C++实现LL1语法分析器:
预备知识:
LL1分析法是一种确定的自上而下的分析方法,通过在输入中向前看固定个数(通常为1)的符号来选择正确的产生式从而实现预测分析的效果,预测分析不需要回溯。
由以上定义,LL1分析器是一种表驱动的语法分析器,分析器依赖于语法分析表,需要在输入串读入字符前选取表中对应产生式进行下一步动作。因此,我们需要提前构建三个集合再根据这三个集合来创建LL1分析表,这三个集合的的构建和定义分别如下:
- FIRST集合的构造和定义:


-
FOLLOW集的定义和构造:


-
SELECT集的构造和定义:

- LL(1)文法的定义:

LL(1)分析器的构造过程:先通过算法构造FIRST集合,然后构造FOLLOW集合(别忘了反复检查,以及FOLLOW集之间的依赖关系)最后根据产生式以及对应的FIRST集和FOLLOW集构造SELECT集,再由SELECT集归约得到LL(1)分析器。
有了以上预备知识,我们就可以着手构建LL1分析表与LL1语法分析器了
构建字符表:
构建字符表,由于当前语法分析器不具有消除左递归和回溯的能力,因此仅支持LL1文法,我们这里采取的方案是从文件中读取相关LL1文法,并将对应非终结字符和终结字符以及产生式都存储起来以便于接下来构造集合
- 数据结构:
class Grammar
{
public:
//字符表
list<char> alphabet[N][N];
//终结符表
char terminalChar[N];
//终结符个数
int terNum;
//非终结符个数
int count;
//每个非终结符的产生式个数
int countEachRow[N];
Grammar(){
terNum=0;
}
};
- 相关构建函数与读取文法步骤如下:
//读取文法考虑以下情况:
//1. 读取文法并拆分成多行(依据\n分隔)
//2. 对每行文法进行解析,可能一行具有多个产生式,需要将每个产生式存进产生式表
//3. 将产生式中的终结符保存至对应的终结符表
//判断一个字符是否为非终结字符
bool isNonTer(char ch);
//判断一个字符是否为空字
bool isEmpty(char ch);
//判断一个字符是否为终结字符
bool isTer(char ch);
//读取文法
void readGrammar();
FIRST集:
根据FIRST集的定义,从字符表中读取对应产生式,并对每个非终结符的每个产生式进行分类讨论构建FIRST集。
- 数据结构:
class FIRST
{
public:
//first集合
set<char> first[N];
//非终结符数组
char nonTer[N];
//构造完成first集的非终结符个数
bool flags[N]={0};
//计数器
int calCount;
FIRST(){
calCount=0;
}
};
- 相关构建函数与FIRST集合计算规则如下:
//FIRST集计算规则:
//FIRST集的定义:非终结符产生式的首终结符集合
//1. 首先是特殊情况,如果一个产生式全是非终结符且每个非终结符的first集都包含空字
//且first集计算完成则将产生式中每个非终结符的first集都加入其中,且包含空字
//2. 如果一个产生式的前i-1个非终结符都包含空字,但第i个不包含,则不将空字加入其中
//考虑到规则1,2的共有情况,先采取循环将计算出first集且包含空字的非终结符first集
//先加入其中,然后再根据产生式是否到达边界判断是否应该将空字加入
//3. 考虑到first集之间具有依赖关系,如果出现当前非终结符依赖另一个非终结符的first集
//但该集还未计算出来的情况,则考虑对first集合的计算添加多次循环,只要所有非终结符
//的first集都未计算完成,则对应那些flag=false的非终结符都需要再次计算first集
//4. 对于终结符,直接将终结符加入first集然后置flag为true结束first集的计算
//获取非终结字符在字符表中的索引
int getNonTerIndex(char ch);
//检测第i个FIRST集是否含有空字
bool hasEmpty(int i);
//计算两个FIRST集合的并集
void UnionFIRST(int i,int j);
//更新FIRST集的计数
int reloadFIRSTCalCount();
//计算FIRST集
void calFIRST();
//输出first集
void printFIRST();
FOLLOW集:
根据FOLLOW集的定义,我们需要查找每一个非终结符在所有产生式中所处的位置,然后根据位置情况进行分类讨论,构建对应的FOLLOW集。
- 数据结构:
//用来记录非终结符在各个产生式中的位置
class Position
{
//x代表非终结符索引,y代表产生式索引
public:
int x;
int y;
Position(){
x=-1;
y=-1;
}
};
class FOLLOW
{
public:
//follow集
set<char> follow[N];
//标志计算完成follow集的非终结符个数
bool flags[N]={0};
//非终结符数组
char nonTer[N];
//位置向量。用来记录非终结符在产生式中所处的位置
vector<Position> position[N];
//计数器
int calCount;
FOLLOW(){
calCount=0;
}
};
- 相关构建函数与FOLLOW集合的计算规则如下:
//FOLLOW集计算规则:
//FOLLOW集的定义:各个产生式右部中紧跟着非终结符的终结符集合
//1. 首先考虑特殊情况,如果非终结符以后的是FIRST集中带有空字的非终结符,则将除空字
//以外的FIRST集元素并入当前非终结符FOLLOW集。
//2. 如果在条件1以后迭代器指向空,且当前非终结符的FOLLOW集计算完成则将当前产生式左部
//的非终结符的FOLLOW集加入到当前非终结符的FOLLOW集中。
//3. 考虑到FOLLOW集之间存在依赖关系,如果出现当前非终结符的FOLLOW集依赖于另一个非终结符
//的FOLLOW集但该集合还未计算出来的情况,需要设置标签,并对FOLLOW集的计算添加多次循环,
//只要所有非终结符的FOLLOW集都未计算完成,则对应那些flag=false的非终结符都需要再次计算FOLLOW集
//4. 对于终结符,则直接将终结符加入到当前非终结符的FOLLOW集中。
//5. 对于空字,则将产生式左部的FOLLOW集并入到当前非终结符的FOLLOW集中。
//获取非终结符在其它非终结符产生式中所处的位置
void getPosition();
//将FIRST集去空加入FOLLOW集,i代表FOLLOW,j代表FIRST集
void calFollowAndFirstUnion(int i,int j);
//计算两个FOLLOW集的并集
void calFollowAndFollowUnion(int i,int j);
//更新FOLLOW集的计数
int reloadFOLLOWCalCount();
//计算FOLLOW集
void calFOLLOW();
//打印FOLLOW集
void printFOLLOW();
SELECT集合:
根据SELECT集合的定义,结合之前求出来的FIRST集合与FOLLOW集合,为每一个产生式都构造对应的SELECT集合。
- 数据结构:
class SELECT
{
public:
//select集
set<char> select[N][N];
//非终结符数组
char nonTer[N];
};
- 相关构建函数与SELECT集合的计算规则如下:
//SELECT集计算规则:
//SELECT集定义:产生式的终结符可选集
//1. 首先考虑特殊情况,如果当前产生式右部首字符为FIRST集包含空字的非终结符,则将非终结符
//的去空FIRST集加入到当前产生式的SELECT集中,并向下继续查看是否有满足条件的非终结符
//2. 如果在条件1以后迭代器指向空则将当前产生式左部的非终结符的FOLLOW集加入到当前产生式
//的SELECT集中
//3. 如果当前产生式右部首字符为FIRST集不包含空字的非终结符,则将对应非终结符的FIRST集加入到
//当前产生式的SELECT集中
//4. 如果当前产生式右部首字符为终结符则将终结符加入到当前产生式的SELECT集中
//5. 如果当前产生式右部首字符为空,则与条件2进行相同处理
//获取终结符在终结符表中的索引
int getTerminalIndex(char ch);
//将产生式转为字符串
string charToString(int i,int j);
//计算SELECT集
void calSELECT();
//打印SELECT集并将其输出到文件中
void printSELECT();
LL1分析表:
根据SELECT集合,为每一个SELECT集合中出现的终结符选择对应的产生式构建LL1分析表,并对没有产生式的表项做空项处理:
- 数据结构:
class AnalyseTable
{
public:
//LL1分析表
string analyseTable[N][N];
};
- 相关构建函数与LL1分析表计算规则:
//构建LL1分析表:
//1. 每行表头为非终结符,每列表头为终结符
//2. 根据select集以对应非终结符和终结符为索引填入对应产生式
//3. 其余表中元素填入syn代表空(此部分可以放在初始化函数中进行)
//LL1分析表初始化
void initAnalyseTable();
//构建预测分析表
void buildAnalyseTable();
//打印预测分析表
void printAnalyseTable();
LL1语法分析器:
输入字符串,并根据SELECT集合与栈结构实现表驱动的自上而下的语法分析:
- 相关构建函数与语法分析规则如下:
//语法分析器:
//1. 首先进行初始化,保存输入的字符串,并将结束符与开始符入栈,结束符在栈底
//2. 然后进入循环,每次循环都根据字符串中的第一个元素与符号栈中的栈顶元素查表,找到对应的产生式,
//3. 如果产生式为空字则将栈顶元素出栈,并进入下一个循环
//4. 如果产生式不为空字则将栈顶元素出栈并将产生式中的元素入栈
//5. 如果查表找到的对应表项为空,则打印错误并停止运行
//将vector中的字符转化为字符串
string vecToString(vector<char> &vec);
//LL1语法分析器
void analyseGrammar();
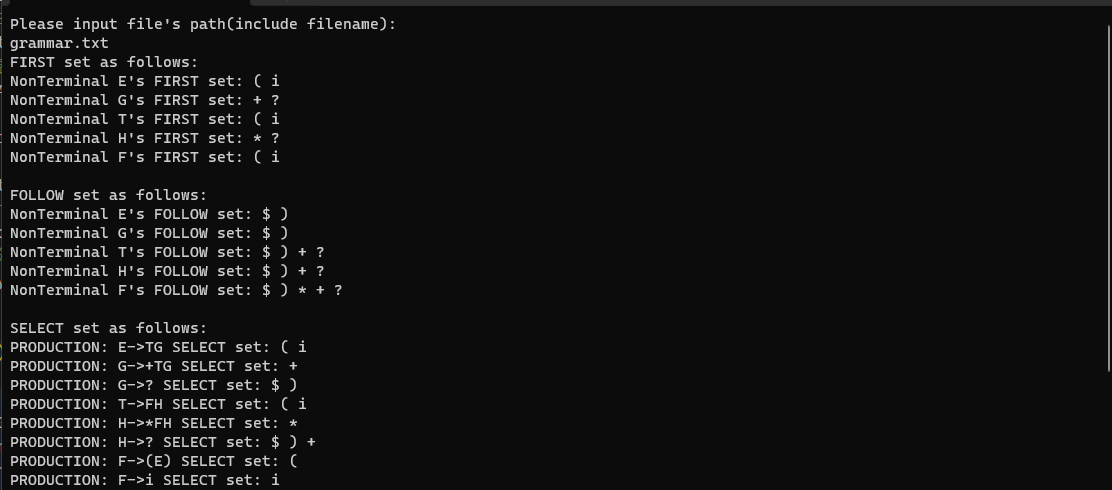
以下是程序运行结果图片:
-
grammar.txt

-
运行结果


-
LL1_analyse.txt

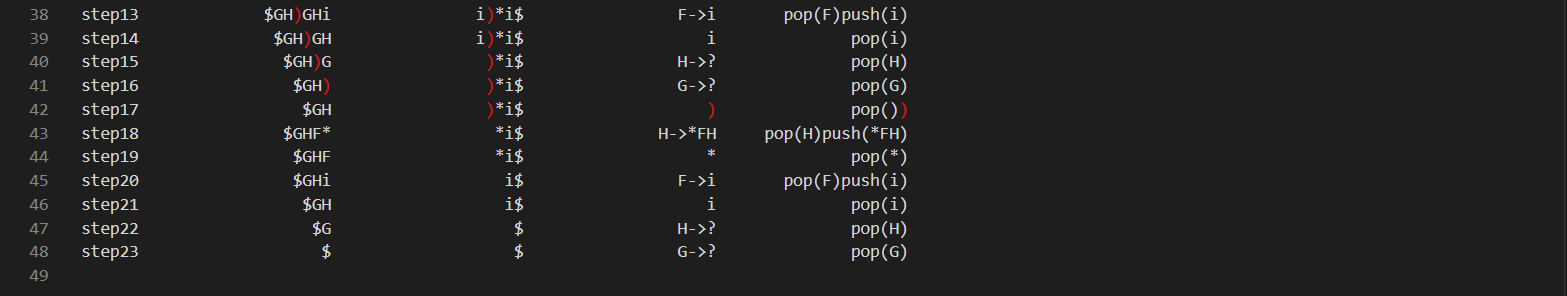
以下是程序源代码:
my_LL1_grammar.h:
#ifndef __grammar__
#define __grammar__
#include <list>
#include <set>
#include <vector>
#define N 50
using namespace std;
class Grammar
{
public:
//字符表
list<char> alphabet[N][N];
//终结符表
char terminalChar[N];
//终结符个数
int terNum;
//非终结符个数
int count;
//每个非终结符的产生式个数
int countEachRow[N];
Grammar(){
terNum=0;
}
};
class FIRST
{
public:
//first集合
set<char> first[N];
//非终结符数组
char nonTer[N];
//构造完成first集的非终结符个数
bool flags[N]={0};
//计数器
int calCount;
FIRST(){
calCount=0;
}
};
//用来记录非终结符在各个产生式中的位置
class Position
{
//x代表非终结符索引,y代表产生式索引
public:
int x;
int y;
Position(){
x=-1;
y=-1;
}
};
class FOLLOW
{
public:
//follow集
set<char> follow[N];
//标志计算完成follow集的非终结符个数
bool flags[N]={0};
//非终结符数组
char nonTer[N];
//位置向量。用来记录非终结符在产生式中所处的位置
vector<Position> position[N];
//计数器
int calCount;
FOLLOW(){
calCount=0;
}
};
class SELECT
{
public:
//select集
set<char> select[N][N];
//非终结符数组
char nonTer[N];
};
class AnalyseTable
{
public:
//LL1分析表
string analyseTable[N][N];
};
#endif
my_LL1_grammar.cpp:
#include<iostream>
#include<fstream>
#include<iomanip>
#include<list>
#include<Cstring>
#include<algorithm>
#include<stack>
#include<set>
#include<string>
#include "my_LL1_grammar.h"
//类变量声明:
FIRST first;
Grammar grammar;
FOLLOW follow;
SELECT select;
AnalyseTable analyseTable;
//函数声明:
//判断一个字符是否为非终结字符
bool isNonTer(char ch);
//判断一个字符是否为空字
bool isEmpty(char ch);
//判断一个字符是否为终结字符
bool isTer(char ch);
//读取文法
void readGrammar();
//获取非终结字符在字符表中的索引
int getNonTerIndex(char ch);
//检测第i个FIRST集是否含有空字
bool hasEmpty(int i);
//计算两个FIRST集合的并集
void UnionFIRST(int i,int j);
//更新FIRST集的计数
int reloadFIRSTCalCount();
//计算FIRST集
void calFIRST();
//输出first集
void printFIRST();
//获取非终结符在其它非终结符产生式中所处的位置
void getPosition();
//将FIRST集去空加入FOLLOW集,i代表FOLLOW,j代表FIRST集
void calFollowAndFirstUnion(int i,int j);
//计算两个FOLLOW集的并集
void calFollowAndFollowUnion(int i,int j);
//更新FOLLOW集的计数
int reloadFOLLOWCalCount();
//计算FOLLOW集
void calFOLLOW();
//打印FOLLOW集
void printFOLLOW();
//获取终结符在终结符表中的索引
int getTerminalIndex(char ch);
//将产生式转为字符串
string charToString(int i,int j);
//计算SELECT集
void calSELECT();
//打印SELECT集并将其输出到文件中
void printSELECT();
//LL1分析表初始化
void initAnalyseTable();
//构建预测分析表
void buildAnalyseTable();
//打印预测分析表
void printAnalyseTable();
//将vector中的字符转化为字符串
string vecToString(vector<char> &vec);
//LL1语法分析器
void analyseGrammar();
int main()
{
readGrammar();
calFIRST();
printFIRST();
calFOLLOW();
printFOLLOW();
calSELECT();
printSELECT();
buildAnalyseTable();
printAnalyseTable();
analyseGrammar();
system("pause");
return 0;
}
//读取文法考虑以下情况:
//1. 读取文法并拆分成多行(依据\n分隔)
//2. 对每行文法进行解析,可能一行具有多个产生式,需要将每个产生式存进产生式表
//3. 将产生式中的终结符保存至对应的终结符表
void readGrammar()
{
//输入文法文件路径
printf("Please input file's path(include filename):\n");
string route;
cin>>route;
ifstream file;
file.open(route.c_str(),ios::in);
string str;
//选取容器set来保存终结符可以避免读取多个产生式时终结符重复insert的问题
set<char> terminal;
char buf[100]={0};
//差错检测
if(!file.is_open())
{
cerr<<"Unable to open the file,please checkout your file's path"<<endl;
exit(1);
}
//读取文法直到文件末尾
int i=0,count=0,index=0;
while(getline(file,str))
{
strcpy(buf,str.c_str());
i=0;
count=0;
//保存产生式左部非终结符
grammar.alphabet[index][count].push_back(buf[i]);
first.nonTer[index]=buf[i];
follow.nonTer[index]=buf[i];
select.nonTer[index]=buf[i];
i+=3;
//判断是否到达边界
while((int)buf[i]!=0)
{
//如果检测到'|'则进入下一个产生式,count自加
if((int)buf[i]==124)
{
count++;
i++;
//保存产生式左部非终结符
grammar.alphabet[index][count].push_back(buf[0]);
}
else
{
grammar.alphabet[index][count].push_back(buf[i]);
//如果是终结符则保存终结符
if(isTer(buf[i]))
{
terminal.insert(buf[i]);
}
i++;
}
}
//保存当前非终结符的产生式个数
grammar.countEachRow[index]=count+1;
index++;
}
//保存文法中非终结符的个数
grammar.count=index;
//读取完所有句子后,保存终结符集合
set<char>::iterator it = terminal.begin();
for(it;it != terminal.end();it++)
{
grammar.terminalChar[grammar.terNum] = *it;
grammar.terNum++;
}
//需要将特殊符号'$'加入
grammar.terminalChar[grammar.terNum] = '$';
grammar.terNum++;
//关闭文法文件
file.close();
}
bool isTer(char ch)
{
//不为非终结符和空字即为终结符
if((!isNonTer(ch))&&(!isEmpty(ch)))
{
return true;
}
else
{
return false;
}
}
bool isNonTer(char ch)
{
if(ch >64 &&ch < 91)
{
return true;
}
else
{
return false;
}
}
bool isEmpty(char ch)
{
if(ch == '?')
{
return true;
}
else
{
return false;
}
}
//FIRST集计算规则:
//FIRST集的定义:非终结符产生式的首终结符集合
//1. 首先是特殊情况,如果一个产生式全是非终结符且每个非终结符的first集都包含空字
//且first集计算完成则将产生式中每个非终结符的first集都加入其中,且包含空字
//2. 如果一个产生式的前i-1个非终结符都包含空字,但第i个不包含,则不将空字加入其中
//考虑到规则1,2的共有情况,先采取循环将计算出first集且包含空字的非终结符first集
//先加入其中,然后再根据产生式是否到达边界判断是否应该将空字加入
//3. 考虑到first集之间具有依赖关系,如果出现当前非终结符依赖另一个非终结符的first集
//但该集还未计算出来的情况,则考虑对first集合的计算添加多次循环,只要所有非终结符
//的first集都未计算完成,则对应那些flag=false的非终结符都需要再次计算first集
//4. 对于终结符,直接将终结符加入first集然后置flag为true结束first集的计算
void calFIRST()
{
//所有非终结符的first集并未计算完成
while(first.calCount != grammar.count)
{
//扫描每一个非终结符
for(int i=0;i<grammar.count;i++)
{
//如果当前非终结符的first集未计算完成
if(!first.flags[i])
{
//扫描每一个产生式
for(int j=0;j<grammar.countEachRow[i];j++)
{
list<char>::iterator it = grammar.alphabet[i][j].begin();
//获取产生式右部首字符
it++;
//如果产生式右部是已经计算完first集的非终结符且包含空字
while(isNonTer(*it) && first.flags[getNonTerIndex(*it)]==true && hasEmpty(getNonTerIndex(*it)))
{
//将对应非终结符的first集并入当前非终结符
UnionFIRST(i,getNonTerIndex(*it));
it++;
}
//如果此时it到达边界,说明产生式全是first集带有空字的非终结符
if(it == grammar.alphabet[i][j].end())
{
//将空字加入当前非终结符的first集
first.first[i].insert('?');
first.flags[i]=true;
//当前产生式遍历完毕,遍历下一个产生式
continue;
}
else
{
//如果为终结符或是空字则直接添加
if(isTer(*it) || (*it)=='?')
{
first.first[i].insert(*it);
first.flags[i]=true;
}
//如果是非终结符
else if(isNonTer(*it))
{
//如果计算过first集,则直接并入当前非终结符的first集
if(first.flags[getNonTerIndex(*it)]==true)
{
first.flags[i]=true;
UnionFIRST(i,getNonTerIndex(*it));
}
//如果没有计算过,则重置当前非终结符的flag为false,以便下一次遍历
else
first.flags[i]=false;
}
}
}
}
}
reloadFIRSTCalCount();
}
}
int reloadFIRSTCalCount()
{
int count =0;
for(int i=0;i<grammar.count;i++){
if(first.flags[i] == true){
count++;
}
}
first.calCount = count;
return count;
}
int getNonTerIndex(char ch)
{
int index=0;
for(index;index<grammar.count;index++)
{
if(ch==first.nonTer[index])
{
break;
}
}
return index;
}
bool hasEmpty(int i)
{
set<char>::iterator it = first.first[i].begin();
for(it;it!=first.first[i].end();it++)
{
if(*it=='?')
{
return true;
}
}
return false;
}
void UnionFIRST(int i,int j)
{
set<char>::iterator it = first.first[j].begin();
//如果有空字则去除空字
for(it;it!=first.first[j].end();it++)
{
if(!isEmpty(*it))
first.first[i].insert(*it);
}
return;
}
void printFIRST()
{
ofstream file;
file.open("LL1_analyse.txt",ios::out);
string str = "FIRST set as follows:";
cout<<str<<endl;
file<<str<<endl;
for(int n=0;n<grammar.count;n++)
{
set<char>::iterator it = first.first[n].begin();
cout<<"NonTerminal "<<first.nonTer[n]<<"'s FIRST set: ";
file<<"NonTerminal"<<first.nonTer[n]<<"'s FIRST set: ";
for(it;it!=first.first[n].end();it++)
{
//printf("%c ",*it);
cout<<*it<<" ";
file<<*it<<" ";
}
//printf("\n");
cout<<endl;
file<<endl;
}
//printf("\n");
cout<<endl;
file<<endl;
file.close();
return;
}
//FOLLOW集计算规则:
//FOLLOW集的定义:各个产生式右部中紧跟着非终结符的终结符集合
//1. 首先考虑特殊情况,如果非终结符以后的是FIRST集中带有空字的非终结符,则将除空字
//以外的FIRST集元素并入当前非终结符FOLLOW集。
//2. 如果在条件1以后迭代器指向空,且当前非终结符的FOLLOW集计算完成则将当前产生式左部
//的非终结符的FOLLOW集加入到当前非终结符的FOLLOW集中。
//3. 考虑到FOLLOW集之间存在依赖关系,如果出现当前非终结符的FOLLOW集依赖于另一个非终结符
//的FOLLOW集但该集合还未计算出来的情况,需要设置标签,并对FOLLOW集的计算添加多次循环,
//只要所有非终结符的FOLLOW集都未计算完成,则对应哪些flag=false的非终结符都需要再次计算FOLLOW集
//4. 对于终结符,则直接将终结符加入到当前非终结符的FOLLOW集中。
//5. 对于空字,则将产生式左部的FOLLOW集并入到当前非终结符的FOLLOW集中。
void calFOLLOW()
{
//获取每一个出现在产生式右部的非终结符在产生式表中的索引
getPosition();
//对于开始符号S,需将'$'加入FOLLOW集
follow.follow[0].insert('$');
//如果所有非终结符的FOLLOW集未计算完成
while(follow.calCount != grammar.count)
{
//扫描所有非终结符
for(int i=0;i<grammar.count;i++)
{
//对于FOLLOW集未计算完成的终结符
if(!follow.flags[i])
{
//遍历当前非终结符在所有产生式右部中的位置
vector<Position>::iterator it = follow.position[i].begin();
for(it;it!=follow.position[i].end();it++)
{
int index = it->x;
int count = it->y;
list<char>::iterator itp = grammar.alphabet[index][count].begin();
itp++;
//找到非终结符在产生式右部中下一个字符的位置
for(itp;itp!=grammar.alphabet[index][count].end();itp++)
{
if(*itp==follow.nonTer[i])
{
itp++;
break;
}
}
//如果下一个字符不为空为非终结符且FIRST集包含空字
while(itp!=grammar.alphabet[index][count].end()&&isNonTer(*itp)&&hasEmpty(getNonTerIndex(*itp)))
{
int ip = getNonTerIndex(*itp);
calFollowAndFirstUnion(i,ip);
itp++;
}
//如果下一个字符不为空,说明该字符为FIRST集不包含空字的非终结符或终结符或空字
if(itp != grammar.alphabet[index][count].end())
{
//如果字符为终结符则将终结符加入当前非终结符的FOLLOW集
if(isTer(*itp))
{
follow.follow[i].insert(*itp);
follow.flags[i]=true;
}
//如果当前字符为非终结符则将非终结符去空字的FIRST集加入当前非终结符的FOLLOW集
else if(isNonTer(*itp))
{
int ip = getNonTerIndex(*itp);
calFollowAndFirstUnion(i,ip);
follow.flags[i]=true;
}
//空字则无操作
else{}
}
//itp指向产生式end指针
else
{
//如果当前产生式左部的非终结符FOLLOW集还未计算则置当前非终结符FOLLOW集计算未完成
if(!follow.flags[index])
follow.flags[i]=false;
else
{
calFollowAndFollowUnion(i,index);
follow.flags[i]=true;
}
}
}
}
}
reloadFOLLOWCalCount();
}
}
void getPosition()
{
//对文法中的每个非终结符
for(int i=0;i<grammar.count;i++)
{
list<char>::iterator it = grammar.alphabet[i][0].begin();
//遍历每个非终结符
for(int j=0;j<grammar.count;j++)
{
//遍历每个非终结符的每个产生式
for(int k=0;k<grammar.countEachRow[j];k++)
{
list<char>::iterator itp = grammar.alphabet[j][k].begin();
itp++;
for(itp;itp!=grammar.alphabet[j][k].end();itp++)
{
if(*it==*itp)
{
Position pos;
pos.x = j;
pos.y = k;
//记录其在产生式右部的位置
follow.position[i].push_back(pos);
}
}
}
}
}
}
int reloadFOLLOWCalCount()
{
int count=0;
for(int n=0;n<grammar.count;n++)
{
if(follow.flags[n]==true)
count++;
}
follow.calCount=count;
return count;
}
void calFollowAndFollowUnion(int i,int j)
{
set<char>::iterator it = follow.follow[j].begin();
for(it;it!=follow.follow[j].end();it++)
{
follow.follow[i].insert(*it);
}
return;
}
void calFollowAndFirstUnion(int i,int j)
{
set<char>::iterator it = first.first[j].begin();
for(it;it!=first.first[j].end();it++)
{
follow.follow[i].insert(*it);
}
return;
}
void printFOLLOW()
{
ofstream file;
file.open("LL1_analyse.txt",ios::app);
//printf("FOLLOW集如下:\n");
cout<<"FOLLOW set as follows:"<<endl;
file<<"FOLLOW set as follows:"<<endl;
for(int n=0;n<grammar.count;n++)
{
set<char>::iterator it = follow.follow[n].begin();
//printf("非终结符%c的FOLLOW集:",follow.nonTer[n]);
cout<<"NonTerminal "<<follow.nonTer[n]<<"'s FOLLOW set: ";
file<<"NonTerminal "<<follow.nonTer[n]<<"'s FOLLOW set: ";
for(it;it!=follow.follow[n].end();it++)
{
//printf("%c ",*it);
cout<<*it<<" ";
file<<*it<<" ";
}
//printf("\n");
cout<<endl;
file<<endl;
}
//printf("\n");
cout<<endl;
file<<endl;
file.close();
return;
}
//SELECT集计算规则:
//SELECT集定义:产生式的终结符可选集
//1. 首先考虑特殊情况,如果当前产生式右部首字符为FIRST集包含空字的非终结符,则将非终结符
//的去空FIRST集加入到当前产生式的SELECT集中,并向下继续查看是否有满足条件的非终结符
//2. 如果在条件1以后迭代器指向空则将当前产生式左部的非终结符的FOLLOW集加入到当前产生式
//的SELECT集中
//3. 如果当前产生式右部首字符为FIRST集不包含空字的非终结符,则将对应非终结符的FIRST集加入到
//当前产生式的SELECT集中
//4. 如果当前产生式右部首字符为终结符则将终结符加入到当前产生式的SELECT集中
//5. 如果当前产生式右部首字符为空,则与条件2进行相同处理
void calSELECT()
{
//扫描每一个非终结符
for(int i=0;i<grammar.count;i++)
{
//扫描非终结符的每一个产生式
for(int j=0;j<grammar.countEachRow[i];j++)
{
//迭代器指向产生式右部首字符
list<char>::iterator it = grammar.alphabet[i][j].begin();
it++;
//如果当前产生式存在FIRST集含空字的非终结符字符串,则将所有非终结符的去空FIRST集加入当前产生式SELECT集中
while(isNonTer(*it)&&hasEmpty(getNonTerIndex(*it)))
{
set<char>::iterator itp = first.first[getNonTerIndex(*it)].begin();
for(itp;itp!=first.first[getNonTerIndex(*it)].end();itp++)
{
if(!isEmpty(*itp))
select.select[i][j].insert(*itp);
}
it++;
}
//如果迭代器指针不为空也不为空字
if(it!=grammar.alphabet[i][j].end()&&(*it)!='?')
{
//为非终结符则将FIRST集并入当前产生式的SELECT集中
if(isNonTer(*it))
{
set<char>::iterator itp = first.first[getNonTerIndex(*it)].begin();
for(itp;itp!=first.first[getNonTerIndex(*it)].end();itp++)
{
select.select[i][j].insert(*itp);
}
}
//为终结符则直接加入
else
{
select.select[i][j].insert(*it);
}
}
//如果迭代器为空或为空字则将当前产生式左部非终结符的FOLLOW集加入当前产生式的SELECT集中
else
{
set<char>::iterator itp = follow.follow[i].begin();
for(itp;itp!=follow.follow[i].end();itp++)
{
if(!isEmpty(*itp))
select.select[i][j].insert(*itp);
}
}
}
}
}
void printSELECT()
{
ofstream file;
file.open("LL1_analyse.txt",ios::app);
//printf("FOLLOW集如下:\n");
cout<<"SELECT set as follows:"<<endl;
file<<"SELECT set as follows:"<<endl;
for(int i=0;i<grammar.count;i++)
{
for(int j=0;j<grammar.countEachRow[i];j++)
{
list<char>::iterator it = grammar.alphabet[i][j].begin();
it++;
string str;
for(it;it!=grammar.alphabet[i][j].end();it++)
{
str.push_back(*it);
}
cout<<"PRODUCTION: "<<grammar.alphabet[i][j].front()<<"->"<<str<<" SELECT set: ";
file<<"PRODUCTION: "<<grammar.alphabet[i][j].front()<<"->"<<str<<" SELECT set: ";
set<char>::iterator itp = select.select[i][j].begin();
for(itp;itp!=select.select[i][j].end();itp++)
{
cout<<*itp<<" ";
file<<*itp<<" ";
}
cout<<endl;
file<<endl;
}
}
cout<<endl;
file<<endl;
file.close();
}
int getTerminalIndex(char ch)
{
int i=0;
for(i;i<grammar.terNum;i++)
{
if(ch==grammar.terminalChar[i])
{
break;
}
}
return i;
}
string charToString(int i,int j){
char buf[100] ={0};
int count = 0;
list<char>::iterator it = grammar.alphabet[i][j].begin();
buf[0] = *it;
buf[1] = '-';
buf[2] = '>';
count+=3;
it++;
for(it;it!=grammar.alphabet[i][j].end();it++){
buf[count] =*it;
count++;
}
buf[count] = '\0';
string str(buf);
return str;
}
//构建LL1分析表:
//1. 每行表头为非终结符,每列表头为终结符
//2. 根据select集以对应非终结符和终结符为索引填入对应产生式
//3. 其余表中元素填入syn代表空(此部分可以放在初始化函数中进行)
void buildAnalyseTable()
{
initAnalyseTable();
for(int i=0;i<grammar.count;i++)
{
for(int j=0;j<grammar.countEachRow[i];j++)
{
set<char>::iterator it = select.select[i][j].begin();
for(it;it!=select.select[i][j].end();it++)
{
analyseTable.analyseTable[i][getTerminalIndex(*it)] = charToString(i,j);
}
}
}
}
void printAnalyseTable()
{
//制表
printf("%-10c",' ');
//LL1分析表列为终结符
for(int i=0;i<grammar.terNum;i++)
{
printf("%-10c",grammar.terminalChar[i]);
}
printf("\n");
//LL1分析表行为非终结符
for(int i=0;i<grammar.count;i++)
{
printf("%-10c",grammar.alphabet[i][0].front());
for(int j=0;j<grammar.terNum;j++)
{
printf("%-10s",analyseTable.analyseTable[i][j].c_str());
//cout<<setw(10)<<analyseTable.analyseTable[i][j];
}
printf("\n");
}
}
void initAnalyseTable()
{
for(int i=0;i<grammar.count;i++)
{
for(int j=0;j<grammar.terNum;j++)
{
analyseTable.analyseTable[i][j]="syn";
}
}
}
//语法分析器:
//1. 首先进行初始化,保存输入的字符串,并将结束符与开始符入栈,结束符在栈底
//2. 然后进入循环,每次循环都根据字符串中的第一个元素与符号栈中的栈顶元素查表,找到对应的产生式,
//3. 如果产生式为空字则将栈顶元素出栈,并进入下一个循环
//4. 如果产生式不为空字则将栈顶元素出栈并将产生式中的元素入栈
//5. 如果查表找到的对应表项为空,则打印错误并停止运行
void analyseGrammar()
{
ofstream file;
file.open("LL1_analyse.txt",ios::app);
//初始化符号栈
stack<char> stack;
vector<char> vec;
printf("Please input string to be analyzed\n");
string str;
cin>>str;
char buf[N]={0};
strcpy(buf,str.c_str());
int count=strlen(buf);
//在待分析的字符串后添加结束符
buf[count++]='$';
//制表
cout<<"STEP"<<setw(2)<<left<<" "<<setw(20)<<right<<"ANASTACK"<<setw(20)<<right<<"INPUTSTRING"<<setw(20)<<right<<"PRODUCTION"<<setw(20)<<right<<"ACTION"<<setw(20)<<right<<"TIPS"<<endl;
file<<"STEP"<<setw(2)<<left<<" "<<setw(20)<<right<<"ANASTACK"<<setw(20)<<right<<"INPUTSTRING"<<setw(20)<<right<<"PRODUCTION"<<setw(20)<<right<<"ACTION"<<setw(20)<<right<<"TIPS"<<endl;
//将结束符$与文法开始符入栈
stack.push('$');
stack.push(grammar.alphabet[0][0].front());
vec.push_back('$');
vec.push_back(grammar.alphabet[0][0].front());
//输入串索引
int index = 0;
int step = 0;
bool isFinish = false;
//分析过程
while(!isFinish)
{
//获取输入串当前首字符与符号栈栈顶字符
char ch,chStack;
ch = buf[index];
chStack = stack.top();
//如果当前符号栈中的字符是终结字符且不为空字
if(isTer(chStack)&&chStack!='$')
{
if(chStack == ch)
{
//栈顶符号出栈
stack.pop();
vec.pop_back();
//输入串指针后移
index++;
step++;
//输出语法分析过程
cout<<"step"<<setw(2)<<left<<step<<setw(20)<<right<<vecToString(vec)<<setw(20)<<right<<(buf+index-1)<<setw(20)<<right<<ch<<setw(20)<<right<<(string)"pop("+ch+(string)")"<<setw(20)<<right<<" "<<endl;
file<<"step"<<setw(2)<<left<<step<<setw(20)<<right<<vecToString(vec)<<setw(20)<<right<<(buf+index-1)<<setw(20)<<right<<ch<<setw(20)<<right<<(string)"pop("+ch+(string)")"<<setw(20)<<right<<" "<<endl;
continue;
}
//差错检测
else
{
printf("There is some error in your input string\n");
exit(1);
}
}
//当前符号栈中的栈顶符号为非终结字符
else if(isNonTer(chStack))
{
string str;
str.push_back(chStack);
str.push_back('-');
str.push_back('>');
str.push_back('?');
//如果当前分析表中对应表项为空项
if(analyseTable.analyseTable[getNonTerIndex(chStack)][getTerminalIndex(ch)] == "syn")
{
printf("There is some error in your input string\n");
system("pause");
exit(1);
}
//如果当前分析表中对应表项为空字
else if(analyseTable.analyseTable[getNonTerIndex(chStack)][getTerminalIndex(ch)]==str)
{
stack.pop();
vec.pop_back();
step++;
cout<<"step"<<setw(2)<<left<<step<<setw(20)<<right<<vecToString(vec)<<setw(20)<<right<<(buf+index)<<setw(20)<<right<<analyseTable.analyseTable[getNonTerIndex(chStack)][getTerminalIndex(ch)]<<setw(20)<<right<<(string)"pop("+chStack+(string)")"<<setw(20)<<right<<" "<<endl;
file<<"step"<<setw(2)<<left<<step<<setw(20)<<right<<vecToString(vec)<<setw(20)<<right<<(buf+index)<<setw(20)<<right<<analyseTable.analyseTable[getNonTerIndex(chStack)][getTerminalIndex(ch)]<<setw(20)<<right<<(string)"pop("+chStack+(string)")"<<setw(20)<<right<<" "<<endl;
continue;
}
//当前对应表项为产生式
else
{
string str1 = analyseTable.analyseTable[getNonTerIndex(chStack)][getTerminalIndex(ch)];
stack.pop();
vec.pop_back();
for(int i=str1.length()-1;i>=3;i--)
{
stack.push(str1[i]);
vec.push_back(str1[i]);
}
str1 = str1.substr(3);
step++;
string push = "push(";
string pop = "pop(";
cout<<"step"<<setw(2)<<left<<step<<setw(20)<<right<<vecToString(vec)<<setw(20)<<right<<(buf+index)<<setw(20)<<right<<analyseTable.analyseTable[getNonTerIndex(chStack)][getTerminalIndex(ch)]<<setw(20)<<right<<pop+chStack+(string)")"+push+str1+(string)")"<<setw(20)<<right<<" "<<endl;
file<<"step"<<setw(2)<<left<<step<<setw(20)<<right<<vecToString(vec)<<setw(20)<<right<<(buf+index)<<setw(20)<<right<<analyseTable.analyseTable[getNonTerIndex(chStack)][getTerminalIndex(ch)]<<setw(20)<<right<<pop+chStack+(string)")"+push+str1+(string)")"<<setw(20)<<right<<" "<<endl;
}
}
else if(chStack =='$')
{
if(ch == chStack)
isFinish = true;
else
{
printf("There is some error occur\n");
system("pause");
exit(1);
}
}
else
{
printf("There is some error occur\n");
system("pause");
exit(1);
}
}
file.close();
}
string vecToString(vector<char> &vec)
{
char buf[N] = {0};
int index = 0;
vector<char>::iterator it = vec.begin();
for(it;it!=vec.end();it++)
{
buf[index] = *it;
index++;
}
buf[index] = '\0';
string str(buf);
return str;
}