc申请的内存空间,地址由低地址向高地址扩张
5.映射区:存储动态链接库以及调用mmap函数的文件映射
6.栈:局部变量、函数的返回值,函数的参数,地址由高地址向低地址扩张
malloc、free,new、delete的用法
答:
1.malloc和free是c++/c语言的库函数,需要头文件支持stdlib.h;new和delete是C++的运算符,不需要头文件,需要编译器支持;
2.使用new操作符申请内存分配时,无需指定内存块的大小,编译器会根据类型信息自行计算。而malloc则需要显式地支持所需内存的大小。
3.new操作符内存分配成功时,返回的是对象类型的指针,类型严格与对象匹配,无需进行类型转换,故new是符合类型安全性的操作符。而malloc内存分配成功则是返回void*,需要通过强制类型转换将void * 指针转换成我们需要的类型。
4.new先为对象申请内存空间,让后再调用构造函数进行初始化,同理delete可以调用析构函数释放内存,而 malloc只是申请内存空间并不能调用构造函数进行初始化,同理free也只是释放内存
5.new内存分配失败时,会抛出bad_alloc异常。malloc分配内存失败时返回NULL。
malloc、calloc、realloc、reallocarray的用法
答:
都是申请堆内存。
malloc是申请sizeof()个字节内存,free是释放指针指向的内存,指针还是可用的;
calloc申请nmemb块内存,每一块sizeof()个字节;初始化内存空间为0.
realloc重新为指针申请sizeof()个字节内存;sizeof()大于原来申请的空间大小,那如果原来内存还有空间那么继续申请sizeof()-原来大小,不够空间则重新找一块内存。sizeof()小于原来申请的空间大小,释放原来大小-sizeof()
reallocarray重新申请nmemb块内存,每一块sizeof()个字节;
内存分配的方式
答:
局部变量存放在栈上,函数执行完毕自动释放。
全局变量和静态变量存放在静态全局存储区。
动态分配的存放在堆上,需要手动释放。
栈的用处
答:
1.用来保存临时变量,临时变量包括函数内部定义的临时变量,函数参数,函数的返回值
2.多线程编程的基础就是栈,每个线程多最少都有自己专属的栈,用来保存本线程运行时各个函数的临时变量。
栈内存最大是多少
答:
windows是2MB,Linux是8MB
可使用ulimit -s查看
函数参数压栈顺序是怎样的
答:
从右往左,并且内存中栈是由高向低扩展,所以先入栈的是右边并且地址是高位
比如printf()函数,也都是先打印最右边。
堆和栈的区别
答:
1.申请方式不同。
2.申请的大小限制不同。
3.申请的效率不同。
堆栈溢出的原因
答:
堆是保存动态分配的内存、栈是保存局部变量、函数参数、和函数返回值。
1.函数调用层次太深,返回了太多的返回值,导致栈无法容纳这些返回地址。
2.数组访问越界
3.动态分配的内存没有释放
4.指针保存了非法的地址
内存泄漏的含义
答:
简单来说就是申请了内存,不使用之后并没有释放内存,或者说,指向申请的内存的指针突然又去指向别的地方,导致找不到申请的内存
内存泄漏的影响
随着程序运行时间越长,占用内存越多,最终用完内存,导致系统崩溃。
避免内存泄漏
1.良好的编码习惯,使用内存分配的函数,一但使用完毕之后就要记得使用对应的函数是否掉
2.将分配的内存的指针以链表的形式自行管理,使用之后从链表中删除,程序结束时可以检查改链表
3.使用智能指针
4.使用常见插件,ccmalloc
内存对齐问题
答:
需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐
常见就是求复合类型大小,比如结构体、联合体 。
为什么需要内存对齐
需要字节对齐的根本原因在于CPU访问数据的效率问题
比如:
C++11
C++ 11的新特性
(1)auto,增加了auto关键字的功能,可以实现自动分析数据的类型。
(2)decltype,增加了decltype关键字,可以查看并返回数据的类型。
(3)nullptr,增加nullptr,可以用来初始化空指针并且可以转换成其他任意类型的指针。
(4)constexpr,增加了constexpr关键字,可以用来让编译器验证变量是否是一个常量表达式
(5)for,增加了范围for语句,可以遍历指定序列的每个元素
(6)Lambda表达式,可以作为无名的内联函数。
(7)initializer_list,此类型用于访问c++初始化列表中的值,列表中的元素类型为const的,也就是常量
(8)bind函数,会将两个函数绑定起来,同时传递参数。
(9)智能指针shared_ptr,unique_ptr,可以更好地管理和使用动态内存,防止内存泄漏和野指针。shared_ptr,多个智能指针指向同一个对象,而unique_ptr只容许一个指针独自指向一个对象。
(10)右值引用&&,我们可以将右值引用进行分类。首先一类右值引用是将亡值,也就是马上要销毁的值,一般指的是跟右值引用相关的表达式,这样的表达式是要被销毁的对象。另外一类是纯右值,例如按值返回的临时对象,运算表达式产生的临时对象,原始字面值,lambda等。
(11)内部初始化,内部初始化会在成员变量声明时,同时实现成员变量的初始化工作
编程技能
GDB
//GDB断点
b src/*.cpp:行数 //某一行设置断点
b src/*.cpp:行数 if cnt==10 //某一行设置条件断点
b *0x400522或者b &变量名 //设置数据断点,某一个变量发生变化
b funcname //函数断点,对静态函数和内联函数无效
info breakpoints //参考断点信息
d 断点编号1 断点编号2 //删除断电
//GDB监视
//监视可以监测栈变量和堆变量值的变化,当被监测变量值发生变化时,程序被停住。
watch *地址/var/(condition) //监视(硬件断点)
GDB常见调试命令
答:
在编译的时候必须加上参数-g
Gcc main.c -g -o ma in
多进程下如何调试
答:
多进程下如何调试:用set follow-fork-mode child 调试子进程
或者set follow-fork-mode parent 调试父进程
条件断点的含义
答:
条件断点:break if 条件 以条件表达式设置断点
Git
Mysql
基本概念
数据库三范式:
- 数据库表中的字段都是单一属性,不可再分。强调的是列的原子性;数据库表的每一列都是不可分割的原子数据项;
- 要求数据库表中的每个实例或行必须可以被唯一区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。这个唯一标识属性列被称为主键
- 确保每列都和主键列直接相关,而不是间接相关不存在其他表的非主键信息;
DML:数据操作语言,用于检索或者修改数据。我们平常最常用的增删改查就是DML;
DDL:数据定义语言,用于操作数据结构,比如创建表,删除表,更改索引都是DDL;
DCL:数据控制语言,用于定义数据库用户的权限,比如创建用户,删除用户都是DCL;
常见数据库
MySQL是一个传统的关系型数据库。广泛应用于OLTP场景(支持事务)
OLTP:联机事务处理,是传统的关系型数据库的主要应用,用于基本的事务处理;【日常处理】
OLAP:联机分析处理,数据仓库系统的主要应用;支持复杂的分析操作,侧重决策支持,并且提供易懂的查询结果;【专业数据分析】
mysql特性
存储引擎
存储引擎是MySQL将数据存储在文件系统中的存储方式或者存储格式
show ENGINEs;//查看当前服务器支持的存储引擎
1.MyISAM引擎:不支持事务,也不支持行级锁和外键 约束,只支持全文索引,数据文件和索引文件是分开保存的。特点:访问速度快,只适合查询或插入为主的应用
2.InnoDB引擎:提供了对数据库ACID事务的支持,并且还提供了行级锁和外键的约束。
3.MEMORY引擎:所有数据都在内存中,数据处理速度快,但是安全不高;
数据类型
数值型
TINYINT 1
SMALLINT 2
MEDIUMINT 3
INT 4
BIGINT 8
FLOAT 4
DOUBLE 8
DECIMAL
字符串型
CHAR 定长字符串
CARCHAR 变长字符串
TINYBLOB
TINYTEXT
BLOB 二进制的文本数据
TEXT 长文本数据
...
日期和时间型
YEAR 1
TIME 3
DATE 3
DATETIME 8
TIMESTAMP 4
约束
primary key :主键约束
主键约束就是用来标识表中的数据,避免出现重复的数据,被主键约束所修饰的'列',其列值是唯一且非空的,而且一张表中只能有一个主键约束
unique:唯一约束
唯一约束就是用来修饰一列或者多列的组合值,使其具有唯一性,防止用户输入重复的数据
default:默认值约束
默认值约束是用来知道某列的默认值,当执行插入操作的时候,如果该列没有插入列值,系统会自动把默认值编程列值,每列只能设置一个默认值
not null:非空约束
非空约束就是在执行插入操作时候,被非空约束所修饰的列,列值不能为空
常用操作命令
数据库操作
//创建数据库
CREATE DATABASE mydatabase;
//show查看数据库
show mydatabase;
//创建表
CREATE TABLE users (
id varchar(100) primary key,
passwd varchar(100) not null,
status int DEFAULT 0
);
//删除表
DROP TABLE users;
//SELECT查看表
SELECT * FROM users;
DESCRIBE users;
SELECT *
FROM users
LIMIT 5,5;//返回第5行开始的5行数据(从0开始算,与数组一样)
SELECT users.id
FROM mydatabase.users;//完全限定的表名
数据操作
//去重
SELECT DISTINCT order_num
FROM OrderItems
//ORDER BY排序数据
SELECT id
FROM users
ORDER BY id;//按单列id的字母顺序小到大升序排序(默认ASC关键字)
SELECT id, score
FROM users
ORDER BY score, id;//按多列score,id升序排序,先看score,相同再看id
SELECT id
FROM users
ORDER BY id DESC////按单列id的字母顺序大到小降序排序
SELECT id, score
FROM users
ORDER BY score DESC, id;//按多列score降序排序,id升序排序,先看score,相同再看id
SELECT score
FROM users
ORDER BY score DESC
LIMIT 1;//通过排序和限制找到score的最大值
//WHERE过滤(搜索)
常用操作符:=(等于), <>或!=(不等于),BETWEEN(之间)
SELECT id, score
FROM users
WHERE score = 2.50;//返回score等于2.50的id和score
//组合WHERE子句,最好用括号
SELECT id,score
FROM users
WHERE score BETWEEN 5 AND 10;//返回score在5到10之间的id和score
SELECT id, score
FROM users
WHERE id = 5 OR id = 10;////返回id是5或10的id和score
//通过IN操作符
SELECT id, score
FROM users
WHERE id IN (5, 10);////返回id是5或10的id和score
SELECT id, score
FROM users
WHERE id NOT IN (5, 10);////返回id不是5或10的id和score
//用谓词LIKE+通配符&或_过滤
SELECT id, score
FROM users
WHERE id LIKE 'jet%';//使用搜索模式'jet%',搜索jet+任意字符的id(%代表任何字符出现任意次数, 0次也可,但是不能匹配NULL,区分大小写)
SELECT id, score
FROM users
WHERE id LIKE 'jet_';//使用搜索模式'jet_',搜索jet+一个字符的id(_代表任意一个字符, 区分大小写)
//用正则表达式REGEXP搜索
SELECT id
FROM users
WHERE id REGEXP '.000'
ORDER BY id;//正则表达式'.000',匹配任意一个字符
SELECT id
FROM users
WHERE id REGEXP '1|2'
ORDER BY id;//正则表达式1|2,|是正则表达式中的OR,匹配存在1和2的数据
SELECT id
FROM users
WHERE id REGEXP '[123] Ton'
ORDER BY id;//正则表达式[123] Ton,[]是正则表达式中的另一种形式的OR,是[1|2|3]的缩写,也可写成[1-3],只匹配单独存在1或2或3的数据
SELECT id
FROM users
WHERE id REGEXP '\\.'
ORDER BY id;//表示搜索.,对应其他的特殊字符\\f(换页),\\n(换行),\\r(回车),\\t(制表),\\v(纵向制表)
//字符类搜索
[:alnum:]
[:digit:]
//定位符
^文本开始,$文本结尾,[[:<:]]词开始,[[:>:]]词结尾
1.WHERE再ORDER BY
2.不区分大小写
3.NULL代表空值,与0不同
4.优先处理AND
5.IN更加方便,简单
6.NOT可对IN,BETWEEN,EXISTS和LIKE等子句取反
7.LIKE和REGEXP的区别,LIKE匹配整个列,REGEXP列值内进行匹配(可用^和$定位符实现LIKE的功能)
8.[123]和[1|2|3]的区别
//函数
//文本处理函数
SELECT id, Upper(id) AS id_upcase
FROM users
ORDER BY id;//id转换为大写并保存到id_upcase列中
//日期和时间处理函数
SELECT id
FROM users
WHERE Date(date) = '2005-09-01';
//数字处理函数
Abs()等
//聚焦函数
SELECT AVG(score) AS avg_score
FROM users;//返回值avg_score
SELECT COUNT(*) AS score_num
FROM users;//对表中行的数目进行计数,并在score_num中返回
//分组
//分组GROUP BY子句
SELECT id, COUNT(*) AS num
FROM users
GROUP BY id;//指定两个列id和num,计算每个id的数量并返回到num中(按组聚集)
//过滤分组HAVING子句
与WHERE类似,但HAVING过滤分组,WHERE过滤行
SELECT id, COUNT(*) AS orders
FROM users
GROUP BY id
HAVING COUNT(*) >= 2;//过滤了COUNT(*) >= 2的分组
//排序过滤分组
SELECT order_num, SUM(quantity*item_price) AS ordertotal
FROM orderitems
GROUP BY order_num
HAVING SUM(quantity*item_price) >= 50
ORDER BY ordertotal;//按order_num分组,按组过滤,按ordertotal排序
GROUP BY子句必须在WHERE子句之后,ORDER BY子句之前
其他的执行顺序:
from
where
group by
having
聚合函数
select
order by
//联结
主键:两个表共有的列名
外键:某个表的一列,它包含另一个表的主键值
可伸缩性:适应不断增加的工作量而不失败
内联结:inner join。取两列的交集。
//创建内联结
SELECT vend_name, prod_name, prod_price
FROM vendors INNER JOIN products
ON vendors.vend_id = products.vend_id;//INNER JOIN 两个表内联结,联结子句中用ON代替WHERE
外连接 (OUTER JOIN)分为三种
1. 左外连接 (LEFT OUTER JOIN 或 LEFT JOIN):左表的记录将会全部表示出来,而右表只会显示符合搜索条件的记录,右表记录不足的地方均为NULL
2. 右外连接 (RIGHT OUTER JOIN 或 RIGHT JOIN):与左(外)连接相反,右(外)连接,右表的记录将会全部表示出来,而左表只会显示符合搜索条件的记录,左表记录不足的地方均为NULL
3. 全外连接 (FULL OUTER JOIN 或 FULL JOIN):左表和右表都不做限制,所有的记录都显示,两表不足的地方用null 填充
MySQL中不支持全外连接,可以使用 UNION 来合并两个或多个 SELECT 语句的结果集
//创建外联结
SELECT customers.cust_id, order.order_num
FROM customers LEFT OUTER JOIN orders
ON customers.cust_id = orders.cust_id;//OUTER JOIN两个表外联结,必须指定LEFT或RIGHT指定包括其所有行的表
//组合查询
union all的使用
select prod_name
from Products
union all
select cust_name
from Customers
order by prod_name;//连接,前面的列名会保留
//在组合查询中,排序只能放在所有语句的最后,且出现一次。
//插入
INSERT INTO users VALUES(1,111);
Qstring sql = QString(" insert into users values(%1, %2, %3);").arg(id).arg(status).arg(passwd);
#include <QSqlQuery>
QSqlQuery query;
if(query.exec(sql))
{
QMessageBox::information(this, "提示","插入成功");
}else{
QMessageBox::information(this, "提示","插入失败");
}
//查找
QsqlQuery query;
query.exec("select * from users;");
while(query.next())
{
qDebug() << query.value(0); //注意类型
qDebug() << query.value(1);
qDebug() << query.value(2);
}
// 删除
QsqlQuery query;
query.exec("delete from users where id="1";");
索引
大家都知道加上索引sql语句会变快,为什么?这个问题大家却回答的没有逻辑性;
不过没关系,一一分析一下几个大问题
1、索引是什么
2、什么能够成为索引?
3、索引为什么能加快速度?
4、mysql的索引是什么,为什么选择B+Tree?
1.索引是什么?
索引你是一种特殊的文件,他们包含着对数据表里所有记录的引用指针;
索引是一种数据结构,而且索引是一个文件,是要占据物理空间的;
2.索引的优缺点
优点:
可以大大加快数据的检索速度;
通过使用索引,可以再查询的过程中,使用优化隐藏器,提高系统的性能;
缺点:
时间方面:创建索引和维护索引需要耗费时间,而且索引也需要动态的维护,会降低增/删/改的执行效率;
空间方面:索引需要占物理空间;
3.创建索引的方式
alter table table_name add index index_name(column_list);
create index index_name on table_name(column_list);
4.MySQL有几种索引类型?
普通索引:一个索引只包含单个列,一个表可以有多个单列索引;
唯一索引:索引猎德值必须是唯一的,但允许有空值;
复合索引:多列值组成一个索引,专门用于组合搜索,效率大于索引合并;
聚簇索引:并不是单独的索引类型,而是一种数据存储方式。InnoDB的聚簇索引都在同一个结构中保存了b+Tree和数据行;
非聚簇索引:不是聚簇索引,就是非聚簇索引;
5.索引的底层实现方式
Hash索引:对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,并且Hash索引将所有的哈希码存储在索引中,同时在索引表中保存指向每个数据行的指针;
B-Tree索引:
在这里插入图片描述
B+Tree
在这里插入图片描述
6.为什么索引结构默认选择B+Tree?(这种问题就是分析其他索引的缺点,说出B+Tree的优点即可)
Hash索引虽然可以快速定位,但是没有顺序,IO复杂度高;
MySQL基于Hash实现,只有Memory存储引擎显式支持哈希索引;
Hash不支持范围查询;
如果有大量重复键值的情况下,哈希索引的效率很低,以为存在哈希碰撞问题;
B+Tree非叶子节点不存储数据,只有叶子节点才存储数据;
B+树是为粗盘或其他直接存取辅助设备设计的一种平衡查找树。在B+树中,所有记录节点都是按照键值的大小顺序存放在同一层的叶子节点,各叶子节点之间通过双向链表进行连接;
锁
从锁粒度来讲:表级锁、行级锁
从强度上讲:共享锁/读锁、排它锁/写锁;
MySQL服务器层并没有实现行锁机制,行锁只在存储引擎层实现;
InnoDB支持行锁he表锁;而MyISAM支持表锁;
表锁
概念:顾名思义其实就是锁定整张表;不管什么存储引擎,对于表锁的策略都是一样的;是开销最小的锁机制;
优点:表锁直接锁定整个表,所以可以很好的避免死锁问题;
缺点:锁的粒度大带来的就是锁资源争用的概率也会最高,导致并发率降低;
行锁
概念:锁住某一行;
分类:
(1)记录锁:基于唯一索引的,锁住的是改行的索引记录;即使没有设置索引,也会有innodb自己的“隐式主键”来进行锁定;
(2)间隙锁:锁定一段范围内的索引记录
共享锁/读锁
允许事务读操作;多个事务在同一时刻可以读取同一个资源;
排它锁/写锁
一个写锁会阻塞其他的读锁和写锁,只有一个事务能执行写入,并防止其他用户读取正在写入的同一资源;
如何加锁
锁机制:InnoDB是可以随时加锁,但不代表可以随时解锁;只有事务commit或者rollback才可以释放锁,而且所有的锁在同一时刻被释放;
对于常见的DDL语句(create,alter)InnoDB会自动给相应的表加表级锁;
对于常见的DML语句(update,delete,insert)InnoDB会自动给相应的记录加写锁;
对于普通的select语句,InnoDB不会加任何锁;
InnoDB也支持通过特定的语句进行显示锁定:两种模式:
select …… lock in share mode加共享锁/读锁;
select …… for updates 加排它锁/写锁;
事务
特性:原子性,一致性,隔离性,持久性
原子性:原子性是指事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败;
一致性:事务必须使数据库从一个一致性状态变换到另外一个一致性状态,换一种方式理解就是:事务按照预期生效,数据的状态是预期的状态;
隔离性:多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离;
持久性:指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响;
数据通过原子性、隔离性、持久性来保证一致性;
原子性实现原理:InnoDB,在干活之前,先将要做的事情记录到一个叫undo log的日志文件中,如果失败了或者主动rollback,就可以通过undo log的内容,将事务回滚;(undo log:逻辑日志,记录的是sql执行相关的信息)
原子性
start transaction;
//操作语句
commit;
rollback;
事务提交(commit)和事务回滚(rollback)。
一致性
一致性主要说明的是事务的前后,数据库中的数据的状态要确保一致。
隔离性
隔离性的体现,多个并发事务之间是隔离的。
持久性
性能优化
常见面试题
Redis
数据结构与算法
查找和排序
查找
顺序查找
时间复杂度:O(n)
二分查找
时间复杂度:O(logn)
1.low high两个指针分别指向数组头和尾
2.mid = (low + high) / 2,并将nums[mid]与target比较
3.如果相等,返回;如果小于,则low移动;如果大于,则high移动
4.否则返回-1
int binary_search(int array[], int value, int size)
{
int low = 0;
int high = size -1;
int mid;
while(low <= high)
{
mid = (low + high) / 2; // 二分
if(array[mid] == value) // 中间数据是目标数据
return mid;
else if(array[mid] < value) // 中间数据比目标数据小
low = mid + 1;
else // 中间数据比目标数据大
high = mid - 1;
}
return -1;
}
class Solution {
public:
int search(vector<int>& nums, int target) {
int low = 0;
int high = nums.size()-1;
while(low <= high){
int middle = (low + high) / 2; //int middle = left + ((right - left) / 2);//防止溢出
if(nums[middle] < target){
low = middle + 1;
}
else if(nums[middle] > target){
high = middle - 1;
}
else
return middle;
}
return -1;
}
};
哈希表查找
需要额外空间O(n)实现哈希表,查找时时间复杂度为O(1),用空间换时间。
二叉树查找
二叉树查找:在二叉树查找值为k的过程中,需要比较的次数等于值为k所代表的结点在二叉树中的层数。因此比较次数最少为1次(k值恰好在根结点),最多不超过树的深度。具有n个结点的二叉树的深度至少是[]+1,至多为n。故:
①如果二叉树是平衡的,那么时间复杂度为O(logn);
②如果二叉排序树完全不平衡,那么时间复杂度为O(n)。
bool search(Node* root, int key)
{
while (root != NULL)
{
if (key == root->data)
return true;
else if (key < root->data)
root = root->left;
else
root = root->right;
}
return false;
排序
(冒泡 插入 选择) (快速 希尔) (堆 归并)
n2(n2) n2(nlogn) nlogn(nlogn) 最坏(平均)
稳 不稳 稳
冒泡排序
O(n2)
vector<int> bobbleSort(vector<int>& nums) {
for (int i = 0; i < nums.size() - 1; i++) { // n-1趟
for (int j = 0; j < nums.size() - 1 - i; j++) { // 未排好序区间
if (nums[j] > nums[j + 1]) {
int tmp = nums[j]; // 交换
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
}
}
}
return nums;
}
//改进版,一趟未交换说明已经排好序了
vector<int> bobbleSort1(vector<int>& nums) {
for (int i = 0; i < nums.size() - 1; i++) {
bool exchange = false; // 标志位
for (int j = 0; j < nums.size() - 1 - i; j++) {
if (nums[j] > nums[j + 1]) {
int tmp = nums[j];
nums[j] = nums[j + 1];
nums[j + 1] = tmp;
exchange = true; // 交换了标志位改变
}
}
if (!exchange) return nums;
}
return nums;
}
插入排序
每次选数插入到适合位置,即已经选好的数排好序
vector<int> insertSort(vector<int>& nums) {
for (int i = 1; i < nums.size(); i++) {
int tmp = nums[i]; // 摸到的数
int index = i - 1; // 手里数下标
while (index >= 0 && nums[index] > tmp) {
nums[index + 1] = nums[index]; // 右移
index--;
}
nums[index + 1] = tmp; // 找到适合位置放入
}
return nums;
}
选择排序
每次选择最小值排序
vector<int> selectSort(vector<int>& nums) {
vector<int> res;
for (int i = 0; i < nums.size(); i++) {
int index = 0, minVal = nums[0];
for (int j = 1; j < nums.size(); j++) { // 获得最小值
if (nums[j] < minVal) {
index = j;
minVal = nums[j];
}
}
res.push_back(minVal);
nums[index] = 1000; // 最小值位置用一个较大数覆盖
}
return res;
//改进版(原地排序)
vector<int> selectSort1(vector<int>& nums) {
for (int i = 0; i < nums.size() - 1; i++) {
int index = i;
for (int j = i + 1; j < nums.size(); j++) {
if (nums[index] > nums[j]) index = j; // 确定最小值索引
}
if (index != i) { // 不是原位置才需交换
int tmp = nums[i];
nums[i] = nums[index];
nums[index] = tmp;
}
}
return nums;
}
快速排序
二分思维+递归思维
1.选取一个数,使这个数归位
2.即数组被分为两部分,左边都比这个数小,右边都比这个数大
3.递归完成排序
int partition(vector<int>& nums, int left, int right) {
int tmp = nums[left]; // 选取的数
while (left < right) {
while (left < right && nums[right] >= tmp) right--;
nums[left] = nums[right]; // 小数放左边
while (left < right && nums[left] <= tmp) left++;
nums[right] = nums[left]; // 大数放右边
}
nums[left] = tmp; // 选取的数放回数组
return left;
}
vector<int> quickSort(vector<int>& nums, int left, int right) {
if (left < right) {
int mid = partition(nums, left, right); // 归位函数
quickSort(nums, left, mid - 1);
quickSort(nums, mid + 1, right);
}
return nums;
希尔排序
又称缩小增量排序,希尔排序的基本思想是先将整个待排记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插人排序。
#include <iostream>
using namespace std;
void Print(int array[],int length){ //每执行一次打印一次序列
for(int i=0;i<length;i++){
cout<<array[i]<<" ";
}
cout<<endl;
}
void ShellSort(int array[],int length){
for(int step=length/2;step>0;step=step/2){//初始步长step为length/2
for(int i=0;i<step;i++){ //遍历每一次分组后的第一个元素
for(int j=i+step;j<length;j+=step){ //遍历步长为step的所有元素 ,进行直接插入排序
int temp=array[j];
int m=j-step;
for(m=j-step;m>=0&&array[m]>temp;m-=step){//array[m]小于 temp 时循环结束,结束后应将 temp 赋值给a[m+step]
array[m+step]=array[m];
}
array[m+step]=temp; //将 temp 赋值给a[m+step]
}
}
Print(array,length); //每排序一趟就打印一次序列
}
}
int main(){
int array[]={49,38,65,97,76,13,27,49};
int length=sizeof(array)/sizeof(*array);
Print(array,length); //先打印原始序列
ShellSort(array,length);
return 0;
}
堆排序
1.建堆---农村包围城市(从最后一个孩子节点的父节点开始一步步使得子树有序)
2.得到堆顶元素为最大值
3.去掉堆顶,将最后一个元素置于堆顶,通过一次向下调整使堆有序
4.堆顶为第二大元素
5.重复步骤3
常用于topk问题
// 大根堆------父节点的值大于左右孩子节点的值
void siftLarge(vector<int>& nums, int low, int high) {
int i = low; // 根节点
int j = 2 * i + 1; // 左孩子节点
int tmp = nums[low]; // 堆顶元素
while (j <= high) {
if (j + 1 <= high && nums[j] < nums[j + 1]) j++; // 右孩子大
if (nums[j] > tmp) {
nums[i] = nums[j];
i = j;
j = 2 * i + 1;
}
else {
nums[i] = tmp; // 找到适合位置放入
break;
}
}
nums[i] = tmp; // 放在叶子节点
}
vector<int> heapSort(vector<int>& nums) {
int n = nums.size() - 1;
for (int i = (n - 1) / 2; i >= 0; i--) { // 建堆
siftLarge(nums, i, n);
}
for (int i = n; i >= 0; i--) {
int tmp = nums[0]; // 交换堆顶和最后一个元素
nums[0] = nums[i];
nums[i] = tmp;
siftLarge(nums, 0, i-1);
}
return nums;
}
归并排序
1.分解------将数组越分越小,直到分成一个元素
2.终止条件------一个元素是有序的
3.合并------将元素数组合并,越来越大
void merge(vector<int>& nums, int left, int mid, int right) {
vector<int> ltmp;
int i = left;
int j = mid + 1;
while (i <= mid && j <= right) { // 两边都有数
if (nums[i] < nums[j]) {
ltmp.push_back(nums[i]);
i++;
}
else {
ltmp.push_back(nums[j]);
j++;
}
}
while (i <= mid) { // 一边没数
ltmp.push_back(nums[i]);
i++;
}
while (j <= right) {
ltmp.push_back(nums[j]);
j++;
}
int index = 0; // 更新nusm
for (int k = left; k <= right; k++) {
nums[k] = ltmp[index];
index++;
}
}
vector<int> mergeSort(vector<int>& nums, int left, int right) {
if (left < right) {
int mid = left + (right - left) / 2;
mergeSort(nums, left, mid);
mergeSort(nums, mid + 1, right);
merge(nums, left, mid, right);
}
return nums;
}
常见面试题
ARM体系和结构
通信协议
基本概念

串行和并行
串行通信是指利用一条传输线将数据一位位地顺序传送。
并行通信是指利用多条传输线将一个数据的各位同时传送。
同步和异步
(对单方面来说,指两种不同的数据传输方式)
在同步传输中,数据传输是按照定时信号进行的。发送方和接收方都需要遵守同样的时序规则,以确保数据能够正确地传输。发送方按照固定的时间间隔发送数据,接收方则按照相同的时间间隔接收数据。由于同步传输需要一定的时序同步,因此在高速传输和长距离传输时,同步传输具有较好的抗干扰能力和可靠性。(同步就是通信双方按照一定时序规则收发数据,常用于高速、长距离通信)
在异步传输中,数据传输没有固定的时间间隔。发送方和接收方可以按照自己的节奏进行数据传输,发送方发送数据时不需要等待接收方的响应。因此,异步传输的速度相对较慢,但可以在低速传输和短距离传输时使用,例如串口通信。(异步就是通信双方想发送就发送,常用于低速短距离通信,如串口通信)
全双工和半双工
(对双方来说,指通信双方在数据传输时的传输模式)
在全双工通信模式下,通信双方可以同时进行发送和接收数据,彼此之间不会产生干扰。也就是说,通信双方可以同时发送和接收数据,就像两个人同时打电话交流一样,可以在通信中同时传输数据。(全双工就是通信双方都可以发送或接收数据、适用于需要高速、可靠的数据传输场合,如打电话)
在半双工通信模式下,通信双方只能单向地发送和接收数据,不能同时进行。例如,当一方发送数据时,另一方必须等待接收完成后才能发送数据。这种通信方式就像人们交替交谈,每次只有一个人能够说话,而另一个人必须等待。(半双工就是通信双方只能单向发送或接收数据,适用于一些数据传输量较小,对实时性要求不高的场合,如对讲机)。
另外还有单工,单工即数据传输只在一个方向上传输,方向是固定的,不能实现双向通信。比如收音机和广播。
波特率
波特率BR是单位时间传输的数据位数
单位:bps 1bps = 1bit/s。
采用异步串行,互相通信甲乙双方必须具有相同的波特率,否则无法成功地完成数据通信,
而在同步串行中,发送和接收数据是由同步时钟触发发送器和接收器而实现的。
注:同步通信中数据传输的同步时钟频率就是波特率;而在异步通信中,时钟频率可为波特率的整数倍。
注意:关于通信协议,我们通常需要考虑四个点:
1.有无clock
2.一次传多少数据位
3.是否支持同时收发
4.是否需要回复ack
主要的片上通信协议:UART(同步串行)、USART(异步串行)、IIC、SPI、PCI和PCIE等。
还有:CAN、以太网等。
UART
同步串行通信
常用于调试、主控或外设
一般是9针插口和USB接口
rx和tx两个信号线
帧格式:
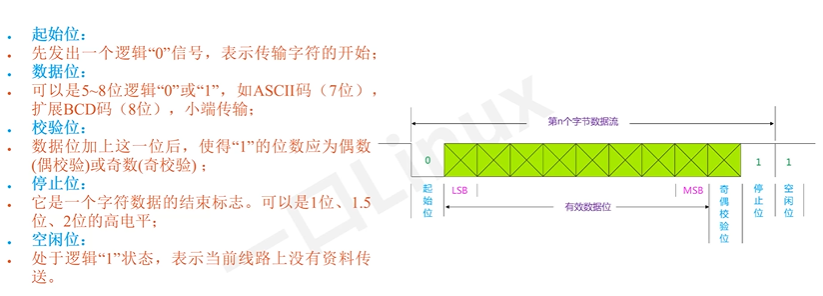
USART
同步(异步)半(全)双工串行
同步(异步)串行通信
USART,即通用同步/异步收发传输器(Universal Synchronous/Asynchronous Receiver/Transmitter),简称串行通信。
它是一种串行通信协议,可以在同步和异步模式下进行数据传输,用于将数据从一个设备传输到另一个设备。它支持全双工和半双工通信模式,并且可以通过中断方式或DMA方式进行数据传输。
每一帧包含起始信号、数据信息、停止信息、校验信息。
SPI
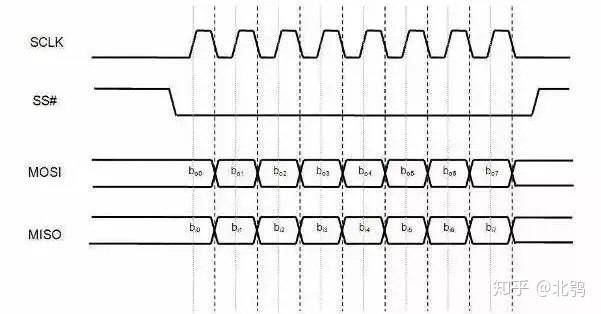
同步全双工串行
SPI是串行外设接口(Serial Peripheral Interface)的缩写,顾名思义就是串行外围设备接口。
SPI,是一种高速的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线,节约了芯片的管脚,同时为PCB的布局上节省空间,提供方便,正是出于这种简单易用的特性,如今越来越多的芯片集成了这种通信协议。SPI数据传输速度总体来说比I2C总线要快,速度可达到几Mbps。
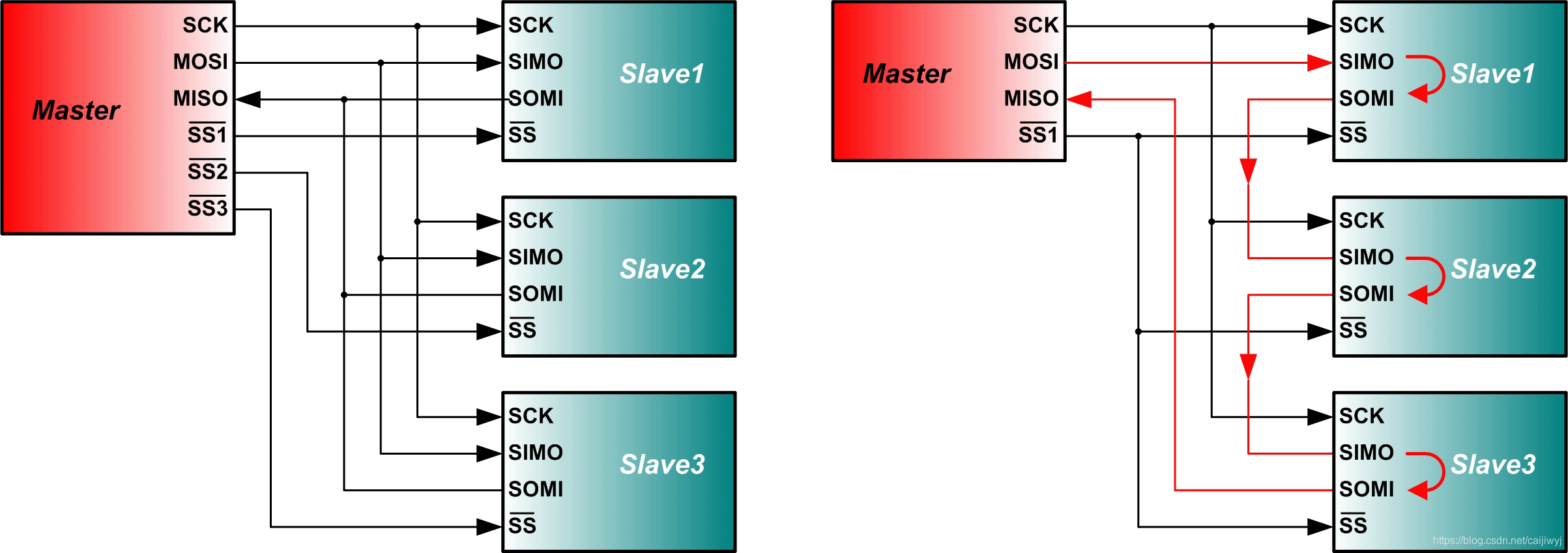
SPI总线只需四条线(如图所示)就可以完成MCU与各种外围器件的通讯:
(1)MOSI – 主(Master)器件数据输出,从(Slave)器件数据输入
(2)MISO – 主(Master)器件数据输入,从(Slave)器件数据输出
(3)SCLK –时钟信号,由主(Master)器件产生
(4)SS – 从器件使能信号,由主器件控制,有的IC会标注为CS(Chip select)
SPI是单主设备(single-master)通信协议,这意味着总线中的只有一支中心设备能发起通信。当SPI主设备想读/写从设备时,它首先拉低从设备对应的SS线(SS是低电平有效),接着开始发送工作脉冲到时钟线上,在相应的脉冲时间上,主设备把信号发到MOSI实现“写”,同时可对MISO采样而实现“读”。
IIC
同步半双工串行
IIC 即Inter-Integrated Circuit(集成电路总线)。它是一种简单、双向、二线制、同步串行总线,主要是用来连接整体电路(ICS) ,IIC是一种多向控制总线,也就是说多个芯片可以连接到同一总线结构下,同时每个芯片都可以作为实时数据传输的控制源。这种方式简化了信号传输总线接口。
I2C串行总线一般有两根信号线,一根是双向的数据线SDA,另一根是时钟线SCL。所有接到I2C总线设备上的串行数据SDA都接到总线的SDA上,各设备的时钟线SCL接到总线的SCL上。
每个连接到总线的设备都有一个独立的地址,主机正是利用该地址对设备进行访问。
与SPI的单主设备不同,IIC是多主设备的总线,IIC没有物理的芯片选择信号线,没有仲裁逻辑电路,只使用两条信号线——serial data(SDA)和serial clock(SCL)。
数据帧格式:
IIC协议规定:
-
每一支IIC设备都有一个唯一的七位设备地址。数据帧大小为8位的字节。数据(帧)中的某些数据位,用于控制通信的开始、停止、方向(读写)和应答机制。
-
IIC数据传输速率有标准模式(100kbps)、快速模式(400kbps)和高速模式(3.4Mbps),另外一些变种实现了低速模式(10kbps)和快速+模式(1Mbps)。
-
物理实现上,IIC总线由两根信号线和一根地线组成。两根信号线都是双向传输的,参考图3。IIC协议标准规定发起通信的设备称为主设备,主设备发起一次通信后,其它设备均为从设备。
IIC通信过程大概如下。首先,主设备发一个START信号,这个信号就像对所有其它设备喊:请大家注意!然后其它设备开始监听总线以准备接收数据。接着,主设备发送一个7位设备地址加一位的读写操作的数据帧。当所设备接收数据后,比对地址自己是否目标设备。如果比对不符,设备进入等待状态,等待STOP信号的来临;如果比对相符,设备会发送一个应答信号——ACKNOWLEDGE作回应。
当主设备收到应答后便开始传送或接收数据。数据帧大小为8位,尾随一位的应答信号。主设备发送数据,从设备应答;相反主设备接数据,主设备应答。当数据传送完毕,主设备发送一个STOP信号,向其它设备宣告释放总线,其它设备回到初始状态。
基于IIC总线的物理结构,总线上的START和STOP信号必定是唯一的。另外,IIC总线标准规定:SDA线的数据转换必须在SCL线的低电平期,在SCL线的高电平期,SDA线的上数据是稳定的。
CAN
异步步半双工串行
CAN总线通信是汽车电控领域最典型的通信方式,从上世纪80年代博世发明该通信方式以来,一直占据着汽车通信中的老大位置。CAN的压差0v表示逻辑1,压差2v表示逻辑0,两根线CANh(high,高压)和CANl(low,低压)输出差分信号,采用差分双绞线连接。
结构:CAN是总线(Bus)通信方式,网络拓扑如下图。总线的意思就是所有节点都连接到同一个传输媒介中,也就是说传输媒介中的电信号会影响到所有的节点。总线通信中一条CAN线上会挂多个节点,所以一般我们会说CAN Bus 或 CAN Network。
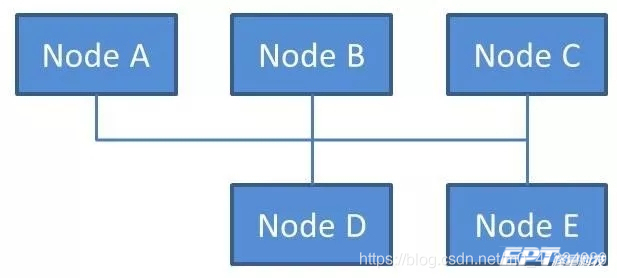
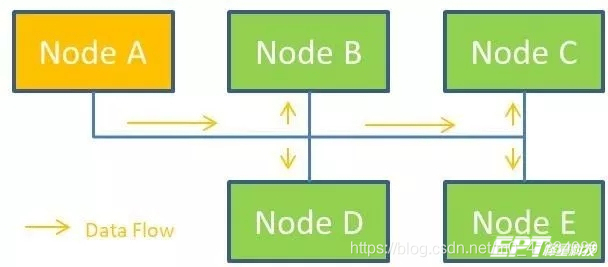
收发方式:CAN总线为广播式通信,一个节点发送信息会占据所有通信媒介,发送节点只管自己发送,不关心谁去接收,总线上所有通信节点都会收到信息。接收节点则根据自身的情况来决定是否接收信息。这就类似于在会议室里开会,一个人发言所有人都能听见,发言内容与谁相关,谁去关注就OK了。
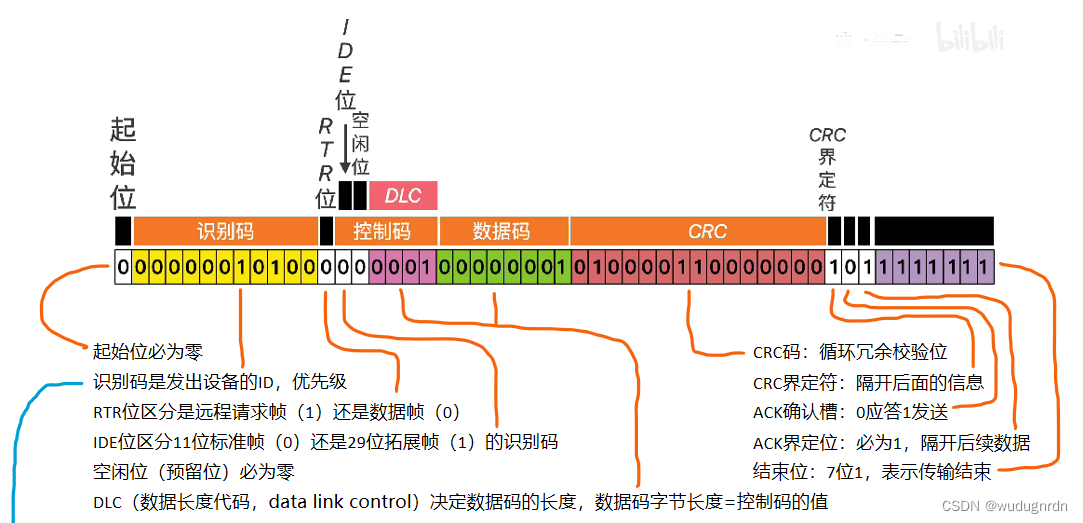
数据帧结构:
以太网
以太网是交换机式(Switched Network)通信方式,网络拓扑如下图。网络中有终端节点,简单理解为一个节点上只有一个以太网端口;和交换机节点,简单理解为一个节点上有多个以太网端口,其主要作用是转发信息。
结构:交换机式通信指的是所有的终端节点都要通过交换机才能连接到一起,所有传递的信息都需要交换机进行转发。交换机式通信中一条网线上只有两端与两个端口相连,没有分叉。所以一般我们不说以太网总线,而是说以太网网络(Ethernet Network)。
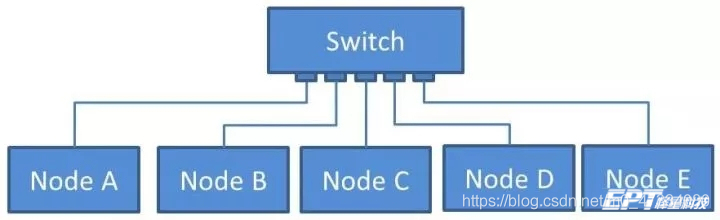
收发方式:以太网的交换机式通信,则是点对点的通信方式。发送节点在发送信息前,会首先想好信息要发送给谁,然后会把自己的地址和接收方的地址放到报文里去。节点A需要发送信息给节点B,可以简单理解为交换机内部把端口1和端口2给连起来了,因此信息就从A传到了B。在A和B收发的过程中,C/D/E节点都没有收到信息,他们之间的通信媒介也没受到影响。这就类似于打电话,一个人拨通另一个人的电话号码,就只有这两个人互相通话。那么如果有信息需要从发送节点发给多个节点,相当于召开多方电话会议,怎么办呢?这就有了多播和广播的概念。
多播指一对多的信息发送,广播指一对所有的信息发送。如果A节点希望发送信息给多个节点,则需要将自己的地址和多个接收方的地址(是一个提前设置好的多播地址)放到报文里去,此时可以简单理解为交换机把发送方的端口同多个接收方的端口连接起来了,因此信息就从A传到了多个节点。如果A节点希望发送信息给所有节点,则需要将自己的地址和所有接收方的地址(是一个提前设置好的广播地址)放到报文里去,此时可以简单理解为交换机把发送方的端口同所有端口连接起来了,因此信息就从A传到了所有节点。
参考资料:
https://zhuanlan.zhihu.com/p/166103763
https://blog.csdn.net/m0_47334080/article/details/106939302
什么是异步串行,什么是同步串行
答:
(1)异步串行方式的特点:
①以字符为单位传送信息,相邻两个字符间的间隔是任意长;即字符内部各位同步,字符间异步;
②因为一个字符中的比特位长度有限,所以接收时钟和发送时钟只要相近就可以了。
(2)同步串行方式的特点:
①以数据块为单位传送信息,在一个数据块内,字符与字符之间无间隔;即字符内部各位同步,字符间也同步;
②因为一次传输的数据块中包含的数据较多,所以接收时钟与发送时钟需要严格同步。
uart如何保证数据传输的正确性
答:
(1)在数据位的两端添加了起始位、奇偶校验位、停止位等用于数据的同步和纠错。
(2)在接收端用16倍波特率对数据进行采样,取中间的采样值,很大程度上确保了采样数据的正确性。
RS-232与RS-485的区别和联系?
答:
(1)区别:
①抗干扰性:RS-485接口的抗干扰性比RS-232接口强,因为RS-485采用差分传输。
②传输距离:RS-485接口(1200m)的传输距离比RS-232接口(50m)远。
③通信能力:RS485接口在总线上允许连接多达128个收发器,而RS-232接口只允许一对一通信。
④传输速率:RS-485接口的最高传输速率为10Mbps,而RS-232接口为20Kbps。
⑤信号线:RS-485接口组成半双工网络需要两根信号线,组成全双工网络需要四根信号线;RS-232接口一般使用RXD、TXD、GND三根线组成全双工网络。
⑥电气电平值:RS-485接口规定A线电平比B线电平高200mV以上时为逻辑“1”,A线电平比B线电平低200mV以上时为逻辑“0”。RS-232接口规定-5V ~ -15V等于逻辑“1”,+5V ~ + 15V为逻辑“0”,噪声容限为2V。
(2)联系:
①都可通过DB-9连接器连接。
②均可采用屏蔽双绞线传输。
③都是串行通信。
④通信方式都是全双工(一般RS-485是半双工)。
SPI的四种操作时序分别是什么
答:
SPI的时钟极性CPOL和时钟相位CPHA可以分别为0或1,由此构成了四种组合:
①CPOL = 0,CPHA = 0:空闲时SCLK为低电平,在第一个边沿开始采样。

②CPOL = 0,CPHA = 1:空闲时SCLK为低电平,在第二个边沿开始采样。

③CPOL = 1,CPHA = 0:空闲时SCLK为高电平,在第一个边沿开始采样。

④CPOL = 1,CPHA = 1:空闲时SCLK为高电平,在第二个边沿开始采样。

IIC总线时序图
答:
(1)时序总结:

| 总线空闲状态 | SCL和SDA均为高电平,接上拉电阻。 |
|---|---|
| 启动信号(START) | 在SCL保持高电平期间,SDA由高电平被拉低。由主控器发出。 |
| 数据位传送(DATA) | 在SCL保持高电平期间,SDA上的电平保持稳定,低电平为数据0、高电平为数据1。用法:主控器和被控器都可发出。 |
| 应答信号(ACK) | 在SCL保持高电平期间,SDA保持低电平。IIC总线上所有数据都是以8位字节传送的,发送器每发送一个字节,就在第9个时钟脉冲期间释放SDA(高电平),由接收器反馈一个ACK。 |
| 非应答信号(NACK) | 在SCL保持高电平期间,SDA保持高电平。如果接收器是主控器,则它在收到最后一个字节后,发送一个NACK,通知被控器结束数据发送,并释放SDA(高电平),以便主控器发送一个STOP。 |
| 停止信号(STOP) | 在SCL保持高电平时间,SDA由低电平被释放(拉高)。由主控器发出。 |
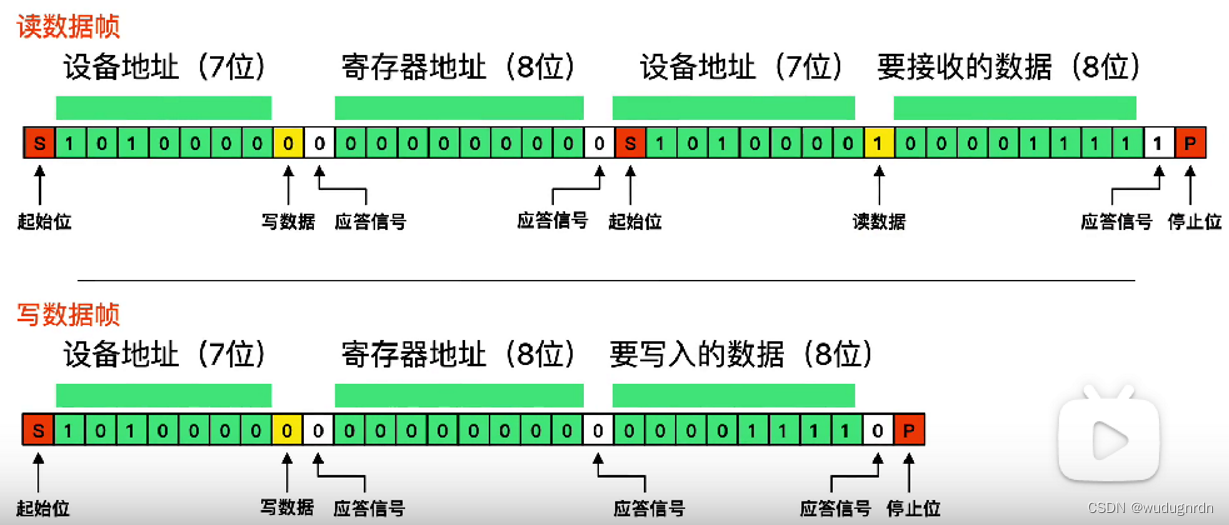
(2)写数据步骤:
①主机发起一个启动信号(START)。
②主机发送7bit从机地址+1bit读写选择位,1表示读、0表示写。
③从机产生应答信号(ACK)。
④主机发送8bit从机寄存器地址。
⑤从机产生应答信号(ACK)。
⑥主机发送一个字节数据。
⑦从机产生应答信号(ACK)。
⑧主机发送一个停止信号(STOP)。
(3)读数据步骤
①主机发送一个启动信号(START)。
②主机发送7bit从机地址+1bit读写选择位,1表示读、0表示写。
③从机产生一个应答信号(ACK)。
④主机发送8bit从机寄存器地址。
⑤从机产生一个应答信号。
⑥主机再次发送一个启动信号(START)。
⑦主机再次发送7bit从机地址+1bit读写选择位,1表示读、0表示写。
⑧从机产生一个应答信号(ACK)。
⑨主机读取一个字节数据。
⑩主机产生一个非应答信号(NACK)。之后产生一个停止信号(STOP)。
请说明总线接口UART、USB、SPI、IIC的异同点
答:
| 总线接口 | 串/并 | 同步/异步 | 工作方式 | 速率 | 线路 | 距离 | 大小端 |
|---|---|---|---|---|---|---|---|
| UART | 串行 | 异步 | 全双工 | 慢,最快只有1.5Mbps | 3线:RX、TX、GND | 远,RS-485可达1200m | 小端模式 |
| USB | 串行 | 同步 | 半双工 | 快,USB3.0可达5Gbps | 4线:Vbus、GND、D+、D- | 近,不超过5m | 小端模式 |
| SPI | 串行 | 同步 | 全双工 | 快,可达50Mbps | 3线或4线:SCLK、SIMO、SOMI、SS | 远,可达10m | 大端模式 |
| IIC | 串行 | 同步 | 半双工 | 慢,最快只有3.4Mbps | 2线:SCL、SDA | 近,不超过30cm | 大端模式 |
UART一帧可以传5/6/7/8位,IIC必须是8位,SPI可以8/16位。
CAN总线接口相对于RS-232接口、RS-485接口的优点是什么?
答:
(1)CAN总线接口相对于RS-232接口的优点是抗干扰能力强、传输距离远。它采用差分传输,内置CRC校验,传输可靠性强。
(2)CAN总线接口相对于RS-485接口的优点是能构成多主系统,同一时刻可以有两个或两个以上的设备处于发送状态,适用于实时性要求高的工控领域。
应用编程和网络编程
应用编程
进程和线程的含义
答:
进程是资源分配的基本单元,它是运行中的程序,它具有独立的内存空间、执行环境和系统资源。
线程是处理器调度的基本单元,是进程的一个执行流,一个进程可以包含多个线程,多个线程共享同一进程的内存和资源。
进程、线程和协程的区别
答:
进程是资源分配的基本单元,它是运行中的程序。线程是程序执行的最小单元,是进程的一个执行流,是微进程,一个进程例可以包含多个线程。协程是微线程,在子程序内部执行,可在子程序内部中断,转而执行别的子程序,在适当的时候再返回来接着执行。
进程和线程的区别:
1.定义不同。进程是资源分配的最小单位,线程是最小的执行单元。
2.开销不同。进程拥有自己的独立地址空间,每启动一个进程,系统就会为其分配地址空间,建立数据表来维护代码段、数据段和堆栈段,进程之间的变量不共用,这种开销非常大。而线程共享进程的数据,使用相同的地址空间,只是拥有独立的栈和寄存器组,开销较小。
3.通信方式不同。进程间通信需要以通信方式IPC进行,而线程之间共享全局变量、静态变量等数据,但线程间需要考虑访问资源的同步和互斥问题。
4.多进程和多线程情况不同。多进程不用考虑一个进程死掉会对其他进程产生影响,而多线程只要有一个线程死掉,整个进程都会死掉。
线程和协程的区别:
1.协程执行效率高,它直接操作栈基本没有内核切换的开销。
2.协程是异步机制,不需要多线程的锁机制。
3.协程是非抢占式的,线程是抢占式的。协程需要用户手动释放使用权切换到其他协程。
进程调度算法即策略有哪些
答:
-
先来先服务
-
短作业优先调度
-
高优先级优先
-
时间片论
-
多级反馈队列
有抢占式和非抢占式的区别
答:
有抢占式优先权调度算法是指系统先把处理机制分配给优先权最高的进程,如果在其执行期间出现了另外一个优先权更高的进出,进程调度程序就会将处理机重新分配给优先权最高的进程。
非抢占式优先权调度算法是指系统先把处理机制分配给优先权最高的进程,直到其执行完成。
并发和并行的含义
答:
并发是指只有一个进程在运行,并且单个CPU在很短的时间内不断在多个线程之间切换。
并行是指多个CPU的多个进程同时运行。
多线程和多进程的特点
答:
多进程的优点是稳定性高,一个进程崩溃不会影响其他进程,缺点是进程切换开销大、资源消耗多。
多线程的优点是创建、切换开销小,可以共享进程的资源,缺点是线程之间共享资源需要进行同步保护,易出现竞态条件和死锁等问题
多线程和多进程的选择问题
答:
对资源保护和管理要求高、不限制开销和效率,使用多进程。
要求并发执行、资源共享、效率高和切换频繁,使用多线程。
创建进程的方式
答:
系统首先初始化,开启后台进程、守护进程;某一个进程使用fork函数开启另一个进程;这个时候子进程拷贝了父进程的数据段、堆、栈以及继承了父进程打开的文件描述符,子进程与父进程并不共享这些存储空间,而是完全复制,互不影响。当然使用vfork函数创建的子进程就会影响父进程。
守护进程的含义
答:
守护进程,也就是通常所说的 Daemon 进程,是 Linux 中的后台服务进程。周期
性的执行某种任务或等待处理某些发生的事件。
Linux 系统有很多守护进程,大多数服务都是用守护进程实现的。比如:像我们
的 tftp,samba,nfs 等相关服务。
UNIX 的守护进程一般都命名为* d 的形式,如 httpd,telnetd 等等。
守护进程会长时间运行,常常在系统启动时就开始运行,直到系统关闭时才终止。不依赖于终端。
守护进程创建流程如下:
- 创建子进程,父进程退出
- 在子进程中创建新会话
- 改变当前目录为根目录
- 重设文件权限掩码
- 关闭文件描述符
Fork wait exec函数的用法
答:
父进程通过fork函数创建一个子进程,此时这个子1进程知识拷贝了父进程的页表,两个进程都读同一个内存,exec函数可以加载一个elf文件去替换父进程,从此子进程就可以运行不同的程序,父进程wait函数之后会阻塞,直到子进程状态发生改变
pid_t wait(int *wstatus);
pid_t waitpid(pid_t pid, int *wstatus, int options);
wait和waitoid的区别在于,前者不能等待指定的pid子进程
-Pid
-options的说明:
fork和vfork的区别
答:
1.fork的子进程拷贝父进程的数据断和代码段;vfork的子进程与父进程共享数据段;
2.fork的父子进程的执行次序是不确定的,vfork保证子进程先运行,调用exit或exec后父进程才可能被调度运行。
3.vfork函数创建的子进程在需要改变共享数据段中变量的值,则拷贝父进程。
同步和异步的含义
答:
同步一般是指阻塞等待,异步一般是不需要等待,比如你发送数据到服务器,那么就不需要等待,直接去干别的事,一般来说异步的效率高于同步。
进程的几种状态
答:
进程有五种状态,创建、就绪、运行(执行)、阻塞和终止。linux系统下,进程的生命周期是从执行到终止。
进程间通信方式
答:
通信方式大致分为三种,管道、系统IPC和套接字。
管道分为无名管道和有名管道,无名管道只能进行有血缘关系的进程间通信,有名管道运行无血缘关系的进程间通信,都是半双工通信。
系统IPC分为信号量、消息队列、信号、共享内存。(1)信号量是个计数器,用来控制多个进程对共享资源的访问,用于进之间的同步和互斥。(2)消息队列是消息的链接表,它独立于进程存放在内核中,实现消息的随机查询,按照消息的类型读取,常用于不相关进程间通信。(3)信号是用于通知进程某个事件已经发生,用于进程间同步。(4)共享内存就是映射一段能被其他进程访问的内存,它是最快的IPC,往往配合其他机制使用,比如信号量等。原理:开辟一个物理内存空间,各个进程将物理地址映射到自己的虚拟地址空间,通过虚拟地址就可以直接访问,进而实现数据共享,共享内存是最快的通信方式,因为少了数据的拷贝。
套接字:socket可用于不同主机之间的进程通信。
//管道函数
int pipe(int pipefd[2]);//无名管道的创建,pipefd[0]是读端,pipefd[1]是写端。
//信号量函数
int semget(key_t key, int nsems, int semflg);//创建信号量对象
/*
key:如果是0(IPC_PRIVATE)会建立新信号量集对象;如果是大于0的32位整数:视参数semflg来确定操作,通常要求此值来源于ftok返回的IPC键值
nsems:创建信号量集中信号量的个数,该参数只在创建信号量集时有效
*/
int semstl(int semid, int semnum, int cmd, ...);//执行cmd指定的控制命令
int semop(int semid, struct sembuf * sops, unsigned nsops);//对信号量的P操作(wait操作,等待资源)或V操作(++操作,资源可用)
/*
函数的参数 semid 为信号量集的标识符;参数 sops 指向进行操作的结构体数组的首地址;参数 nsops 指出将要进行操作的信号的个数。semop 函数调用成功返回 0,失败返回 -1。
semop 的第二个参数 sops 指向的结构体数组中,每个 sembuf 结构体对应一个特定信号的操作。因此对信号量进行操作必须熟悉该数据结构,该结构定义在 linux/sem.h,如下所示:
struct sembuf{
unsigned short sem_num;//信号在信号集中的索引,0代表第一个信号,1代表第二个信号
short sem_op; //操作类型,大于0则信号加上sem_op,表示进程释放控制的资源,资源可用(V);等于0则睡眠;小于0则信号加上sem_op,进程阻塞等待资源(P)
short sem_flg; //操作标志,sem_flg公认的标志是 IPC_NOWAIT 和 SEM_UNDO。如果操作指定SEM_UNDO,它将会自动撤消该进程终止时。
};
*/
//消息队列函数
msgid = msgget (key, IPC_CREAT | IPC_EXCL | 0666)//创建消息队列
msgsize = msgrcv (msgid, &msgbuf, sizeof (msgbuf) - sizeof (long), 1L, 0);//从一个消息队列中获取消息,保存到msgbuf中
//信号函数
signal();
//共享内存函数
shmid = shmget(key,size,IPC_CREAT);//开辟共享内存
addr = shmat(shmid, NULL, 0);//映射到进程虚拟地址
memcpy(addr,buf,sizeof(buf));//保存数据到addr中
int ret = shmdt(addr);//解除映射
int ctl = shmctl(shmid, cmd, buf);//删除共享内存对象
//套接字函数
进程间的通信中管道通信的实现原理
答:
操作系统在内核中开辟一块缓冲区(称为管道)用于通信
编程步骤:
-
父进程调用pipe开辟管道,得到两个文件描述符指向管道的两端
-
父进程调用fork创建子进程,那么子进程也有两个文件描述符指向同一管道
-
父进程关闭管道读端,子进程关闭管道写端。父进程可以往管道里写,子进程可以从管道里读,管道是用环形队列实现的,数据从写端流入从读端流出,这样就实现了进程间通信
#include<unistd.h>
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define INPUT 0 //读数据fd
#define OUTPUT 1 //发数据fd
int main(){
//创建管道
int fd[2];
pipe(fd);
//创建子进程
pid_t pid = fork();
if (pid < 0){
printf("fork error!\n");
exit(-1);
}
else if (pid == 0){//执行子进程
printf("Child process is starting...\n");
//子进程向父进程写数据,关闭管道的读端
close(fd[INPUT]);
write(fd[OUTPUT], "hello douya!", strlen("hello douya!"));
exit(0);
}
else{//执行父进程
printf ("Parent process is starting......\n");
//父进程从管道读取子进程写的数据 ,关闭管道的写端
close(fd[OUTPUT]);
char buf[255];
int output = read(fd[INPUT], buf, sizeof(buf));
printf("%d bytes of data from child process: %s\n", output, buf);
}
return 0;
}
有名管道的通信方式
答:
-
创建fifo文件
-
打开fifo文件
-
读写fifo文件
共享内存的操作方式
答:
进程A
1)创建共享内存
2)映射到进程地址
3)通过映射地址操作共享内存
4)关闭映射
进程B
1)打开共享内存
2)映射
3)操作共享内存
4)关闭映射
如何选择进程间的通信方式
答:
管道通信主要是应用在进程间互发短小、频率很高的消息。
共享内存主要是在接进程间共享数据庞大、读写频繁的数据(因为是把物理地址映射到进程)。
其他考虑socket。
僵尸进程、孤儿进程和守护进程的含义
答:
僵尸进程:一个进程使用fork出一个子进程,如果子进程退出,但是父进程没有使用wait或者waitpid函数回收子进程的资源,那么该进程就是僵尸进程。
孤儿进程:是指父进程异常退出,而子进程还没退出,那么子进程就会被1号进程(init)收养。
守护进程:是指后台进程,有意把父进程先结束,然后被1号进程收养。
僵尸进程的危害
答:
僵尸进程的进程号并不会被释放,但是系统的进程号是有限的,如果出现大量僵尸进程就会导致系统无进程号可用就无法产生新进程。
如何杀死僵尸进程
答:
结束其父进程。
如何实现守护进程
答:
-
创建子进程,终止父进程
-
调用setsid创建一个新会话
-
将当前目录更改为根目录
-
重设文件权限掩码,文件权限掩码是指屏蔽掉文件权限的对应为
-
关闭不再需要的文件描述符
进程哪些情况会终止
答:
进程终止分为正常和异常。正常终止包括main函数通过return语句返回来终止进程,应用程序调用exit()或_exit()终止进程。异常终止包括应用程序调用abort()函数终止进程,进程收到信号(SIGKILL信号)终止。
系统包括哪些特殊进程
答:
Linux下有3个特殊的进程,
idle进程(PID = 0), idle进程是由系统自动创建,运行在内核态
init进程(PID = 1),init进程是由idle创建运行在用户空间,其父进程就是idle
kthreadd(PID = 2)。内核线程,负责内核线程的创建工作,其父进程就是idle
死锁的原因、产生条件和解决办法
答:
死锁是指多个进线在执行过程中,因争夺资源而造成互相等待,此时系统产生了死锁。
产生的条件有多个:
-
互斥条件:进程对所分配的资源不允许其他进程访问,若其他进程需要访问,只能等待,知道该进程使用完毕后释放资源
-
请求保持条件:进程获得一定资源后,有对其他资源发出请求,但该资源被其他进程占用,此时请求阻塞,而且这个进程不会释放自己已经占有的资源
-
不可剥夺条件:进程获得资源,只能自己释放,不可剥夺
-
环路等待条件:若干进程之间形成一种头尾相接等待资源关系
解决办法;
1.资源一次性分配,从而解决请求保持的问题
2.可剥夺资源:当进程新的资源未得到满足时,释放已有的资源;
3.资源有序分配:资源按序号递增,进程请求按递增请求,释放则相反
内核线程和用户线程的含义
答:
内核线程由操作系统创建和销毁。
用户线程是由用户进行管理,用户线程的创建、调度、同步和销毁全由库函数在用户空间完成,不需要内核的帮助,这种线程开销是比较小的。
线程间的通信方式
答:
通信方式包括临界区、互斥锁、信号量、事件、条件变量和读写锁。
临界区:每个线程访问临界资源的那段代码叫临界区,每次只允许一个线程进入临界区,进入后其他线程无法进入
互斥锁:采用互斥对象机制,只有拥有互斥对象的线程才可以访问
信号量:计数器,允许多个线程同时访问统一资源
事件(信号):
条件变量:通过条件变量通知操作的方式保持多线程同步
读写锁:读写锁和互斥量类似,但互斥量要么是锁住状态,要么就是不加锁状态。读写锁一次只允许一个线程写,但允许一次多个线程读,这样效率就比互斥锁要高。
//1.互斥锁函数
/*
mutex:互斥锁ID,其类型为pthread_mutex_t,是一个long long类型的数
attr:指向互斥锁属性的指针。通常为 NULL,表示使用默认属性。
*/
//用于初始化一个互斥锁。可以使用默认属性或者自定义属性进行初始化
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);
//用于获取一个互斥锁(上锁),如果该锁已经被其他线程获取,则当前线程将阻塞,直到该锁被释放为止
int pthread_mutex_lock(pthread_mutex_t *mutex);
// 试图加锁(不阻塞操作)
// 不同点:当锁已经在使用的时候,返回为EBUSY,而不是挂起等待。
int pthread_mutex_trylock(pthread_mutex_t *mutex);
//用于释放一个互斥锁(解锁),如果该锁当前没有被任何线程获取,则此函数将返回一个错误。
int pthread_mutex_unlock(pthread_mutex_t *mutex);
//用于销毁一个互斥锁,释放相关资源。
int pthread_mutex_destroy(pthread_mutex_t *mutex);
//2.信号量函数
int semget(key_t key, int nsems, int semflg);//创建信号量对象
/*
key:如果是0(IPC_PRIVATE)会建立新信号量集对象;如果是大于0的32位整数:视参数semflg来确定操作,通常要求此值来源于ftok返回的IPC键值
nsems:创建信号量集中信号量的个数,该参数只在创建信号量集时有效
*/
int semstl(int semid, int semnum, int cmd, ...);//执行cmd指定的控制命令
int semop(int semid, struct sembuf * sops, unsigned nsops);//对信号量的P操作(wait操作,等待资源)或V操作(++操作,资源可用)
/*
函数的参数 semid 为信号量集的标识符;参数 sops 指向进行操作的结构体数组的首地址;参数 nsops 指出将要进行操作的信号的个数。semop 函数调用成功返回 0,失败返回 -1。
semop 的第二个参数 sops 指向的结构体数组中,每个 sembuf 结构体对应一个特定信号的操作。因此对信号量进行操作必须熟悉该数据结构,该结构定义在 linux/sem.h,如下所示:
struct sembuf{
unsigned short sem_num;//信号在信号集中的索引,0代表第一个信号,1代表第二个信号
short sem_op; //操作类型,大于0则信号加上sem_op,表示进程释放控制的资源,资源可用(V);等于0则睡眠;小于0则信号加上sem_op,进程阻塞等待资源(P)
short sem_flg; //操作标志,sem_flg公认的标志是 IPC_NOWAIT 和 SEM_UNDO。如果操作指定SEM_UNDO,它将会自动撤消该进程终止时。
};
*/
//3.条件变量函数
/*
cond:条件变量ID,其类型为pthread_cond_t,是一个long long类型的数
cond_attr:条件变量属性。通常为 NULL,表示使用默认属性。
*/
#include <pthread.h>
//初始化和创建条件变量
int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *cond_attr)
//销毁条件变量
int pthread_cond_destroy(pthread_cond_t *cond)
//条件变量等待
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex)
//条件变量唤醒
int pthread_cond_signal(pthread_cond_t *cptr);//唤醒一个等待线程
int pthread_cond_broadcast(pthread_cond_t *cptr);//唤醒所有等待线程
信号量的含义和作用
答:
由于信号量只能进行两种操作等待和发送信号,即P(sv)和V(sv),
(1)P(sv)操作:如果sv的值大于零,就给它减1;如果它的值为零,就挂起该进程的执行(信号量的值为正,进程获得该资源的使用权,进程将信号量减1,表示它使用了一个资源单位)。
(2)V(sv)操作:如果有其他进程因等待sv而被挂起,就让它恢复运行,如果没有进程因等待sv而挂起,就给它加1(若此时信号量的值为0,则进程进入挂起状态,直到信号量的值大于0,若进程被唤醒则返回至第一步)。
作用:用于多进程或多线程对共享数据对象的读取,它主要是用来保护共享资源(信号量也属于临界资源),使得资源在一个时刻只有一个进程独享。
线程和进程的同步方式有哪些?
答:
进程的同步方式有信号、信号量、消息队列。
线程的同步方式有信号、信号量、条件变量、互斥锁、读写锁。
进程和线程的中断切换过程
答:
上下文切换指的是内核(操作系统的核心)在CPU上对进程或者线程进行切换。
进程上下文切换:
(1)保护被中断进程的处理器现场信息
(2)修改被中断进程的进程控制块有关信息,如进程状态等
(3)把被中断进程的进程控制块加入有关队列
(4)选择下一个占有处理器运行的进程
(5)根据被选中进程设置操作系统用到的地址转换和存储保护信息
(6)根据被选中进程恢复处理器现场
线程池创建原因和设计思路
答:
创建原因:创建和销毁线程的花销是比较大的,这些时间可能比处理业务时间还要长,这样频繁的创建和销毁线程,再加上业务工作的线程,消耗系统资源的时间,可能导致系统资源不足,线程池可以提升系统效率。
设计思路:
实现线程池步骤:
-
设置一个生产者消费队列,作为临时资源
-
初始化n个线程,并让其运行起来,加锁去队列里去任务运行
-
当任务队列为空时,所有线程阻塞
-
当生产者队列来了一个任务后,先对队列加锁,把任务挂到队列上,然后使用条件变量通知阻塞中的线程来处理
线程池的线程数量和哪些相关
答:
CPU、IO/并发、并行有关
如果是CPU密集型应用,则线程池大小设置为:CPU数目+1
如果是IO密集型应用,则线程池大小设置为:2*CPU数目+1
最佳线程数目 = (线程等待时间与线程CPU时间之比 + 1)* CPU数目
所以线程等待时间所占比例越高,需要越多线程。线程CPU时间所占比例越高,需要越少线程
互斥锁的机制
答:
互斥锁机制:mutex,用于保证在任何时刻,都只能有一个线程访问该对象。当获取锁操作失败时,线程会进入睡眠,等待锁释放时被唤醒。
互斥锁和读写锁的区别
答:
互斥锁和读写锁:
(1) 读写锁区分读锁和写锁,而互斥锁不区分
(2)互斥锁同一时间只允许一个线程访问该对象,无论读写;读写锁同一时间内只允许一个写者,但是允许多个读者同时读对象
读写锁通过函数 acquire() 获取锁,而函数 release() 释放锁
单核机械上写多线程程序,是否考虑加锁?
答:
需要。因为线程锁只要是用来实现线程的同步和通信,在抢占式操作系统中,通常为每个线程分配一个时间片,当某个线程时间片耗尽时,操作系统会将其挂起,然后运行另一个线程。如果这两个线程共享某些数据,不使用线程锁的前提下,可能会导致共享数据修改引起冲突。
多线程要注意什么
用什么样的方式可以减少数据竞争
管道、信号量的实现方式和特性
有名管道和无名管道的区别
什么是线程的同步,什么是线程的异步,分别有什么样的使用场景
使用虚拟内存有什么样的优点
怎么建立虚拟地址和物理地址之间的映射
网络编程
OSI网络模型
答:
应用层:为应用程序提供服务,与进程进行交互,通常包括HTTP/TFTP
传输层:建立起不同进程间的通信连接,通常包括TCP/UDP
网络层:建立起不同主机间的通信连接,通常包括IP/ICMP
链路层:提高传输的物理介质,通常包括以太网

HTTP的含义
答:
http是超文本传输协议,是一个基于TCP/IP的通信协议来传递数据。
超文本:超越了普通文本的文本,它是文字、图片、视频等的混合体,最关键有超链接,能从一个超文本跳转到另外一个超文本。
传输:数据虽然是在 A 和 B 之间双向传输,允许中间有中转或接力。
协议:它使用计算机能够理解的语言确立了一种计算机之间交流通信的规范(两个以上的参与者),以及相关的各种控制和错误处理方式(行为约定和规范)
HTTP常见状态码

答:
1xx 类状态码属于提示信息,是协议处理中的一种中间状态,实际用到的比较少。
2xx 类状态码表示服务器成功处理了客户端的请求,也是我们最愿意看到的状态。
- 「200 OK」是最常见的成功状态码,表示一切正常。如果是非
HEAD请求,服务器返回的响应头都会有 body 数据。 - 「204 No Content」也是常见的成功状态码,与 200 OK 基本相同,但响应头没有 body 数据。
- 「206 Partial Content」是应用于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部,而是其中的一部分,也是服务器处理成功的状态。
3xx 类状态码表示客户端请求的资源发送了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
- 「301 Moved Permanently」表示永久重定向,说明请求的资源已经不存在了,需改用新的 URL 再次访问。
- 「302 Found」表示临时重定向,说明请求的资源还在,但暂时需要用另一个 URL 来访问。
301 和 302 都会在响应头里使用字段 Location,指明后续要跳转的 URL,浏览器会自动重定向新的 URL。
- 「304 Not Modified」不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,也就是告诉客户端可以继续使用缓存资源,用于缓存控制。
4xx 类状态码表示客户端发送的报文有误,服务器无法处理,也就是错误码的含义。
- 「400 Bad Request」表示客户端请求的报文有错误,但只是个笼统的错误。
- [ 401 ] 表示客户端未经授权,禁止访问。
- 「403 Forbidden」表示服务器禁止访问资源,并不是客户端的请求出错。
- 「404 Not Found」表示请求的资源在服务器上不存在或未找到,所以无法提供给客户端。
5xx 类状态码表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。
- 「500 Internal Server Error」与 400 类型,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道。
- 「501 Not Implemented」表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思。
- 「502 Bad Gateway」通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
- 「503 Service Unavailable」表示服务器当前很忙,暂时无法响应服务器,类似“网络服务正忙,请稍后重试”的意思。
GET 和 POST 有什么区别?
答:
根据 RFC 规范,GET 的语义是从服务器获取指定的资源,这个资源可以是静态的文本、页面、图片视频等。GET 请求的参数位置一般是写在 URL 中,URL 规定只能支持 ASCII,所以 GET 请求的参数只允许 ASCII 字符 ,而且浏览器会对 URL 的长度有限制(HTTP协议本身对 URL长度并没有做任何规定)。比如,你打开我的文章,浏览器就会发送 GET 请求给服务器,服务器就会返回文章的所有文字及资源。
根据 RFC 规范,POST 的语义是根据请求负荷(报文body)对指定的资源做出处理,具体的处理方式视资源类型而不同。POST 请求携带数据的位置一般是写在报文 body 中, body 中的数据可以是任意格式的数据,只要客户端与服务端协商好即可,而且浏览器不会对 body 大小做限制。比如,你在我文章底部,敲入了留言后点击「提交」(暗示你们留言),浏览器就会执行一次 POST 请求,把你的留言文字放进了报文 body 里,然后拼接好 POST 请求头,通过 TCP 协议发送给服务器。
具体来说:
- get是获取数据的,而post是提交数据的。
- GET产生一个TCP数据包;POST产生两个TCP数据包。具体来说GET,浏览器直接将http header和 data一起发送出去,服务器相应200;而POST是先发送header,服务器相应100之后在发送 data,服务器相应200 ok。
- GET把参数包含在URL中,POST通过request body传递参数。
- get安全性非常低,post安全性较高。 因为参数直接暴露在URL上,所以不建议使用get请求来传递 敏感信息。
HTTP有什么特点
答:
1、传输效率高
无连接:交换HTTP报文前,不需要建立HTTP连接
无状态:数据传输过程中,不保存任何历史和状态信息
传输格式简单:请求时,只需要传输请求方法和路径
2、传输可靠性高
采用TCP作为传输层协议
3、兼容性好
支持B/S、C/S模式
4、灵活性高
HTTP允许传输任意类型的数据对象
https用了什么机制来保证数据传输的安全性
答:
为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
HTTP和HTTPS的区别
答:
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
什么是TCP
答:
面向连接的、可靠的、基于字节流的传输层通信协议。
- 面向连接:一定是「一对一」才能连接,不能像 UDP 协议可以一个主机同时向多个主机发送消息,也就是一对多是无法做到的;
- 可靠的:无论网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端;
- 字节流:消息是「没有边界」的,所以无论我们消息有多大都可以进行传输。并且消息是「有序的」,当「前一个」消息没有收到的时候,即使它先收到了后面的字节,那么也不能扔给应用层去处理,同时对「重复」的报文会自动丢弃。
什么是TCP连接
答:
用于保证可靠性和流量控制维护的某些状态信息,这些信息的组合,包括Socket、序列号和窗口大小称为连接。
所以我们可以知道,建立一个 TCP 连接是需要客户端与服务器端达成上述三个信息的共识。
- Socket:由 IP 地址和端口号组成
- 序列号:用来解决乱序问题等
- 窗口大小:用来做流量控制
TCP头部格式
答:
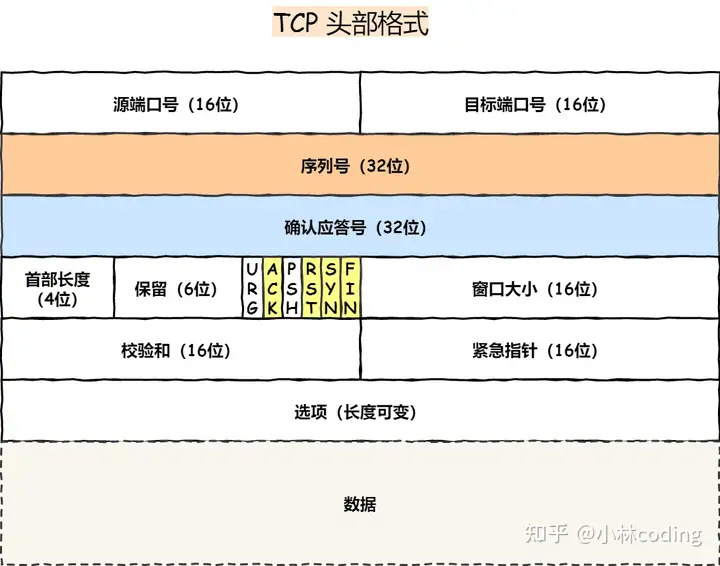
序列号:在建立连接时由计算机生成的随机数作为其初始值,通过 SYN 包传给接收端主机,每发送一次数据,就「累加」一次该「数据字节数」的大小。用来解决网络包乱序问题。
确认应答号:指下一次「期望」收到的数据的序列号,发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。用来解决丢包的问题。
控制位:
- ACK:该位为
1时,「确认应答」的字段变为有效,TCP 规定除了最初建立连接时的SYN包之外该位必须设置为1。 - RST:该位为
1时,表示 TCP 连接中出现异常必须强制断开连接。 - SYN:该位为
1时,表示希望建立连接,并在其「序列号」的字段进行序列号初始值的设定。 - FIN:该位为
1时,表示今后不会再有数据发送,希望断开连接。当通信结束希望断开连接时,通信双方的主机之间就可以相互交换FIN位为 1 的 TCP 段。
为什么需要TCP
答:
IP 层是「不可靠」的,它不保证网络包的交付、不保证网络包的按序交付、也不保证网络包中的数据的完整性。如果需要保障网络数据包的可靠性,那么就需要由上层(传输层)的 TCP 协议来负责。
因为 TCP 是一个工作在传输层的可靠数据传输的服务,它能确保接收端接收的网络包是无损坏、无间隔、非冗余和按序的。
如何唯一确定一个 TCP 连接呢?
答:
TCP 四元组可以唯一的确定一个连接,四元组包括如下:
- 源地址
- 源端口
- 目的地址
- 目的端口
源地址和目的地址的字段(32位)是在 IP 头部中,作用是通过 IP 协议发送报文给对方主机。
源端口和目的端口的字段(16位)是在 TCP 头部中,作用是告诉 TCP 协议应该把报文发给哪个进程。
有一个 IP 的服务器监听了一个端口,它的 TCP 的最大连接数是多少?
答:
服务器通常固定在某个本地端口上监听,等待客户端的连接请求。
因此,客户端 IP 和 端口是可变的,其理论值计算公式如下:

对 IPv4,客户端的 IP 数最多为 2 的 32 次方,客户端的端口数最多为 2 的 16 次方,也就是服务端单机最大 TCP 连接数,约为 2 的 48 次方。
当然,服务端最大并发 TCP 连接数远不能达到理论上限,会受以下因素影响:
-
文件描述符限制,每个 TCP 连接都是一个文件,如果文件描述符被占满了,会发生 too many open files。Linux 对可打开的文件描述符的数量分别作了三个方面的限制:
-
- 系统级:当前系统可打开的最大数量,通过 cat /proc/sys/fs/file-max 查看;
- 用户级:指定用户可打开的最大数量,通过 cat /etc/security/limits.conf 查看;
- 进程级:单个进程可打开的最大数量,通过 cat /proc/sys/fs/nr_open 查看;
-
内存限制,每个 TCP 连接都要占用一定内存,操作系统的内存是有限的,如果内存资源被占满后,会发生 OOM。
UDP 和 TCP 有什么区别呢?分别的应用场景是?
答:
UDP 不提供复杂的控制机制,利用 IP 提供面向「无连接」的通信服务。
UDP 协议真的非常简,头部只有 8 个字节( 64 位),UDP 的头部格式如下:
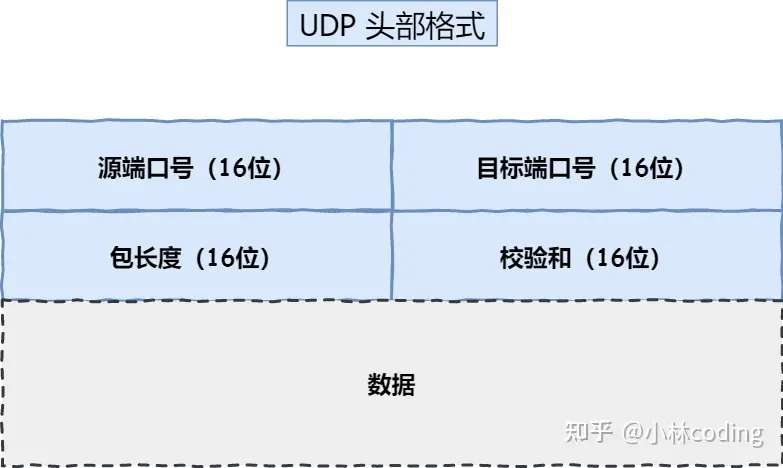
UDP 头部格式
- 目标和源端口:主要是告诉 UDP 协议应该把报文发给哪个进程。
- 包长度:该字段保存了 UDP 首部的长度跟数据的长度之和。
- 校验和:校验和是为了提供可靠的 UDP 首部和数据而设计,防止收到在网络传输中受损的 UDP包。
TCP 和 UDP 区别:
1. 连接
- TCP 是面向连接的传输层协议,传输数据前先要建立连接。
- UDP 是不需要连接,即刻传输数据。
2. 服务对象
- TCP 是一对一的两点服务,即一条连接只有两个端点。
- UDP 支持一对一、一对多、多对多的交互通信
3. 可靠性
- TCP 是可靠交付数据的,数据可以无差错、不丢失、不重复、按需到达。
- UDP 是尽最大努力交付,不保证可靠交付数据。
4. 拥塞控制、流量控制
- TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
- UDP 则没有,即使网络非常拥堵了,也不会影响 UDP 的发送速率。
5. 首部开销
- TCP 首部长度较长,会有一定的开销,首部在没有使用「选项」字段时是
20个字节,如果使用了「选项」字段则会变长的。 - UDP 首部只有 8 个字节,并且是固定不变的,开销较小。
6. 传输方式
- TCP 是流式传输,没有边界,但保证顺序和可靠。
- UDP 是一个包一个包的发送,是有边界的,但可能会丢包和乱序。
7. 分片不同
- TCP 的数据大小如果大于 MSS 大小,则会在传输层进行分片,目标主机收到后,也同样在传输层组装 TCP 数据包,如果中途丢失了一个分片,只需要传输丢失的这个分片。
- UDP 的数据大小如果大于 MTU 大小,则会在 IP 层进行分片,目标主机收到后,在 IP 层组装完数据,接着再传给传输层。
TCP 和 UDP 应用场景:
由于 TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
FTP文件传输;- HTTP / HTTPS;
由于 UDP 面向无连接,它可以随时发送数据,再加上UDP本身的处理既简单又高效,因此经常用于:
- 包总量较少的通信,如
DNS、SNMP等; - 视频、音频等多媒体通信;
- 广播通信;
TCP三次握手和四次挥手过程
答:
三次握手:
第一次:客户端将标志位SYN设置为1,随机产生一个seq=x(序列号),并将该数据包发送给服务端,客户端进入SYN_SENT状态,等待服务端确认
第二次:服务端收到数据包后,由标志位SYN=1可知client请求连接,服务端将标志位SYN和ACK都置1,ack=x+1(序列号),seq=y,并将该数据包发送给客户端确认连接请求,服务端进入SYN_RCVD状态
第三次:客户端收到确认后,检查ack(序列号)是否为x+1,ACK是否为1,如果正确,将数据包发给服务端,服务端检查ACK是否为1,ack是否为y+1,seq=x+1,如果是,则连接成功,服务器和客户端都进入ESTABLISHED
第一次作用:客户端确认自己可以发送数据, 服务器确认自己能收到数据。
客户端发送信息给服务器,服务器接受客户端信息
第二次作用:客户端确认自己能收到数据,服务器能发也能收 服务器确认自己能发
服务器发送应答给客户端,客户端接收应答和报文
第三次作用:服务器确认客户端可以收到
客户端应答服务器
四次挥手:
第一次:客户端发送FIN=1(序列号)给服务端,告诉服务端数据已经发送完毕,请求终止连接,此时客户端不能发送数据(不包括协议,比如应答这些),但还能接收数据,
第二次:服务端接受FIN包之后给客户端回一个ACK包告诉它自己已经收到,此时没有断开socket连接,而是等待剩下的数据传输完成
第三次:服务端等待数据传输完毕之后,向客户端发送FIN包(序列号),表明可以断开连接
第四次:客户端收到后,回应一个ACK包表明已经收到,等待一段时间,确保服务端没有数据再发来,然后彻底断开
TCP2次握手,4次握手行不行,为什么要3次
答:
TCP协议双方都必须维护一个序列号,三次握手的过程就是通信双方互相告知序列号起始值,并确认对方已经收到了序列号。
如果只是两次握手,至多只有连接发起方的起始序列号能被确认,另一方选择的序列号则是得不到确认,服务器这边无法判断客户端是否能接收。
普通回答:因为三次握手才能保证双方具有接收和发送的能力
高级回答:
1.三次握手才可以阻止重复历史连接的初始化(主要原因)
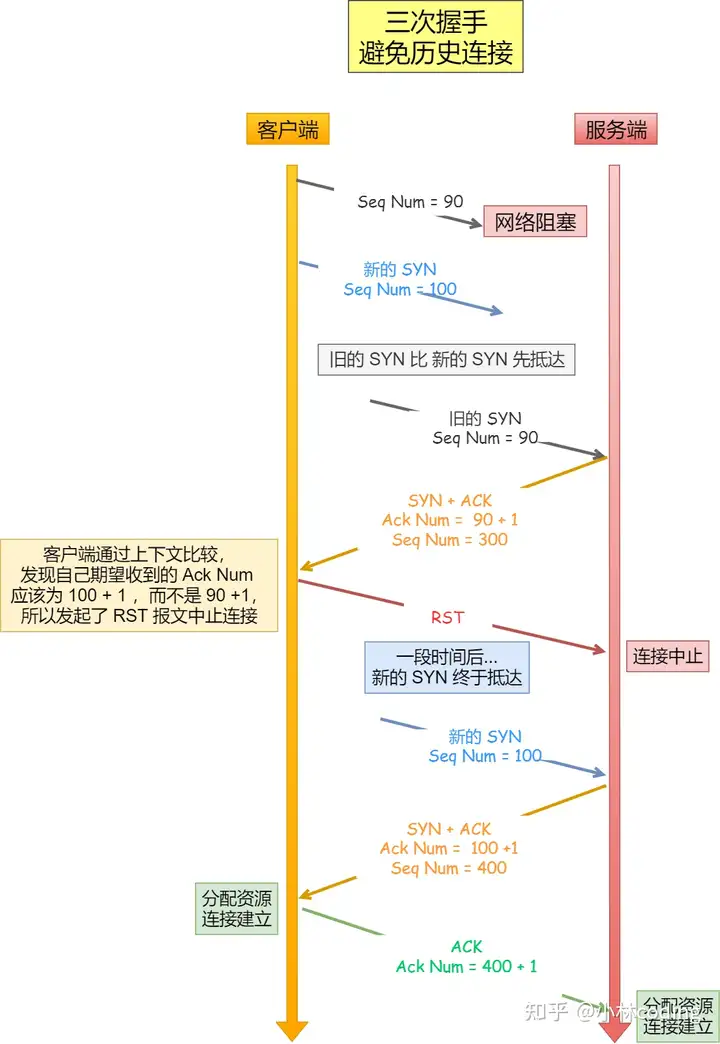
客户端连续发送多次 SYN 建立连接的报文,在网络拥堵情况下:
- 一个「旧 SYN 报文」比「最新的 SYN 」 报文早到达了服务端;
- 那么此时服务端就会回一个
SYN + ACK报文给客户端; - 客户端收到后可以根据自身的上下文,判断这是一个历史连接(序列号过期或超时),那么客户端就会发送
RST报文给服务端,表示中止这一次连接。
2.三次握手才可以同步双方的初始序列号
3.三次握手才可以避免资源浪费
两次:无法防止历史连接的建立,会造成双方资源的浪费,也无法可靠的同步双方序列号;
四次:三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数。
第三次握手可以发送数据吗?
答:
第三次握手是可以携带数据的,前两次握手是不可以携带数据的。第三次的报文可以携带客户到服务器的数据。
三次握手中每次握手信息对方没有收到会怎样?
答:
如果第一次握手消息丢失,那么请求方不会得到ack消息,超时后进行重传。
如果第二次握手消息丢失,那么请求方不会得到ack消息,超时后进行重传。
如果第三次握手消息丢失,那么Server 端该TCP连接的状态为SYN_RECV,并且会根据 TCP的超时重传机制,会等待3秒、6秒、12秒后重新发送SYN+ACK包,以便Client重新发送ACK包,如果重发指定次数之后,仍然未收到 client 的ACK应答,那么一段时间后,Server自动关闭这个连接。
三次挥手可以吗
答:
不行。假设是客户端主动断开,在第一次挥手中客户端发起请求断开,接着服务器回了个应答(第二次),表示我已经收到请求,等一段时间,等服务器的数据发送完成之后再向客户端发起断开(第三次),客户端接受到之后发起应答(第四次)。
如果是三次挥手那么只能是第二和第三次合并,即收到第一次挥手之后,发起应答和断开请求,但是这样会存在服务器有些数据还没发送完成就发起断不开
一句话:服务器回应你的请求断开,服务器可能还有数据没发送,所以应答和FIN就分开发。
为什么四次挥手时,客户端最后还要等待2MSL
答:
保证客户端发送的最后一个ACK报文能够到达服务器,因为这个报文可能丢失,站在服务器的角度看来,我已经发送了FIN+ACK报文请求断开,客户端没有给我回应,应该是我的请求报文没有收到,于是服务器就会重新发送一次,客户端就能够在这个2MSL时间内收到这个重传的报文,接着回应报文,如图所示:
TCP头部结构
答:
TCP有什么样的特点
答:
面向连接的,稳定可靠的,使用了滑动窗口和重传机制等保证稳定传输。
Socket网络编程中使用函数
答:
服务端:socket创建套接字,bind绑定IP和port,listen使套接字转为被动链接,accept等待客户端,write/read接收或发送数据,close关闭连接
客户端:socket创建套接字,bind绑定IP和port,connect连接服务器,send和recv或write/read接收或发送数据,close关闭连接
TCP如何保证可靠性
答:
1)检验和:
通过检验和的方式,接收端可以检测出来数据是否有差错和异常,假如有差错就会直接丢弃TCP段,重新发送。TCP在计算检验和时,会在TCP首部加上一个12字节的伪首部。检验和总共计算3部分:TCP首部、TCP数据、TCP伪首部
2)序列号/ 确认应答、超时重传
数据到达接收方之后,接收方会发送一个确认应答,表示已经收到数据段,并且确认序号会说明了它下一次需要接收的数据序列号,如果发送方没收到确认应答,那么发送方方会进行重发,这个等待时间一般是2*RTT(往返时间)+一个偏差值
如果一个包多次重发没有收到接收端的确认包,就会强制关闭连接
3)窗口控制与重发控制/快速重传(重复确认应答)
TCP会利用窗口控制来提高传输速度,意思是在一个窗口大小内,不用一定等到应答才能发送下一段数据,窗口大小就是无需等待确认而可以继续发送数据的最大值,如果不使用窗口控制,每一个没收到应答的数据都要重发
阻塞的原因
答:
网络能够提供的资源不足以满足用户的需求,这些资源包括缓存空间、链路带宽容量和中间节点的处理能力。由于互联网的设计机制导致其缺乏“接纳控制”能力,因此在网络资源不足时不能限制用户数量,而只能靠降低服务质量来继续为用户服务。
简单来说就是网络的资源不足,又无法很好地接纳信息,只能降低服务质量以此继续为用户服务。
TCP阻塞控制
答:
TCP的拥塞控制由4个核心算法组成:
1.“慢启动”(Slow Start):
发送方维持一个拥塞窗口 cwnd ( congestion window )的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送方让自己的发送窗口等于拥塞。
当建立新的TCP连接时,拥塞窗口(congestion window,cwnd)初始化为一个数据包大小。源端按cwnd大小发送数据,每收到一个ACK确认,cwnd就增加一个数据包发送量。
每经过一个传输轮次,拥塞窗口 cwnd 就加倍。
2.原则:
只要网络没有出现拥塞,拥塞窗口就再增大一些,以便把更多的分组发送出去。但只要网络出现拥塞,拥塞窗口就减小一些,以减少注入到网络中的分组数。
3.“拥塞避免”(Congestion voidance):
引入一个慢启动阈值ssthresh的概念,当cwnd <ssthresh的时候,tcp处于慢启动状态,否则,进入拥塞避免阶段。
让拥塞窗口cwnd缓慢地增大,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1
拥塞窗口cwnd按线性规律缓慢增长,比慢开始算法的拥塞窗口增长速率缓慢得多。
4.“快速重传 ”(Fast Retransmit)、“快速恢复”(Fast Recovery):
通常认为client接收到3个重复的ack后,就会开始快速重传,如果还有更多的重复ack,就开始快速恢复,事实上,我们可以把快速恢复看作是快速重传的后续处理,它不是一种单独存在的形态。
TCP慢启动
答:
慢启动(Slow Start),是传输控制协议(TCP)使用的一种阻塞控制机制。慢启动也叫做指数增长期。慢启动是指每次TCP接收窗口收到确认时都会增长。增加的大小就是已确认段的数目。这种情况一直保持到要么没有收到一些段,要么窗口大小到达预先定义的阈值。如果发生丢失事件,TCP就认为这是网络阻塞,就会采取措施减轻网络拥挤。一旦发生丢失事件或者到达阈值,TCP就会进入线性增长阶段。这时,每经过一个RTT窗口增长一个段。
TCP滑动窗口(流量控制)和重传机制
答:
滑动窗口是传输层进行流控的一种措施,接收方通过告诉发送方自己的窗口大小,从而控制发送方的发送速度,防止发送方发送速度过快导致接收方被淹没。滑动窗口的大小接收缓冲区的大小,告诉发送方,自己还能接收多少数据。TCP的滑动窗口解决了端到端的流量控制问题,允许接受方对传输进行限制,直到它拥有足够的缓冲空间来容纳更多的数据。这是一种流量控制技术。
重传机制就是TCP在发送数据时会设置一个计时器,若到计时器超时仍未收到数据确认信息,则会引发相应的超时或基于计时器的重传操作,计时器超时称为重传超时(RTO) 。另一种方式的重传称为快速重传,通常发生在没有延时的情况下。若TCP累积确认无法返回新的ACK,或者当ACK包含的选择确认信息(SACK)表明出现失序报文时,快速重传会推断出现丢包,需要重传。
滑动窗口过小会有什么影响
答:
造成很大的数据延迟。假设滑动窗口只有1,那么每次只能发送一个数据,并且发送只有接收方对这个数据进行确认之后才能进行下个数据的发送,如果数据较大那么就需要不停的对数据进行确认,就会造成很大延迟。
TCP粘包和拆包的含义
答:
由于TCP底层并不了解上层业务数据的具体含义,它会根据TCP缓冲区的实际情况进行包的划分。
TCP粘包就是指发送方发送的若干数据包到达接收方时粘成了一个包。从接收缓冲区来看,后一包数据的头紧接着前一包数据的尾,即把多个小的包封装成一个大的数据包发送。
TCP拆包就是一个完整的包可能会被TCP拆分成多个包进行发送。
粘包的原因
答:
(1)发送方原因:TCP默认使用Nagle算法(主要作用:减少网络中报文段的数量),Nagle算法主要做两件事情:
a.只有上一个分组得到确认,才会发送下一个分组。
b.收集多个小分组,在一个确认到来时一起封装并发送。
(2)接收方原因:TCP接收到数据包,应用层并不会立即处理。实际上,TCP将收到的数据包保存在接收缓存里,然后应用程序主动从缓存读取收到的分组。这样一来,如果TCP接收数据包到缓存的速度大于应用程序从缓存中读取数据包的速度,多个包就会被缓存,应用程序就有可能读取到多个首尾相接的包。
如何解决粘包和拆包
答:
粘包的问题出现是因为不知道一个用户消息的边界在哪,如果知道了边界在哪,接收方就可以通过边界来划分出有效的用户消息
所以:
1.固定长度的消息;
2.特殊字符作为边界;要注意特殊字符转义
3.自定义消息结构。
比如这个消息结构体,首先 4 个字节大小的变量来表示数据长度,真正的数据则在后面。
TCP一次可以发一个数据包还是几个数据包
答:
多个数据包。
UDP通信用到哪些函数,具体过程是怎样的
答:
TCP和UDP的区别
答:
1.TCP协议是有连接的,有连接的意思是开始传输实际数据之前TCP的客户端和服务器端必须通过三次握手建立连接,会话结束之后也要结束连接。而UDP是无连接的
2.TCP首部需20个字节(不算可选项),UDP首部字段只需8个字节
3.TCP有流量控制和拥塞控制,UDP没有,网络拥堵不会影响发送端的发送速率
4.TCP是一对一的连接,而UDP则可以支持一对一,多对多,一对多的通信。
5.TCP面向的是字节流的服务,UDP面向的是报文的服务。
TCP比UDP可靠的原因
答:
1.确认和重传机制
主要还是三次握手和四次挥手
2.数据排序
TCP有专门的序列SN字段,可提供re-order
3.流量控制
窗口和计时器的使用,TCP窗口中指明双方能够接发的最大数据数量
4.拥塞控制
TCP的拥塞控制由4个核心算法组成,“慢启动”,“拥塞避免”,“”快速重传,“快速恢复”。
什么时候使用TCP、什么时候用UDP
答:
使用TCP:当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP、SMTP等邮件传输的协议。
使用UDP:当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用UDP。
IP地址的含义
答:
是计算机为每台主机分配的一个逻辑地址,以此来屏蔽物理地址的差异。
32位二进制,通常以点十分制表示。
每个IP地址包括两个ID,即网络ID和主机ID。
A类 一个网络字节(最高位必须为1),三个主机字节 一般用于广域网 主机号数量为2^24 - 2,去除255和0
B类 两个网络字节,两个主机字节
C类 三个网络字节,一个主机字节 一般用于局域网 主机号数量为2^8-2
D类
E类
子网掩码的含义
答:
用来指明一个IP地址的哪些位标识的是主机所在的子网,以及哪些位标识的是主机的位掩码
子网掩码的作用
答:
求出网络ID和主机ID,判断出是哪类网络
如何利用子网掩码 求出网络ID
公式:IP地址 & 子网掩码
比如
192.168.1.128
255.255.255.0
得出192.168.1.0 即该网络为C类,3个字节表示网络ID,一个字节表示主机ID
对掩码取反之后得
192.168.1.128
0.0.0.255
可以得出主机ID128
还有种表示比如
192.168.2.128/24 其中24表示的是子网掩码是连续的24个1即255.255.255.0
如何判断两个IP地址释放在同一个网段
答:
只需要通过IP和子网掩码求出它们的网络ID,相同就是在同一个网段。
IPv4和IPv6的区别
答:
1)协议地址的区别
地址长度:IPv4协议具有32位(4字节)地址长度;IPv6协议具有128位(16字节)地址长度
地址的表示方法:IPv4地址是以小数表示的二进制数。 IPv6地址是以十六进制表示的二进制数。
2)地址解析协议
IPv4协议:地址解析协议(ARP)可用于将IPv4地址映射到MAC地址
IPv6协议:地址解析协议(ARP)被邻居发现协议(NDP)的功能所取代。
3)身份验证和加密
IPv6提供身份验证和加密,但IPv4不提供。
4)数据包的区别
包的大小:IPv4协议的数据包最小值为576个字节;IPv6协议的数据包最小值为1280个字节。
包头:IPv4长度为20~40字节;IPv6固定40字节。
字节序有什么影响
答:
大端:数据的高位存放在内存的低地址,低位存放在内存的高地址
小端:数据的高位存放在内存的高地址,低位存放在内存的低地址
不同机器中的大小端是不一样的,有的机器是大端,有的是小端,这个时候通讯就会有问题,
解决:
发送端使用API函数转换成大端,接收端再依据自己是小端还是大端对数据进行转换
比如:htons表示主机字节序转为网络字节序,网络字节序一定是大端
Linux驱动
文件IO
常用的文件操作函数有哪些
答:
linux下:
ftell() 函数用于得到文件位置指针当前位置相对于文件首的偏移字节数;
fseek()函数用于设置文件指针的位置;
rewind()函数用于将文件内部的位置指针重新指向一个流(数据流/文件)的开头;
ferror()函数可以用于检查调用输入输出函数时出现的错误。
int fseek(FILE *stream, long offset, int whence);
long ftell(FILE *stream);
void rewind(FILE *stream);
int fgetpos(FILE *stream, fpos_t *pos);该函数相当于ftell
int fsetpos(FILE *stream, const fpos_t *pos);该函数相当于fseek
select函数的用法
答:
select函数能够监听设置的fd集合。它会从用户空间拷贝 fd_set 到内核空间,然后在内核中遍历一遍所 有的 socket 描述符,如果没有满足条件的 socket 描述符,内核将进行休眠,当设备驱动发生 自身资源可读写后,会唤醒其等待队列上睡眠的内核进程,即在 socket 可读写时唤醒,或 者在超时后唤醒。
int select(int maxfdp1,fd_set *readset,fd_set *writeset,fd_set *exceptset,
, const struct timeval *timeout)
/*
maxfdp1:指定感兴趣的 socket 描述符个数,它的值是套接字最大 socket 描述符加1。注意0,1,2会事先被设置为感兴趣,也就是说我们自己的fd是从3开始。 默认:准输入 0 , 标准输出 1 , 标准错误 2
下面几个参数设置什么情况下该函数会返回:
• readset:指定这个 socket 描述符是可读的时候才返回。
• writeset:指定这个 socket 描述符是可写的时候才返回。
• exceptset:指定这个 socket 描述符是异常条件时候才返回。
• timeout:指定了超时的时间,当超时了也会返回。
*/
select函数的优缺点
答:
优缺点:(开销大,监听个数固定1024,遍历fd)
- 每次调用 select ,都需要把 fd 集合从用户态拷贝到内核态,这个开销在 fd 很多时会很
大。
- 同时每次调用 select 都需要在内核遍历传递进来的所有 fd ,这个开销在 fd 很多时也很
大。
- 每2次在 select() 函数返回后,都要通过遍历文件描述符来获取已经就绪的 socket
文件描述符集合操作有哪些?
答:
文件描述符集合的所有操作都可以通过这四个宏来完成,这些宏定义如下所示:
\#include <sys/select.h>
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);
这些宏按照如下方式工作:
⚫ FD_ZERO()将参数 set 所指向的集合初始化为空;
⚫ FD_SET()将文件描述符 fd 添加到参数 set 所指向的集合中;
⚫ FD_CLR()将文件描述符 fd 从参数 set 所指向的集合中移除;
⚫ 如果文件描述符 fd 是参数 set 所指向的集合中的成员,则 FD_ISSET()返回 true,否则返回 false,一般用来判断返回的文件描述符是否为目标文件描述符
注意事项:
每次调用select()函数 时,当监听到某个文件描述符可读或写或异常时,只把该文件描述符返回,也就是说,会修改我们前面设置的监听集合
举个例子:
这里添加两个文件描 述符到监听可读集合里,当有文件描述符可读时就会返回该文件描述符,假设是0,此时 readfds 指向的集合中就只包含了文件描述0,也就是说监听到文件描述符就绪后就会修改集合里面定义值,后面再想监听全部的文件描述符的话就需要事先搞个备份出来,比如:
fd_set rdfds**;**
My_rdfds= rdfds;
FD_ZERO**(&**rdfds**);**
FD_SET**(**0**, &**rdfds**);** //添加键盘
FD_SET**(**fd**, &**rdfds**);** //添加鼠标
ret **=** select**(**fd **+** 1**, &**My_rdfds**, NULL, NULL, NULL);**
每次监听都是监听My_dfds,这样就可以保证rdfds是不变的。
select epoll poll 函数区别
答:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。
而epoll其实也需要调用epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内部定义的等待队列)。这也能节省不少的开销。
Linux内核
Linux内核整体结构
答:
根据其对应的功能,Linux内核划分了五个子系统,分别负责如下功能:
- 进程管理:进程管理功能负责创建和销毁进程,并处理它们和外部的连接,不同进程间的通信也是整个系统的基本功能,除此之外,控制进程如何调度也是进程管理的一部分,总体来说,进程管理子系统就是在单个或者多个CPU上实现多个进程的抽象活动。
- 内存管理:内存是计算机的主要资源,用来如何管理内存的策略是决定系统性能的主要因素,内核在有限可用的资源之上为每个进程创建了一个虚拟地址空间,该机制可以让进程使用多于系统可用的内存空间。内核的不同部分和内存管理子系统交互的时候使用一组系统调用,包括简单的mallo/free函数以及更加复杂的函数,皆由此实现。
- 文件系统:Linux系统的思想,一切皆是文件,几乎每个对象都可以当作文件来处理,内核在没有结构化的硬件上构建了结构化的文件系统。此外Linux内核支持多个文件系统,也就是物理上组织数据的不同方式。Linux为其抽象统一的读写接口。
- 设备控制:设备驱动程序,几乎每个系统操作最终都会映射到物理设备上。所有的设备控制相关操作,皆有该子系统的代码来完成,这段代码就叫驱动程序,内核必须为每件外设嵌入对应的驱动程序。
- 网络功能:因为大部分网络操作和具体进程无关,所以网络功能也由内核管理:数据包的传入是异步事件,在某个进程处理之前,必须收集、标识、分发这些数据包,内核负责在应用程序和网络接口之间传递数据包,并根据网络活动控制程序的执行,此外所有的路由和地址解析也由该模块处理。
Linux内核的组成部分
答:
Linux内核主要由五个子系统组成:进程调度,内存管理,虚拟文件系统,网络接口,进程间通信,通常再外加一个系统调用。
具体来说:
Linux内核由以下几个主要组成部分构成:
进程管理:负责创建、调度和终止进程,以及处理进程间通信和同步。
内存管理:管理系统的物理内存和虚拟内存,包括分配、回收和页面调度等操作。
文件系统:提供对文件和目录的管理和访问,包括文件的创建、读写、删除等操作。
网络协议栈:支持各种网络协议,如TCP/IP协议栈,用于实现网络通信功能。
设备驱动程序:管理和控制硬件设备,通过与硬件交互来实现输入/输出功能。
系统调用:提供给用户空间的接口,允许用户程序请求内核执行特权操作。

Linux系统的组成部分
答:
Linux系统一般有4个主要部分:
内核、shell、文件系统和应用程序。

用户空间与内核通信方式有哪些?
答:
1)系统调用。用户空间进程通过系统调用进入内核空间,访问指定的内核空间数据;
2)驱动程序。用户空间进程可以使用封装后的系统调用接口访问驱动设备节点,以和运行在内核空间的驱动程序通信;
3)共享内存mmap。在代码中调用接口,实现内核空间与用户空间的地址映射,在实时性要求很高的项目中为首选,省去拷贝数据的时间等资源,但缺点是不好控制;
4)copy_to_user()、copy_from_user(),是在驱动程序中调用接口,实现用户空间与内核空间的数据拷贝操作,应用于实时性要求不高的项目中。
以及:
procfs(/proc)
sysctl (/proc/sys)
sysfs(/sys)
netlink 套接口
系统调用与普通函数调用的区别?
答:
系统调用:
1.使用INT和IRET指令,内核和应用程序使用的是不同的堆栈,因此存在堆栈的切换,从用户态切换到内核态,从而可以使用特权指令操控设备
2.依赖于内核,不保证移植性
3.在用户空间和内核上下文环境间切换,开销较大
4.是操作系统的一个入口点
普通函数调用:
1.使用CALL和RET指令,调用时没有堆栈切换
2.平台移植性好
3.属于过程调用,调用开销较小
4.一个普通功能函数的调用
总得来说:
系统调用与普通函数调用的区别在于执行的上下文和特权级别。系统调用是用户程序向内核请求执行特权操作的一种机制,因此会触发从用户态切换到内核态的过程,并且需要进行权限检查。普通函数调用则在同一个特权级别下执行,不涉及特权操作和切换。
系统调用read()/write(),内核具体做了哪些事情
系统调用read()和write()涉及以下主要操作:
用户空间程序调用read()/write()函数并传递相应参数。
内核接收到系统调用请求后,从用户提供的缓冲区中读取或写入数据。
内核对数据进行处理,包括检查权限、验证数据合法性等。如果需要,内核会将数据从内核空间复制到用户空间(read()),或者从用户空间复制到内核空间(write())。
内核返回操作结果给用户空间程序。
内核态,用户态的区别
答:
内核态,操作系统在内核态运行——运行操作系统程序
用户态,应用程序只能在用户态运行——运行用户程序
当一个进程在执行用户自己的代码时处于用户运行态(用户态),此时特权级最低,为3级,是普通的用户进程运行的特权级,大部分用户直接面对的程序都是运行在用户态。Ring3状态不能访问Ring0的地址空间,包括代码和数据;当一个进程因为系统调用陷入内核代码中执行时处于内核运行态(内核态),此时特权级最高,为0级。执行的内核代码会使用当前进程的内核栈,每个进程都有自己的内核栈。
什么是bootloader,uboot
答:
BootLoader是嵌入式设备中用来启动操作系统内核的一段程序。Bootloader是嵌入式系统在加电后执行的第一段代码,通过这段小程序,进行硬件初始化,获取内存大小信息等。
uboot(universal bootloader)是一种可以用于多种嵌入式CPU得BootLoader程序,换言之,uboot是bootloader的一个子集。uboot的核心作用就是启动操作系统内核,uboot的本质就是一段裸机程序。
bootloader、内核 、根文件的关系
答:
启动顺序:bootloader->linux kernel->rootfile->app
Bootloader全名为启动引导程序,是第一段代码,它主要用来初始化处理器及外设,然后调用Linux内核。Linux内核在完成系统的初始化之后需要挂载某个文件系统作为根文件系统(RootFilesystem),然后加载必要的内核模块,启动应用程序。(一个嵌入式Linux系统从软件角度看可以分为四个部分:引导加载程序(Bootloader),Linux内核,文件系统,应用程序。)
Bootloader启动过程
答:
-
计算机上电或重启后,固件(BIOS或UEFI)会进行自检和初始化,并加载Bootloader到内存中的指定位置。
-
Bootloader被执行,它首先进行硬件初始化,例如设置内存、存储等设备参数,并加载操作系统内核和根文件系统到内存中的指定位置。
-
一旦内核和根文件系统加载完毕,Bootloader会设置内核的启动参数(如命令行参数)并跳转到内核的入口点。
-
控制权转交给内核后,内核开始执行,在初始化阶段完成各种系统配置和资源管理。
-
内核会挂载根文件系统为系统的根目录,并根据配置加载其他必要的模块和驱动程序。
-
最后,内核启动第一个用户空间进程(通常是init进程),它负责系统初始化、服务启动和用户程序管理。
整个过程中,Bootloader起到了连接硬件和操作系统的桥梁作用,将控制权从固件传递给内核,并提供必要的参数和加载操作系统所需的文件。
Bootloader启动的两个阶段
答:
Stage1:汇编语言
1)基本的硬件初始化(关闭看门狗和中断,MMU(带操作系统),CACHE。配置系统工作时钟)
2)为加载stage2准备RAM空间
3)拷贝内核映像和文件系统映像到RAM中
4)设置堆栈指针sp
5)跳到stage2的入口点
Stage2:c语言
1)初始化本阶段要使用到的硬件设备(led uart等)
2)检测系统的内存映射
3)加载内核映像和文件系统映像
4)设置内核的启动参数
嵌入式系统中广泛采用的非易失性存储器通常是Flash,而Bootloader就位于该存储器的最前端,所以系统上电或复位后执行的第一段程序便是Bootloader。
大小端的概念
答:
主要弄清楚大小端的区别、各自的优点、判断大小端的三种方式和哪种时候用。
1.大小端(Endianness)是指在多字节数据类型存储时,字节序(即字节的排列顺序)的不同方式。主要有两种形式:
- 大端字节序(Big Endian):将高位字节存储在低地址,低位字节存储在高地址。
- 小端字节序(Little Endian):将低位字节存储在低地址,高位字节存储在高地址。
2.选择使用哪种字节序取决于硬件架构和通信协议的要求。各种字节序各有优点:
- 大端序:易于阅读和理解,对网络通信的兼容性较好; 符号位在所表示的数据的内存的第一个字节中,便于快速判断数据的正负和大小。
- 小端序:处理器直接访问最低有效字节,具有更高的效率,适用于大部分现代处理器架构;内存的低地址处存放低字节,所以在强制转换数据时不需要调整字节的内容。
3.判断大小端的三种方式:
- 内存中地址的比较:通过创建一个包含多字节数据的指针,并根据指针所指向的内存地址来判断字节序。
- 联合体(Union):创建一个联合体类型,其中包括一个多字节数据类型和对应的字节型数组。访问并比较字节数组的第一个元素即可判断字节序。
- 位操作:通过将数据类型强制转换为字节类型,然后检查字节的顺序来判断字节序。
4.哪种时候用:
小端存储:常见于本地主机上(也有部分类型主机为大端存储)。
大端存储:常见于网络通信上,网际协议TCP/IP在传输整型数据时一般使用大端存储模式表示,例如TCP/IP中表示端口和IP时,均采用的是大端存储。
linux下检查内存状态的命令
答:
1)查看进程:top
2)查看内存:free
3)cat /proc/meminfo
4)vmstat
假如一个公司服务器有很多用户,你使用top命令,可以看到哪个同事在使用什么命令,做什么事情,占用了多少CPU。
一个程序从开始运行到结束的完整过程(四个过程)
答:
- 编译(Compilation):将源代码文件转换为可执行的目标代码,通常通过编译器完成。
- 链接(Linking):将目标代码与所需的库函数进行链接,生成最终的可执行文件。链接器将各个模块之间的引用和符号解析为可执行代码。
- 加载(Loading):将可执行文件从存储介质加载到内存中,并为其分配必要的资源。加载器负责解析可执行文件的结构,创建进程并将代码和数据加载到适当的内存位置。
- 执行(Execution):处理器按照指令在内存中的顺序执行程序,执行各个操作,包括数据操作、控制流程和与外部环境的交互。
BSS段、数据段、代码段、堆和栈的含义
BSS段:存放程序中未初始化的全局变量的一块内存区域,BSS段属于静态内存分配。
数据段:存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
代码段:存放程序执行代码的一块内存区域。
堆(heap):存放进程运行中被动态分配的内存段,内存手动申请手动释放
栈(stack):栈又称堆栈, 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。内存自动申请自动释放
什么是堆,栈,内存泄漏,内存溢出和内存越界?
答:
堆(Heap)是用于动态分配内存的区域,用于存储程序运行时创建的对象和数据。堆的大小通常由操作系统管理,并通过特定的分配和释放方法(如malloc和free)来进行内存的分配和释放。
栈(Stack)是一种线程专用的内存区域,用于存储局部变量、函数调用、参数和返回地址等临时数据。栈的大小通常较小且有限,由编译器和运行时环境进行管理,自动分配和释放。
内存泄漏是指堆内存的泄漏。堆内存是指程序从堆中分配的,大小任意的(内存块的大小可以在程序运行期决定),使用完后必须显式释放的内存。应用程序一般使用malloc,new等函数从堆中分配到一块内存,使用完后,程序必须负责相应的调用free或delete释放该内存块,否则,这块内存就不能被再次使用。
内存溢出是要求分配的内存超出了系统能给的,系统不能满足需求,于是产生溢出。
内存越界是向系统申请了一块内存,而在使用内存时,超出了申请的范围(常见的有使用特定大小数组时发生内存越界)
内存溢出问题是 C 语言或者 C++ 语言所固有的缺陷,它们既不检查数组边界,又不检查类型可靠性(type-safety)。众所周知,用 C/C++ 语言开发的程序由于目标代码非常接近机器内核,因而能够直接访问内存和寄存器,这种特性大大提升了 C/C++ 语言代码的性能。只要合理编码,C/C++ 应用程序在执行效率上必然优于其它高级语言。然而,C/C++ 语言导致内存溢出问题的可能性也要大许多。
堆和栈的区别
答:
堆(Heap)是动态分配内存的区域,用于存储程序运行时创建的对象和数据。堆的大小通常由操作系统管理,并通过特定的分配和释放方法(如malloc和free)来进行内存的分配和释放。堆上的内存分配是手动控制的,没有固定的分配顺序。
栈(Stack)是一种线程专用的内存区域,用于存储局部变量、函数调用、参数和返回地址等临时数据。栈的大小通常较小且有限,由编译器和运行时环境进行管理,自动分配和释放。栈上的内存分配是自动控制的,遵循后进先出(LIFO)原则
主要区别:
分配方式:堆上的内存分配是手动控制的,需要显式地申请和释放内存。栈上的内存分配是自动控制的,由编译器和运行时环境自动处理。
管理机制:堆的内存管理通常由操作系统负责,通过动态内存分配算法来管理堆上的内存。栈的内存管理由编译器和运行时环境负责,通过栈指针控制栈上的内存使用。
大小与生命周期:堆的大小通常较大且灵活,存储动态分配的对象和数据。栈的大小通常较小且有限,存储局部变量和临时数据。堆上的内存可以在程序运行期间一直存在,直到显式释放。栈上的内存随着函数的调用和返回而自动分配和释放。
死锁的原因、条件
答:
产生死锁的原因主要是:
(1) 因为系统资源不足。
(2) 进程运行推进的顺序不合适。
(3) 资源分配不当等。
如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则就会因争夺有限的资源而陷入死锁。其次,进程运行推进顺序与速度不同,也可能产生死锁
这四个条件是死锁的必要条件,只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
(1) 互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3) 不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4) 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
死锁的四个条件及处理方法
(1)互斥条件:一个资源每次只能被一个进程使用。
(2) 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
(3)不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
(4)循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
解决死锁的方法分为死锁的预防,避免,检测与恢复三种。
硬链接与软链接
答:
链接操作实际上是给系统中已有的某个文件指定另外一个可用于访问它的名称。对于这个新的文件名,我们可以为之指定不同的访问权限,以控制对信息的共享和安全性的问题。如果链接指向目录,用户就可以利用该链接直接进入被链接的目录而不用打一大堆的路径名。而且,即使我们删除这个链接,也不会破坏原来的目录。
1>硬链接
硬链接只能引用同一文件系统中的文件。它引用的是文件在文件系统中的物理索引(也称为inode)。当您移动或删除原始文件时,硬链接不会被破坏,因为它所引用的是文件的物理数据而不是文件在文件结构中的位置。硬链接的文件不需要用户有访问原始文件的权限,也不会显示原始文件的位置,这样有助于文件的安全。如果您删除的文件有相应的硬链接,那么这个文件依然会保留,直到所有对它的引用都被删除。
2>软链接(符号链接)
软连接,其实就是新建立一个文件,这个文件就是专门用来指向别的文件的(那就和windows 下的快捷方式的那个文件有很接近的意味)。软连接产生的是一个新的文件,但这个文件的作用就是专门指向某个文件的,删了这个软连接文件,那就等于不需要这个连接,和原来的存在的实体原文件没有任何关系,但删除原来的文件,则相应的软连接不可用。
//链接
$ ln [options] FILE_NAME LINK_NAME
linux下的文件有哪些组成?
答:
文件是存储在硬盘上的,硬盘的最小存储单位叫做“扇区”(sector),每个扇区存储512字节。
一般连续八个扇区组成一个“块”(block),一个块是4K大小,是文件存取的最小单位。操作系统读取硬盘的时候,是一次性连续读取多个扇区,即一个块一个块的读取。
文件数据包括实际数据与元信息(类似文件属性)。文件数据存储在“块”中,存储文件元信息(比如文件的创建者、创建日期、文件大小、文件权限等)的区域就叫做 inode。因此,一个文件必须占用一个 inode,并且至少占用一个 block。
inode不包含文件名。文件名是存放在目录当中的。Linux系统中一切皆文件,因此目录也是一种文件。
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称,文件名和inode号码是一一对应关系,每个inode号码对应一个文件名。
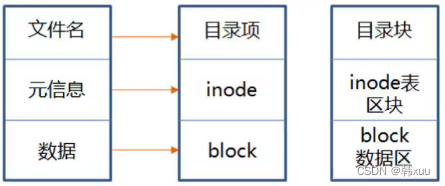
linux系统访问文件的步骤?
答:
当用户在Linux系统中试图访问一个文件时,系统会先根据文件名去查找它对应的inode号码;通过inode号码,获取inode信息,根据incde信息,看该用户是否具有访问这个文件的权限,如果有,就指向相对应的数据block,并读取数据
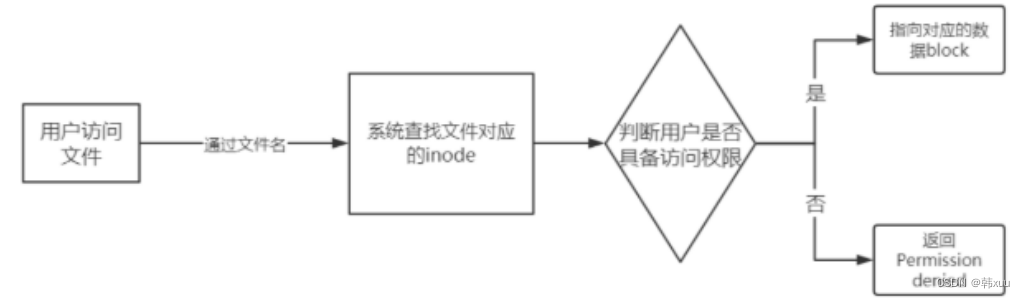
什么是inode
答:
“inode”实际上是“index node”的缩写,它描述了在类Unix系统中的一个文件系统对象(如一个文件或目录)。在GNU/Linux文件系统中,每个文件和目录均需被分配一个inode,不存储任何实际的数据。每个inode都存储着对象数据的属性以及在磁盘块位置,其中对象数据的属性可能包含元数据(最后修改时间,权限,修改)以及所有者和许可数据。
inode大小
答:
- inode也会消耗硬盘空间,每个inode的大小,一般是128字节或256字节。
- inode的总数,在格式化时就确定。
- 查看每个硬盘分区的inode总数和已经使用的数量,可以使用 df -i
如何查看文件的inode等详细信息
答:
ls -i //文件或目录查看文件inode号
//注意:修改文件内容时,mtime改变,ctime会改变,inode也会改变
stat 文件或目录//查看inode等详细信息
比如:
stat initial-setup-ks.cfg
文件:"initial-setup-ks.cfg"
大小:2080 块:8 IO 块:4096 普通文件
设备:fd00h/64768d Inode:67170387 硬链接:1
权限:(0644/-rw-r--r--) Uid:( 0/ root) Gid:( 0/ root)
环境:system_u:object_r:admin_home_t:s0
最近访问(atime):2022-07-29 21:48:52.562988764 +0800
最近更改(mtime):2022-07-29 21:48:52.563988763 +0800
最近改动(ctime):2022-07-29 21:48:52.563988763 +0800
创建时间:
linux下文件类型和访问权限如何查看
答:
通过\(ll\)命令可查看
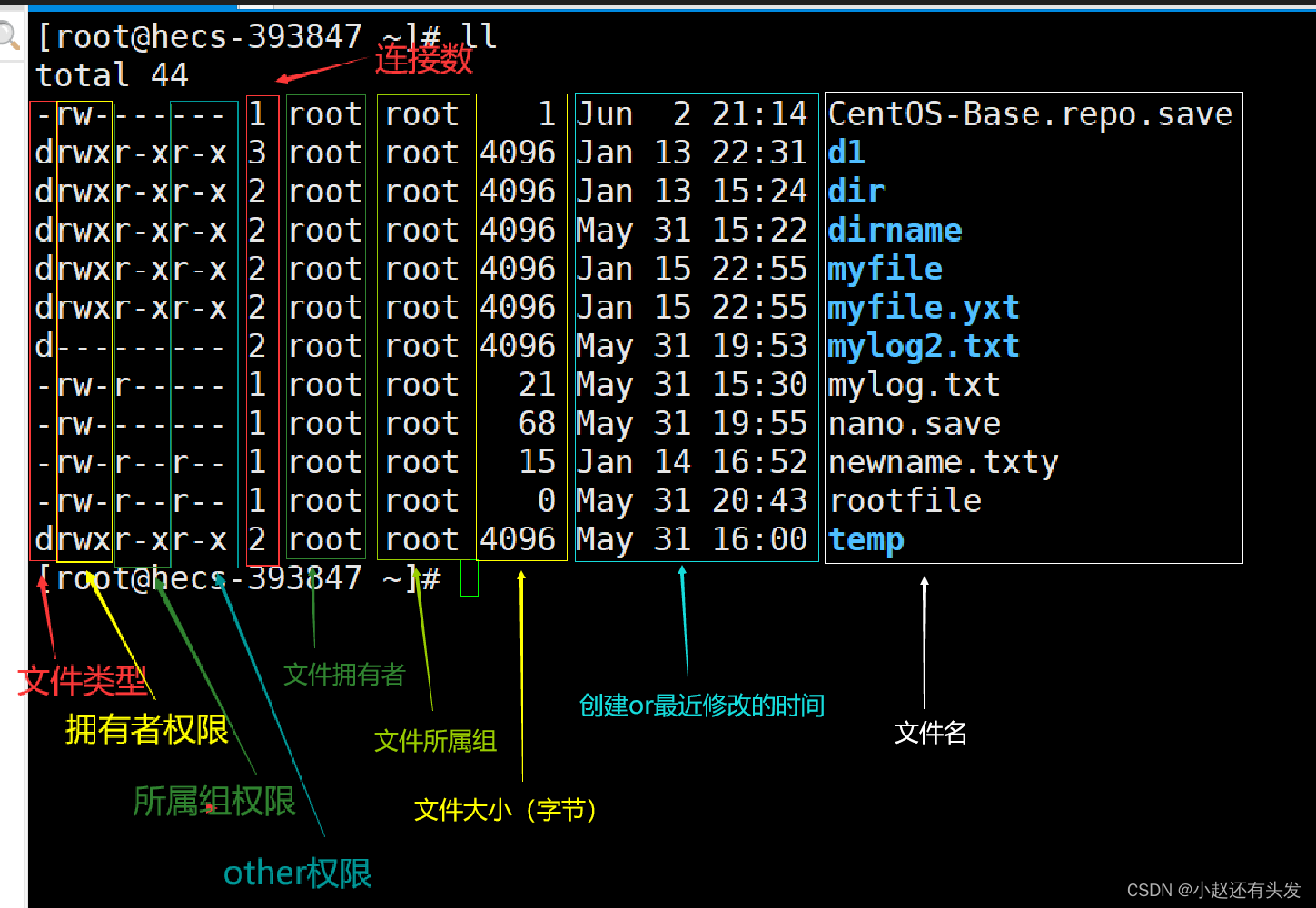
1.文件类型
Linux操作系统不用文件后缀区分文件类型,而是用文件属性中第一列的第一个字符来区分。
d(常见):文件夹,目录
-(常见):普通文件,文本,可执行,归档文件等
l:软链接(类似Windows的快捷方式)
b:块设备文件(例如硬盘、光驱等)
p:管道文件
c:字符设备文件(例如屏幕等串口设备)
s:套接口文件
2.访问权限
- 读(r/4):Read对文件而言,具有读取文件内容的权限;对目录来说,具有浏览该目录信息的权限
- 写(w/2):Write对文件而言,具有修改文件内容的权限;对目录来说具有删除移动目录内文件的权限
- 执行(x/1):execute对文件而言,具有执行文件的权限;对目录来说,具有进入目录的权限
注:数字分别对应相应权限的八进制数字。
atime,mtime和ctime的含义
| 最近访问(atime) | 最后一次访问文件或目录的时间 |
|---|---|
| 最近更改(mtime) | 最后一次修改文件或目录(内容)的时间 |
| 最近改动(ctime) | 最后一次改变文件或目录(属性)的时间 |
inode有什么特别的作用吗?
答:
由于 inode 号与文件名分离,导致Linux系统会有以下几种特殊现象:
1.文件名包含特殊字符,无法正常删除,直接删除inode可起到删除文件的作用(说明文件名和inode是软链接?)。
2.mv移动文件或重命名文件,只是改变文件名,不影响inode号
3.vim修改文件后,inode会改变(因为vim是编辑原文件.swap,修改完成后替换)
虚拟内存,虚拟地址与物理地址的转换
答:
虚拟内存(Virtual Memory)是计算机系统中的一种技术,将物理内存和磁盘之间的交换空间作为逻辑地址空间的延伸。虚拟内存允许程序使用连续的逻辑地址空间,而不需要连续的物理内存空间。虚拟地址是程序中使用的逻辑地址,而物理地址是实际对应于主存中的地址。
虚拟地址与物理地址的转换是通过操作系统的内存管理单元(Memory Management Unit,MMU)实现的。MMU使用页表或段表等数据结构来映射虚拟地址到物理地址。当程序访问虚拟地址时,MMU根据页表或段表的映射关系进行地址转换,将虚拟地址转换为对应的物理地址
计算机中,32bit与64bit有什么区别
答:
64bit计算主要有两大优点:可以进行更大范围的整数运算;可以支持更大的内存。
64位操作系统下的虚拟内存空间大小:地址空间大小不是\(2^{32}\) ,也不是\(2^{64}\),而一般是\(2^{48}\)。因为并不需要\(2^{64}\)那么大的寻址空间,过大的空间只会造成资源的浪费。所以64位Linux一般使用48位表示虚拟空间地址,40位标识物理地址。
中断和异常的区别
答:
内中断:同步中断(异常)是由cpu内部的电信号产生的中断,其特点为当前执行的指令结束后才转而产生中断,由于有cpu主动产生,其执行点必然是可控的。
外中断:异步中断是由cpu的外设产生的电信号引起的中断,其发生的时间点不可预期。
具体来说:
中断是由外部事件触发的信号,用于中断当前正在执行的程序流程,以处理紧急或优先级较高的任务。中断可以来自硬件设备(如键盘、鼠标、定时器)或其他外部源。中断通常会打断当前正在执行的程序,转而执行中断处理程序,然后返回到被中断的程序继续执行。
异常是指在程序执行过程中遇到的错误或异常情况,例如除零错误、内存访问错误等。异常通常由处理器检测到,并触发相应的异常处理机制。异常可以导致程序的终止或转到异常处理程序进行处理,具体处理方式取决于操作系统或编程语言的实现。
中断怎么发生,中断处理流程
答:
请求中断→响应中断→关闭中断→保留断点→中断源识别→保护现场→中断服务子程序→恢复现场→中断返回。
具体来说:
发生:中断通常由硬件设备或其他外部源发出一个中断请求信号(IRQ),将控制权转移到中断向量表中对应的中断服务程序。
响应:处理器接收到中断请求信号后,暂停当前执行的指令,保存相关上下文信息(如寄存器状态),并跳转到中断向量表中对应的中断服务程序。
处理:中断服务程序执行与中断相关的处理逻辑,可能包括读取设备状态、处理数据、更新数据结构等。
恢复:中断服务程序执行完毕后,恢复之前保存的上下文信息,将控制权返回到被中断的程序继续执行。
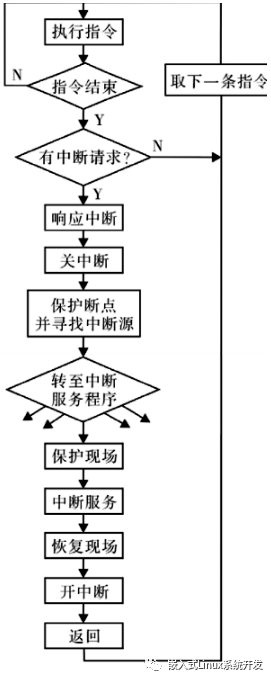
Linux 操作系统挂起、休眠、关机相关命令
答:
关机命令有halt, init 0, poweroff ,shutdown -h 时间,其中shutdown是最安全的
重启命令有reboot,init 6,,shutdow -r时间
在linux命令中reboot是重新启动,shutdown -r now是立即停止然后重新启动。
具体来说:
挂起(Suspend):用于将系统进入低功耗状态,暂停所有活动并保留当前状态。在绝大多数Linux发行版中,使用systemctl suspend或pm-suspend命令来挂起系统。
休眠(Hibernate):将系统当前的状态保存到硬盘,并关闭电源以实现完全的断电。休眠后系统可以恢复到之前的状态。在大多数Linux发行版中,使用systemctl hibernate或pm-hibernate命令来进行休眠操作。
关机(Shutdown):用于安全地关闭操作系统并关闭计算机。在绝大多数Linux发行版中,使用shutdown、poweroff或halt命令来进行关机操作。
说一个linux下编译优化选项
答:
加:-o
在有数据cache情况下,DMA数据链路为
答:
外设-DMA-DDR-cache-CPU
linux命令
答:
1、改变文件属性的命令:chmod (chmod 777 /etc/squid 运行命令后,squid文件夹(目录)的权限就被修改为777(可读可写可执行))
2、查找文件中匹配字符串的命令:grep
3、查找当前目录:pwd
4、删除目录:rm -rf 目录名
5、删除文件:rm 文件名
6、创建目录(文件夹):mkdir
7、创建文件:touch
8、vi和vim 文件名也可以创建
9、解压:tar -xzvf 压缩包
打包:tar -cvzf 目录(文件夹)
10、查看进程对应的端口号
1、先查看进程pid
ps -ef | grep 进程名
2、通过pid查看占用端口
netstat -nap | grep 进程pid
硬实时系统和软实时系统
答:
软实时系统:
Windows、Linux系统通常为软实时,当然有补丁可以将内核做成硬实时的系统,不过商用没有这么做的。
硬实时系统:
对时间要求很高,限定时间内不管做没做完必须返回。
VxWorks,uCOS,FreeRTOS,WinCE,RT-thread等实时系统;
MMU基础
答:
现代操作系统普遍采用虚拟内存管理(Virtual Memory Management) 机制,这需要MMU( Memory Management Unit,内存管理单元) 的支持。有些嵌入式处理器没有MMU,则不能运行依赖于虚拟内存管理的操作系统。
也就是说:操作系统可以分成两类,用MMU的、不用MMU的。
用MMU的是:Windows、MacOS、Linux、Android;不用MMU的是:FreeRTOS、VxWorks、UCOS……
与此相对应的:CPU也可以分成两类,带MMU的、不带MMU的。
带MMU的是:Cortex-A系列、ARM9、ARM11系列;
不带MMU的是:Cortex-M系列……(STM32是M系列,没有MMU,不能运行Linux,只能运行一些UCOS、FreeRTOS等等)。
MMU就是负责虚拟地址(virtual address)转化成物理地址(physical address),转换过程比较复杂,可以自行百度。
项目
基于CC2530和Zigbee的无线传感网
基于Qt的网络聊天室的多线程实现
综合题
技术论述
性格论述
职业规划
我目前的职业规划大概分为两个阶段:
第一阶段是快速融入团队,熟悉环境及业务,尽快熟练掌握岗位需要的技术;
第二阶段是跟随公司发展,让自己的各项能力再上一个台阶。
这是目前的想法,之后会根据情况动态调整。
自我介绍
面试官,您好。我是李志强,目前就读于广州大学电子与通信工程学院,研三。