来自:
https://blog.popkx.com/linux-multithreaded-programming-in-io-read-write-security-functions-pread-pwrite-and-read-write-what-is-the-difference-and-relat/
与 Windows 不同, Linux 允许一个文件在写入的时候被读取(或者在被读取的时候写入),本文就来探索一下多个进程同时读写同一个文件会产生的效果。
Read + Read
多个进程同时读取同一个文件不会出现问题的,放心去干吧。
Read + Write
本文的重点研究对象。Linux 通过文件描述符表维护了打开的文件描述符信息,而文件描述符表中的每一项都指向一个内核维护的文件表,文件表指向打开的文件的 vnode(Unix) 和 inode。同时,文件表保存了进程对文件读写的偏移量等信息。
我们通过两个简单的 Go 语言程序来测试一下在读文件的同时修改文件会发生什么:
testwrite.go
func writeFile(filename string, data string) {
f, _ := os.OpenFile(filename, os.O_CREATE|os.O_WRONLY, 0644)
defer f.Close()
body := []byte(data)
_, _ = f.Write(body)
}
func main() {
// 首先向文件中写入 “Hello World!”
writeFile("test.txt", "Hello World!")
time.Sleep(7 * time.Second)
// 七秒后,修改文件内容,写入 “Author MeiK!”
writeFile("test.txt", "Author MeiK!")
}testread.go
func readFile(filename string) {
f, _ := os.OpenFile(filename, unix.O_RDONLY, 0644)
defer f.Close()
body := make([]byte, 1)
n := 1
for n != 0 {
time.Sleep(time.Second)
var err error
n, err = f.Read(body)
if err == io.EOF {
break
}
s, _ := f.Seek(0, os.SEEK_CUR)
fmt.Printf("%c %d\n", body, s)
}
}
func main() {
readFile("test.txt")
}同时执行两个程序:
./testwrite & ./testread输出:
[H] 1
[e] 2
[l] 3
[l] 4
[o] 5
[ ] 6
[ ] 7
[M] 8
[e] 9
[i] 10
[K] 11
[!] 12
这个程序打印了读取到的内容以及读取到每一步的文件偏移量。我们首先写入 Hello World!,开始每秒读取一个字符,并且在 7 秒后重新将 Author MeiK! 写入文件。我们最终读取到了什么呢?既不是 Hello World!,也不是 Author MeiK!,而是 Hello MeiK!。我们每个字符串读取到了一半!
从每一步的文件偏移量来看,读取的程序只是按部就班的一个字符一个字符的读取文件,对文件内容的变化毫无感知,当读取到文件结尾的 EOF 时结束读取。
那么我们要如何保证读取与写入的一致性呢? Linux 提供了 fcntl 系统调用,可以锁定文件。
我们对刚刚的文件稍作修改,使用 fcntl 进行加锁:
testwrite.go
func writeFile(filename string, data string) {
fmt.Println("write start")
f, _ := os.OpenFile(filename, os.O_CREATE|os.O_WRONLY, 0644)
defer f.Close()
flockT := unix.Flock_t{
Type: unix.F_WRLCK,
Whence: io.SeekStart,
Start: 0,
Len: 0,
}
_ = unix.FcntlFlock(f.Fd(), unix.F_SETLKW, &flockT)
body := []byte(data)
_, _ = f.Write(body)
fmt.Println("write end")
}
func main() {
// 首先向文件中写入 “Hello World!”
writeFile("test.txt", "Hello World!")
time.Sleep(7 * time.Second)
// 七秒后,修改文件内容,写入 “Author MeiK!”
writeFile("test.txt", "Author MeiK!")
}testread.go
func readFile(filename string) {
f, _ := os.OpenFile(filename, unix.O_RDONLY, 0644)
defer f.Close()
flockT := unix.Flock_t{
Type: unix.F_RDLCK,
Whence: io.SeekStart,
Start: 0,
Len: 0,
}
_ = unix.FcntlFlock(f.Fd(), unix.F_SETLKW, &flockT)
body := make([]byte, 1)
n := 1
for n != 0 {
time.Sleep(time.Second)
var err error
n, err = f.Read(body)
if err == io.EOF {
break
}
s, _ := f.Seek(0, os.SEEK_CUR)
fmt.Printf("%c %d\n", body, s)
}
}
func main() {
readFile("test.txt")
}额外添加 write start 和 write end 来标识当前进度,执行结果如下:
write start
write end
[H] 1
[e] 2
[l] 3
[l] 4
[o] 5
[ ] 6
write start
[W] 7
[o] 8
[r] 9
[l] 10
[d] 11
[!] 12
write end
可以看到,第一次写入文件时,进程很快的完成了写入;而当第二次写入时,由于此时 read 进程对文件加锁了,导致写入进程阻塞,直到读取结束后, write 进程才把内容写入了文件。因此 read 进程读取到的就是第一次写入的内容 Hello World!。完美的解决了我们的问题,可喜可贺。
不过,还有两点需要注意:
- 文件锁是与进程相关的,一个进程中的多个线程/协程对同一个文件进行的锁操作会互相覆盖掉,从而无效。
fcntl创建的锁是建议性锁,只有写入的进程和读取的进程都遵循建议才有效;对应的有强制性锁,会在每次文件操作时进行判断,但性能较差,因此 Linux/Unix 系统默认采用的是建议性锁。
1、flock,lockf,fcntl之间区别
先上结论:flock是文件锁,锁的粒度是整个文件,就是说如果一个进程对一个文件加了LOCK_EX类型的锁,别的进程是不能对这个文件加锁的。
lockf是对fcntl的封装,这两个东西在内核上的实现是一样的。它们的粒度是字节,不同的进程可以对相同的文件不同字节加LOCK_EX类型的锁。
2、linux文件系统
在详解锁的实现机制前,我们先来看一下linux文件系统的实现。
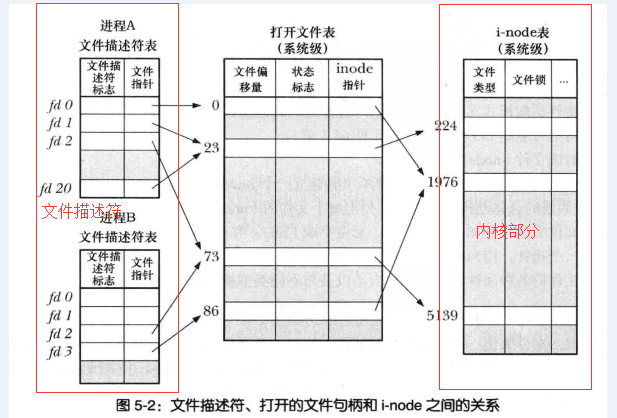
相信大家都看过这样一副图。与进程相关的是文件描述符表,文件表和i-node都是系统级别的。当我们在进程中打开一个文件时,文件描述符里就会产生一个文件描述符表项与之对应,同样的系统内也会有文件句柄和相应的i-node,我们需要注意的是多个文件表项(同一个进程或不同进程)可以指向同一个文件句柄。
2、 flock锁的实现机制
flock在实现上关联到的是文件描述符(上图中文件描述符部分),这就意味着如果我们在进程中复制了一个文件描述符,那么使用flock对这个描述符加的锁也会在新复制出的描述符中继续引用。我们可以写如下代码测试:

#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/file.h>
#include <wait.h>
#define PATH "/tmp/lock"
int main()
{
int fd;
pid_t pid;
fd = open(PATH, O_RDWR | O_CREAT | O_TRUNC, 0644);
flock(fd, LOCK_EX);
printf("%d: locked!\n", getpid());
pid = fork();
if (pid == 0) {
// fd = open(PATH, O_RDWR|O_CREAT|O_TRUNC, 0644);
flock(fd, LOCK_EX);
printf("%d: locked!\n", getpid());
exit(0);
}
wait(NULL);
unlink(PATH);
exit(0);
}
输出结果:
Sangfor:aCMP/acmp-fefcfe3a1674 ~/test o ./a.out
118333: locked!
118334: locked!
由结果可见,父进程已经持有互斥锁的情况下,子进程应该对文件加锁失败才符合我们的预期。但是子进程确加锁成功。原因就在于flock的实现是关联文件描述符。
子进程由父进程创建,子进程的文件描述符表和父进程的一模一样,在fork()子进程后,子进程本身就持有该文件的互斥锁。同样的道理,对文件描述符dup(), dup2()都会有这样的问题。怎么解决这个问题呢?
1、重新open这个文件,使用新的文件描述符
fd = open(PATH, O_RDWR|O_CREAT|O_TRUNC, 0644);
我们将上述注释掉的代码打开,重新编译执行,输出结果如下:
Sangfor:aCMP/acmp-fefcfe3a1674 ~/test o ./a.out
172199: locked!
这次子进程没有能上锁,重新open这个文件会创建一个新的文件描述符与父进程进程而来的描述符是不相关的,所以就符合我们预期的效果。
另外要注意:除非文件描述符被标记了close-on-exec标记,flock锁和lockf锁都可以穿越exec,在当前进程变成另一个执行镜像之后仍然保留。
3、lockf的实现机制
lockf的实现是关联到内核i-node的(上图内核部分),每次加锁都会在i-node节点上挂一个flock的结构:
struct flock
{
short l_type;/*F_RDLCK, F_WRLCK, or F_UNLCK*/
off_t l_start;/*相对于l_whence的偏移值,字节为单位*/
short l_whence;/*从哪里开始:SEEK_SET, SEEK_CUR, or SEEK_END*/
off_t l_len;/*长度, 字节为单位; 0 意味着缩到文件结尾*/
pid_t l_pid;/*returned with F_GETLK*/
};
对LOCK_EX类型的锁来说,内核中最多只有一份这样的数据,所以即使文件描述符是从父进程进程过来或dup()产生的,对同一个节点加锁都会失败。我们写如下代码测试一下:
#include <stdlib.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/file.h>
#include <wait.h>
#define PATH "/tmp/lock"
int main()
{
int fd;
pid_t pid;
fd = open(PATH, O_RDWR | O_CREAT | O_TRUNC, 0644);
lockf(fd, F_LOCK, 0);
printf("%d: locked!\n", getpid());
pid = fork();
if (pid == 0) {
lockf(fd, F_LOCK, 0);
printf("%d: locked!\n", getpid());
exit(0);
}
wait(NULL);
unlink(PATH);
exit(0);
}
执行结果:
Sangfor:aCMP/acmp-fefcfe3a1674 ~/test o ./a1.out
47087: locked!
这次我们没有对文件重新open,子进程就一直等在那里。完全符合我们的预期。这也印证了lockf的实现是内核中i-node相关的。
此外有一篇文章介绍建议性锁和强制性锁,这篇文章是以flock为例说明的,flock和lockf的加锁规则是一致的。需要了解加锁规则请参看:
强制性锁和建议锁
参考: