RAG是一种检索增强生成模型,由信息检索系统和seq2seq生成器组成。它的内部知识可以轻松地随时更改或补充,而无需浪费时间或算力重新训练整个模型。
举个例子,假设你正在写一篇关于猫的文章,但你不确定如何描述猫的行为。你可以使用RAG来检索与猫行为相关的文档,然后将这些文档作为上下文与原始输入拼接起来,再输入到seq2seq模型中。这样,RAG就可以生成关于猫行为的描述了.
RAG 将检索模型与生成模型相结合,检索模型充当 “图书馆员”,扫描大型数据库以获取相关信息,生成模型充当 “作家”,将这些信息合成为与任务更相关的文本。 它用途广泛,适用于实时新闻摘要、自动化客户服务和复杂研究任务等多种领域。
RAG 需要检索模型,例如跨嵌入的向量搜索,与通常基于 LLMs 构建的生成模型相结合,该模型能够将检索到的信息合成为有用的响应。
检索增强生成 (RAG)
通用语言模型通过微调就可以完成几类常见任务,比如分析情绪和识别命名实体。这些任务不需要额外的背景知识就可以完成。
要完成更复杂和知识密集型的任务,可以基于语言模型构建一个系统,访问外部知识源来做到。这样的实现与事实更加一性,生成的答案更可靠,还有助于缓解“幻觉”问题。
Meta AI 的研究人员引入了一种叫做检索增强生成(Retrieval Augmented Generation,RAG)(opens in a new tab)的方法来完成这类知识密集型的任务。RAG 把一个信息检索组件和文本生成模型结合在一起。RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。
Lewis 等人(2021)提出一个通用的 RAG 微调方法。这种方法使用预训练的 seq2seq 作为参数记忆,用维基百科的密集向量索引作为非参数记忆(使通过神经网络预训练的检索器访问)。这种方法工作原理概况如下:
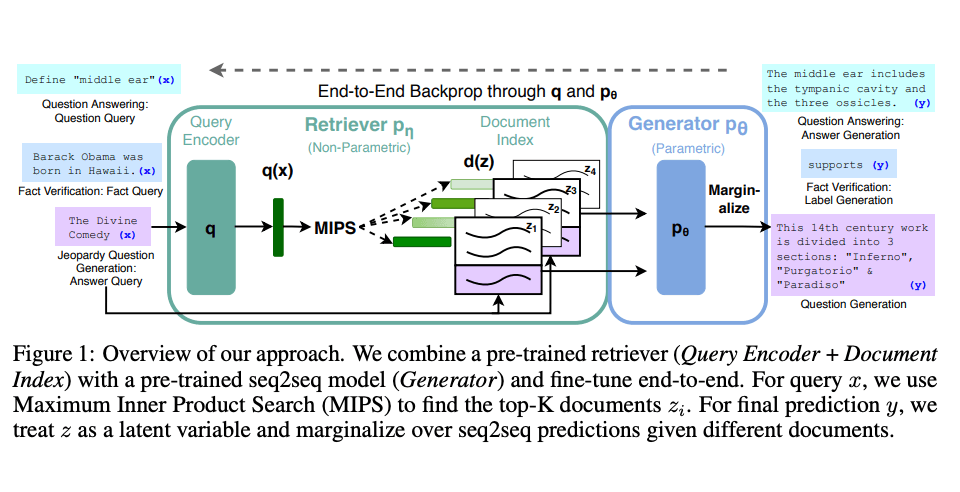
图片援引自: Lewis et el. (2021)(opens in a new tab)
RAG 在 Natural Questions(opens in a new tab)、WebQuestions(opens in a new tab) 和 CuratedTrec 等基准测试中表现抢眼。用 MS-MARCO 和 Jeopardy 问题进行测试时,RAG 生成的答案更符合事实、更具体、更多样。FEVER 事实验证使用 RAG 后也得到了更好的结果。
这说明 RAG 是一种可行的方案,能在知识密集型任务中增强语言模型的输出。
最近,基于检索器的方法越来越流行,经常与 ChatGPT 等流行 LLM 结合使用来提高其能力和事实一致性。
LangChain 文档中可以找到一个使用检索器和 LLM 回答问题并给出知识来源的简单例子(opens in a new tab)。
如下:
Using a Retriever
This example showcases question answering over an index.
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
loader = TextLoader("../../state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_documents(texts, embeddings)
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever())
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
" The president said that she is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He also said that she is a consensus builder and has received a broad range of support, from the Fraternal Order of Police to former judges appointed by Democrats and Republicans."
Chain Type
You can easily specify different chain types to load and use in the RetrievalQA chain. For a more detailed walkthrough of these types, please see this notebook.
There are two ways to load different chain types. First, you can specify the chain type argument in the from_chain_type method. This allows you to pass in the name of the chain type you want to use. For example, in the below we change the chain type to map_reduce.
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="map_reduce", retriever=docsearch.as_retriever())
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
" The president said that Judge Ketanji Brown Jackson is one of our nation's top legal minds, a former top litigator in private practice and a former federal public defender, from a family of public school educators and police officers, a consensus builder and has received a broad range of support from the Fraternal Order of Police to former judges appointed by Democrats and Republicans."
The above way allows you to really simply change the chain_type, but it doesn't provide a ton of flexibility over parameters to that chain type. If you want to control those parameters, you can load the chain directly (as you did in this notebook) and then pass that directly to the RetrievalQA chain with the combine_documents_chain parameter. For example:
from langchain.chains.question_answering import load_qa_chain
qa_chain = load_qa_chain(OpenAI(temperature=0), chain_type="stuff")
qa = RetrievalQA(combine_documents_chain=qa_chain, retriever=docsearch.as_retriever())
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
" The president said that Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice, a former federal public defender, and from a family of public school educators and police officers. He also said that she is a consensus builder and has received a broad range of support from the Fraternal Order of Police to former judges appointed by Democrats and Republicans."
Custom Prompts
You can pass in custom prompts to do question answering. These prompts are the same prompts as you can pass into the base question answering chain
from langchain.prompts import PromptTemplate
prompt_template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer in Italian:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever(), chain_type_kwargs=chain_type_kwargs)
query = "What did the president say about Ketanji Brown Jackson"
qa.run(query)
" Il presidente ha detto che Ketanji Brown Jackson è una delle menti legali più importanti del paese, che continuerà l'eccellenza di Justice Breyer e che ha ricevuto un ampio sostegno, da Fraternal Order of Police a ex giudici nominati da democratici e repubblicani."
Vectorstore Retriever Options
You can adjust how documents are retrieved from your vectorstore depending on the specific task.
There are two main ways to retrieve documents relevant to a query- Similarity Search and Max Marginal Relevance Search (MMR Search). Similarity Search is the default, but you can use MMR by adding the search_type parameter:
docsearch.as_retriever(search_type="mmr")
You can also modify the search by passing specific search arguments through the retriever to the search function, using the search_kwargs keyword argument.
kdefines how many documents are returned; defaults to 4.score_thresholdallows you to set a minimum relevance for documents returned by the retriever, if you are using the "similarity_score_threshold" search type.fetch_kdetermines the amount of documents to pass to the MMR algorithm; defaults to 20.lambda_multcontrols the diversity of results returned by the MMR algorithm, with 1 being minimum diversity and 0 being maximum. Defaults to 0.5.filterallows you to define a filter on what documents should be retrieved, based on the documents' metadata. This has no effect if the Vectorstore doesn't store any metadata.
Some examples for how these parameters can be used:
# Retrieve more documents with higher diversity- useful if your dataset has many similar documents
docsearch.as_retriever(search_type="mmr", search_kwargs={'k': 6, 'lambda_mult': 0.25})
# Fetch more documents for the MMR algorithm to consider, but only return the top 5
docsearch.as_retriever(search_type="mmr", search_kwargs={'k': 5, 'fetch_k': 50})
# Only retrieve documents that have a relevance score above a certain threshold
docsearch.as_retriever(search_type="similarity_score_threshold", search_kwargs={'score_threshold': 0.8})
# Only get the single most similar document from the dataset
docsearch.as_retriever(search_kwargs={'k': 1})
# Use a filter to only retrieve documents from a specific paper
docsearch.as_retriever(search_kwargs={'filter': {'paper_title':'GPT-4 Technical Report'}})
Return Source Documents
Additionally, we can return the source documents used to answer the question by specifying an optional parameter when constructing the chain.
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 30}), return_source_documents=True)
query = "What did the president say about Ketanji Brown Jackson"
result = qa({"query": query})
result["result"]
" The president said that Ketanji Brown Jackson is one of the nation's top legal minds, a former top litigator in private practice and a former federal public defender from a family of public school educators and police officers, and that she has received a broad range of support from the Fraternal Order of Police to former judges appointed by Democrats and Republicans."
result["source_documents"]
[Document(page_content='Tonight. I call on the Senate to: Pass the Freedom to Vote Act. Pass the John Lewis Voting Rights Act. And while you’re at it, pass the Disclose Act so Americans can know who is funding our elections. \n\nTonight, I’d like to honor someone who has dedicated his life to serve this country: Justice Stephen Breyer—an Army veteran, Constitutional scholar, and retiring Justice of the United States Supreme Court. Justice Breyer, thank you for your service. \n\nOne of the most serious constitutional responsibilities a President has is nominating someone to serve on the United States Supreme Court. \n\nAnd I did that 4 days ago, when I nominated Circuit Court of Appeals Judge Ketanji Brown Jackson. One of our nation’s top legal minds, who will continue Justice Breyer’s legacy of excellence.', lookup_str='', metadata={'source': '../../state_of_the_union.txt'}, lookup_index=0),
Document(page_content='A former top litigator in private practice. A former federal public defender. And from a family of public school educators and police officers. A consensus builder. Since she’s been nominated, she’s received a broad range of support—from the Fraternal Order of Police to former judges appointed by Democrats and Republicans. \n\nAnd if we are to advance liberty and justice, we need to secure the Border and fix the immigration system. \n\nWe can do both. At our border, we’ve installed new technology like cutting-edge scanners to better detect drug smuggling. \n\nWe’ve set up joint patrols with Mexico and Guatemala to catch more human traffickers. \n\nWe’re putting in place dedicated immigration judges so families fleeing persecution and violence can have their cases heard faster. \n\nWe’re securing commitments and supporting partners in South and Central America to host more refugees and secure their own borders.', lookup_str='', metadata={'source': '../../state_of_the_union.txt'}, lookup_index=0),
Document(page_content='And for our LGBTQ+ Americans, let’s finally get the bipartisan Equality Act to my desk. The onslaught of state laws targeting transgender Americans and their families is wrong. \n\nAs I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential. \n\nWhile it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year. From preventing government shutdowns to protecting Asian-Americans from still-too-common hate crimes to reforming military justice. \n\nAnd soon, we’ll strengthen the Violence Against Women Act that I first wrote three decades ago. It is important for us to show the nation that we can come together and do big things. \n\nSo tonight I’m offering a Unity Agenda for the Nation. Four big things we can do together. \n\nFirst, beat the opioid epidemic.', lookup_str='', metadata={'source': '../../state_of_the_union.txt'}, lookup_index=0),
Document(page_content='Tonight, I’m announcing a crackdown on these companies overcharging American businesses and consumers. \n\nAnd as Wall Street firms take over more nursing homes, quality in those homes has gone down and costs have gone up. \n\nThat ends on my watch. \n\nMedicare is going to set higher standards for nursing homes and make sure your loved ones get the care they deserve and expect. \n\nWe’ll also cut costs and keep the economy going strong by giving workers a fair shot, provide more training and apprenticeships, hire them based on their skills not degrees. \n\nLet’s pass the Paycheck Fairness Act and paid leave. \n\nRaise the minimum wage to $15 an hour and extend the Child Tax Credit, so no one has to raise a family in poverty. \n\nLet’s increase Pell Grants and increase our historic support of HBCUs, and invest in what Jill—our First Lady who teaches full-time—calls America’s best-kept secret: community colleges.', lookup_str='', metadata={'source': '../../state_of_the_union.txt'}, lookup_index=0)]
Alternatively, if our document have a "source" metadata key, we can use the RetrievalQAWithSourcesChain to cite our sources:
docsearch = Chroma.from_texts(texts, embeddings, metadatas=[{"source": f"{i}-pl"} for i in range(len(texts))])
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
chain = RetrievalQAWithSourcesChain.from_chain_type(OpenAI(temperature=0), chain_type="stuff", retriever=docsearch.as_retriever())
chain({"question": "What did the president say about Justice Breyer"}, return_only_outputs=True)
{'answer': ' The president honored Justice Breyer for his service and mentioned his legacy of excellence.\n',
'sources': '31-pl'}
RAG 的关键组件
了解 RAG 的内部工作原理需要深入研究它的两个基本元素:检索模型和生成模型。 这两个组件是 RAG 卓越的获取、合成和生成信息丰富文本能力的基石。 让我们来分析一下每个模型带来的好处以及它们在 RAG 框架中带来的协同作用。
检索模型
检索模型充当 RAG 架构中的信息看门人。 它们的主要功能是搜索大量数据以查找可用于文本生成的相关信息。 将他们视为专业的图书馆员,当你提出问题时,他们确切地知道要从 “书架”上取下哪些 “书”。 这些模型使用算法来排序和选择最相关的数据,提供了一种将外部知识引入文本生成过程的方法。 通过这样做,检索模型为更明智、上下文丰富的语言生成奠定了基础,从而提升了传统语言模型的能力。
检索模型可以通过多种机制来实现。 最常见的技术之一是使用向量嵌入和向量搜索,但也常用的是采用 BM25(最佳匹配 25)和 TF-IDF(词频 - 逆文档频率)等技术的文档索引数据库。
生成模型
一旦检索模型找到了适当的信息,生成模型就开始发挥作用。 这些模型充当创意作家,将检索到的信息合成为连贯且上下文相关的文本。 生成模型通常建立在 LLMs 的基础上,能够创建语法正确、语义有意义且与初始查询或提示一致的文本。 他们采用检索模型选择的原始数据,并赋予其叙述结构,使信息易于理解和操作。 在 RAG 框架中,生成模型是拼图的最后一块,提供我们与之交互的文本输出。
为什么使用 RAG?
在不断发展的 NLP 领域,人们一直在寻求更智能、上下文感知的系统。 这就是 RAG 发挥作用的地方,它解决了传统生成模型的一些局限性。 那么,是什么推动了 RAG 的日益普及呢?
首先,RAG 提供了一种生成文本的解决方案,该文本不仅流畅,而且事实准确且信息丰富。 通过将检索模型与生成模型相结合,RAG 确保其生成的文本既消息灵通又编写良好。 检索模型带来 “什么” —— 事实内容 —— 而生成模型则贡献 “如何” —— 将这些事实组成连贯且有意义的语言的艺术。
其次,RAG 的双重性质在需要外部知识或上下文理解的任务中提供了固有的优势。 例如,在问答系统中,传统的生成模型可能难以提供精确的答案。 相比之下,RAG 可以通过其检索组件提取实时信息,使其响应更加准确和详细。
最后,需要多步骤推理或综合各种来源信息的场景才是 RAG 真正的亮点。 想想法律研究、科学文献评论,甚至复杂的客户服务查询。 RAG 搜索、选择和综合信息的能力使其在处理此类复杂任务方面无与伦比。
总之,RAG 的混合架构提供了卓越的文本生成功能,使其成为需要深度、上下文和事实准确性的应用程序的理想选择。