后门攻击是针对 DNN 分类器的一种重要的对抗性威胁,当嵌入后门时,一个或多个测试样本将被(错误地)分类到攻击者的目标类中。本文关注文献中常见的 post-training 后门防御场景,其中防御者的目的是检测一个训练后的分类器是否在没有任何访问训练集的情况下受到了后门攻击。许多训练后的检测器被设计用来检测一个或几个特定的后门攻击(例如,补丁替换或附着攻击)。当攻击者(防御者未知)使用的后门嵌入函数与防御者假设的后门嵌入函数不同时,这些检测器可能会失效。
相比之下,我们提出了一种 post-training 防御,它使用任意类型的后门嵌入来检测后门攻击,而不对后门嵌入类型做任何假设。我们的检测器利用了后门攻击的影响,独立于后门嵌入机制,对 softmax 层之前的分类器输出的景观。对于每个类,都估计了一个最大边际统计量。然后,通过对这些统计数据应用一个无监督的异常检测器来执行检测推断。因此,我们的检测器不需要任何合法的干净样本,并且可以有效地检测具有任意数量的源类的后门攻击。在四个数据集上,对于三种不同类型的后门模式和各种攻击配置,展示了比几种最先进的方法的这些优点。最后,我们提出了一种新的,通用的方法,后门缓解一旦检测出来。缓解方法在第一次IEEE木马删除比赛中获得亚军。该代码已在网上提供。
1. Introduction
虽然深度神经网络(DNNs)在许多研究领域都很成功,但它们很容易受到[1]的攻击。后门攻击或木马是一种重要的攻击类型,当来自一个或多个源类的测试样本嵌入了攻击者的后门模式[2]-[4]时,DNN分类器将预测攻击者的目标类。后门攻击通常是通过用来自源类的样本毒害分类器的训练集,并嵌入了相同的后门将在推理过程中使用的模式,并标记为目标类[5]。由于成功的后门攻击不会降低分类器在干净测试样本上的准确性,因此它们不能很容易被检测到。
针对后门攻击的防御有时会在分类器的训练阶段[7]-[14]期间部署,但这也通常是不可行的(例如,考虑到专有系统和遗留系统)。在这里,我们考虑一个实际的 post-training 场景,其中防御者是,例如,下载的预训练分类器的下游用户,目的是检测分类器是否被攻击(例如,提供预训练模型[15]的模型动物园),不访问分类器的训练集。防御者也不能访问任何未受攻击的分类器作为参考(例如,设置检测阈值)。
许多训练后的防御者都假设防守者独立地拥有来自每个职业的少量干净、合法的样本。这些样本可以使用:
i)对假定的后门模式进行逆向工程,这是异常检测[16]-[22]的基础;或
ii)训练有或没有(已知的)后门攻击的阴影神经网络,在此基础上训练一个二元“元分类器”来预测被检查的分类器是否被后门攻击的[23]-[25]。然而,这些方法假设攻击者使用的嵌入后门模式的机制是已知的。
对于基于逆向工程的防御,后门模式的嵌入功能明确地涉及到逆向工程问题,例如[16];因此,这些方法可能无法有效地检测与反向工程不同的模式类型的后门攻击。对于元分类方法,假设有一个后门模式池来训练具有后门攻击[24]的阴影神经网络;这些方法可能不能很好地推广到训练池中看不到的后门模式。
在此,我们提出了一种基于最大边际的后门检测方法(MM-BD),该方法不对攻击者使用的后门模式类型不做任何假设。我们的检测方法是基于一种新的方法来捕获分类器的输出(在softmax之前)的非典型性。特别地,我们提出了一种新的最大边际(MM)检测统计量。该统计量是通过从多个随机输入模式开始解决一个边际最大化问题来获得的,然后选择一个边际最大的解。我们将展示,使用这些统计数据的方法是可以区分后门目标类和非后门类的,而不管所使用的后门模式/嵌入函数的类型如何。基于mm的检测不需要清洁的样品。将完全无监督异常检测器应用于最大边际统计来进行检测推断。值得注意的是,我们的方法的设计允许它检测具有任意数量的源类的后门攻击,并且比许多现有的方法具有更好的计算效率。
我们还提出了一种基于最大边际的后门缓解方法(MM-BM),它确实需要使用一些干净的样本。该方法使用一组优化的上界(每个神经元一个)来抑制最大可能的神经元激活,而不降低分类器在干净样本上的准确性。与现有的方法不同,我们不修改DNN体系结构或任何训练过的参数。
我们的贡献总结如下:
我们揭示,在受害者分类器的输出函数中,最大边际(MM)可以作为攻击的签名(对于具有足够高攻击成功率的攻击),而不管后门模式类型。在此基础上,我们提出了MM-BD,一种不需要对攻击者使用的后门模式类型进行任何假设的训练后后门检测方法。
•MM-BD不需要任何清洁的样品来进行检测。此外,如实验所示,它准确地,有效地检测后门攻击,而不管攻击者使用的源类的数量。
•我们展示了MM-BD的性能相比,许多最近的训练后检测器的标准攻击设置。这些实验包括四个数据集,三种不同类型的后门模式,以及不同的DNN架构。
我们评估MM-BD对许多新出现的,以前的探测器没有考虑到的后门攻击。这些攻击包括另外两种类型的后门模式和六种攻击设置。这些攻击大多假设攻击者对训练过程有很强的控制能力;相比之下,对MM-BD的假设却很少。
•我们提出了一种新的后门缓解方法(MMBM),通过对每个神经元的激活应用一个优化的上界。这种方法不修改DNN架构或任何可训练的参数。
2.背景
本节提供了关于后门攻击和防御的背景资料。我们从Sec中对机器学习(ML)系统的新威胁的高级描述开始。2.1.在第二节中。2.2,我们引入了经典的后门攻击,包括其目标和发射策略。在第二节中。2.3和秒。2.4,我们分别给出了后门防御和高级后门攻击的分类。
2.1. Threats to Machine Learning Systems
机器学习,特别是深度神经网络,开始被用于各种安全关键应用,如欺诈检测,如[26],[27]和医疗保健,如[28],[29]。然而,ML系统受到敌对攻击[30]的威胁。通常,ML系统涉及一个训练阶段和一个推理阶段[31]。因此,对抗性攻击也可以分为训练阶段攻击和推理阶段攻击[32]。
推理阶段攻击的目的是导致ML系统产生对手选择的输出,或收集关于模型特征[32]的证据。例如,对抗性逃避攻击使用精心制作的对抗性例子(即,带有对抗性扰动的输入)来误导ML模型,以做出不正确的预测,[1],[33]-[37]。另一个例子是,模型提取攻击复制了受害者ML模型的功能映射规则,这是模型所有者的一个重要资产。查询受害者模型[38]-[41]。
另一方面,训练阶段攻击的目的是通过修改模型的训练集来破坏模型。例如,数据中毒攻击通过使用错误标记的样本[42]-[46]中毒其训练集,从而降低了受害者模型的预测精度。本文关注的后门攻击也是一种训练阶段攻击,因为受害者模型将植入一个后门。
2.2. Classical Backdoor Attacks
2.3. Backdoor Defenses
后门防御可以在分类器的训练阶段、训练后或推理期间部署。每一个场景都具有不同的防御者角色和能力。
训练过程中的后门防御的目的是从可能中毒的训练集[7]-[14]中产生一个无后门的分类器。现有的防御从训练集[7]-[9]中检测并去除可疑样本,识别异常值,只对非离群、可信样本[10]-[12]进行训练,或修改训练损失或训练程序,以更好地对抗数据中毒[13]的鲁棒性[13],[14]。
在推理阶段部署的后门防御旨在检测嵌入了后门模式[51]-[56]的测试样本,也可能寻求纠正这些样本上的决策。其中一种方法通过重叠大量的良性样本或随机噪声来扰动输入样本,然后使用集成预测结果来检测[51]、[52]。在[53],[54]中,可以识别出输入空间的可疑区域。在[55],[57]中,干净样本的潜在表示被建模,这样具有后门模式的测试时间输入将被检测为离群值。
在这里,防御者拥有分类器用户的有利位置,无法访问训练集。训练后的一个主要防御任务是后门检测,其中防御者的目标是检测一个给定的分类器是否被后门攻击,[25],[58]。现有的防御要么
i)回复所有类的假定的后门模式,并检测这些反向工程模式是否相对于其他模式异常(例如,模式大小异常小)[16]-[22];或
ii)训练一个“元分类器”来识别从被检查的分类器中提取的特征[23],[24]。
另一个训练后的防御任务是后门缓解,它旨在从受害者分类器[59]中删除学习到的后门映射。主流方法要么微调分类器,以“解开”后门映射[16]、[60]、[61],要么修剪可能被后门模式[62]激活的神经元。
2.4. Advanced Backdoor Attacks
最近,有人提出先进的后门攻击,以实现更好的对人类检查人员的攻击。清洁标签攻击使用仅从目标分类类[63],[64]中收集的样本来毒害分类器的训练集。这些样本被扰动,以删除原始的类区分特征和/或嵌入与后门模式相关联的特征。这些样本没有重新标记,这有助于避免在训练期间对人类的怀疑。在[47],[65],[66]中,后门模式被优化(例如,使用代理分类器),使其在测试时对人类无法察觉。实现这种测试时间不可感知性的其他策略包括在频域[67]中嵌入后门模式或利用图像上的扭曲信息来嵌入[68]。或者,可见的后门模式可以巧妙地嵌入,例如,作为一个场景-可信的物理对象[69]或模拟在光滑表面[70]上的物理反射。
也有先进的自适应攻击被提出来逃避特定类型的后门防御。例如,[2]中的“全通全”攻击,可以绕过假设单一目标类的后门防御,例如[16],[17]。标签平滑攻击[71]被设计为绕过基于后门模式逆向工程[16],[18]的防御。[72]中基于瓦瑟斯坦的后门攻击是为在训练阶段部署的基于聚类的防御而设计的,如[7]、[8]、[73]。在[74] (a.k.a.输入感知的后门[75])可以绕过假设公共后门模式(在输入空间中)的防御,比如[51]。然而,大多数这些高级后门攻击需要强大的对手能力,这将在秒的下一个讨论。 3.即便如此,在我们的实验中,我们将评估所提出的MM-BD对上述一些具有代表性的高级攻击的检测能力。
3. Threat Model
3.1. Attacker’s Goals and Capabilities
在本文中,我们主要关注针对图像分类器的后门攻击。我们的方法在其他领域的扩展将在第二节中讨论。6.5.特别地,我们考虑了三种具有不同目标和能力的攻击者来彻底评估我们提出的防御。
基本攻击者:由“基本”攻击者发起的攻击是Sec中讨论的经典后门攻击。2.2.攻击与一个后门目标类、任意数量的源类和一个常见的后门模式相关联,这样,当后门模式存在时,来自源类的样本应该被错误地分类到目标类,而无后门的样本被正确地分类。攻击者有能力毒害训练集[76]。但是攻击者既不能访问分类器训练集中的样本,也不能访问训练过程本身。在本文中,我们将我们提出的MM-BD和我们的缓解方法与其他解决基本攻击者的方法进行了比较。
高级攻击者:这些攻击者的动机除了基本攻击者的目标,比如攻击对人类检查的坚定性,以及对后门防御的回避性。大多数这些附加的目标都不能由一个基本的攻击者来实现。因此,高级攻击者被赋予了额外的能力,例如: (a)收集足够的数据和训练代理分类器的能力,甚至(b)完全控制受害者的训练过程。后者是一个特别重要的假设,它只在少数情况下有效,例如,有一个内部人员或培训被外包给一个恰好是攻击者的第三方。在我们的实验中,MM-BD将对Sec中提到的几个高级后门攻击进行评估。6.3.
自适应攻击者:本文所考虑的最强攻击者是自适应攻击者,它除了具有基本攻击者的目标外,还具有击败已安装防御的目标。自适应攻击者比前两种攻击者更强,具有对训练过程的完全控制和对防御的充分了解。在第二节中。6.6.1,我们基于这些能力创建了一个强大的、优化的自适应攻击。我们证明,为了绕过MM-BD,攻击者需要解决一个复杂的最小-最大优化问题,这是耗时的。
3.2. Defender’s Goals and Assumptions
在本文中,我们考虑了实际的训练后防御场景,其中防御是在分类器被训练后应用的,而不访问训练集[15]。训练后防御最重要的目标是检测分类器是否受到后门攻击。如果检测到攻击,用户可以选择一个替代分类器,如果一个分类器可用。否则,应该减轻后门攻击,以便: a)当一个测试样本嵌入了后门模式时,分类器对原始源类进行预测,b)对干净、无后门的测试样本的分类精度没有显著降低。
与训练后的防守场景相关的假设总结如下: (1)防守者事先不知道是否有攻击。这是训练后后门检测问题有意义的基本假设。(2)防守者无法获得关于后门模式的信息。这一假设被许多现有的训练后检测器放宽——他们对后门模式类型或如何实现人类不可感知(例如,Sec中附加扰动后门模式的小ℓ2范数。2.2).然而,MM-BD严格地没有对后门模式做出任何假设。(3)防御者无法访问分类器的训练集。防御者是分类器的用户,或遗留系统的用户。在前一种(专有)情况下,分类器的训练集可能不公开可用,而在后一种(遗留)情况下,它早已被遗忘。(4)没有针对同一领域训练的干净分类器。否则,防御者可以直接使用干净的分类器(可能是经过一些微调之后)来代替要检查的分类器。更重要的是,如果有干净的分类器可用,训练后的检测将是一个更容易的“半监督”问题,因为这些分类器可以被使用(例如)。为检测推理[77]设置一个保形阈值。(5)防御者能够独立地收集一个小的、干净的数据集,其中包含来自域中所有类的样本。大多数训练后检测器使用,例如[16]-[21]。然而,MM-BD不需要任何干净的样品来进行检测。这使得MM-BD适用于干净的样本非常罕见或非常昂贵的情况。
- Related Work
训练后的后门检测方法。现有的方法包括一系列“元学习”方法,其中大量标记为“攻击”或“无攻击”的阴影神经网络被训练——从这些标记网络中提取的特征被视为监督例子,输入二元分类器”训练来区分“攻击”和“无攻击”[23],[24]。但是,这些方法使用了一个后门模式类型池,当攻击者实际使用的类型不在池中时,可能会失败。此外,训练阴影网络需要相对大量的干净样本,并且需要大量的计算量。另一个检测器试验为每个假定的目标类[16]-[20],[22],[78]的后门模式。这种逆向工程是使用一组干净样本[16],或使用模型反演[79],[80]获得的模拟样本。然后,检测推断是基于统计数据,从估计的后门模式(例如,估计的掩码的补丁替换后门模式的ℓ1规范)。然而,逆向工程依赖于后门模式类型[16],[18],[24]的知识。此外,除了[79],[80]之外,大多数这些基于反向工程的方法都需要一些干净的样本,这并不总是像我们在第二节中讨论的那样可用的。3.2.相比之下,MMBD不依赖于后门模式类型的知识,也不需要任何干净的样本。此外,当后门攻击只涉及少数源类时,一些基于逆向工程的方法会失败,如[18],[21]所示。[18]通过显著增加了计算复杂度来解决了这个问题。虽然[21]通过一个复杂的优化过程来估计源类和目标类,但我们的方法可以准确地检测具有任意数量的源类的后门攻击,并且计算效率高,这将在我们的实验中所示。
培训后的后门缓解方法。在[16],[60],[61]中,一个检测到的分类器对大量的干净的样本进行微调,以“解开”后门映射。在[62],[81]中,可能与后门模式相关的神经元根据其激活或(利普希茨)连续性的模量而被修剪。虽然我们的论文的主要焦点是后门检测,在秒。5.3,我们还提出了一种方法,对于大多数类型的后门模式,使用很少的干净样本,并且不对分类器的任何原始参数进行微调。我们的方法也可以与现有的方法相结合,以获得更好的性能。
后门防御处理各种后门模式类型。有许多后门防御能够解决各种后门模式类型。特别是,大多数训练阶段的后门防御,如[7]-[14],和一些推理阶段的后门防御,如[51],[55],[57],并没有考虑到任何特定类型的后门模式(即,它们是后门不可知论的)。然而,对于本文所关注的训练后后门检测问题,防御者无法访问任何实际的后门模式,这与前两种防御场景不同。因此,一些训练后的检测器倾向于依赖于对后门模式不协调的定量机制的假设。例如,[16]处理了基于补丁的模式,[18]假设了难以察觉的扰动模式,而[82]考虑了甚至不涉及后门模式的攻击。与此相反,我们的训练后检测器对后门模式的合并机制没有做任何假设。
5. Method
Sec 5.1. 中讨论 detector 背后的关键思想;Sec 5.2. 提出了我们的 detector 程序;Sec 5.3. 中提出了一种 mitigation method。
5.1. Key Ideas
与现有的 detector 不同(现有的后门检测方法往往是基于 small patch size 或 small perturbation size 的后门模式进行检测),而我们的 detector 是基于后门攻击的影响(分类器的 logit)进行探测,独立于后门模式。
考虑一个目标类为 \(t∈Y\) 的后门攻击,分类器的 logit 函数表示为 \(g_c: \mathcal{X} → \mathbb{R}\)(假设 X 不失一般性)。对于所有的非目标类别 \(c∈Y \backslash t\),无论后门是基于什么模式进行构建(small patch 或 small perturbation),我们都可能观察到:
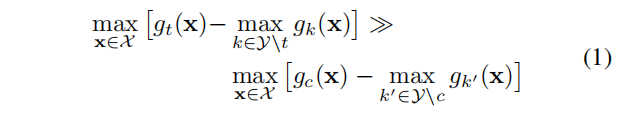
也就是说,后门攻击目标类的最大边际统计值将会比所有其他类的最大边际统计值大得多。
Why a backdoor attack causes the above phenomenon?
后门模式是一种常见的 pattern,后门嵌入在训练集的部分样本中以感染模型,这种嵌入在图像领域可以是 small patch,又或者是颜色;同样的 pattern 嵌入到测试样本中将导致测试阶段的错误分类。
一些最近提出的高级后门攻击方法使用一些特定样本作为后门模式 [74],[75] (Sec 2.4) 然而,这些后门模式仍然具有共同的语义特征,并且在某些潜在的嵌入空间中彼此相似。因此,这类后门攻击仍然可以被我们的方法检测到,这将在 Sec 6.3. 中展示。
相比之下,与后门模式无关的类鉴别特征通常会表现出很高的可变性。例如在不同视角、范围、光照条件下捕捉到的同一物体,该物体可能会决定模型将样本区分为某个类别。极端情况下,类鉴别特征可能来自同一类的样本中非常常见的特征,我们可以将类鉴别特征理解为模型 “内在的” 后门,该后门很难与攻击者植入的后门区分开来 [83]。排除这种内在后门的一般解决方案仍然是一个未解决的问题。
后门模式的共同特征所覆盖的类鉴别特征对于后门攻击时至关重要的,这有利于受害者分类器在训练期间可以很容易地学习后门模式。然而,过于重复、常见的后门模式嵌入到训练集也可能诱发不可避免的模型过拟合,后门攻击的存在会极大增强目标类的 logit,更重要的是,同时抑制了其他所有类别的 logit。因此,由于 “增强” 和 “抑制” 效应,目标类的 logit 和 logit 之间将产生异常大的边际。
我们考虑了 CIFAR-10 数据集上对于 “deer” 作为目标类的后门模型和 clean 模型,对于这两个分类器,我们使用相同的 MM-BD 协议来最大化 “deear” 分类的logit。两个分类器的所有类的 logits 如 Fig.9a 所示。即使我们没有故意抑制除 “deer” 类之外所有类的 logits,但这些 logits 显著减少。因此,虽然后门攻击即便可能逃过仅基于 maximizing logit 的探测器,但它将很容易被 MM-DB 利用 logit “增强” 和 “抑制” 效应检测到。
值得一提的是,相同方向的工作《Effective backdoor defense by
exploiting sensitivity of poisoned samples》还揭示了后门样本的内部特征表示将由后门模式主导,而不是由良性的类鉴别特征主导,而这种主导主要是由过拟合引起的。然而,《Effective backdoor defense by
exploiting sensitivity of poisoned samples》关注的是训练过程中的防御,有训练集可用,而我们的工作是训练后的,有训练集不可用。
上述推理在 Fig.1 中展示了可视化示例。
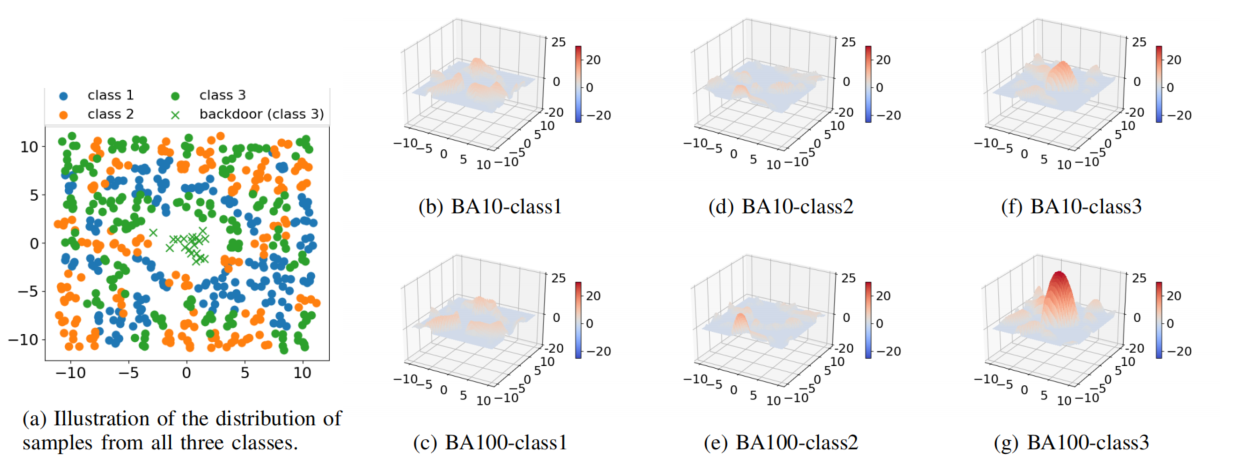
我们考虑具有三个类别的 2-dim 输入,每个类别的样本分布由一个高斯混合模型 GMM 生成。我们每个类别生成 500 个训练样本,并发起了两次后门攻击(目标为类别 3),两次攻击分别插入 10/100 个(BA-10/BA-100)后门样本。对于每个后门攻击,我们都训练了一个 3xhidden_layers 的多层感知机,这在两种后门攻击实施后,在 clean 测试样本上达到了接近 91% 的准确率,即后门攻击几乎不会影响到模型对干净数据集的预测精度。BA-10 和 BA-100 在测试阶段的攻击成功率分别为 92% 和 99%。
在 Fig.1 中,对于每个后门攻击和每个类,我们绘制了一个类的 logit 和其他两个类中最大的 logit 之间的差值(为了更好地可视化,只保留正值)。我们观察到,后门目标类( Fig.1f Fig.1g)对两种后门攻击都有异常大的最大边际值,与 Eq.1 结果一致。此外与 BA-10 相比,BA-100 对于目标类别的最大边际值非典型性更为明显(请注意,攻击者会尽可能选择更高的中毒率,即感染更多的训练样本,因为这将产生更高的攻击成功率)。
为了给我们的假设提供另一个观点,请考虑一个简单的线性模型 \(g(·): \mathcal{X} → \mathbb{R}^{|\mathcal{Y}|}\),其输出的嵌入能够被关联到类别 \(c ∈ Y\),\(g_c(x) = w'_c x\),其中,\(w_c\) 表示与类 \(c\) 相关的权值向量,它与输入\(x\) 具有相同的维度;而模型对于输入 x 分类到类 c 将具有具有最大的关联的 logit \(g_c(x)\)。
同时假设,训练后模型能够正确分类所有的样本,置信度高于 \(τ\),通过正确类的 margin 进行评估(即通过该类的 logit 类减去所有其他类中的最大 logit)进行评估:
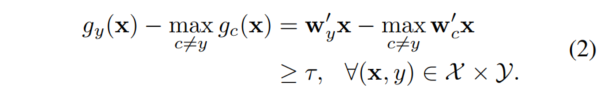
假设一个后门模式 \(v\) 被合并到一个 clean 训练图像 \(x_s\)中(其原本的类别 \(s \not ={t}\)),并被重新标记为目标类 \(t\)。Eq2. 可表示为表示:
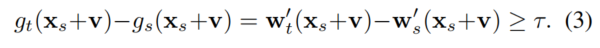
基于 Eq.2 中的可信边际假设,对于 clean \(x_s\) 我们有:
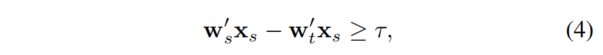
整合 Eq.3 和 Eq.4:
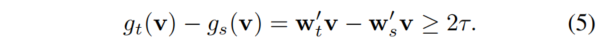
也就是说,后门目标类的最大边际的下界至少为 \(2τ\),大于所有类别的合法样本的下界。
5.2. Detection Procedure
Estimation step.
对于每个类 \(c∈Y\),我们估计最大边际统计量 by 如下公式:
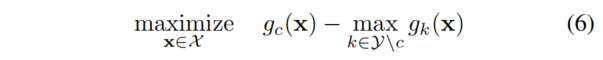
使用梯度上升(通常用于模型反演[80]和相关应用,例如,生成敌对的例子[85])并投影到X上(例如X=[0,1]H×W×C用于高度H、宽度W和C通道的彩色图像)。
注意,X是一个闭凸集;因此,X上的连续logit函数是有界的,利普希茨。换句话说,存在闭球,其中函数是凸的,具有局部极大值的。然后,根据[86]中的定理3.2,保证了在X中与X上投影的任意随机初始化的梯度上升的收敛性。正如通常的做法一样,我们在X中执行多个随机初始化(例如,对于图像,像素值在区间[0,1]中均匀地随机初始化),并选择最大的局部最优解。与基于逆向工程的防御相比,假设的后门模式嵌入类型和真正的攻击后门模式类型之间可能存在不匹配,我们的优化问题不需要假设一个后门模式嵌入类型。此外,实验发现,基于逆向工程的防御使用所有非目标类的干净样本的后门模式估计,当这些类大多数不是源类[21]时,是失败的。相比之下,我们的方法可以检测具有任意数量的源类的后门攻击,并且不需要知道来自该域的任何合法样本。
Detection inference step.
我们提出了在论文《Detection of backdoors in
trained classifiers without access to the training set》中给出的无监督异常检测器。
记每个类 \(c∈Y\) 的估计最大边际统计量为 \(r_c\),其中最大值为 \(r_{max}=max_{c∈Y} r_c\)。我们假设,当存在后门攻击时,\(r_{max}\) 将与目标类相关联,并且将是非目标类的最大边际统计量分布的一个离群值。
因此,我们使用不包括 \(r_{max}\) 在内的所有统计数据来估计一个零分布 \(h_0\)。考虑到最大边际是严格正的(在我们的实验中估计的最大边际的理论和经验),我们在实验中选择了零分布的单尾密度形式,例如伽马分布。为了评估 \(r_{max}\) 在估计的零值下的非典型性,我们计算了一个阶统计量 p-value:
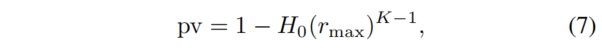
其中,\(K = |Y|\) 为域中类的总数。很容易观察到,pv 在 “无攻击” 的 null 假设下,在 [0,1] 上服从均匀分布。因此,如果 pv < θ,我们认为检测置信度为 1−θ(例如 θ=0.05)。如果检测到后门攻击,则 \(r_{max}\) 关联的类被推断为后门目标类。
5.3. Mitigation of Backdoor Attacks
当检测到后门攻击时,受害者分类器对检测到的目标类以外的类所做的预测,或者对 clean 测试样本所做的预测可能仍然是可信的。一个选择是减轻后门攻击。
我们的缓解方法是基于观察到的后门攻击,诱导每一层的一个神经元子集有异常大的激活。这种 “large activation” 现象也是 [19] 中后门检测方法的基础,尽管需要几个超参数,例如,来识别负责大激活的神经元。
相比之下,我们对每个神经元都应用一个特定的优化上限,以抑制由后门攻击引起的任何可能的大规模激活,而不会显著降低分类器在 clean 样本上的准确性。
设 \(σ_l: \mathbb{R}^{n_{l-1}} → \mathbb{R}^{n_{l}}\) 为受害者分类器的第1层的激活(作为前一层激活的函数)。在这里,为了简洁,我们没有明确地表示每一层中的参数,因为在我们的缓解过程中,它们都不会被修改。然后,任何类 \(c∈Y\) 和任何输入 \(x∈ \mathcal{X}(= \mathbb{R}^{n_0})\) 的 logit 函数都可以写成:
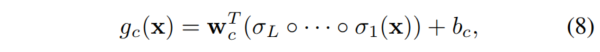
其中,\(w_c∈\mathbb{R}^{n_{l}}\) 和 \(b_c∈ \mathbb{R}\) 分别是与类 c 相关的权重向量和偏差。
对于每一层 \(l = 2,...,L\) 我们还表示一个边界向量 \(z_l∈\mathbb{R}^{n_{l}}\),这样,对于每个类c∈Y和任何输入x,具有有界激活的 logit 函数都可以表示为:
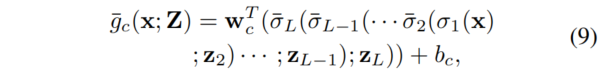
其中,Z = {z2、···、zL}和¯σl(·;zl)=min{σl(·)、任意l = 2、···、l(其中“min”运算符应用于向量的每个分量)。为了在不影响分类器在干净测试样本上的性能的情况下,找到每个神经元的最小激活上界,我们建议在一个小集合D的干净样本上解决以下问题:
其中,1[·]表示指标函数,π为最小精度基准(如set π = 0.95)。在这里,我们最小化边界向量的ℓ2范数,以惩罚在每一层中具有绝对值过大的激活。
为了实际解决上述问题,我们提出使用梯度下降法使以下拉格朗日量最小化:
其中Z的初始化值很大。等式的第一项(11)目的是保持D中样本的分类器对数不变。这种设计不仅有助于满足问题(10)中的精度约束,而且避免了给定样本与的类标签相关联,从而进一步增长(即过拟合),允许在有限的样本下实现缓解5。λ会自动更新,以满足问题(10)的约束。这个过程在Alg。 1.注意,我们将Z中的值初始化得足够大,以便最初不执行激活边界/饱和。这可以很容易地通过喂食干净的样品来获得一个粗略的激活范围,然后将初始上限设置为比典型激活更大的幅度。
最后,通过对对数(¯;Z∗)}∈∈,得到一个具有后门缓解的类后验。
6. Experiments
实验主要在四个具有不同分辨率、大小和数量的图像基准数据集上进行: CIFAR-10、CIFAR-100 [87]、TinyImageNet、GTSRB[88].
6.1. Main Experiments for Backdoor Detection
下面展示了后门检测器 MM-BD 在检测精度和计算效率方面的有效性,与一些最先进的训练后检测器对各种后门攻击配置(包括后门模式类型和源类的数量)相比。虽然这里我们关注经典的后门攻击,通常认为现有的后门检测工作和最近的竞争,如[58],MM-BD的成功对许多其他高级后门攻击设置和自适应后门攻击显示在 Sec. 6.3.
6.1.1. Setting
我们从后门攻击文献中考虑了三种常见的后门嵌入类型:附加、补丁替换和混合(与中相关的嵌入函数。Sec 2.2)。MM-BD 对基于 基于 warping-based 的后门模式和特定于样本的后门模式的有效性在 Sec 6.3. 中显示。
我们将考虑以下五种后门模式。对于 additive 后门模式,我们考虑了来自 [18] 的全局 “chess board” 模式和来自 [7] 的局部 “1-pixel” 扰动。对于补丁替换后门模式类型,我们考虑一个来自 [2] 的 BadNet 模式和一个 “unicolor” 补丁[16]。对于混合后门模式类型,我们考虑一个来自 [18] 的 “blended” 噪声补丁。这些后门模式的例子和更多的细节在 Apdx A.2. 中。
和大多数现有的攻击方法一样,我们考虑使用单个目标类的后门攻击(为每个攻击随机选择目标类)。但是,我们允许从一个或多个 source 类中选取目标类 —— 为了简洁起见,这两个源类设置分别表示为 ‘S’/‘M’。对于每个 ‘S’ 设置的后门攻击,将随机选择源类。对于TinyImageNet,我们为 ‘M’ 设置的每个后门攻击随机选择10个源类;而对于其他三个数据集,除了目标类之外的所有类都被选择为源类。通过上述标记,使用 “chess board” 后门模式和多源类的后门攻击被表示为 “chess board-m”。
对于 CIFAR-10,我们分别为 5 种不同的后门模式和 S/M 模式的所有 10 个组合创建了 10 个后门攻击。对于 CIFAR-100 和 GTSRB,我们分别为 5 个后门模式创建了 5 个后门攻击集合,它们都使用了 M 设置。我们没有为这两个数据集创建单源类的后门攻击,因为每个类中的图像数量有限,不能从单个类生成足够的后门训练图像来启动成功的后门攻击。对于TinyImageNet,我们只生成了一个设置为 “BadNet-M” 的后门攻击,因为在这个数据集上训练一个分类器的时间非常高。对于每个集成,使用 [2] 中经典的“数据中毒”协议,根据指定的设置独立生成 10 个不同的攻击。其他配置,包括在每个集合中为后门攻击创建的后门训练映像的数量,都放在 Apdx A.3.
我们为每个后门攻击训练了一个分类器。用于对 CIFAR-10、CIFAR-100、TinyImageNet 和 GTSRB 进行后门攻击的 DNN 架构分别为 ResNet-18 [89]、VGG-16 [90]、ResNet-34 [89] 和 MobileNet [91]。
对于每个数据集,我们还创建了一个干净分类器的集合来评估错误检测率。与为相同数据集训练的干净分类器相比,我们创建的所有后门攻击都是成功的,攻击成功率(ASR)高,而干净测试精度(ACC)的下降可以忽略不计。更多的细节显示在 Apdx A.4.中。
6.1.2. Detection Performance.
我们比较了 MM-BD 与六种最先进的训练后检测方法: NC [16]、TABOR [17]、ABS [19]、PT-RED [18]、META [24] 和 TND [22]。我们遵循了这些方法的原始实现,只做了微小的变化(例如,选择最好的检测阈值来最大化它们的性能)。特别是对于 META,我们使用官方代码来训练 “元分类器” 进行检测。
对于MM-BD,我们使用梯度上升与收敛准则7ϵ=10−5和30随机初始化解决了问题(6)。这些选择对检测精度并不重要。在推理阶段,将检测阈值设置为 θ = 0.05,即检测置信度为 0.95,这是统计假设检验的经典阈值,在本文的所有实验中都保持不变。
在 Tab.1,我们展示了 MM-BD 与我们创建的后门攻击集成上的其他方法相比的检测精度,并报告了每种方法使用的每类Nimg的合法图像数量。成功的检测需要检测到后门攻击和正确推断出目标类。我们还显示了被认为不被每个检测器攻击的干净分类器的比例。我们只评估了 CIFAR- 10 上的 META,因为将 META 应用于对其他数据集的后门攻击的计算成本过高(超过24小时)。PT-RED,估计每个(源、目标)类对的后门模式,我们降低其复杂性通过估计后门模式 CIFAR-100,每个假定的目标类,GTSRB——否则,在这些数据集上重复实验将不可能由于大量的类复杂。
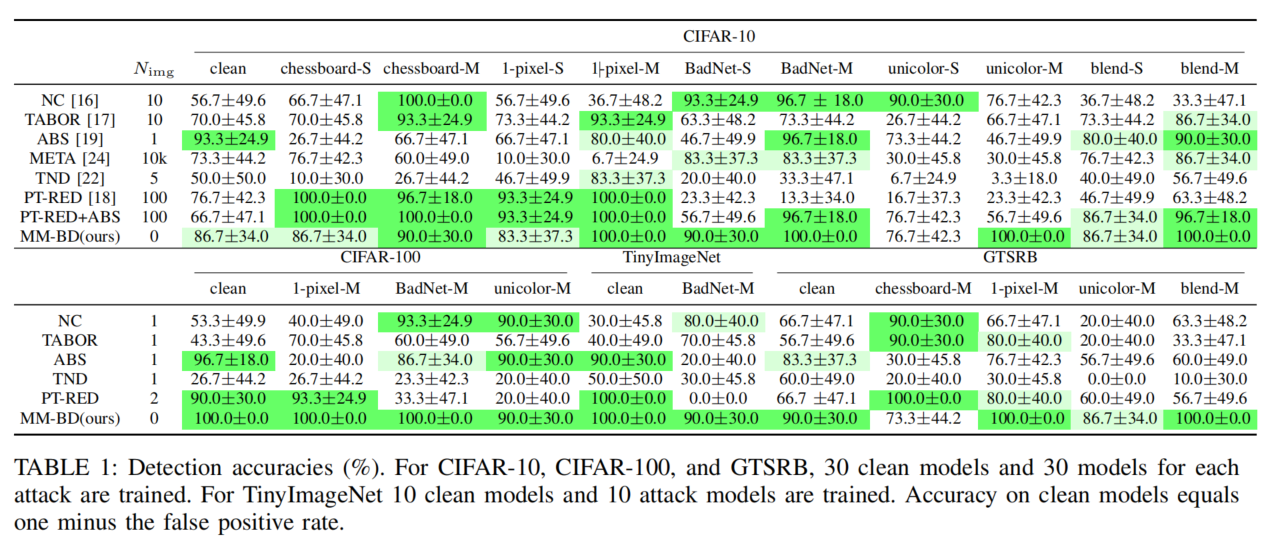
同样,由于时间限制(和空间限制),我们分别只包括了CIFAR-100、TinyImageNet和GTSRB的少数任意选择的后门攻击集合的检测结果。对于所有后门攻击集合的MM-BD的完整结果都在Apdx中。B.1.
正如我们在 Sec 4. 中讨论过的。现有的训练后检测器假定一种或几种后门模式类型。例如,NC在检测补丁替换后门模式(BadNet&单色)的后门攻击方面具有较强的能力,为此设计了它;但NC无法检测到具有本地加性后门模式(1像素)的后门攻击8。ABS和META也报告了类似的结果,它们是为了进行补丁替换/混合的后门模式(BadNet、单色和混合),而没有针对附加的后门模式(棋盘和1像素)。
相比之下,PT-RED在附加后门模式(棋盘和1像素)上表现良好,它是为此设计的,但对于其他后门模式(BadNet-blend)通常无效。与其他方法相比,TABOR和TND并没有表现出具有竞争力的性能,因为它们对后门模式的形状或颜色采用了额外的约束条件。与这些方法不同,MM-BD对所有后门模式都具有较高的检测精度,对所有数据集的误检出率较低;也就是说,其性能对后门模式类型很大程度上对后门模式类型不变。
即使ABS联合部署ABS(对补丁后门模式BadNet、单色和混合有效)和PT-RED(对附加后门模式棋盘-1像素有效)(检测),对具有后门攻击的分类器的检测精度与MM-BD相当,但有更多的错误检测和计算成本的显著增加。此外,NC、TABOR、ABS和TND假设后门攻击具有多个源类(“M”设置);因此,它们很容易对具有单一源类的后门攻击失败(“S”设置)。然而,MM-BD在检测具有任意数量的源类的后门攻击时通常是有效的,如Tab所示。1,因为它没有对源类的数量做出任何假设。最后,与其他方法不同,MM-BD不需要任何干净的图像进行检测。