1.1 深度学习原理概述
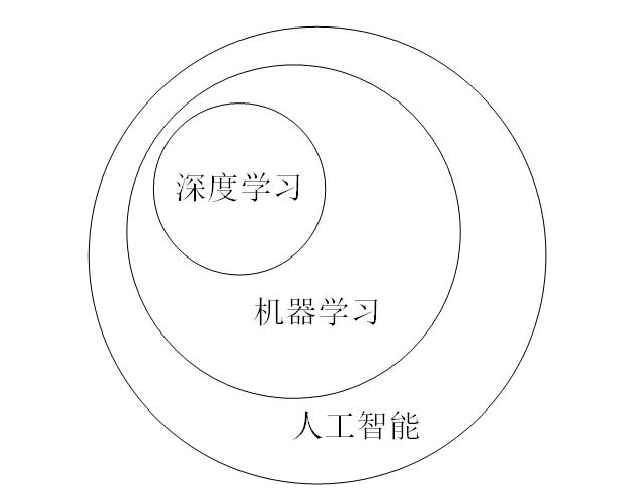
深度学习是机器学习的一个分支,机器学习是人工智能的一个分支。三者的关系如图:
通常,对于一个问题的求解,是先给定输入数据,然后将输入数据代入对应的计算规则,利用计算规则求解出对应问题的计算结果。
而对于机器学习而言,是先给定输入数据和真实结果,将给定的输入数据,代入到机器学习模型中进行处理,得到预测结果。再计算预测结果和真实结果的差异,输出计算规则。这种计算规则后续可应用于新的输入数据,得出新的预测结果。
机器学习模型是训练出来的,将某个任务相关的数据输入机器学习模型,机器学习模型会在这些数据中学习到数据自身存在的规律。需要从以下三个要素来进行机器学习的训练。这三个要素分别是输入数据、预期输出数据和衡量机器学习算法优劣的指标。
深度学习是从数据中学习规律的一种方法,强调从连续的层中进行学习。深度学习和有限元在模型的构建上有相似性,有限元模型是通过堆叠有限且规范的单元,对无限自由度的物体进行描述。而深度学习模型,是通过堆叠有限且规范的层,对一组数据的规律进行描述。在深度学习中,这些层的堆叠,构成了神经网络模型。神经网络的结构是逐层堆叠的,通过堆叠层来实现输入到输出的映射,每一种层代表着一种数学变换。
神经网络中每层对输入数据所做的具体操作保存在该层的权重中,权重的其本质是一串数字,每层实现的数学变换由其权重来参数化,所以权重有时也被称为该层的参数。而学习的意思是找到神经网络中最适宜的一组权重值。
为了找到最适宜的权重,需要一个指标来对神经网络的输出值和真实值的差异进行评估,这个指标就是损失值(误差)。将网络的输出值和实际的真实值代入到损失函数,即可计算出二者的损失值。再利用误差反向传播算法,得到最为适宜的权重值,完成对神经网络的训练。神经网络训练流程如图所示:
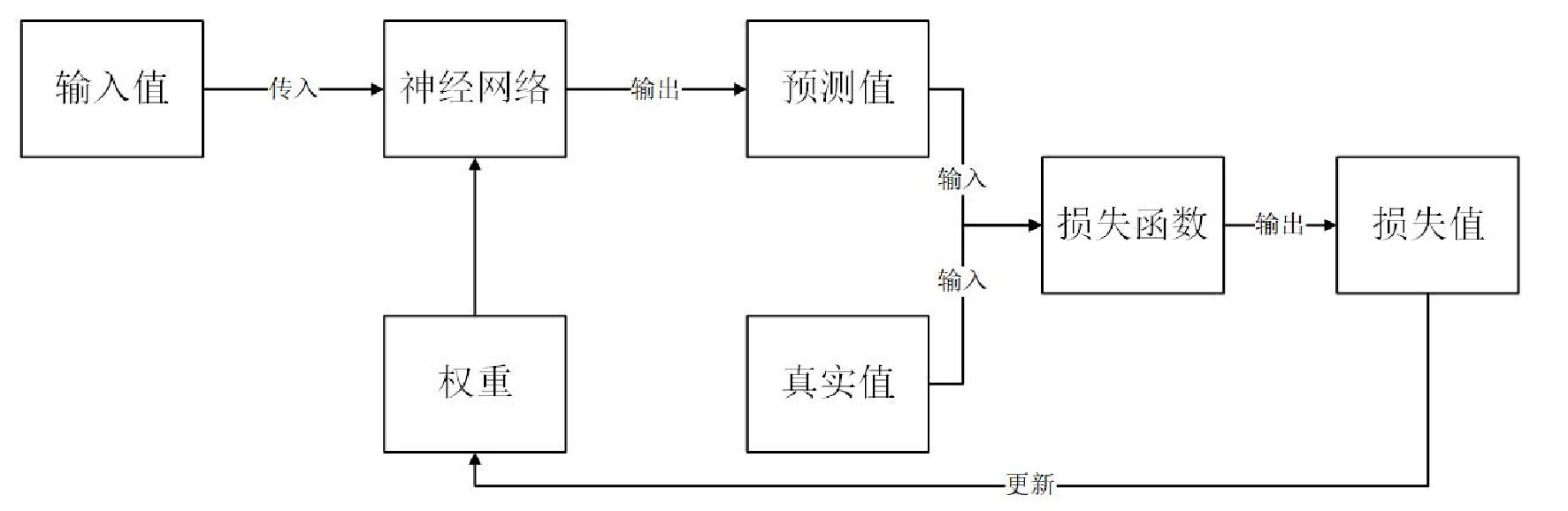
神经网络训练流程
1.2 深度学习的层
(1)卷积层
在深度学习中,常使用卷积神经网络对图像进行处理。卷积神经网络使用卷积层对图像进行卷积运算。对于输入数据,卷积运算以一定间隔滑动卷积核,将各个位置上的输入数据的元素和卷积核的元素对应相乘再求和,将这个结果保存到输出的对应位置。
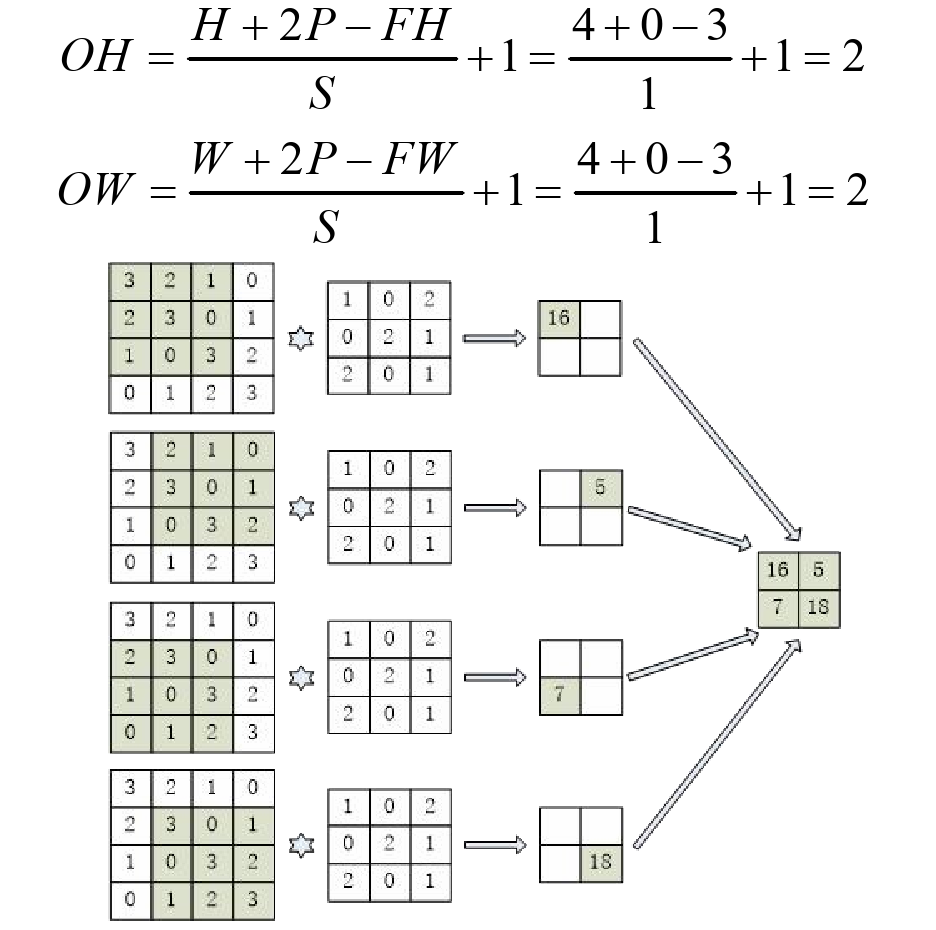
在进行卷积运算之前,常在输入数据的周围填入固定的数据,比如0,这称为填充(Padding)。而卷积核单次滑动的距离称为步幅(Stride)。假设输入大小为(H,W)=(4,4),卷积核大小为(FH,FW)=(3,3),填充为P=0,步幅为S=1,此时,输出大小为(OH,OW)的卷积运算如图所示。
(2)池化层
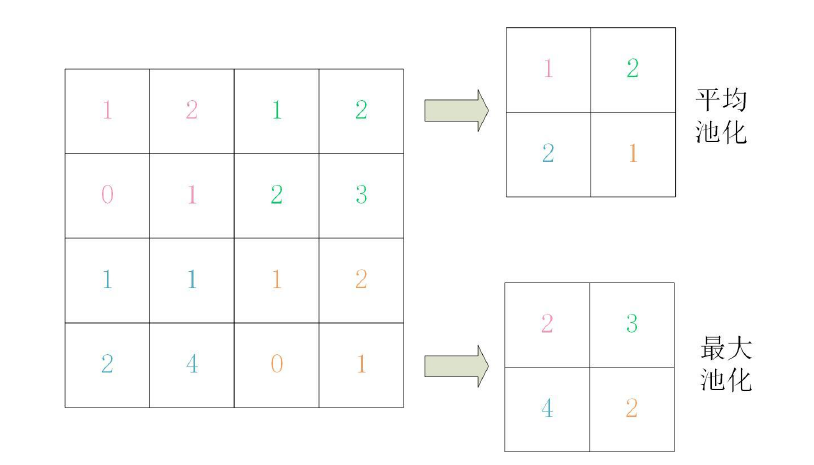
池化层进行池化运算。池化运算是缩小图像高度方向、长度方向的运算。常用的池化运算有最大池化、平均池化。平均池化是计算目标区域的平均值,最大池化是计算目标区域的最大值。例如,步幅为2、池化核大小为2的平均池化和最大池化如图所示。
1.3 激活函数
(1)Sigmoid函数
神经网络中经常使用的一个激活函数是Sigmoid激活函数,公式为式:

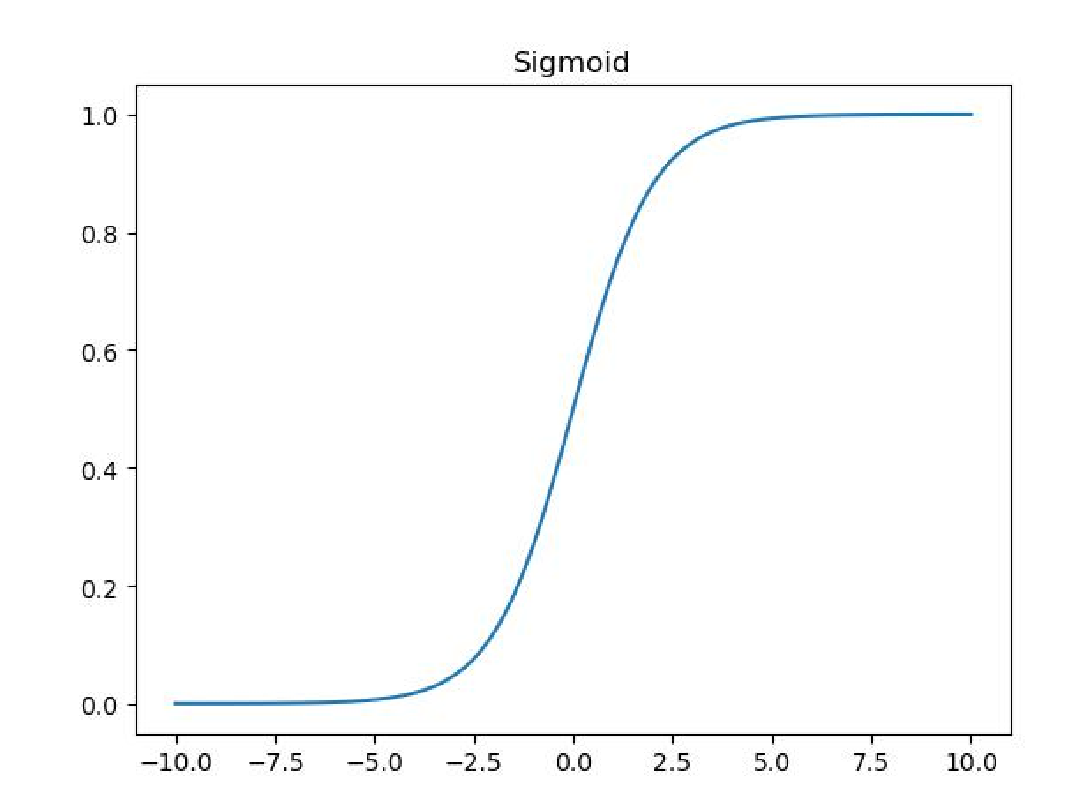
Sigmoid函数用于隐层神经元输出,取值范围为(0,1)。它可以将一个实数映射到(0,1)的区间,主要用于二分类问题。具体而言,当输入的值越大于0,输出的值越趋近于1,当输入的值越小于0,输出的值越趋于0。Sigmoid函数这样做的目的是将输出的数据规整到0和1附近。Sigmoid激活函数如图所示。由图可知,只有-5和5之间的输入值不会转化为趋近于0或1,小于-5的值会转化为趋近于0,大于5的值会转化为趋近1。
(2)ReLU激活函数
ReLU激活函数是在输入大于0时直接输出该值,在输入小于0时输出0,公式为式:
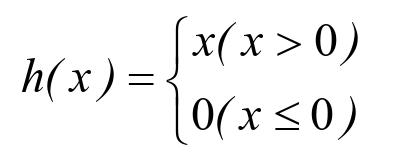
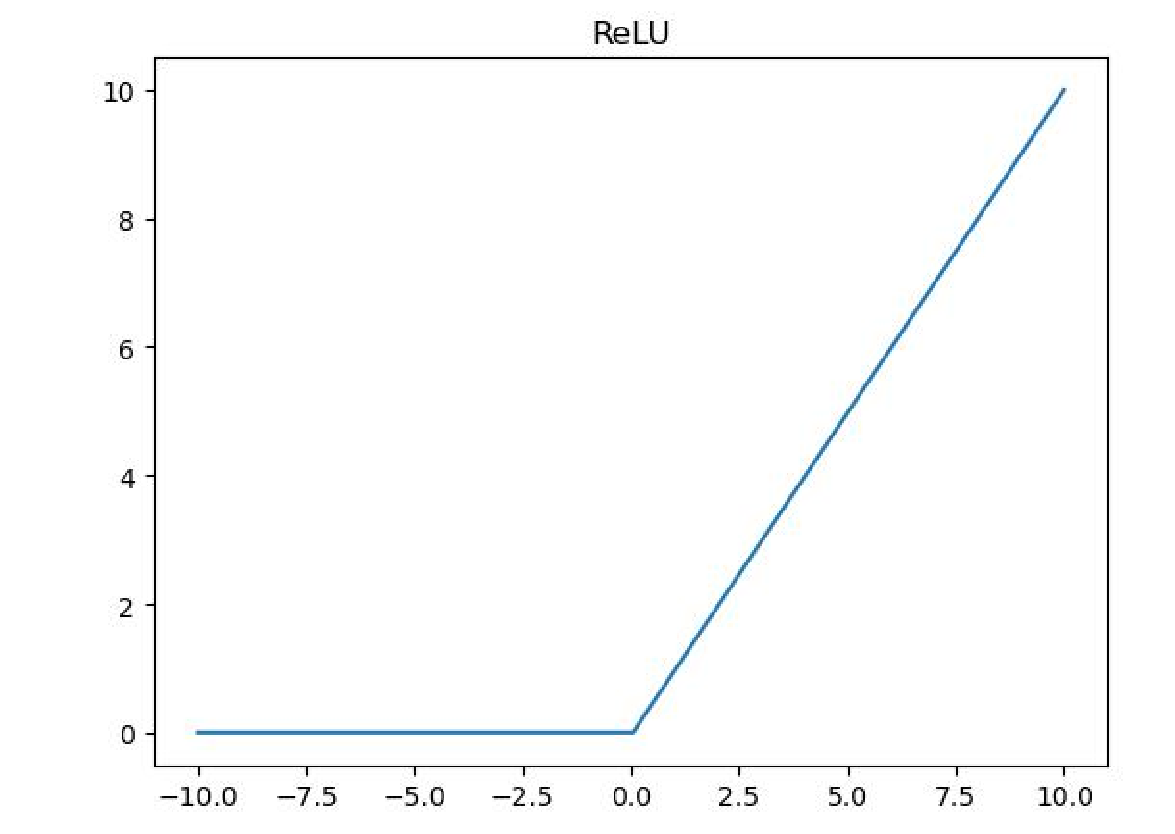
ReLU函数是分段线性函数,把所有的负值都变为0,而正值不变,这种操作被称为单侧抑制。在输入是正值的情况下输出自身,神经元被激活,而在输入是负值的情况下,它会输出0,那么神经元就不会被激活。这意味着同一时间只有部分神经元会被激活,从而使得网络很稀疏,对于计算来说非常有效率。ReLU激活函数如图所示:
(3)Softmax激活函数
Softmax激活函数常用在多分类深度神经网络最后的输出层。它的作用是将一个n位的向量进行归一化,使n位向量每一位的和为1,即总的概率为1。Softmax激活函数的公式可以表示为式:
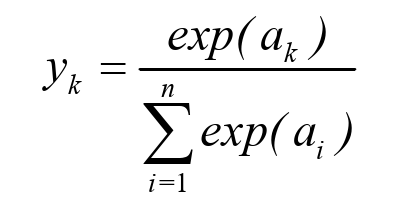
式中:ak表示第k个神经元的输入,yk表示第k个神经元的输出
1.4 损失函数
在深度学习中,损失函数代表着预测结果与真实结果的差异。它能够反映当前模型的性能优劣。通过以损失值为基准对模型进行训练,从而寻找最优的权重参数。
在神经网络的学习中,寻找最优参数(权重和偏置)时,要寻找使损失函数的值尽可能小的参数。为了找到使损失函数的值尽可能小的地方,需要计算参数的导数(确切地讲是梯度),然后以这个导数为指引,逐步更新参数的值。
假设有一个神经网络,现在我们来关注这个神经网络中的某一个权重参数。此时,对该权重参数的损失函数求导,表示的是“如果稍微改变这个权重参数的值,损失函数的值会如何变化”。
- 如果导数的值为负,通过使该权重参数向正方向改变,可以减小损失函数的值;
- 如果导数的值为正,则通过使该权重参数向负方向改变,可以减小损失函数的值;
- 当导数的值为 0 时,无论权重参数向哪个方向变化,损失函数的值都不会改变,此时该权重参数的更新会停在此处。(https://blog.csdn.net/wohu1104/article/details/106844664/)
(1)均方误差(差值距离)
均方误差(MSE,mean squared error)为回归问题中最常用的损失函数,它表示预测值与目标值之差的平方。均方误差的公式为式:
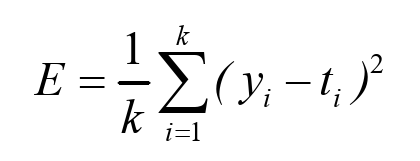
式中:k表示数据的维数,yi表示预测数据中的第i位数值,ti表示真实数据中的第i位数值。
(2)交叉熵误差(cross entropy error)
除均方误差之外,交叉熵误差也经常被用作损失函数。使用交叉熵损失函数可以避免在训练后期梯度下降过慢的问题,交叉熵损失函数的公式如式所示。
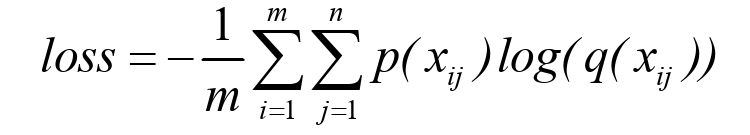
式中:m表示m个样本数;n表示n维向量,代表n个类别;i表示m个样本中的第i个样本;j表示n维向量中的第j个元素;p(xij)代表标签的真实值;q(xij)代表标签预测值。
1.5 优化器
优化器是基于损失函数来更新网络权重的机制,能对网络参数进行高效的更新。
(1)SGD优化器
SGD是随机梯度下降优化器,是最简单的优化器,即参数向梯度下降最快的方向更新。SGD优化器的公式如下:

式中:Wt为t时刻的模型权重,η为学习率,gt为Wt在t时刻的梯度。
(2)Adam优化器
Adam优化器能够自适应调节学习率以及优化损失函数在更新中存在摆动幅度过大的问题,可以实现参数空间的高效搜索。Adam优化器的公式:


论文学习摘录:李想. 深度学习技术在混凝土裂缝识别及混凝土单轴受压本构中的应用[D]. 南昌大学, 2022.