前言 大型语言模型 (LLMs) 最近在代码层面的一系列下游任务中表现十分出彩。通过对大量基于代码的数据 (如 GitHub 公共数据) 进行预训练,LLM 可以学习丰富的上下文表征,这些表征可以迁移到各种与代码相关的下游任务。但是,许多现有的模型只能在一部分任务中表现良好,这可能是架构和预训练任务限制造成的。
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
从架构的角度来看,现有的 LLMs 通常采用纯编码器或纯解码器的模型,这些模型通常只在一些理解或生成任务上执行的效果出色。纯编码模型通常适用于理解文本、代码检索之类的任务,而生成代码类的生成任务用纯解码器模型能有更出色的性能表现。并且,最近的一些模型用编码器 - 解码器这种更统一的架构来应对不同的任务。虽然这些模型可以同时支持理解型、生成型任务,但在特定任务中没法达到最佳性能。在检索和代码完成任务上,编码器 - 解码器模型还是不如最先进 (SOTA) 的纯编码器和纯解码器基线。单模块架构虽然通常可以适用于所有任务,但它的局限性也会导致编码器 - 解码器模型的不足。总之,先前的方法在设计时并没有考虑如何让单个组件可以被激活以更好地适应不同类型的下游任务。
从学习对象的角度来看,目前的模型通常采用一组有限的预训练任务。由于预训练和微调阶段的差异,这些预训练任务会使一些下游任务性能下降。例如,基于 T5 的模型通常以跨度去噪目标进行训练。然而,在代码生成等下游任务中,大多数最先进的模型都是用下一个 token 预测目标进行预训练的,该目标可以逐 token 自回归地预测处理。学习对比代码表征对于理解文本、代码检索等任务至关重要,但许多模型没有接受过这一方面训练。尽管近期一些研究尝试引入对比学习任务来缓解这个问题,但这些方法忽略了文本和代码表征之间的细粒度跨模态对齐。
为解决上述限制,来自 Salesforce 的研究者提出了「CodeT5+」—— 一个新的基础 LLM 系列编码器 - 解码器,可用于广泛的代码理解和生成任务。

- 论文地址:https://arxiv.org/pdf/2305.07922.pdf
- 项目地址:https://github.com/salesforce/CodeT5/tree/main/CodeT5%2B
CodeT5 + 是基于编码器 - 解码器的模型,但可以灵活地在纯编码器、纯解码器以及编码器 - 解码器模式下操作,来适应不同的下游应用。总体架构如下图 1:
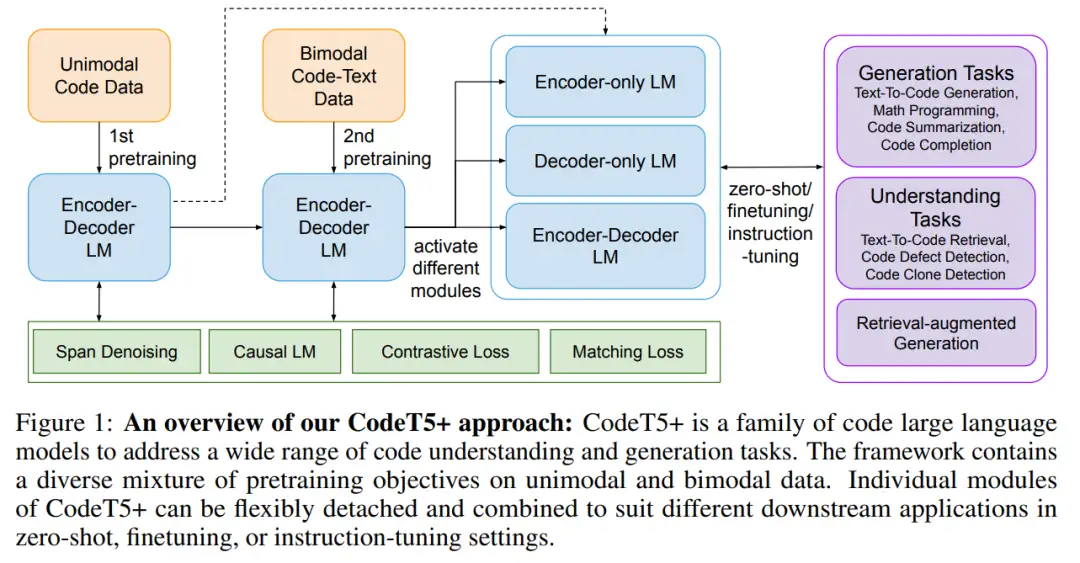
这种灵活性是基于预训练任务实现的,包括代码数据上的跨度去噪和因果语言建模 (CLM) 任务,以及文本 - 代码对比学习、匹配和文本 - 代码数据上的 CLM 任务。如此广泛的预训练任务可以帮助在代码和文本数据中学习丰富的表征,并弥合各种应用中的预训练 - 微调差距。研究者发现,将匹配任务与对比学习相结合,对于捕捉细粒度的文本 - 代码对齐和提高检索性能至关重要。
通过利用现成的 LLM 代码来初始化 CodeT5 + 的组件,用高效计算的预训练策略来扩展 CodeT5 + 的模型大小。CodeT5 + 采用了「浅编码器和深解码器」架构,其中编码器和解码器都从预训练的 checkpoints 中进行初始化,并由交叉注意力层连接。此外,该研究还冻结了深度解码器 LLM,只训练浅层编码器和交叉注意力层,从而大大减少了有效调优的可训练参数数量。最后,受 NLP 领域的启发,研究者开始探索 CodeT5 + 在指令调优上的效果,以更好地使模型与自然语言指令保持一致。
该研究在 20 多个与代码相关的基准测试中对 CodeT5 + 进行了广泛的评估,包括零样本、微调和指令调优。结果表明,与 SOTA 基线相比,CodeT5 + 在许多下游任务上有着实质性的性能提升,例如,8 个文本到代码检索任务 (+3.2 avg. MRR), 2 个行级代码补全任务 (+2.1 avg. Exact Match) 和 2 个检索增强代码生成任务 (+5.8 avg. BLEU-4)。
在 MathQA 和 GSM8K 基准上的两个数学编程任务中,低于十亿参数大小的 CodeT5 + 模型明显优于许多多达 137B 参数的 LLM。特别是,在 HumanEval 基准上的零样本文本到代码生成任务中,指令调优后的 CodeT5+ 16B 与其他开源代码 LLM 相比,达到了新的 SOTA 结果,为 35.0% pass@1 和 54.5% pass@10,甚至超过了闭源 OpenAI code- cusherman -001 模型。最后,该研究发现 CodeT5 + 可以无缝的看作半参数检索增强生成系统,在代码生成方面明显优于其他类似方法。所有的 CodeT5 + 模型都将开源,以支持研究和开发者社区。
CodeT5+:开源大型语言模型
本文开发了 CodeT5+,一个新的开源代码大型语言模型家族,用于代码理解和生成任务。基于编码器 - 解码器架构,CodeT5 + 通过本文提出的在单模态和双模态数据上混合预训练目标的方式,增强了在不同下游任务中以不同模式运行的灵活性。
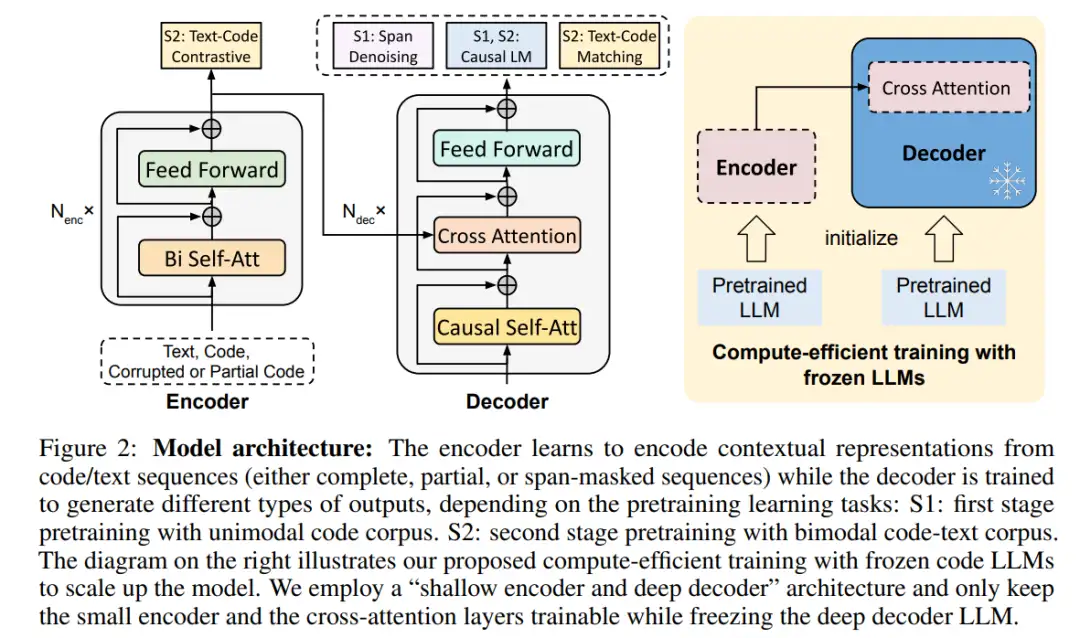
架构细节

预训练细节
在单模态预训练阶段,研究者使用大量的代码数据,用计算高效的目标预训练模型。在双模态预训练阶段,继续用较小的具有跨模态学习目标的代码 - 文本数据集预训练模型。对于每个阶段,使用相同的权重联合优化多个预训练目标。
研究者发现这种分阶段训练方法可以有效地让模型接触更多样化的数据,以学习丰富的上下文表征。此外,他们探索了用现成的代码 LLM 初始化 CodeT5+,以有效地扩展模型。最后,CodeT5 + 中的模型组件可以动态组合以适应不同的下游应用任务。
实验
研究者实现了一系列 CodeT5 + 模型,模型大小从 220M 到 16B 不等。
CodeT5+ 220M 和 770M 采用与 T5 相同的架构,并从头开始进行预训练,而 CodeT5+ 2B、6B、16B 采用「浅层编码器和深层解码器」架构,编码器分别从 CodeGen-mono 350M 初始化,解码器从 CodeGen-mono 2B、6B、16B 初始化。研究者将 CodeT5 + 与 SOTA 代码模型进行了比较,这些 LLM 可以分为 3 种类型:纯编码器、纯解码器和编码器 - 解码器模型。
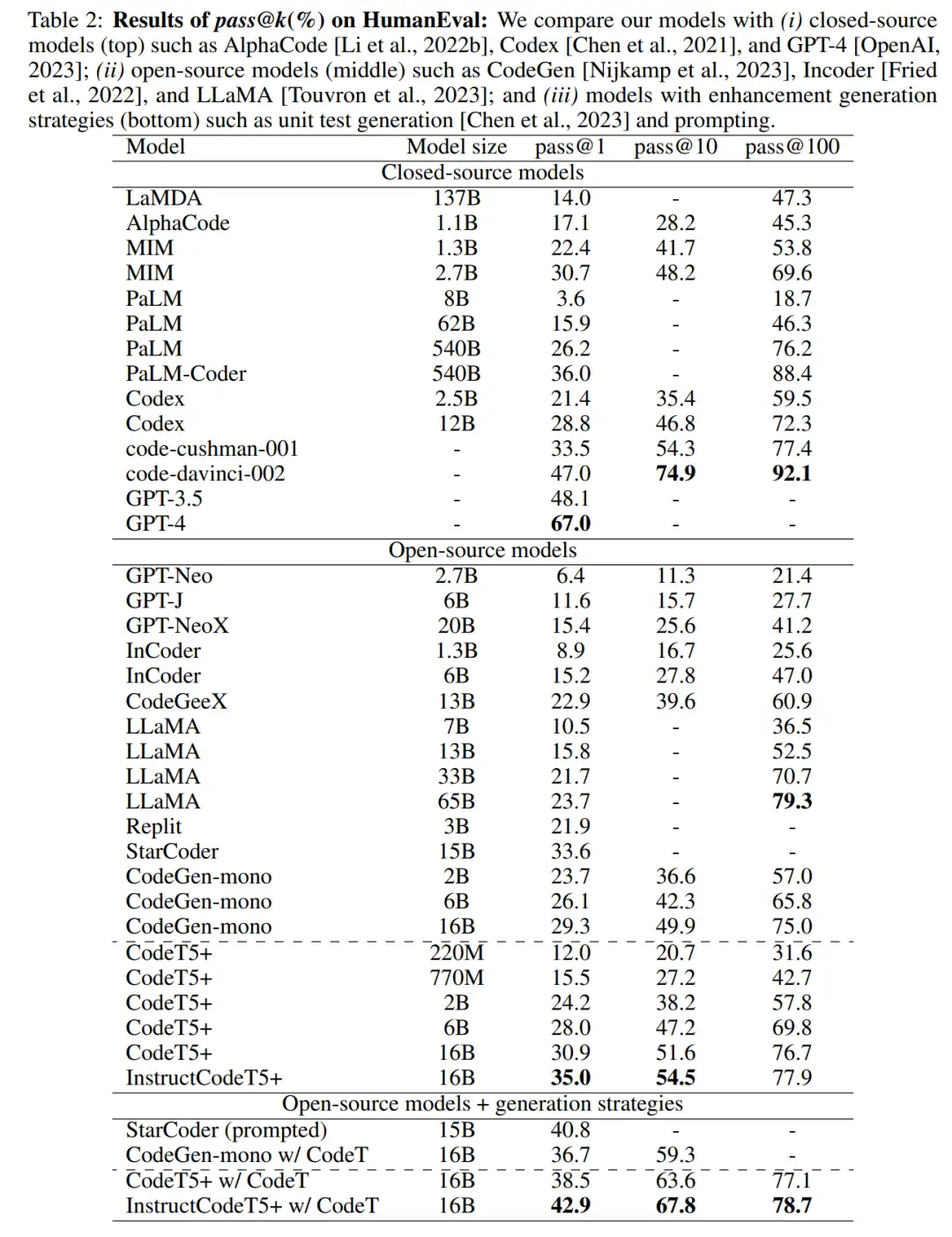
文本到代码生成任务的零样本评估
在给定自然语言规范的情况下,研究者评估了模型在零样本设置下生成 Python 代码的能力,通过在单元测试中测试生成的代码来评估模型性能。表 2 中展示了合格率 pass@k。
评估数学编程任务
研究者同时考察了其他代码生成任务,特别是两个数学编程基准 MathQAPython 和 GSM8K 。如表 3 所示,CodeT5 + 取得了显著的性能提升,超过了许多更大规模的代码 LLM。
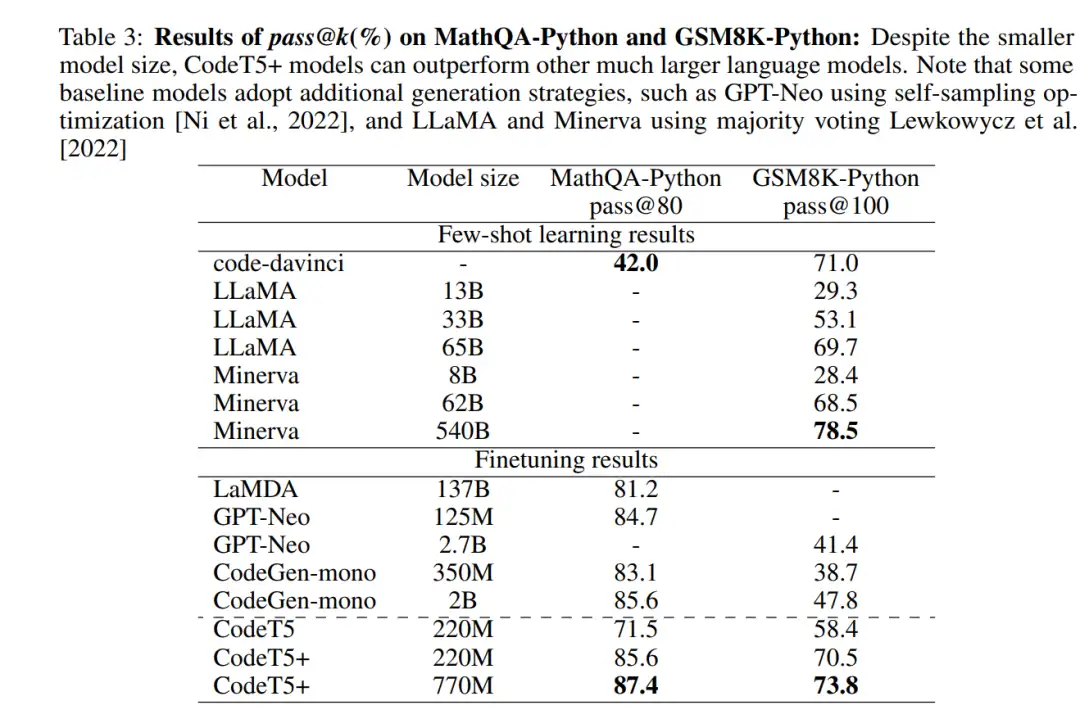
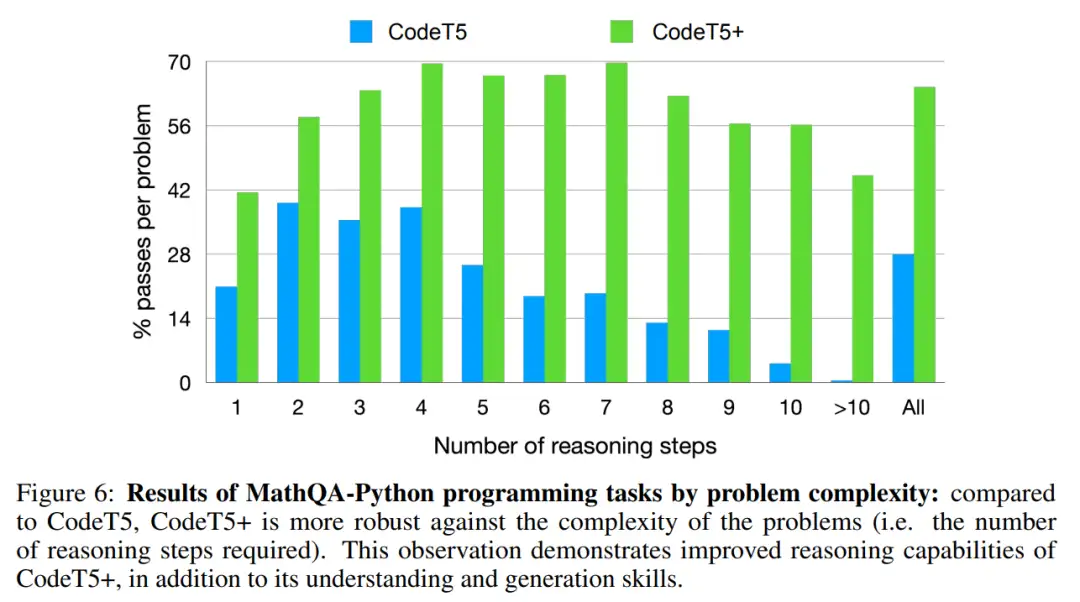
图 6 展示了通过 MathQA-Python 上数学编程问题的复杂性来分析模型性能。对于每个问题,提取解决问题所需的推理步骤数。与 CodeT5 相比,CodeT5 + 对问题的复杂性 (即所需的推理步骤数量) 更鲁棒。
评估代码摘要任务
代码摘要任务旨在将代码片段总结为自然语言文档字符串。研究者使用了六种编程语言的 Clean 版本的 CodeSearchNet 数据集来评估这项任务的模型。
从表 4 中可以发现,编码器 - 解码器模型 (CodeT5 和 CodeT5+) 的性能通常优于纯编码器模型、纯解码器模型以及 UniLM-style 的模型 UniXcoder 。

评估代码补全任务
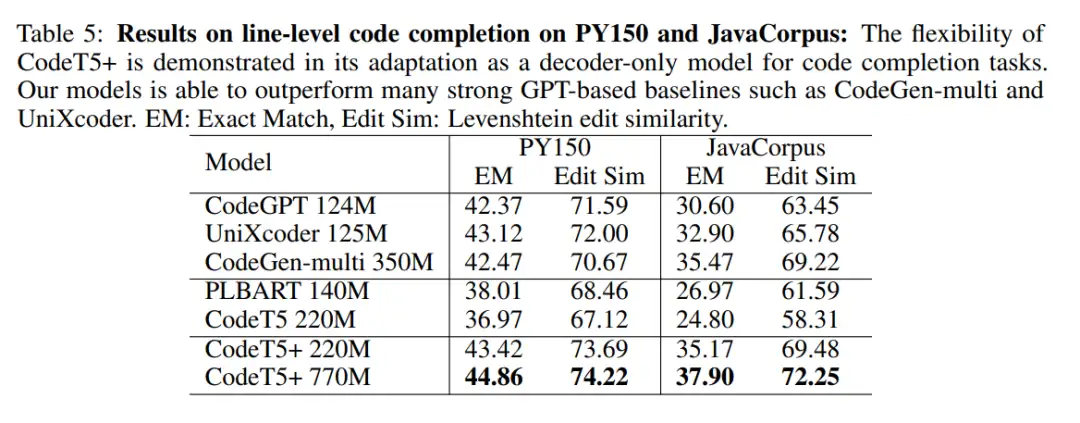
研究者通过 line-level 补全任务评估了 CodeT5 + 仅解码器的生成能力,旨在根据上下文完成下一行代码。
如表 5 所示,CodeT5+(在纯解码器的模式下) 和纯解码器模型 (top block) 的性能都明显优于编码器 - 解码器模型(the middle block),验证了纯解码器的模型可以更好地适应代码补全任务。
评估文本到代码的检索任务
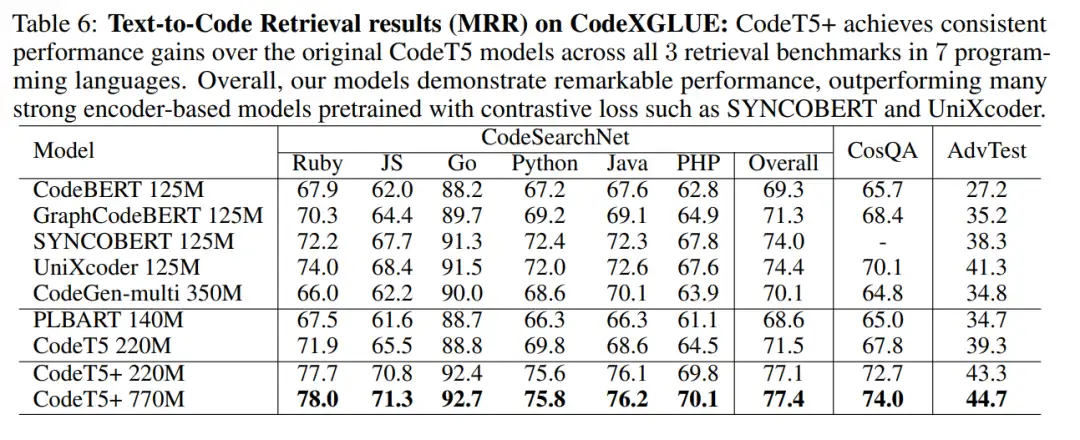
研究者还通过跨多个 PL 的文本到代码检索任务评估 CodeT5 + 的代码理解能力。从表 6 中可以看出,CodeT5+ 220M 明显优于所有现有的纯编码器 / 纯解码器模型 (顶部块) 和编码器 - 解码器模型 (中间块)。
更多研究细节,可参考原论文。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
ICLR2023 | 扩散生成模型新方法:极度简化,一步生成
小内存有救了!Reversible ViT:显存减少15倍,大模型普及曙光初现!
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
CVPR 2023 | 即插即用!SQR:对于训练DETR-family目标检测的探索和思考
CVPR 2023 Highlight | 西湖大学提出一种全新的对比多模态变换范式
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary