一、ZooKeeper简介
ZooKeeper是一个分布式协调服务,提供了诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知和分布式锁等分布式基础服务。
1.1、数据结构
ZooKeeper采用znode的树状层级结构来存储信息,znode节点可能包含数据也可能没有数据,znode存储数据格式为字节数组,znode数据结构如下图示:
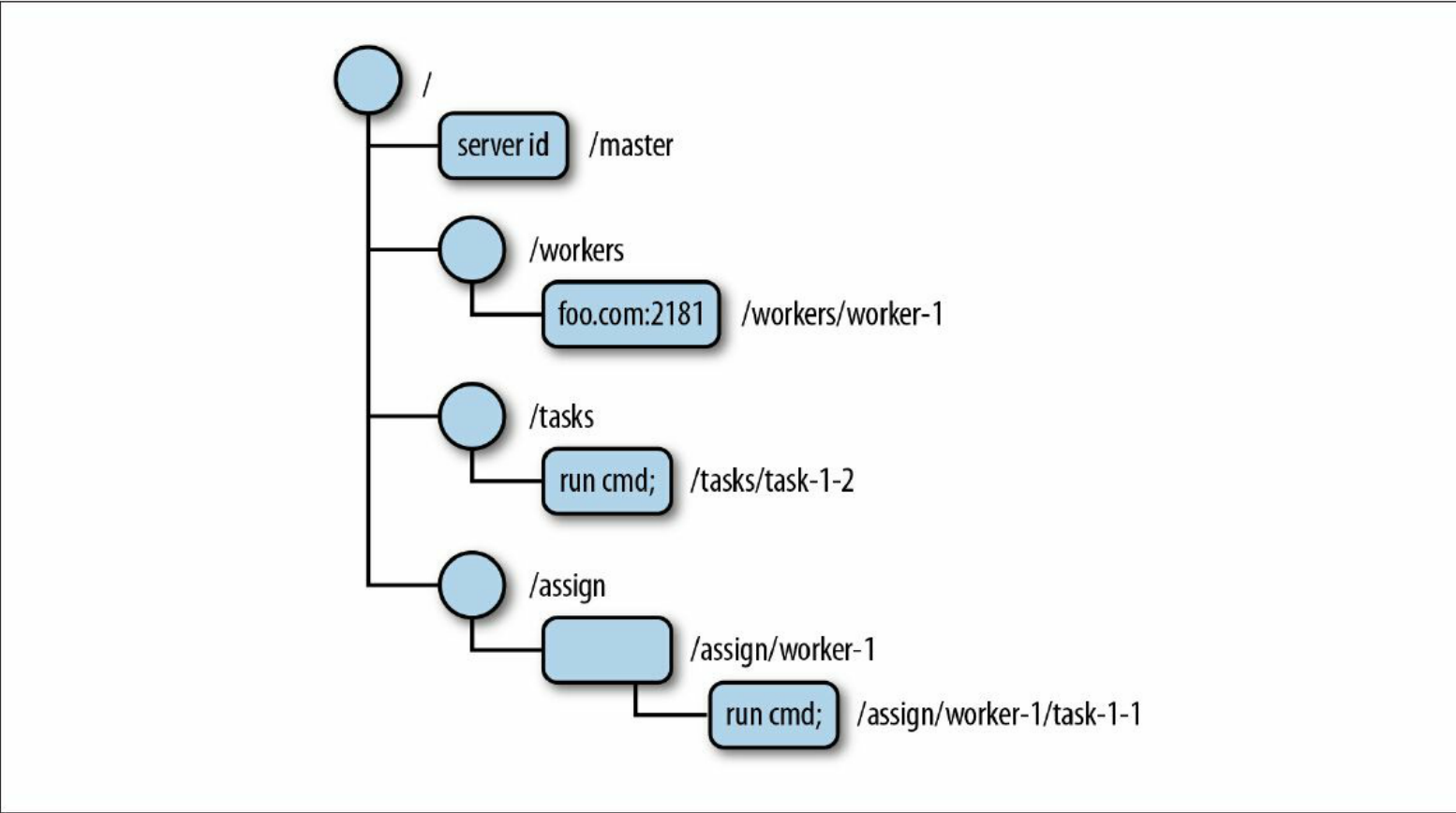
ZooKeeper提供了如下API:
1、创建znode节点/path并包含数据data:create/path data
2、删除节点:delete/path
3、判断节点是否存在:exists/path
4、设置节点数据:setData/path data
5、获取节点数据:getData/path
6、获取节点的子节点:getChildren/path
ZooKeeper读取或写入节点数据时不允许局部操作,只允许读取全部数据或写入覆盖全部数据;
1.2、ZooKeeper节点类型
ZooKeeper节点类型包括持久(persistent)节点和临时(ephemeral)节点
持久节点一旦创建就会持久化,直到通过delete命令删除节点;
临时节点创建之后生命周期和客户端连接生命周期一致,一旦客户端连接关闭就会自动删除给客户端创建的所有临时节点,当然临时节点也可以主动删除。
持久节点可以创建子节点,但是临时节点不允许创建子节点,因为临时节点一旦客户端连接断开就会删除。
有序节点
一个znode还可以设置为有序(sequential)节点。一个有序znode节 点被分配唯一个单调递增的整数。当创建有序节点时,一个序号会被追 加到路径之后。例如,如果一个客户端创建了一个有序znode节点,
其路径为/tasks/task-,那么ZooKeeper将会分配一个序号,如1,并将这个 数字追加到路径之后,最后该znode节点为/tasks/task-1。
有序znode通过 提供了创建具有唯一名称的znode的简单方式。同时也通过这种方式可 以直观地查看znode的创建顺序
所以,znode一共有4种类型:持久的(persistent)、临时的 (ephemeral)、持久有序的(persistent_sequential)和临时有序的 (ephemeral_sequential)
1.3、监视与通知
客户端获取znode信息通常需要远程调用的方式获取,但是如果轮训查询就会查询到大量相同的内容或者为空的数据。所以为了减少无效的查询请求,ZooKeeper采用通知机制来替代客户端轮训。
客户端向ZK注册想要监听的znode,ZK会对这个znode设置监视点,那么当被监听的znode数据发生变化时,ZK会主动通知客户端。不过监视通知是一次性行为,也就是通知一次之后就不会再通知,
此时需要再次监视才会发送新的通知。监视点的类型包括节点数据变化、子节点变化、节点创建和删除变化等;
由于监视通知为单次行为,所以客户端每次接收更新通知后都需要设置下一次的监视点,这里就存在一个时间差,在接收到通知到设置新的监视点之间可能数据再一次发生变化,这样客户端在设置监视点后就无法获取
设置监视点之前的更新,所以为了防止数据丢失,客户端再每次设置监视点之前都会再一次读取最新的状态确保不会丢失更新的数据。
1.4、版本号
ZooKeeper的znode都有一个版本号,每次当znode数据变化版本号都会自增更新,当根据znode进行setData和getData操作时都必须携带版本号,只有当版本号一致时才会操作成功,否则就会操作失败。
这样就可以避免并发情况下的数据不一致问题。
1.5、运行模式
ZooKeeper服务器架构模式有独立模式(Standalone)和仲裁模式(Quorum),也就是单机模式和集群模式。
单机模式下比较简单,一台服务器负责维护所有客户端读写请求并存储节点数据。
集群模式下所有节点都复制整个集群的数据,当集群数据更新时,只有当超过半数节点更新成功时才算一次更新成功。
1.6、会话
客户端和ZK服务器之间的连接叫做会话,客户端和服务器之间的交互必须建立在会话之上,当会话应该主动关闭或网络异常断开时,ZK会删除此会话创建的临时节点。同一个会话中的请求是有序的,但是如果一个客户端
创建多个会话,那么请求顺序是不一定有序的。
客户端和服务器之间的会话可能有多种状态,分别为CONNECTING(连接中)、CONNECTED(已连接)、CLOSED(已关闭)、NOT_CONNECTED(未连接)
会话状态从NOT_CONNECTED开始,初始化连接时转为CONNECTING状态,连接ZK成功后变成CONNECTED状态,当和服务器断开时会转为CONNECTING状态并继续尝试连接其他ZK服务器,如果重新连接成功则
转为CONENCTED状态,否则变成CLOSED状态。
每个会话创建时都会有一个过期时间,如果经过时间t之后服务接收不到这个会话的任何消息,服务就会声明会话过期。而在客户端侧,如果经过t/3的时间未收到任何消息,客户端将向服务器发送心跳消息。
在经过2t/3时间后,ZooKeeper客户端开始寻找其他的服务器,而此时它还有t/3时间去寻找。
tips:
二、ZooKeeper实践
2.1、ZooKeeper服务启动
下载zookeeper安装包解压并进入bin目录,执行./zkServer.sh start 命令可以启动ZooKeeper,客户端执行./zkCli.sh -server ip:port 连接服务器。
客户端可执行命令如下:

1 ZooKeeper -server host:port cmd args 2 stat path [watch] 3 set path data [version] 4 ls path [watch] 5 delquota [-n|-b] path 6 ls2 path [watch] 7 setAcl path acl 8 setquota -n|-b val path 9 history 10 redo cmdno 11 printwatches on|off 12 delete path [version] 13 sync path 14 listquota path 15 rmr path 16 get path [watch] 17 create [-s] [-e] path data acl 18 addauth scheme auth 19 quit 20 getAcl path 21 close 22 connect host:port
2.2、Java集成ZooKeeper
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
</dependency>
测试代码如下:
1 public static void main(String[] args){
2 ZkClient zkClient = new ZkClient("localhost:2181");
3 /** 创建路径为first数据为空的临时节点*/
4 zkClient.create("/first", null, CreateMode.EPHEMERAL);
5 while (true){
6 }
7 }
public static void main(String[] args){
ZkClient zkClient = new ZkClient("localhost:2181");
/** 创建路径为first数据为空的临时节点*/
zkClient.create("/test", null, CreateMode.PERSISTENT);
zkClient.create("/test/first", null, CreateMode.EPHEMERAL);
zkClient.create("/test/second", null, CreateMode.EPHEMERAL);
zkClient.create("/test/third", null, CreateMode.EPHEMERAL);
List<String> subs = zkClient.getChildren("/test");
System.out.println(JSON.toJSONString(subs));
while (true){
}
}
上面案例是先创建path为/test的持久化节点,然后再依次创建/first, /second, /third三个子节点临时节点,然后通过getChildren方法获取/test目录的子节点,打印结果如下:
["third","first","second"]
这里需要注意,父节点只可以是持久化节点,不可以是临时节点,只有持久化节点才可以创建子节点,而临时节点只能是叶子子节点,不可以在临时节点下创建子节点。
public static void main(String[] args){
ZkClient zkClient = new ZkClient("localhost:2181");
/** 创建路径为first数据为空的临时节点*/
zkClient.create("/test/sub", null, CreateMode.EPHEMERAL_SEQUENTIAL);
zkClient.create("/test/sub", null, CreateMode.EPHEMERAL_SEQUENTIAL);
zkClient.create("/test/sub", null, CreateMode.EPHEMERAL_SEQUENTIAL);
List<String> subs = zkClient.getChildren("/test");
System.out.println(JSON.toJSONString(subs));
while (true){
}
}
上面案例是在/test目录下创建三个sub子节点,且子节点为有序节点,所以子节点名称会在sub后面增加序号,打印结果如下:
["sub0000000003","third","first","sub0000000004","second","sub0000000005"]
public static void main(String[] args) throws InterruptedException {
ZkClient zkClient = new ZkClient("localhost:2181");
zkClient.create("/test/sub", null, CreateMode.EPHEMERAL);
/** 订阅节点数据变化通知 */
zkClient.subscribeDataChanges("/test/sub", new IZkDataListener() {
@Override
public void handleDataChange(String dataPath, Object data) throws Exception {
//监听数据变化
System.out.println("变化结果为:" + JSON.toJSONString(data));
}
@Override
public void handleDataDeleted(String dataPath) throws Exception {
}
});
Thread.sleep(2000L);
new Thread(new Runnable() {
@Override
public void run() {
/** 节点数据写入 */
zkClient.writeData("/test/sub", "线程:" + Thread.currentThread().getName() + "写入");
}
}).start();
Thread.sleep(5000L);
new Thread(new Runnable() {
@Override
public void run() {
/** 节点数据写入 */
zkClient.writeData("/test/sub", "线程:" + Thread.currentThread().getName() + "写入");
}
}).start();
while (true){
}
}
上述案例通过主线程订阅/test/sub节点数据变化通知,通过IZkDataListener实现类来处理变化结果,然后开启两个线程分别调用writeData向/test/sub写入数据,发现可以通过监听器获取到变化的结果,打印结果如下:
变化结果为:"线程:Thread-1写入" 变化结果为:"线程:Thread-2写入"
三、ZooKeeper实战
3.1、ZooKeeper实现分布式锁
分布式锁需要满足以下功能
1、获取锁和释放锁
2、锁同一时间只可以由同一时间获取
3、锁被占用时不可抢占
4、当占有锁的客户端异常无法获取锁时,锁可以自动释放
基于分布式锁的特性,结合ZooKeeper的节点特性,可以发现基于ZooKeeper就可以实现分布式锁
1、通过创建znode和删除znode实现获取锁和释放锁,并且znode类型为临时节点
2、znode存在时不可用再次创建,保证同一时间只有一个线程获取锁,且不可被抢占
3、当客户端断开连接时,创建的临时节点会自动删除从而释放锁资源
基于ZooKeeper实现分布式锁方案如下
方案一:
创建节点进行加锁,删除节点释放锁,获取锁成功的客户端执行业务逻辑,获取锁失败的客户端添加监听器,监听锁的状态变化,当锁被删除之后再次尝试获取锁。
如锁的key为/test,同时有3个Client尝试获取锁,那么执行逻辑流程如下:
1、Client1 创建临时节点 /test 成功,获取锁成功;
2、Client2 和 Client 3 创建临时节点 /test 失败,获取锁失败;
3、Client2 和 Client 3 开启监听器,监听 /test节点的状态是否被删除;
4、Client1 执行业务逻辑,后删除节点 /test 释放锁;
5、Client2 和 Client 3同时监听到 /test锁释放,则再次同时尝试创建临时节点/test获取锁,此时只有一个Client获取锁成功,另一个失败再次进入监听等待状态;
此方案虽然可以满足分布式锁的效果,但是有一个小问题就是当锁被释放时,此时可能同时存在大量的等待锁的客户端,此时就会同时唤醒大量的客户端再次获取锁,也就是所谓的--惊鸿效应。
大量的客户端频繁的尝试获锁失败又频繁的进入监听状态,浪费系统资源。所以最好的效果是当锁释放时,只有1个客户端尝试获取锁,其他客户端还是处于监听状态,那么此时就需要将所有等待的客户端进行排序,
而ZooKeeper的临时有序节点刚好就可以实现这样的效果,所以就有了方案二。
方案二:
客户端根据key创建临时有序子节点,然后判断当前创建的子节点的序号是否是所有子节点中最小序号的一个,如果是最小序号的子节点那么就表示获取锁成功,如果不是最小序号的子节点那么就表示获取锁失败,
此时开启监听器监听上一个节点的删除事件,只有当上一个节点被删除了才会唤醒继续尝试获取锁,否则就一直处于等待状态。
所以正常情况下每次当获取锁的客户端释放锁删除子节点后,只会唤醒下一个节点,而其他节点仍然处于监听状态,不会被唤醒。这样就保证了同时只有一个客户端获取锁且每次只会唤醒一个客户端。
如锁的key为 /test,同时有3个Client尝试获取锁,那么执行逻辑流程如下:
1、Client1、Client2、Client3分别创建临时节点 /test/0000000001、/test/0000000002、/test/0000000003;
2、Client1判断当前子节点0000000001是最小的子节点,则获取锁成功;
3、Client2 和 Client 3 判断当前子节点不是最小子节点,那么开启监听器,分别监听 /test/0000000001和/test/0000000002的删除事件;
4、Client1执行业务逻辑完成并删除 /test/0000000001 子节点;
5、Client2 监听到上一个子节点被删除,此时再次判断当前子节点是否为最小节点,如果是则表示获取锁成功;
6、Client2执行业务逻辑完成并删除 /tests/0000000002 子节点;
7、Client3 监听到上一个子节点删除,此时再次判断当前子节点是否为最小节点,如果是则表示获取锁成功;
总结
基于ZooKeeper实现分布式锁,主要是使用了ZooKeeper的临时有序子节点的特性来实现。临时节点保证锁会随着客户端断开而释放,有序子节点保证获取锁的有序性,ZooKeeper创建节点保证线程安全。
另外ZooKeeper的监听通知机制可以实现等待锁的客户端及时感知锁的释放事件从而可以及时尝试获取锁。
3.2、ZooKeeper实现注册中心
注册中心的核心功能包括服务发布、服务订阅、健康检测以及服务更新推送等功能。
那么基于ZooKeeper实现注册中心的整体工作流程如下:
1、服务提供者和服务消费者启动将本身信息注册到ZooKeeper;
2、服务提供者发布服务到ZooKeeper
3、消费者从ZooKeeper订阅服务,并监听服务更新事件
4、ZooKeeper感知服务变化,及时推送服务更新事件给消费者
5、ZooKeeper通过检测客户端连接状态来健康检测
如dubbo分布式框架,那么服务发布和服务订阅之后,ZooKeeper存储结果如下:

根目录下有一个dubbo目录,dubbo目录下有元数据metadata目录和配置config目录两个持久节点分别存储服务元数据和配置,然后针对所有服务分别创建持久子目录,目录名称为服务全路径如com.lucky.test.UserService
服务目录下包含4个持久化子节点,核心是consumers和providers两个子节点,这两个子节点下面就是服务消费者和服务提供者对应的临时节点,分别存储服务订阅者列表和服务消费者列表。
工作流程如下:
1、服务提供者发布服务时在/dubbo/service1/providers节点记录服务请求地址;
2、服务订阅者订阅服务时在/dubbo/service1/consumers节点记录消费者信息;
3、服务订阅者获取/dubbo/service1/providers节点数据得到所有服务提供者对应的请求地址信息;
4、服务订阅者监听/dubbo/service1/providers节点的子节点变化通知,当providers子节点信息变化时,zookeeper会发生子节点变化通知给对应的服务消费者;
5、服务订阅者接收服务提供者变化通知刷新本地缓存;