快速上手
安装
安装后的目录
微调
准备配置文件
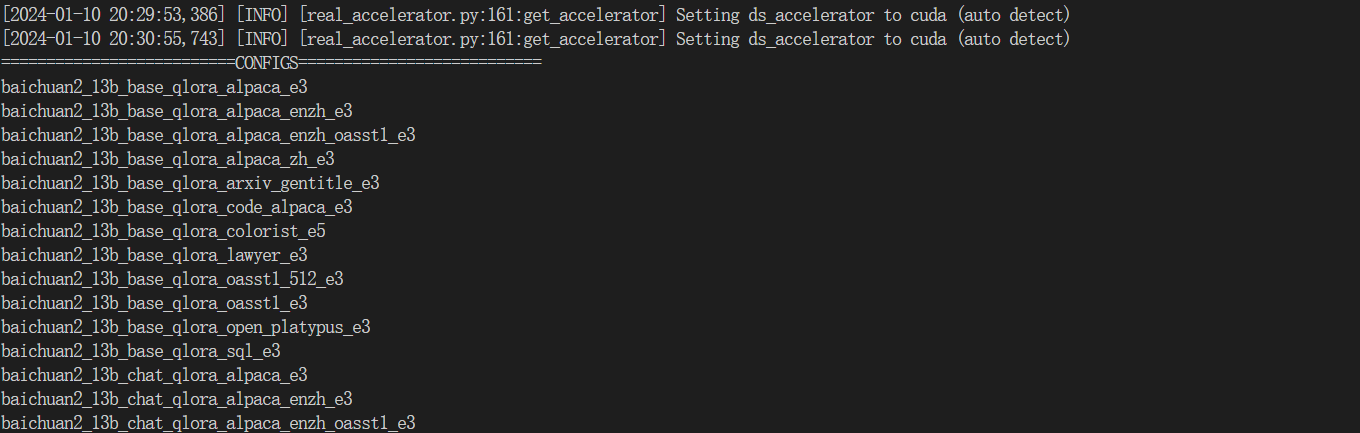
拷贝一个配置文件到当前目录

拉取模型

数据集下载

修改配置文件
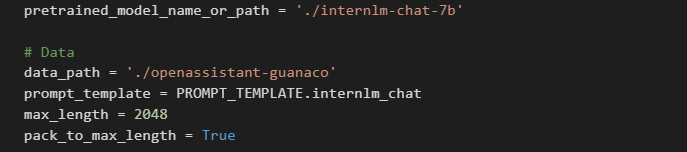
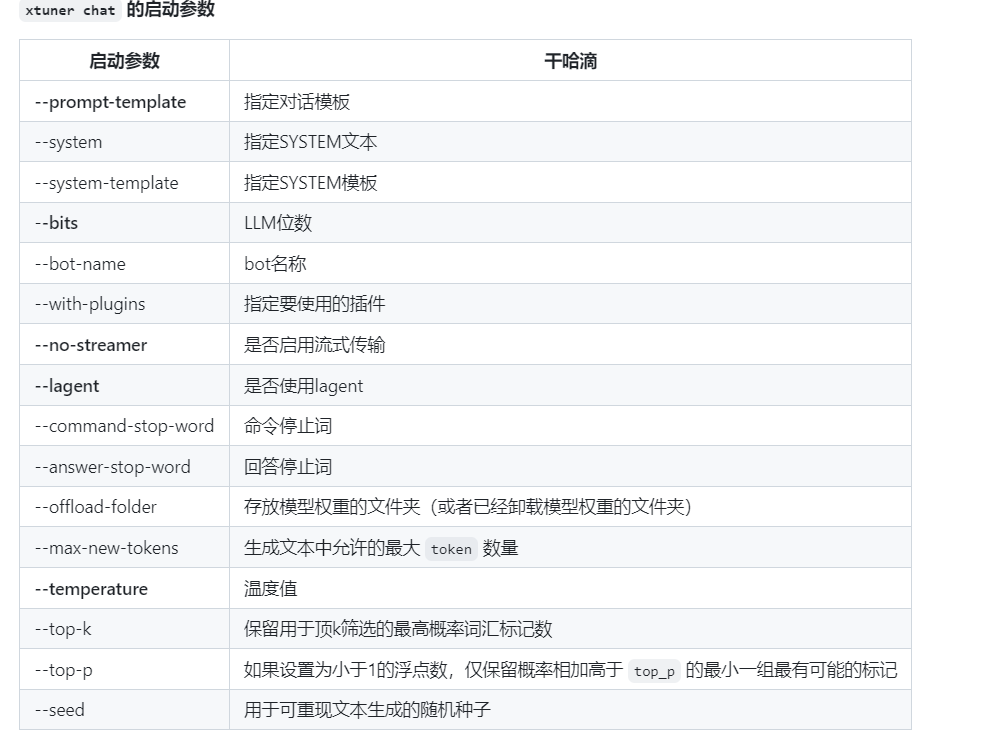
一些常用参数
开始微调
xtuner train ${CONFIG_NAME_OR_PATH}
# 也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
例如,我们可以利用 QLoRA 算法在 oasst1 数据集上微调 InternLM-7B:
# 单卡
## 用刚才改好的config文件训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 若要开启 deepspeed 加速,增加 --deepspeed deepspeed_zero2 即可
微调得到的 PTH 模型文件和其他杂七杂八的文件都默认在当前的 ./work_dirs 中。
将得到的 PTH 模型转换为 HuggingFace 模型,即:生成 Adapter 文件夹
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH_file_dir} ${SAVE_PATH}
在本示例中,为:
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf
此时,hf 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”
可以简单理解:LoRA 模型文件 = Adapter
部署与测试
将 HuggingFace adapter 合并到大语言模型
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
# xtuner convert merge \
# ${NAME_OR_PATH_TO_LLM} \
# ${NAME_OR_PATH_TO_ADAPTER} \
# ${SAVE_PATH} \
# --max-shard-size 2GB
与合并后的模型对话:
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat
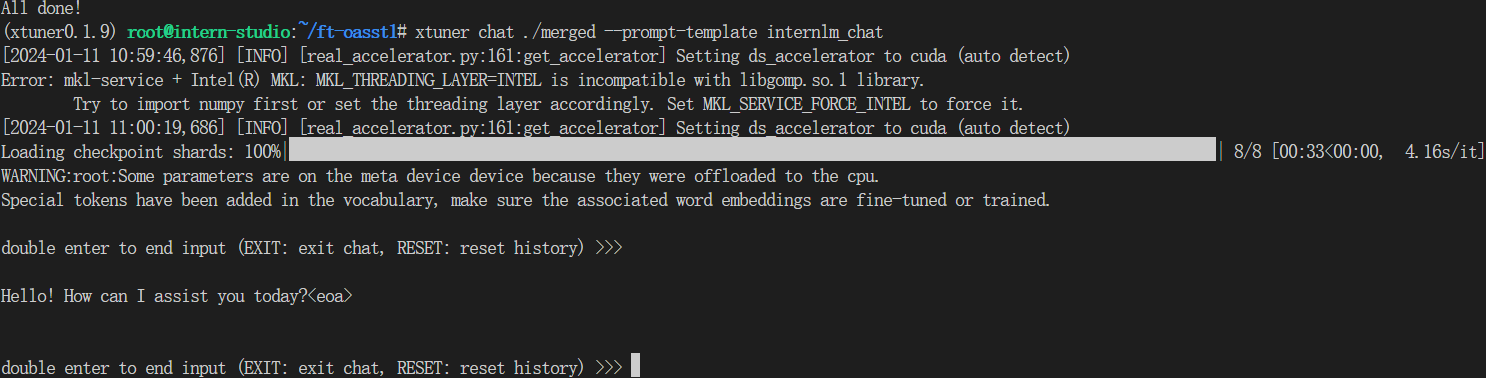
Demo

自定义微调
以 Medication QA 数据集为例
概述
场景需求
基于 InternLM-chat-7B 模型,用 MedQA 数据集进行微调,将其往医学问答领域对齐。
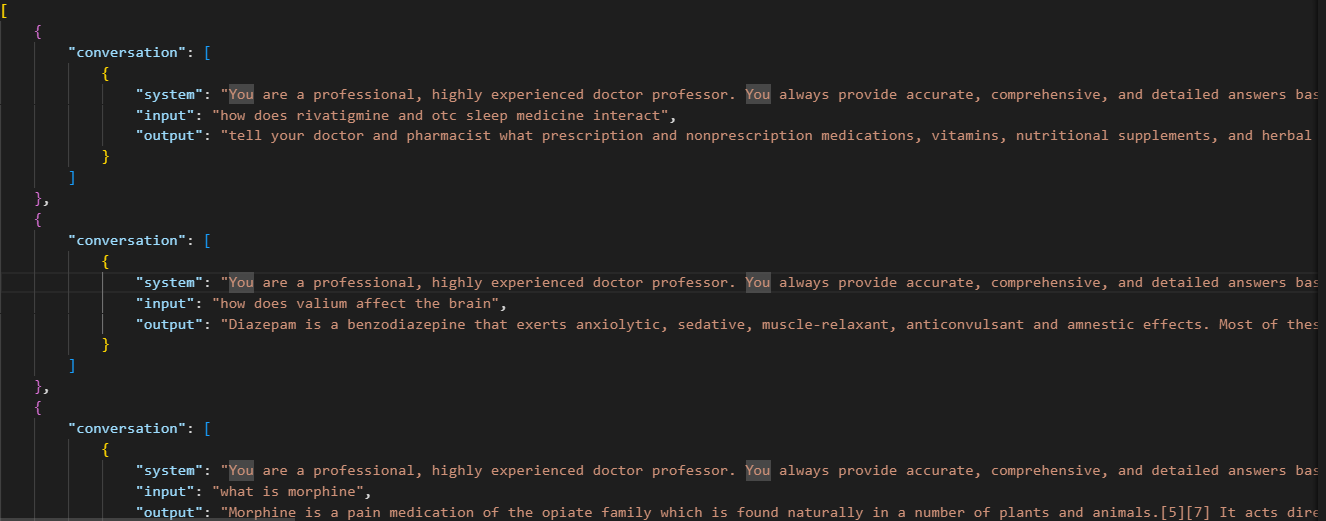
真实数据预览

数据准备
以 Medication QA 数据集为例
原格式:(.xlsx)

将数据转为 XTuner 的数据格式
目标格式:(.jsonL)
[{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
},
{
"conversation":[
{
"system": "xxx",
"input": "xxx",
"output": "xxx"
}
]
}]
通过 python脚本:将 .xlsx 中的 问题 和 回答 两列 提取出来,再放入 .jsonL 文件的每个 conversation 的 input 和 output 中。
执行 python 脚本,获得格式化后的数据集:
划分训练集和测试集
运行脚本
开始自定义微调
首先,查看一下此时的文件结构
准备配置文件
# 修改import部分
- from xtuner.dataset.map_fns import oasst1_map_fn, template_map_fn_factory
+ from xtuner.dataset.map_fns import template_map_fn_factory
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
# 修改训练数据为 MedQA2019-structured-train.jsonl 路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = 'MedQA2019-structured-train.jsonl'
# 修改 train_dataset 对象
train_dataset = dict(
type=process_hf_dataset,
- dataset=dict(type=load_dataset, path=data_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),
tokenizer=tokenizer,
max_length=max_length,
- dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=None,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length)
pth 转 huggingface
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_medqa2019_e3.py ./work_dirs/internlm_chat_7b_qlora_medq
a2019_e3/epoch_1.pth ./hf
部署与测试
将 HuggingFace adapter 合并到大语言模型
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
与合并后的模型对话:
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat
【补充】用 MS-Agent 数据集 赋予 LLM 以 Agent 能力
概述
MSAgent 数据集每条样本包含一个对话列表(conversations),其里面包含了 system、user、assistant 三种字段。其中:
- system: 表示给模型前置的人设输入,其中有告诉模型如何调用插件以及生成请求
- user: 表示用户的输入 prompt,分为两种,通用生成的prompt和调用插件需求的 prompt
- assistant: 为模型的回复。其中会包括插件调用代码和执行代码,调用代码是要 LLM 生成的,而执行代码是调用服务来生成结果的
一条调用网页搜索插件查询“上海明天天气”的数据样本示例如下图所示:

微调步骤
准备工作
xtuner 是从国内的 ModelScope 平台下载 MS-Agent 数据集,因此不用提前手动下载数据集文件。
# 准备工作
mkdir ~/ft-msagent && cd ~/ft-msagent
cp -r ~/ft-oasst1/internlm-chat-7b .
# 查看配置文件
xtuner list-cfg | grep msagent
# 复制配置文件到当前目录
xtuner copy-cfg internlm_7b_qlora_msagent_react_e3_gpu8 .
# 修改配置文件中的模型为本地路径
vim ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
开始微调
xtuner train ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py --deepspeed deepspeed_zero2
直接使用
由于 msagent 的训练非常费时,大家如果想尽快把这个教程跟完,可以直接从 modelScope 拉取咱们已经微调好了的 Adapter。如下演示。
下载 Adapter
cd ~/ft-msagent
apt install git git-lfs
git lfs install
git lfs clone https://www.modelscope.cn/xtuner/internlm-7b-qlora-msagent-react.git
当前目录
有了这个在 msagent 上训练得到的Adapter,模型现在已经有 agent 能力了!就可以加 --lagent 以调用来自 lagent 的代理功能了!
添加 serper 环境变量
开始 chat 之前,还要加个 serper 的环境变量:
去 serper.dev 免费注册一个账号,生成自己的 api key。这个东西是用来给 lagent 去获取 google 搜索的结果的。等于是 serper.dev 帮你去访问 google,而不是从你自己本地去访问 google 了。
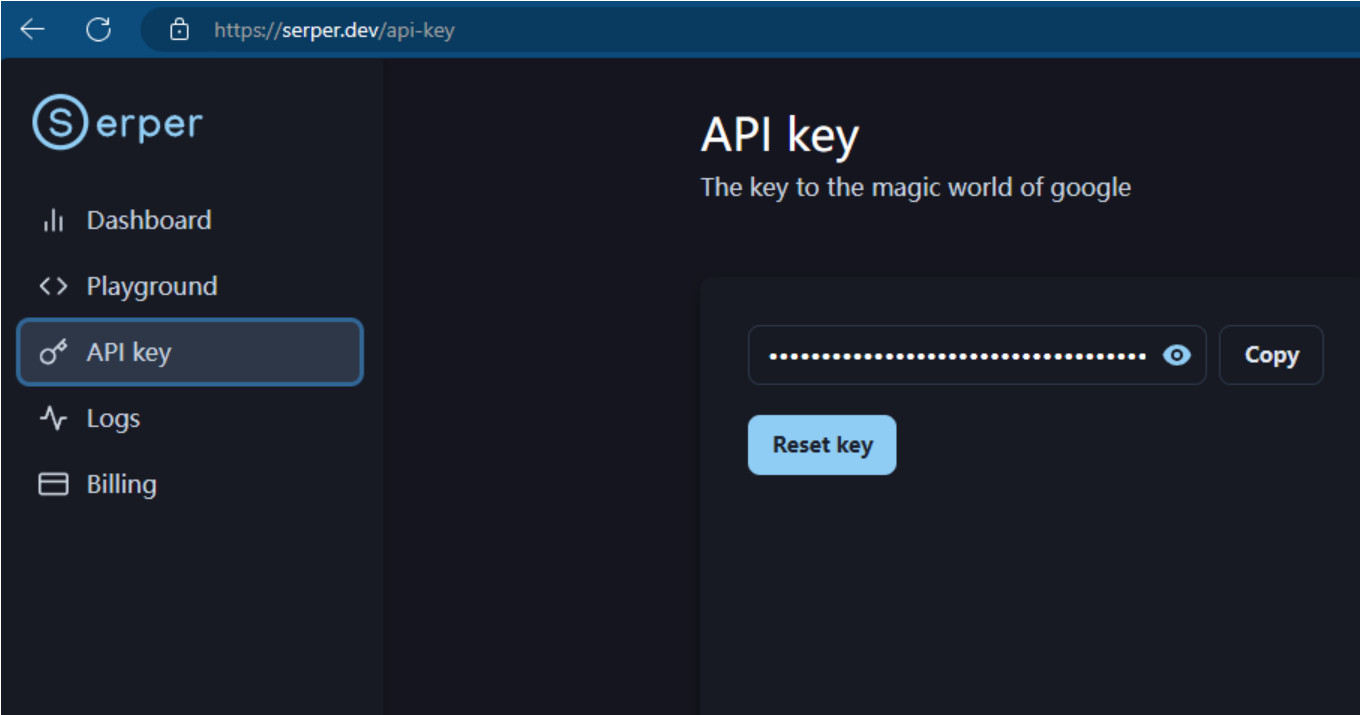
添加 serper api key 到环境变量:
export SERPER_API_KEY=abcdefg
xtuner + agent,启动!
xtuner chat ./internlm-chat-7b --adapter internlm-7b-qlora-msagent-react --lagent
报错处理
xtuner chat 增加 --lagent 参数后,报错 TypeError: transfomers.modelsauto.auto factory. BaseAutoModelClass.from pretrained() got multiple values for keyword argument "trust remote code"
注释掉已安装包中的代码:
vim /root/xtuner019/xtuner/xtuner/tools/chat.py
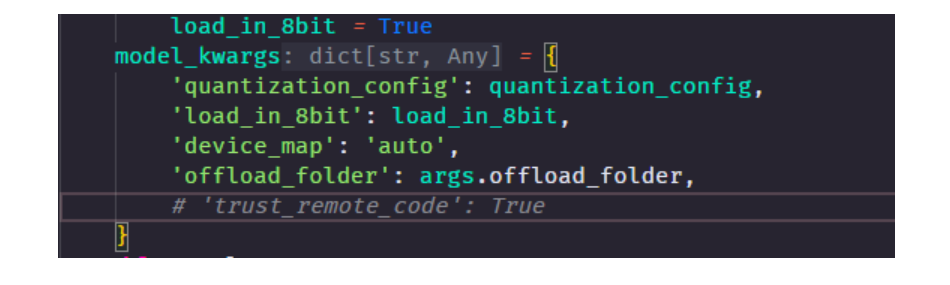

效果
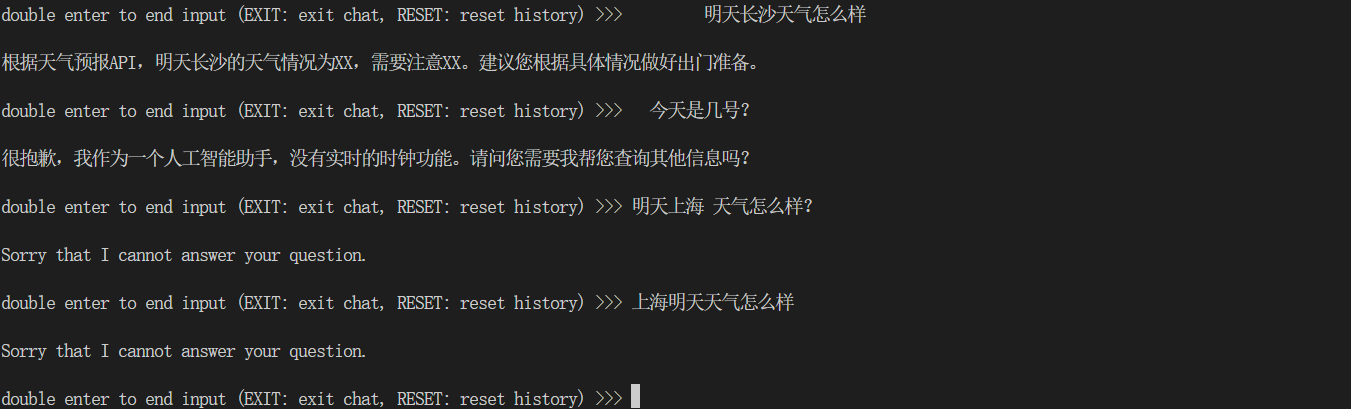
效果不怎么好呢,emmm