微信公众号的一篇文章,着重介绍如何使用知识图谱来增强大语言模型QA的问答效果
1. 核心架构
核心架构如下:
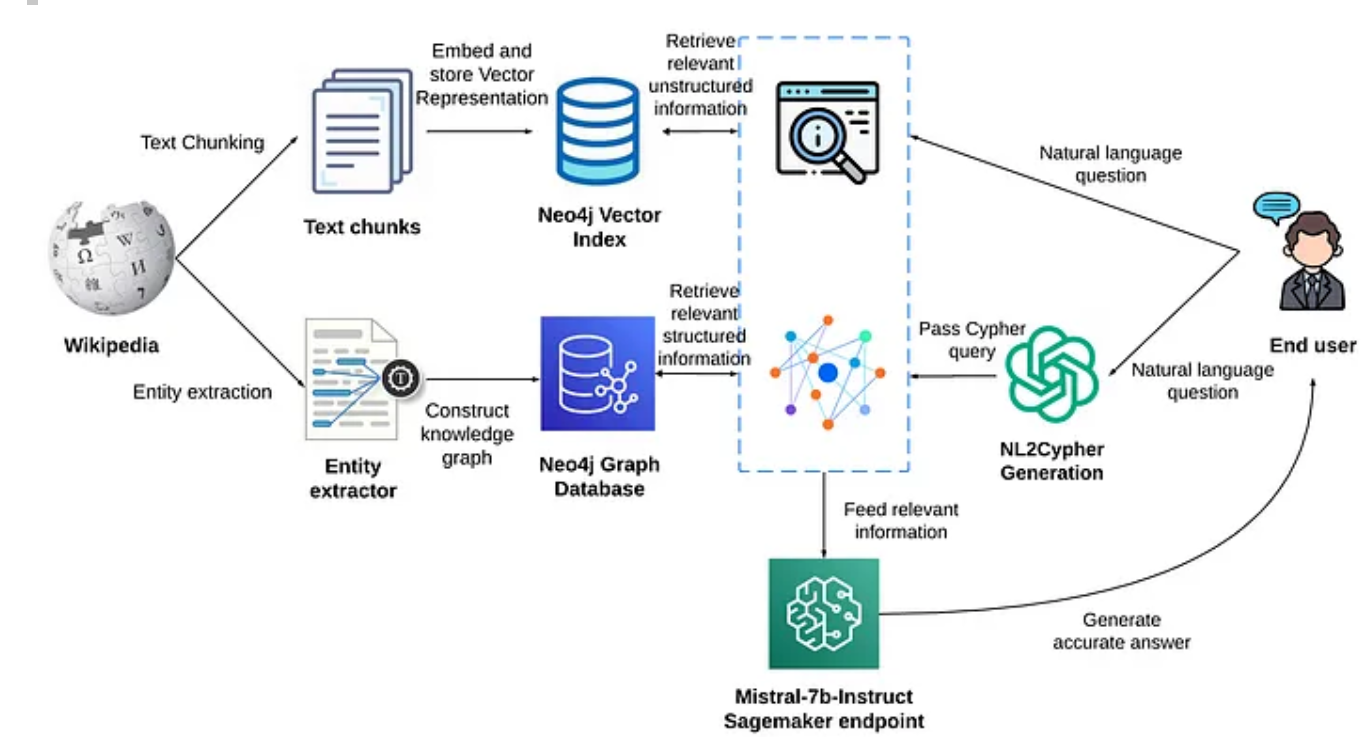
可以通过Neo4j的向量索引和Neoconj图数据的强大能力来实现检索增强的生成系统,提供精确且上下文丰富的答案。
两条路:
向量相似性搜索来检索非结构化信息,
访问图数据库来提取结构化信息,
最后,系统将检索到的结构化和非结构化的信息传递给大语言模型Mistral-b,
用于文本生成
2. 所用组件
GraphCypherQAChain
该类作用为借助LLM从用户输入的问题生成Cypher查询(和MySQL类似的查询语言),然后执行这些查询在Neo4j图形数据库中,并根据查询结果提供答案
Mistral-7B
一种最新的大语言模型,在各项测试中表现卓越。
3. 具体实现
从安装依赖项开始
pip install langchain openai wikipedia tiktoken neo4j python-dotenv transformers
pip install -U sagemaker
向量索引
先导入必要的库和包,为数据集准备、Neo4j向量索引接口、Mistral 7B的文本生成功能奠定基础。
采用dotenv方式,安全加载环境变量,保护OpenAI和Neo4j的敏感信息。
import os
import re
from langchain.vectorstores.neo4j_vector import Neo4jVector
from langchain.document_loaders import WikipediaLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
from dotenv import load_dotenv
load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv('OPENAI_API_KEY')
os.environ["NEO4J_URI"] = os.getenv('NEO4J_URI')
os.environ["NEO4J_USERNAME"] = os.getenv('NEO4J_USERNAME')
os.environ["NEO4J_PASSWORD"] = os.getenv('NEO4J_PASSWORD')
接下来,
使用Leonhard Euler维基百科页面进行实验,
使用bert-base-uncased模型标记文本(对文本进行分词,文本->token,所有token均转化为小写形式),
WikipediaLoader加载指定页面的原始内容,
Langchain中RecursiveCharacterTextSplitter将文本划分为若干更小的文本片段,
(文本->chunk)
划分为每个块中最多200个标记,重叠20个标记
tokenizer = AutoTokenizer.from_pertrained("bert-base-uncased")
def bert_len(text):
tokens = tokenizer.encode(text)
return len(tokens)
raw_documents = WikipediaLoader(query="Leonhard Euler").load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 200,
chunk_overlap = 20,
length_function = bert_len,
separators = ['\n\n','\n',' ',''],
)
documents = text_splitter.create_document([raw_document[0].page_content])
分块后的文档作为节点实例化到Neo4j的向量索引中。
使用Neo4j图数据库和OpenAI嵌入的核心功能构建向量索引。
neo4j_vector = Neo4jVector.from_documents (
documents,
OpenAIEmbeddings(),
url = os.environ["NEO4J_URL"],
username = os.environ["NEO4J_USERNAME"],
password = os.environ["NEO4J_PASSWORD"]
)
在提取向量索引中的文档,对示例用户查询执行向量相似度检索,
检索前2个最相似的文档。
query = "Who were the siblings of Leonhard Euler?"
vector_results = neo4j_vector.similarity_search(query,k=2)
for i, res in enumerate(vector_results):
print(res.page_content)
if i != len(vector_results) - 1:
print()
vector_result = vector_results[0].page_content
检索结果如下:

简要概括一下:
对文本进行分词并分块后,对每一个chunk做embedding存储到图数据库中,
检索时查找与query向量最接近的向量代表的文本作为回复。
构建知识图谱
采用NaLLM开源项目从非结构化数据构建知识图,
如下所示,采用Leonhard Euler维基百科构建的单个文档块的知识图:
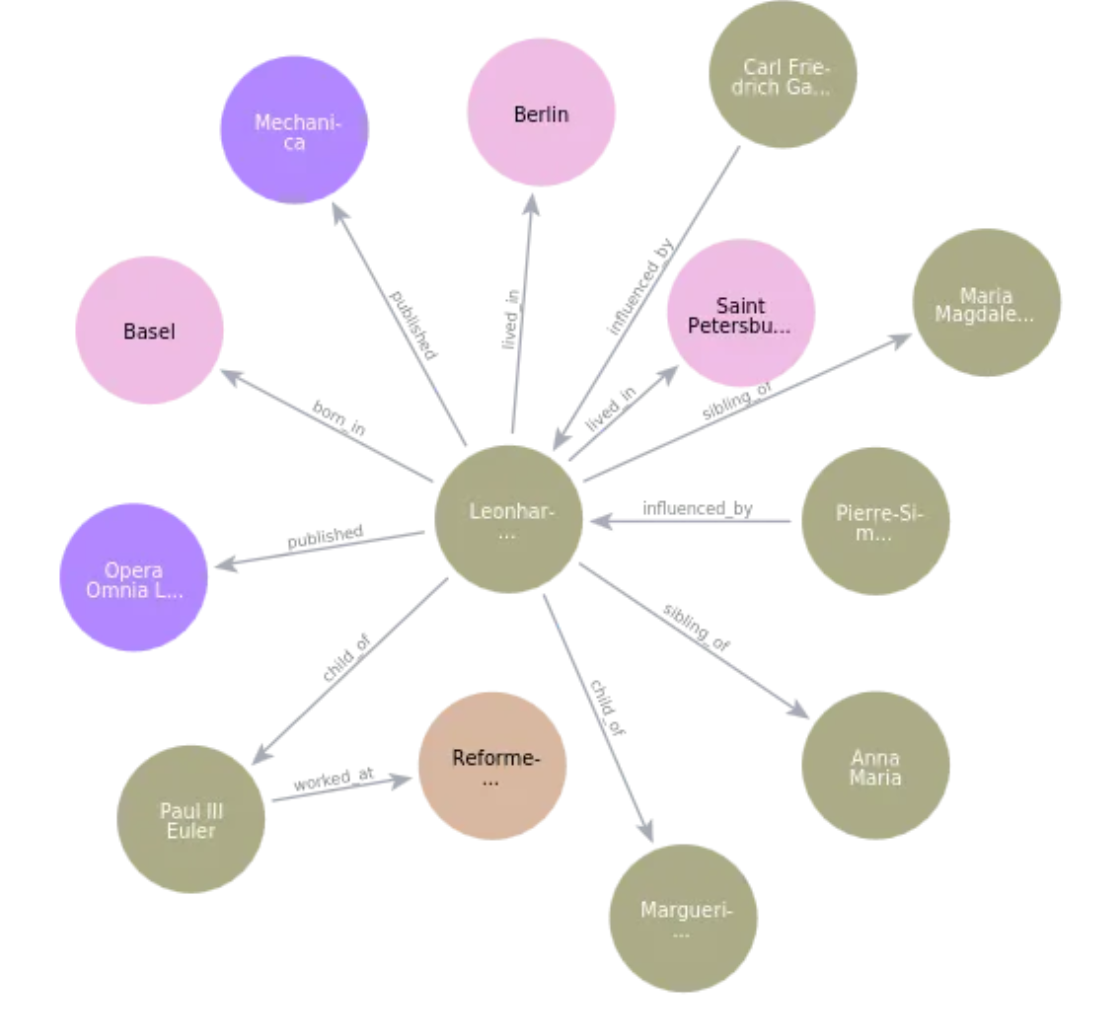
采用的prompt,
You are a data scientist working for a company that is building a graph database.
Your task is to extract information from data and convert it into a graph database.
Provide a set of Nodes in the form [ENTITY_ID,TYPE,PROPERTIES] and a set of relationships in the form [ENTITY_ID,RELATIONSHIP,ENTITY_ID_2,PROPERTIES].
It is important that the ENTITY_ID_1 and ENTITY_ID_2 exists as nodes with a matching ENTITY_ID.
If you can't pair a relationship with a pair of nodes don't add it
When you find a node or relationship you want to add try to create a generic TYPE for it that describes the entity you can also think of it as a label.
Example
Data:
Aice lawyer and is 25 years old and Bob is her roommate since 2021.
Bob works as a journalist.
Alice owns a the webpage www.alice.com and Bob owns the webpage www.bob.com.
Nodes:
["alice", "Person", {"age": 25, "occupation": "lawyer", "name":"Alice"}],
["bob", "Person", {"occupation": "journalist", "name": "Bob"}],
["alice.com", "Webpage", {"url": "www.alice.com"}],
["bob.com", "Webpage", {"url": "www.bob.com"}]
Relationships:
["alice", "roommate", "bob", {"start": 2021}],
["alice", "owns", "alice.com", {}],
["bob", "owns", "bob.com", {}]
"""
Neo4j DB QA链
接下来,导入必要的库来实现Neo4j DB的QA链,如下
from langchain.chat_models import ChatOpenAI
from langchain.chains import GraphCypherQAChain
from langchain.graphs import Neo4jGraph
构建图表,需要连接到Neo4jGraph实例并可视化模式,
graph = Neo4jGraph(url = os.environ["NEO4J_URL"],
username = os.environ["NEO4J_USERNAME"],
password = os.environ["NEO4J_PASSWORD"]
)
print(graph)
输出模式结果如下:
Node properties are the following:
[{'labels': 'Person', 'properties': [{'property': 'name', 'type': 'STRING'},
{'property': 'nationality', 'type': 'STRING'},
{'property': 'death_date', 'type': 'STRING'},
{'property': 'birth_date', 'type': 'STRING'}]},
{'labels': 'Location', 'properties': [{'property': 'name', 'type': 'STRING'}]},
{'labels': 'Organization', 'properties': [{'property': 'name', 'type': 'STRING'}]},
{'labels': 'Publication', 'properties': [{'property': 'name', 'type': 'STRING'}]}]
Relationship properties are the following:
[]
The relationships are the following:
['(:Person)-[:worked_at]->(:Organization)',
'(:Person)-[:influenced_by]->(:Person)',
'(:Person)-[:born_in]->(:Location)',
'(:Person)-[:lived_in]->(:Location)',
'(:Person)-[:child_of]->(:Person)',
'(:Person)-[:sibling_of]->(:Person)',
'(:Person)-[:published]->(:Publication)']
抽象GraphCypherQAChain所有细节并输出自然语言问题(NLQ)的自然语言响应。
内部过程:
使用LLM生成自然语言问题的Cypher查询,
并从图数据库中检索结果,
最后使用结果生成最终的自然语言响应(借助LLM实现)
抽象过程如下:
chain = GraphCypherQAChain.from_llm(
ChatOpenAI(temperature = 0), graph = graph, verbose = True
)
graph_result = chain.run("Who were the sibling of Leonhard Euler?")
生成Cypher查询和答案如下所示:

当输出graph_result时,答案是:
'The siblings of Leonhard Euler were Maria Magdalena and Anna Maria.'
本实验借助Mistral-7b模型实现最终答案。
主要通过构造指令、向量检索的相关数据,图数据库中相关信息和用户查询。
(相当于通过将向量检索和图谱查询的结果结合起来送给大模型
mistral7b_predictor = huggingface_model.deploy (
initial_instrance_count = 1,
instance_type = "ml.g5.4xlarge",
)
mistral7b_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.g5.4xlarge",
container_startup_health_check_timeout=300,
)
query = "Who were the siblings of Leonhard Euler?"
final_prompt = f""
"You are a helpful question-answering agent. Your task is to analyze
and synthesize information from two sources:
the top result from a similarity search
(unstructured information) and
relevant data from a graph database (structured information).
Given the user's query: {query},
provide a meaningful and efficient answer based on the insights derived from the following data:
Unstructured information: {vector_result}.
Structured information: {graph_result}.
"""
response = mistral7b_predictor.predict({
"inputs": final_prompt,
})
print(re.search(r"Answer: (.+)", response[0]['generated_text']).group(1))
生成回复
The siblings of Leonhard Euler were Maria Magdalena and Anna Maria.
注意,re.search找到所有符合正则表达式模式的字串位置,group表示返回子串
group(1)表示返回第一个子串
总结:
上面过程主要展示了向量查询与图数据库查询结合综合起来来丰富大模型的prompt,提供更多的上下文内容,从而辅助大模型的回答。
未来尝试多条查询