PSANet: Point-wise Spatial Attention Network for Scene Parsing
* Authors: [[Hengshuang Zhao]], [[Yi Zhang]], [[Shu Liu]], [[Jianping Shi]], [[Chen Change Loy]], [[Dahua Lin]], [[Jiaya Jia]]
初读印象
comment:: (PSANet)每个像素都运用了双向的注意力机制。
Why
CNN中卷积核限制了感受野,无法建立长程依赖。
以前的解决方法:
- 扩大感受野:膨胀卷积,全局池化
- 建立长程依赖:CRF,MRF,RNN
缺点: - 在不同区域内使用了相同的上下文依赖关系。
- 效率低。
What
为所有像素建立一个可学习的、自适应的长程依赖和双向传播路径。
构造注意力矩阵的方法改变为从over-completed的map中采样。
How
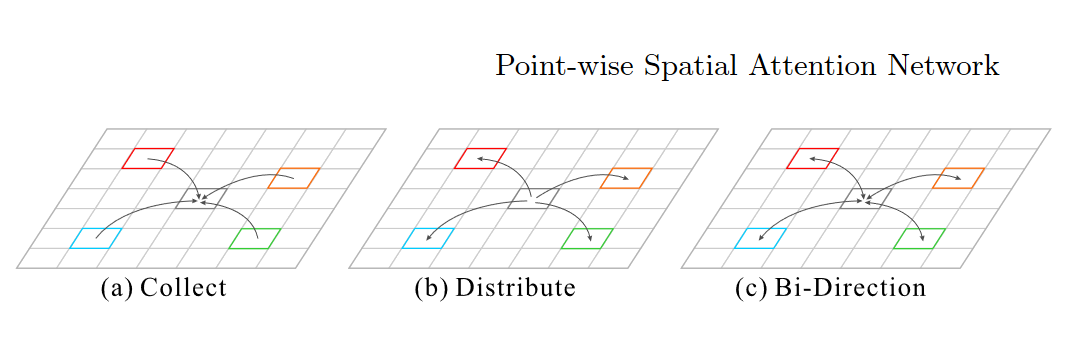 *建立双向自适应依赖如下,前者为“收集”路径,后者为“分发路径”。
*建立双向自适应依赖如下,前者为“收集”路径,后者为“分发路径”。
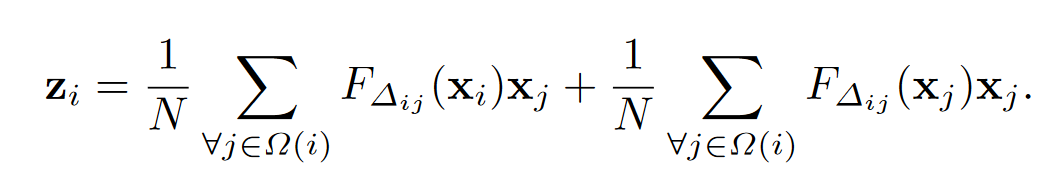
- 其中的两个函数值可以视为预测注意值,分别取自\(Z^c,Z^d\)矩阵。
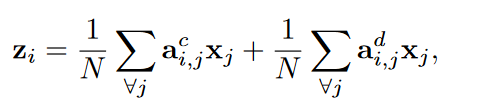
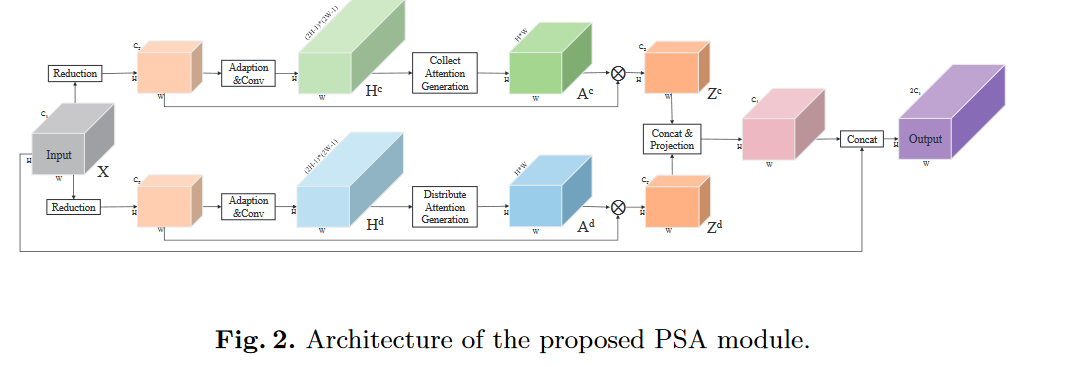
(pdf) - 用了两个分支以产生\(Z^c,Z^d\)矩阵,这两个分支的操作是相同的。
-
用一个1×1卷积降低维度(\(C_1>C_2\))。
-
1×1卷积进行特征自适应,BN,激活函数 。
-
用1×1卷积层生成predicted over-completed map--\(H^c,H^d\),通道数为\((2H-1)×(2W-1)\)。其中每一行都能拿出来reshape成一个空间矩阵,其中以i为中心的\(H×W\)的数据是能被汇聚的。
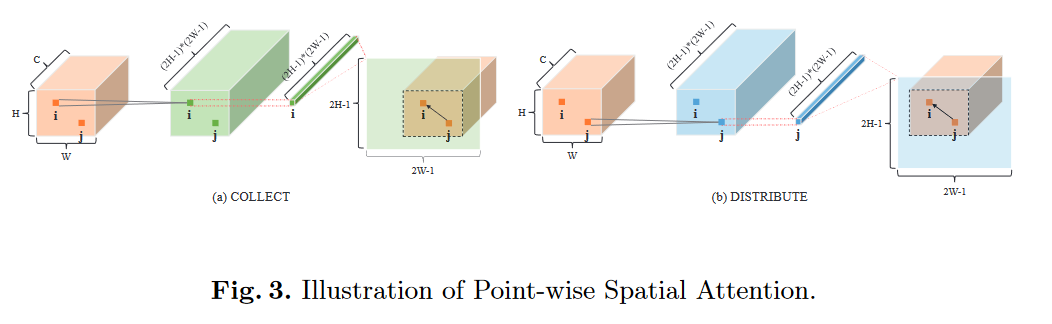
-
用\(H^c,H^d\)产生Attention Map--\(A^c,A^d\)。以“收集”分支为例,如上图所示,从\(H^c\)中取出一行\(h_i^c\),reshape为(2H-1)×(2W-1)的map,如果i是第k行、第l列的,那么该元素对应的注意力map就是从reshape后的map中从(H-k),(W-l)开始截出H,W大小的map。
-
将降维后的\(X\)reshape成\(C_2×(H×W)\),\(A\)reshape为\((H×W)×(H×W)\),相乘两者再reshape为\(C_2×H×W\)以得到\(Z^c,Z^d\),并对其进行正则化
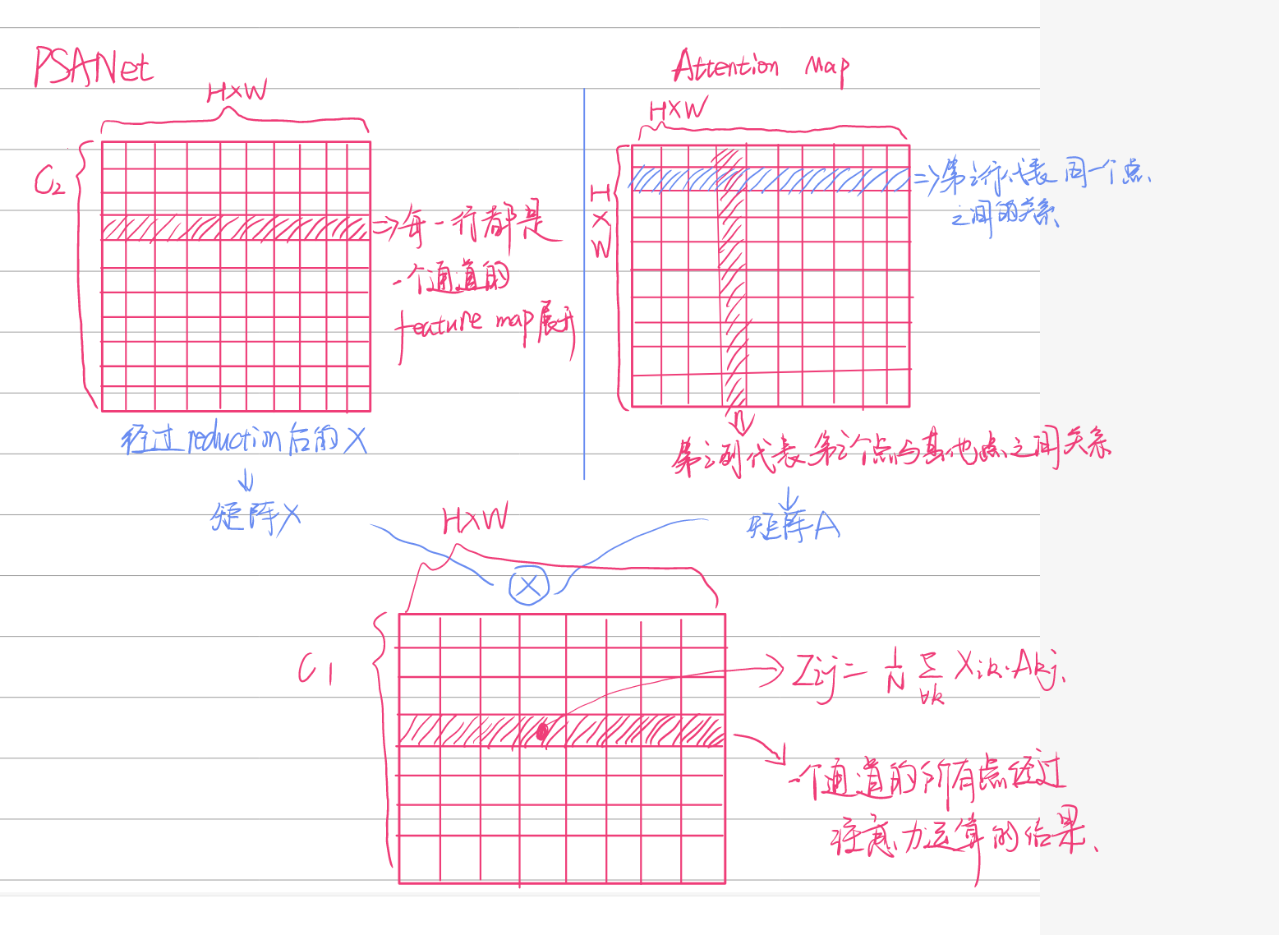
-
x_col = torch.bmm(x_col.view(n, c, h * w), y_col.view(n, h * w, h * w)).view(n, c, h, w) * (1.0 / self.normalization_factor)
x_dis = torch.bmm(x_dis.view(n, c, h * w), y_dis.view(n, h * w, h * w)).view(n, c, h, w) * (1.0 / self.normalization_factor)
- 拼接\(Z^c,Z^d\),n×(卷积,BN,激活函数),再与X拼接,n×(卷积,BN,激活函数)以产生最终输出。
- 将其添加在FCN后。
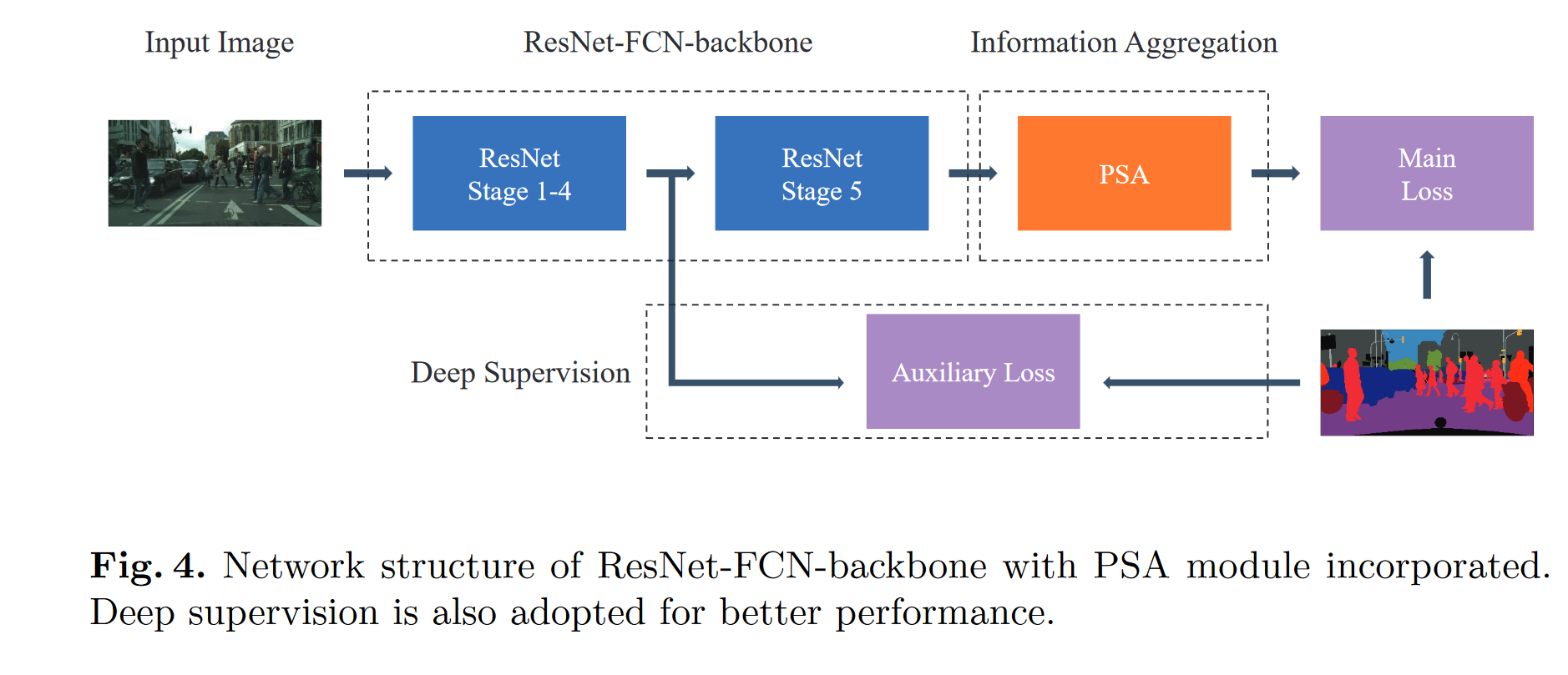
Experiment
超参数
batchsize:16
poly,lr=0.01,power=0.9
动量=0.9
权重衰退 = 0.0001
数据增强:随机镜像,随机resize(0.5-2.0),随机旋转(-10到10°),随机高斯模糊
不同信息汇聚方法的比较
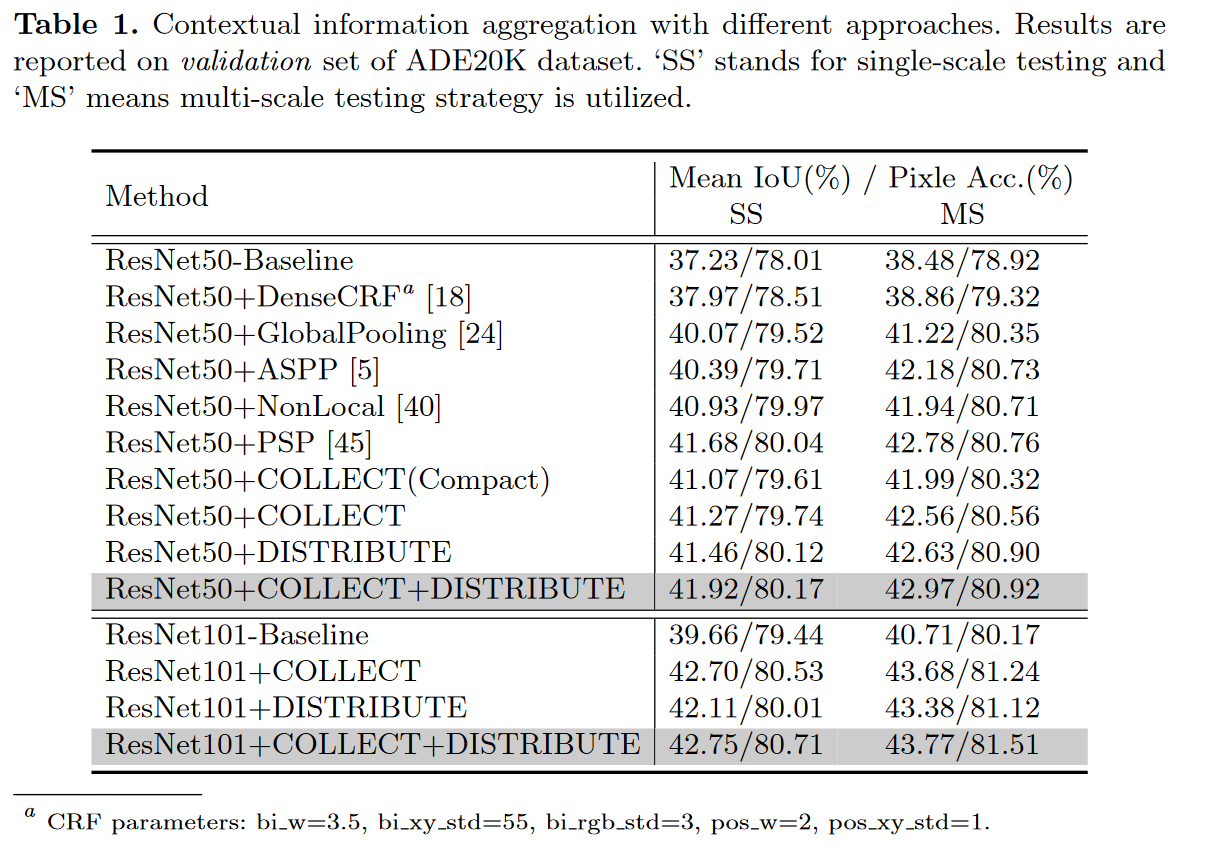
Conclusion
通过双向的数据传播路径,传输点对点间的长程语义信息。
相对于Non-local,获得attention map的方法改变了。