前面一篇内容讲解了如何利用Pytorch实现ResNet,这一篇我们用ResNet18实现一个二分类。接下来从模型、数据及训练三个方面展开。
一、目标
利用ResNet18将以下数据分为两类
- class_0

- class_1

二、模型
ResNet系列的模型在上一篇已经详细介绍了,这里采用ResNet18。
1. 模型导入
在torchvision库中已经有一些常用模型,我们这里直接引入即可。
from torchvision.models import resnet18
model = resnet18(pretrained=True) # 设为True加载预训练权重
2. 修改输出层
调用list(model.children())

可以看到库里面自带的ResNet模型最后经过全局最大池化后接的输出是1000类,但这里只有两类,所以需要对最后输出层进行修改。
import torch.nn as nn
model = nn.Sequential(*list(model.children())[:-1], # [b, 512, 1, 1] -> 接全连接层
# torch.nn.Flatten(),
nn.Linear(512, 2)) # 添加全连接层
经过修改后模型最后一层输出变为2类。

3. 模型可视化
为了更直观理解网络,这里采用Netron查看网络结构。下图是网络前面几层的结构图。
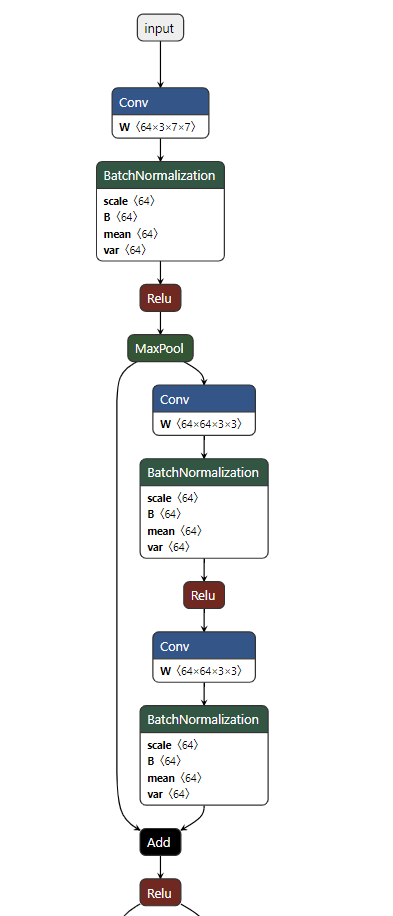
三、数据集制作
模型确定以后,我们接下来依据模型输入,制作数据集。如下图所示,原始论文中输入大小为224*224,经过5次卷积后特征图大小依次变为112 * 112 ==> 56 * 56 ==> 28 * 28 ==> 14 * 14 ==> 7 * 7,最后经过全局池化变为 1 * 1 共512维。由于这里设计了全局池化层,所以对输入不一定限制为224 * 224的大小。
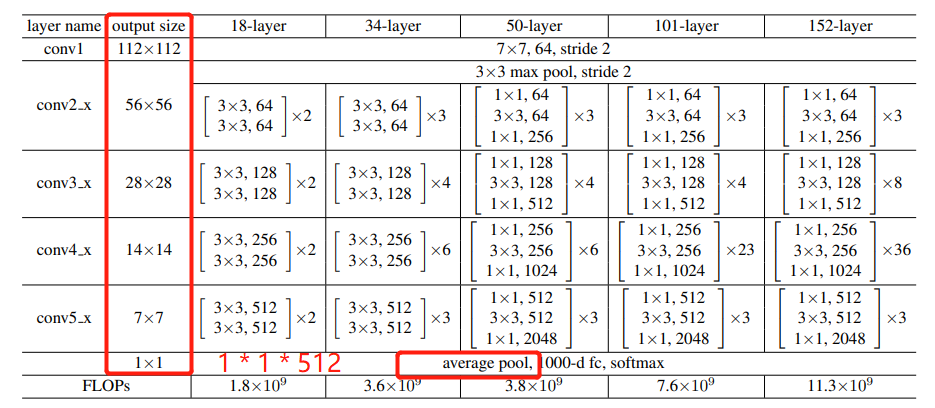
这里考虑到数据本身比较小,因此输入大小统一为64 * 64。接下来依据以上内容一步一步实现数据集制作。
1. 原始数据分文件存储
将原始图片按类型分别存在不同的文件夹下,其目录结构如下
data
- class_0
- class_1
2. 数据预处理
通道转换,将图片转为RGB格式,(png图片读取会变成RGBA)
from PIL import Image
lambda x: Image.open(x).convert('RGB')
考虑到原始图片可能大小不一,这里需要进行缩放,将其变为64 * 64
from torchvision import transforms
transforms.Resize(64, 64)
为了训练时更快的收敛,这里对输入图片进行归一化处理,即减去均值后除以方差。
transforms.ToTensor(), # 将输入数据由(H, W, C)变为(C, H, W),并将数值转化至[0, 1]
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 给定不同通道均值和方差参数,进行归一化处理
3. 数据增强
由于数据量较少,这里对数据集进行增强处理,进行旋转和裁剪
transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
4. 数据加载器
pytorch提供了数据加载器,定义自己数据集的时候只需要继承Dataset类,然后重写__init__,__len__和__getitem__三个方法即可,其中__init__可以用来初始化一些变量,__len__返回数据集大小, __getitem__返回指定索引对应的数据。
from torch.utils.data import Dataset
class Mydataset(Dataset):
def __init__(self):
super(Mydataset, self).__init__()
...
def __len__(self):
...
def __getitem__(self, idx):
...
接下来我们依据数据集编写数据类
- mydataset.py
from PIL import Image
import torch
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
import os
import glob
class Mydataset(Dataset):
def __init__(self, root, resize):
super(Mydataset, self).__init__()
self.root = root
self.resize = resize
self.imgs = []
self.labels = []
# class_0
imgs = glob.glob(os.path.join(self.root + "/class_0", "*.png"))
for i in range(len(imgs)):
self.imgs.append(imgs[i])
self.labels.append(0)
# class_1
imgs = glob.glob(os.path.join(self.root + "/class_1", "*.png"))
for i in range(len(imgs)):
self.imgs.append(imgs[i])
self.labels.append(1)
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
tf = transforms.Compose([
lambda x: Image.open(x).convert('RGB'),
transforms.Resize((int(self.resize), int(self.resize))),
# transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
# transforms.RandomRotation(15),
# transforms.CenterCrop(self.resize),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
img = tf(img)
label = torch.tensor(label)
return img, label
def denormalize(self, x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x - mean) / std
# x = x_hat * std + mean
# x:[x,h,w]
# mean: [3] -> [3, 1, 1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
x = x_hat * std + mean
return x
5. 测试及可视化
验证数据类是否正确,指定索引后,利用matplotlib.pyplot进行绘图,并打印出相应标签
import matplotlib.pyplot as plt
def denormalize(x_hat):
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
# x_hat = (x - mean) / std
# x = x_hat * std + mean
# x:[C,H,W]
# mean: [3] -> [3, 1, 1]
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
x = x_hat * std + mean
return x
def torch_tensor_to_pil(tensor_img, norm=True):
if norm:
tensor_img = denormalize(tensor_img)
tensor_img = tensor_img.squeeze(0).permute(1, 2, 0)
pil_img = tensor_img.numpy()
pil_img = Image.fromarray((pil_img * 255).astype(np.uint8))
return pil_img
my_dataset = Mydataset("./data", 64)
# 显示第1个数据
idx = 0
img, label = my_data[0]
print("label: ", label)
pil_img = torch_tensor_to_pil(img)
plt.imshow(pil_img)
plt.show()
四、模型训练
经过上面的讨论,已经定义好模型和数据集,接下来实现模型训练。按照pytorch框架,需要有优化器以及损失函数,这里依次展开。
1. 定义损失函数
这里采用交叉熵损失,也可以根据实际需求进行修改。
import torch.nn as nn
criterion = nn.CrossEntropyLoss()
2. 定义优化器
优化器这里采用Adam
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
3. 数据集划分及加载器
将数据集划分为训练集和验证集,这里依据给定比例进行随机划分。
from torch.utils.data import DataLoader, random_split
dataset = Mydataset("./data", 64)
train_ratio = 0.9
n_train = int(train_ratio * len(dataset))
n_val = len(dataset) - n_train
print("data number: {}, train: {}, val: {}".format(len(dataset), n_train, n_val))
train_dataset, val_dataset = random_split(dataset, [n_train, n_val])
train_loader = DataLoader(train_dataset, batch_size, True)
val_loader = DataLoader(val_dataset, batch_size, False)
4. 训练
for epoch in range(start_epoch, epoch_num):
# train
model.train()
for i, (imgs, labels) in enumerate(train_loader):
inputs = Variable(imgs).to(device)
labels = Variable(label).to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print('[ Train Epoch {:005d} -> {:005d} / {} ] loss : {:15} '.format(
epoch, i, len(train_loader), loss.item()))
# val
model.eval()
with torch.no_grad():
val_loss = 0.0
for i, (imgs, labels) in enumerate in enumerate(val_loader):
inputs = Variable(imgs).to(device)
labels = Variable(label).to(device)
outputs = model(inputs)
val_loss += criterion(outputs, labels).item()
val_loss /= len(val_loader)
print('******* val loss : {:15} '.format(val_loss))
if (epoch+1) % save_freq == 0 or epoch == epoch_num - 1:
save(model, epoch + 1, "tooth", is_best=False)
5. 可视化训练结果
借助visdom工具监控训练过程,也可以采用TensorBoard等工具。

小结
借助pytorch训练模型,大体可以分为三个步骤,第一步先确定好数据集,第二步依据数据集定义好模型的输入输出,第三步定义好损失函数和优化器后进行训练,这三个步骤都要用好可视化工具,便于检查及监控训练过程。