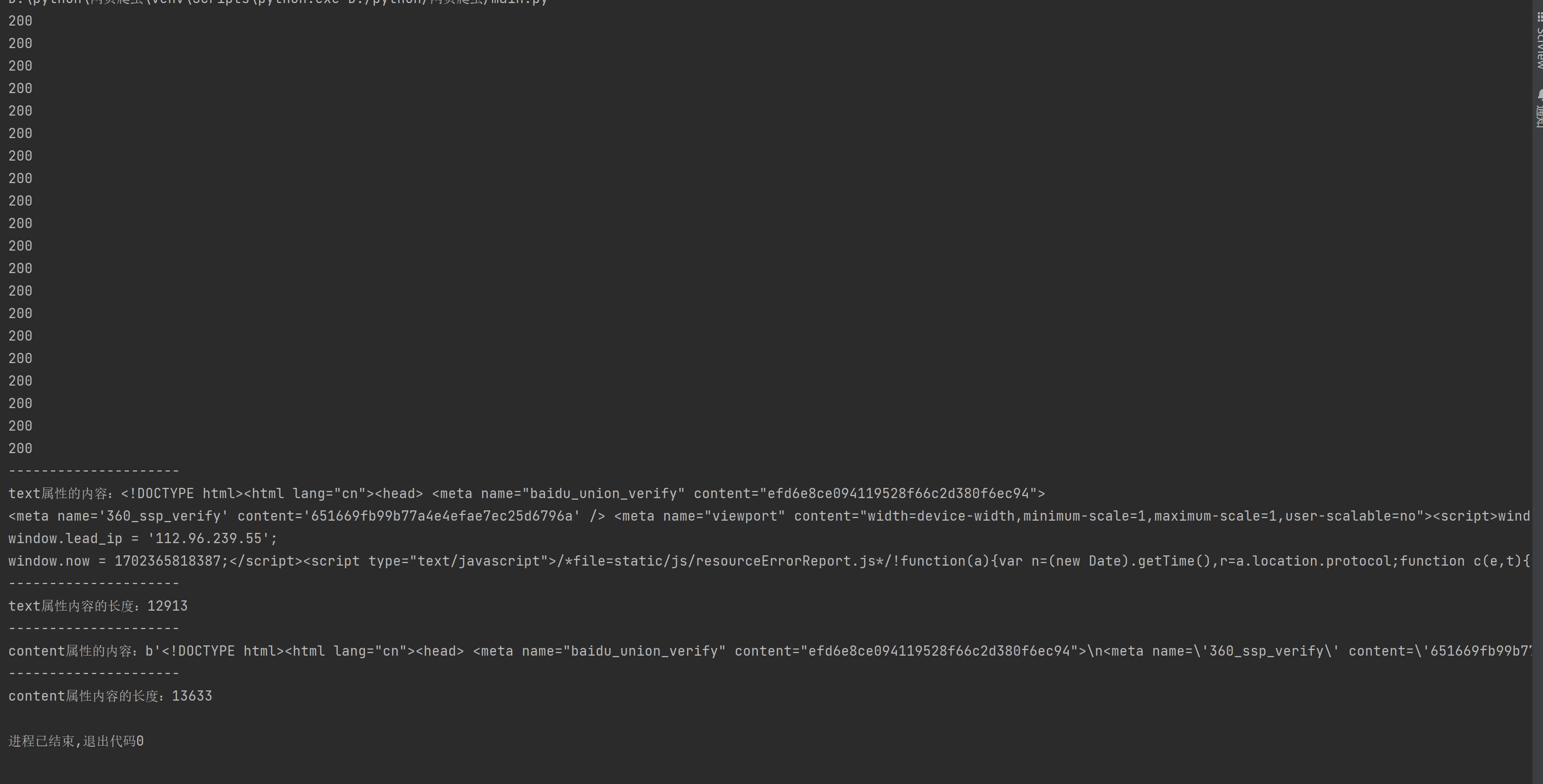
(2)请用requests库的get()函数访问如下一个搜狗网站主页20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度。
1 import requests 2 url = "https://www.sogou.com" 3 for i in range(20): 4 r = requests.get(url) 5 print(r.status_code) 6 print('---------------------') 7 print("text属性的内容:{}".format(r.text)) 8 print('---------------------') 9 a = len(r.text) 10 print("text属性内容的长度:{}".format(a)) 11 print('---------------------') 12 print("content属性的内容:{}".format(r.content)) 13 print('---------------------') 14 b = len(r.content) 15 print("content属性内容的长度:{}".format(b))
(3)这是一个简单的html页面,请保持为字符串,完成后面的计算要求。
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html>
要求:a.打印head标签内容和你的学号后两位
b.获取body标签的内容
c. 获取id 为first的标签对象
d. 获取并打印html页面中的中文字符
1 import re 2 from bs4 import BeautifulSoup 3 text = '''<!DOCTYPE html> 4 <html> 5 <head> 6 <meta charset="utf-8"> 7 <title>菜鸟教程(runoob.com)</title> 8 </head> 9 <body> 10 <h1>我的第一个标题</h1> 11 <p id="first">我的第一个段落。</p> 12 </body> 13 <table border="1"> 14 <tr> 15 <td>row 1, cell 1</td> 16 <td>row 1, cell 2</td> 17 </tr> 18 <tr> 19 <td>row 2, cell 1</td> 20 <td>row 2, cell 2</td> 21 </tr> 22 </table> 23 </html>''' 24 soup = BeautifulSoup(text) 25 print("学号后两位:03") 26 print("head标签内容:{}".format(soup.head)) 27 print('---------------------') 28 print("body标签内容:{}".format(soup.body)) 29 print('---------------------') 30 print("id为first的标签对象:{}".format(soup.p)) 31 print('---------------------') 32 print('页面里面的所有中文字符为:{}'.format(re.findall("[\u4e00-\u9fa5]+?", soup.text)))

(4) 爬中国大学排名网站内容,https://www.shanghairanking.cn/rankings/bcur/201811
要求:(一)爬取大学排名(学号尾号3,4,爬取年份2016)
(二)把爬取得数据,存为csv文件