activation functions summary and comparision
发布时间 2023-11-28 03:37:53作者: Daze_Lu
written in the foreword
Any nonlinear function that has good derivative properties has the potential to become an activation function. So here, we will just compare some classic activation functions.
summary
| name |
formula |
digraph |
attribution |
advantage |
disadvantage |
usage |
addition |
| sigmoid |

|
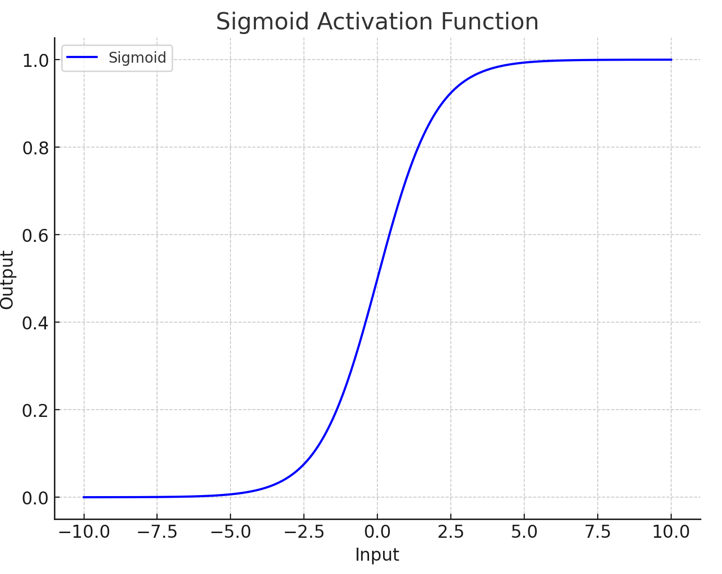
|
- output is in [0-1]
- gradient in [0-0.25]
|
- Smooth and easy to differentiate, avoid jumpy value
|
- Gradient Vanishing
- high computation, low speed
|
|
|
| tanh |
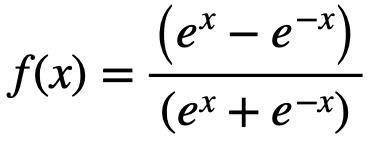
|

|
- output is in [-1, 1]
- gradient in [0-1]
|
- mean=0 , easy to compute
- smooth
|
- Gradient Vanishing
- high computation, low speed
|
|
|
| softmax |

|

|
|
- convert output as property distribution, the sum of all classes is 1
- smooth
|
- Gradient Vanishing
- high computation, low speed
|
|
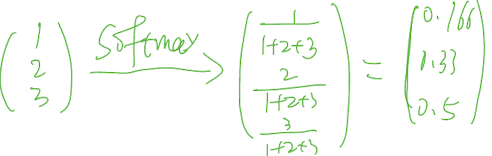
|
| ReLU |
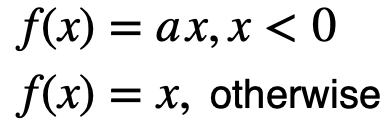
|

|
|
- Preventing Gradient Vanishing
- Fast Convergence
|
|
|
|
| ReLU6 |

|
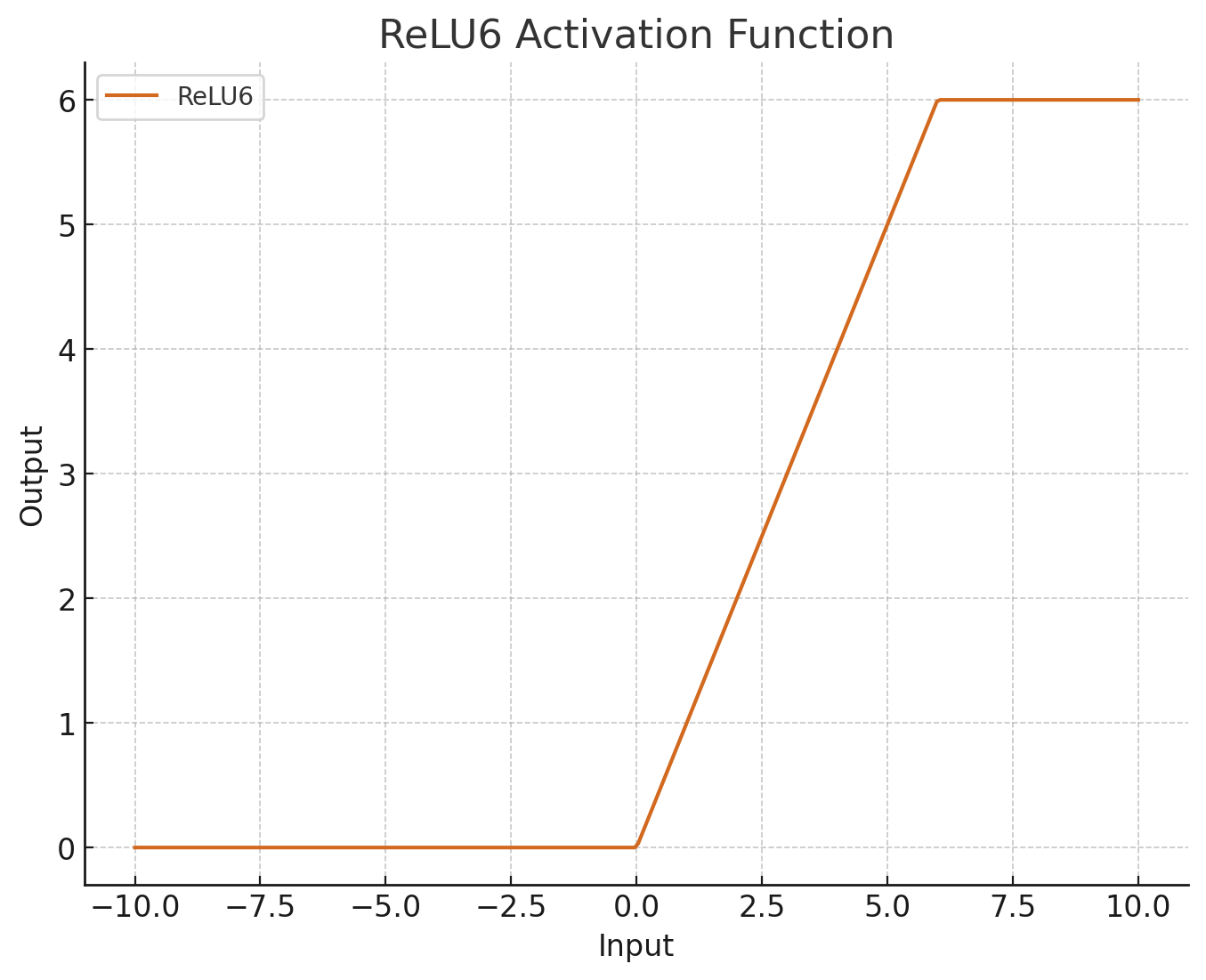
|
|
|
- limited expression of output
|
|
|
| SwiGLU |
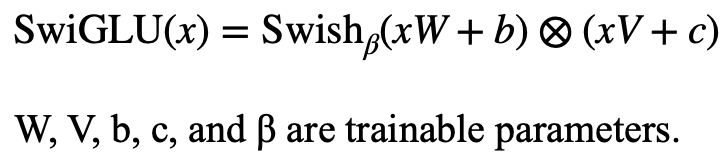
|
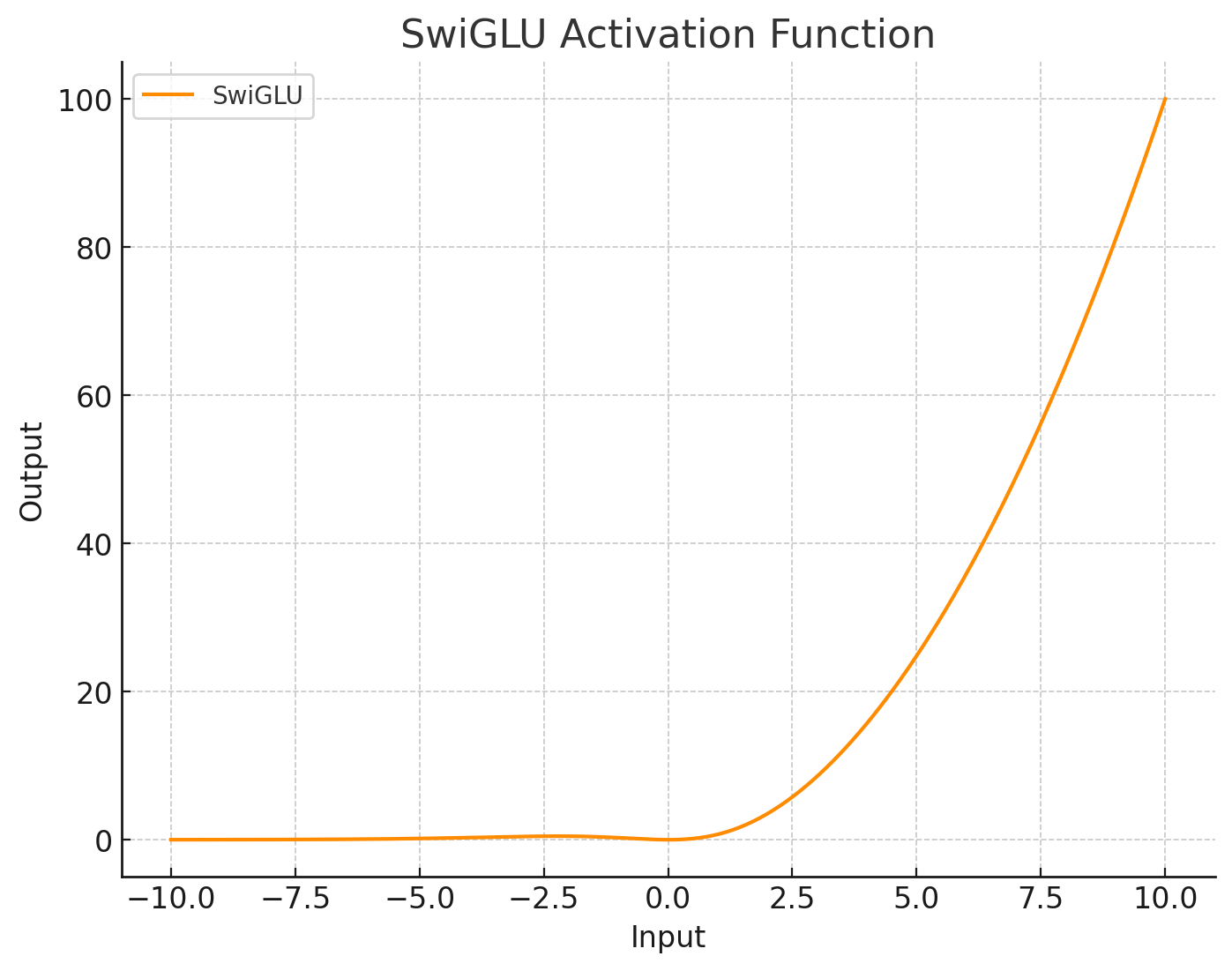
|
|
- performance improvement, better than swish, GLU, etc. including the vision field.
- dynamic mating mechanism
|
|
- PaLM(google)
- llama2(meta)
|
|
comparison