第二章 Google生产环境:SRE视角
Google 数据中心与其他传统数据中心和小型服务器集群相比非常不同。这些差异有好处也有坏处,本章将详细讨论 Google 数据中心建设中遇到的机遇与挑战。
硬件
数据中心(供电系统,制冷系统,网络系统,计算机硬件)
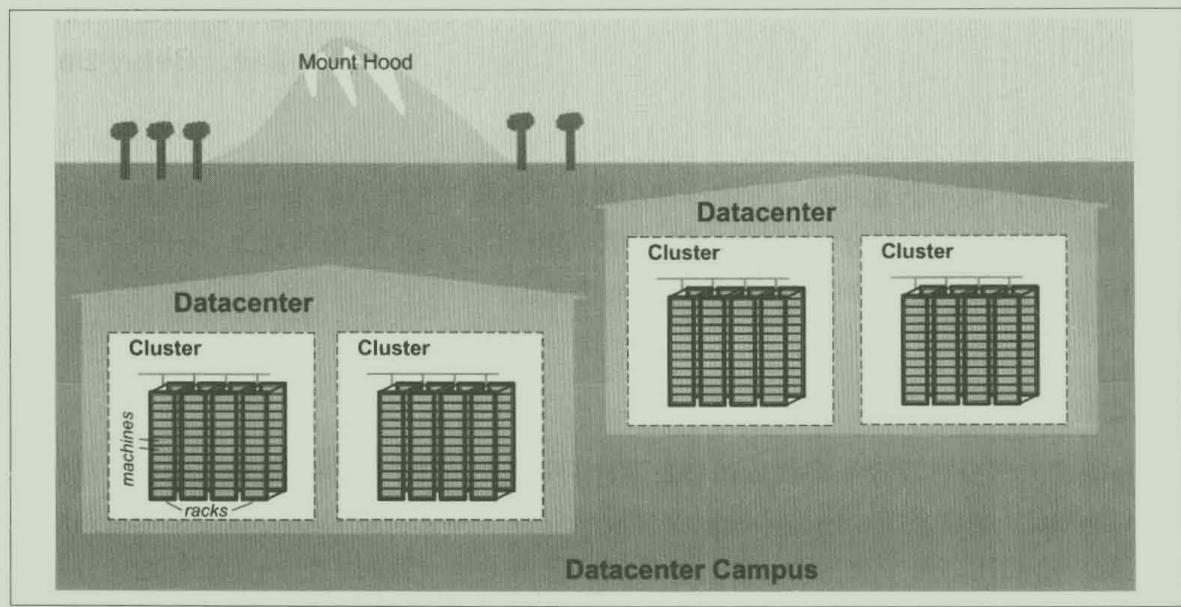
- 约10台物理服务器组成一个机柜(rack)
- 数台机柜组成一个机柜排(row)
- 一排或多排机柜组成了一个集群(cluster)
- 一般来说,一个数据中心(dataCenter)包含多个集群
- 多个相邻的数据中心组成了一个园区(campus)
管理物理服务器的系统管理软件
在一年内,一个单独集群中平均会发生几千起物理服务器损坏事件,会损失几千块硬盘。需要将硬件故障和实际业务用户隔离开来。
管理物理服务器
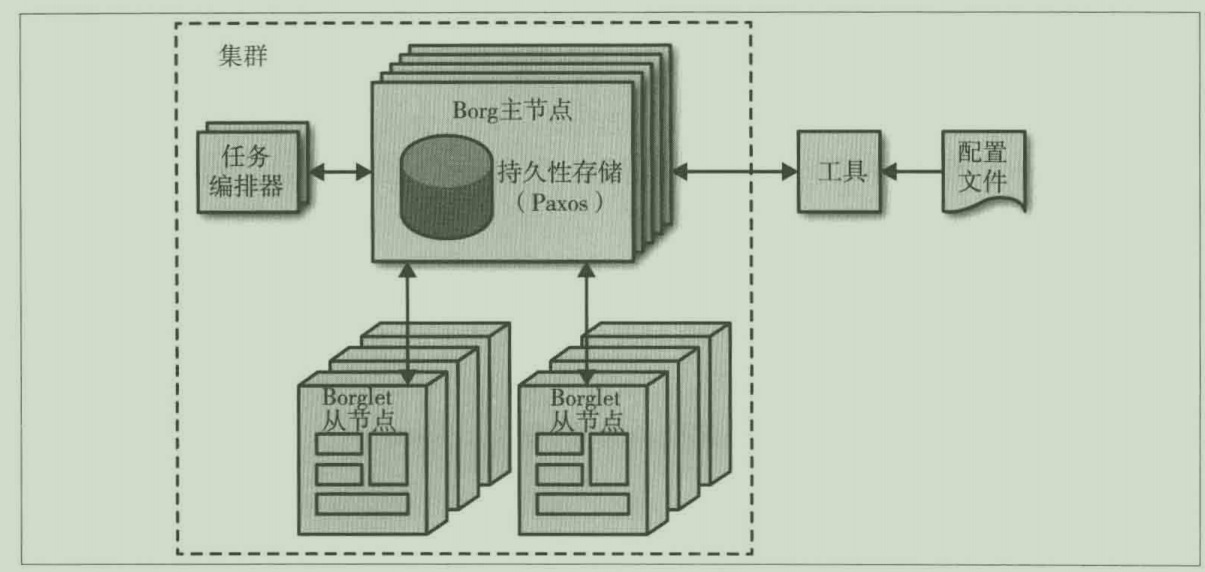
Borg的下一代:K8S
Borg 负责运行用户提交的 "任务"(job),每个任务由一个或多个实例(task)组成。当Borg 启动一个任务的时候,它会为每一个实例安排一台物理服务器,并且执行具体的程序启动它。Borg 同时会不断监控这些实例,如果发现某个实例出现异常,其会终止该实例,并且重启它,有时候会在另外一台物理服务器上重启。
因为任务实例与机器并没有一对一的固定对应关系,所以我们不能简单地用 IP地址和端口来指代某一个具体任务实例。为了解决这个问题,我们增加了一个新的抽象层。每当Borg 启动某一个任务的时候,它会给每个具体的任务实例分配一个名字和一个编号,这个系统称之为 Borg名称解析系统(BNS)。当其他任务实例连接到某个任务实例时,使用BNS名称建立连接,BNS系统负责将这个名称转换成具体的IP 地址和端口进行连接。举例如下,一个BNS 地址可能是这样一个字符串: /bns/< 集群名>/用户名>/<任务名>/<实例名>,这个BNS地址最终将会被解析为 IP地址:端口。
Borg 还负责将具体资源分配给每个任务。每个任务都需要在配置文件中声明它需要的具体资源(例如: 3CPU核心,2GB 内存等)。有了这样的信息,Borg 可以将所有的任务实例合理分配在不同的物理服务器上,以提高每个物理服务器的利用率。同时 Borg 还关注物理服务器的故障域(failure domain)属性。例如,Borg 不会将某个任务的全部实例都运行在某一个机柜上。因为这样一来,机柜交换机将成为整个任务的单点故障源。
如果一个任务实例资源使用超出了它的分配范围,Borg 会杀掉这个实例,并且重启它我们发现,一个缓慢的不断重启的实例要好过一个永远不重启一直泄露资源的实例。
存储
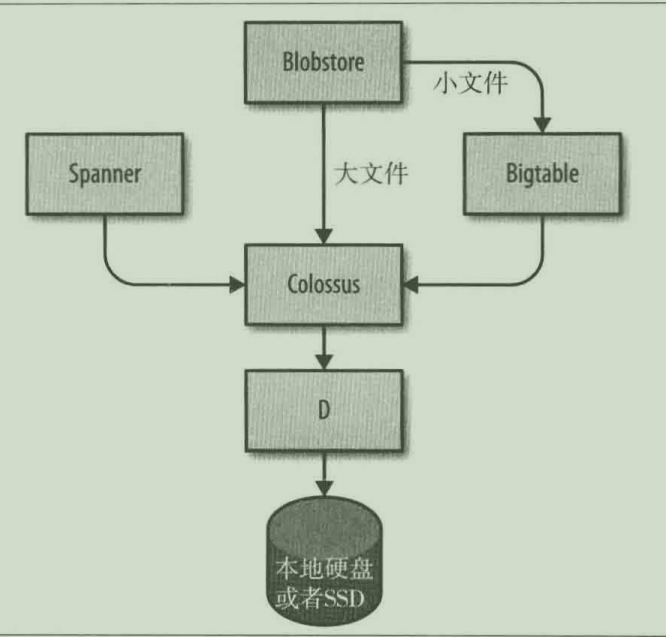
- 最底层由成为 D 的服务提供(D 代表磁盘 Disk)
- D上面一层称为 Colossus,Colossus 建立了一个覆盖了整个集群的文件系统。Colossus 是 GFS 的改进版本。
- 构建于 Colossus 之上,有几个类似的数据库服务可供选择:
- Bigtable 是一个 NoSQL 数据库
- Spanner 可提供 SQL 接口以及满足一致性要求的全球数据库
网络
我们希望能够将用户指派给距离最近的、有空余容量的数据中心处理。我们的全球负载均衡系统(GSLB)在三个层面上负责负载均衡工作:
- 利用地理位置信息进行负载均衡 DNS 请求
- 在用户服务层面进行负载均衡
- 在远程调用层面进行负载均衡
其他系统软件
分布式锁服务(chubby):使用Paxos协议来提供分布式一致性
监控与警报系统:Borgmon 监控程序实例。Borgmon 定期从监控对象抓取监控指标(Metric)。这些监控指标可以被用来触发警报,也可以存储起来供以后观看。主要有以下几种方式使用监控系统:
- 对真实问题进行报警
- 对比服务更新前后的状态变化:新的版本是否让软件服务器进行得更快了?
- 检查资源使用量随时间的变化情况,这些信息对合理制定资源计划很有用
软件基础设施
RPC:Stubby,gRPC
Protocol Buffer 是 Google RPC 的传输方式,通常简写为 Protobuf,与 Apache Thrift 类似
研发环境
开发后,提交改动申请(changelist,CL),等待代码评审