作业①
(1)实验内容
o要求:指定一个网站,例如中国气象网(http://www.weather.com.cn)。爬取这个网站中的所有图片。使用scrapy框架分别实现单线程和多线程的方式爬取。(控制总页数、总下载的图片数量等限制爬取的措施。)
o输出信息:将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图。
oGitee 文件夹链接:
o核心代码文件配置:
配置文件 setting.py:
# Obey robots.txt rules
#默认是True,遵守robots.txt文件中的协议,遵守允许爬取的范围。
#设置为False,是不遵守robo协议文件。。。
ROBOTSTXT_OBEY = False
#把爬取的数据推送到 pipelines 的 ProjectOnePipeline 类中
ITEM_PIPELINES = {
"project_one.pipelines.ProjectOnePipeline": 300,
}
scrapy爬虫程序 mySpider.py:
from bs4 import UnicodeDammit
from scrapy.selector import Selector
import scrapy
import re
from project_one.items import imgItem
class mySpider(scrapy.Spider):
name="mySpider"
start_urls=[]
url = "http://search.dangdang.com/?key=python&act=input" # 网址(这里选择爬取当当网Python书籍页面)
number = eval(input("请输入爬取商品的数量:")) # 获得爬取商品数量
# 根据需获取商品的数量计算爬取的页面
s = number - 60 # 网址单页商品个数为60
page = 1
while s > 0:
s = s - 60
page = page + 1
# https://search.dangdang.com/?key=python&act=input&page_index=2
# https://search.dangdang.com/?key=python&act=input&page_index=3
# 翻页后只修改了一个参数page_index,于是要实现翻页只需要修改url中的page_index即可。
for i in range(page): #获取各页面网址
url = url + '&page_index={}'.format(i + 1)
start_urls.append(url)
def parse(self, response):
try:
number=self.number #获取的商品数量
count=0
r = r'data-original'
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = Selector(text=data)
lis = selector.xpath("//ul[@class='bigimg']/li/a[@class='pic']/img")
for i in range(len(lis)):
count=count+1
if number>=count:
res = re.search(r, str(lis[i]))
if res:
pic = lis[i].xpath("@data-original").extract_first()
else:
pic = lis[i].xpath("@src").extract_first()
img_url = "https:" + str(pic)
item = imgItem()
item["img_url"] = img_url if img_url else ""
item["count"] = count if count else ""
yield item
else :
break
except Exception as err:
print(err)
数据项目类 items.py:
import scrapy
class imgItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img_url=scrapy.Field()
count=scrapy.Field()
数据处理类 pipelines.py:
import urllib.request
class ProjectOnePipeline(object):
def process_item(self, item, spider):
try:
req = urllib.request.urlopen(item["img_url"])
buf = req.read() # 获取文件数据
print("正在下载图片:" + item["img_url"]) # 显示当前正在下载的图片网址
f = open('C:/Users/86180/Desktop/Python/project_one/images/' + str(item["count"])+".jpg", 'wb+')
f.write(buf)
f.close()
except Exception as err:
print(err)
return item
执行爬虫程序 run.py:
from scrapy import cmdline
# mySpider 为爬虫程序name
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
o运行结果:

o查看images文件夹:
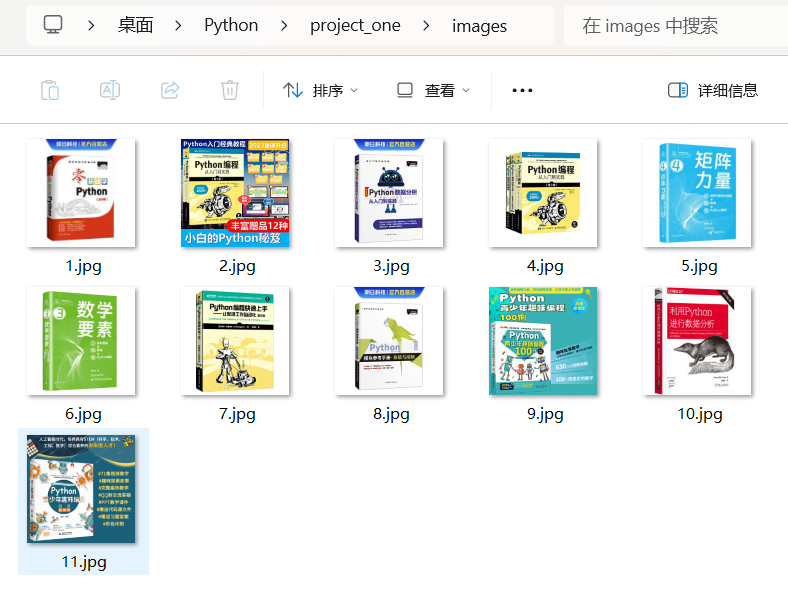
oGitee 文件夹链接:
o核心代码文件配置:
配置文件 setting.py:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
#把爬取的数据推送到 pipelines 的 ProjectOneThreadPipeline 类中
ITEM_PIPELINES = {
"project_one_thread.pipelines.ProjectOneThreadPipeline": 300,
}
scrapy爬虫程序 mySpider.py:
from bs4 import UnicodeDammit
from scrapy.selector import Selector
import scrapy
import urllib.parse
import re
from project_one_thread.items import imgItem
class mySpider(scrapy.Spider):
name="mySpider"
start_urls=[]
url = "http://search.dangdang.com/?key=python&act=input" # 网址
number = eval(input("请输入爬取商品数:")) # 获取爬取商品数
s = number - 60 # 网址单页商品个数为60
page = 1
while s > 0:
s = s - 60
page = page + 1
# https://search.dangdang.com/?key=python&act=input&page_index=2
# https://search.dangdang.com/?key=python&act=input&page_index=3
# 翻页后只修改了一个参数page_index,于是要实现翻页只需要修改url中的page_index即可。
for i in range(page):
url = url + '&page_index={}'.format(i + 1)
start_urls.append(url)
def parse(self, response):
try:
number=self.number
count=0
r = r'data-original'
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = Selector(text=data)
lis = selector.xpath("//ul[@class='bigimg']/li/a[@class='pic']/img")
for i in range(len(lis)):
count=count+1
if number>=count:
res = re.search(r, str(lis[i]))
if res:
pic = lis[i].xpath("@data-original").extract_first()
else:
pic = lis[i].xpath("@src").extract_first()
img_url = "https:" + str(pic)
item = imgItem()
item["img_url"] = img_url if img_url else ""
yield item
else :
break
except Exception as err:
print(err)
数据项目类 items.py:
import scrapy
class imgItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img_url=scrapy.Field()
数据处理类 pipelines.py:
import urllib.request
import threading
threads=[]
counts=0
class ProjectOneThreadPipeline(object):
def process_item(self, item, spider):
global counts
global threads
url=item["img_url"]
counts=counts+1
T = threading.Thread(target=self.downloadImg, args=(url, counts))
T.setDaemon(False) # 前台线程,非守护线程
T.start()
threads.append(T)
return item
def downloadImg(self, url, counts): # data为一张图片网址 count为每个线程编号,同时设为图片名称,便于区分观察
req = urllib.request.urlopen(url)
buf = req.read() # 获取文件数据
print("正在下载第{}张图片,".format(counts) + "网址:" + url) # 显示当前正在下载哪张图片及其网址
f = open('C:/Users/86180/Desktop/Python/project_one_thread/images/' + str(counts) + '.' + 'jpg', 'wb+')
f.write(buf)
f.close()
执行爬虫程序 run.py:
from scrapy import cmdline
# mySpider 为爬虫程序name
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
o运行结果:

o查看images文件夹:
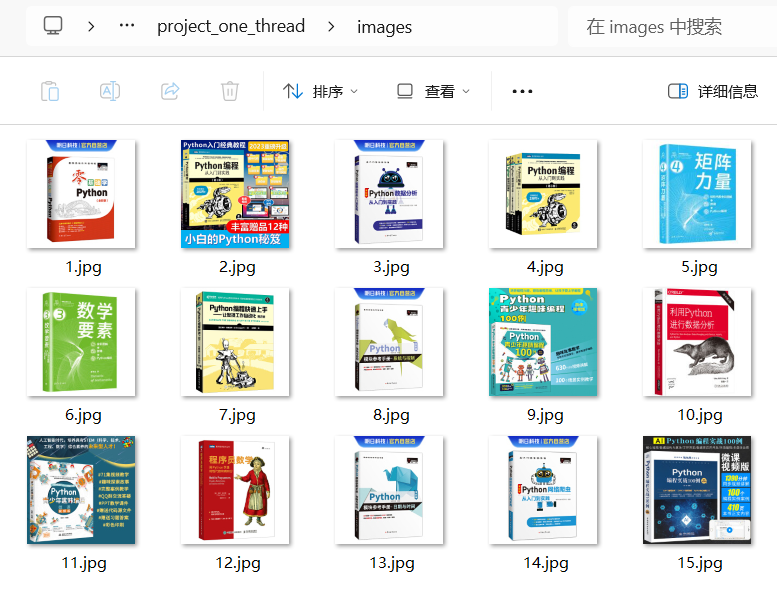
o问题与解决:
观察其img标签src属性,通过src属性内容可以获取所有商品图片网址。


然而编写程序测试,发现除了第一个商品src属性值对应,其余src属性值均相同且非对应图片网址,爬取结果如下所示
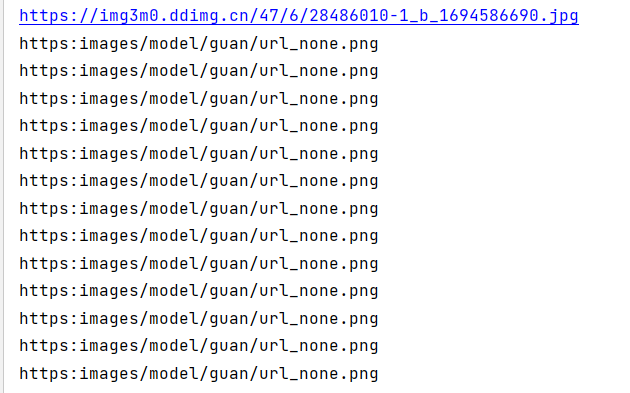
再次编程测试,发现除了第一个商品图片网址存于src属性,其余商品图片网址存于data-original属性,爬取结果如下所示

至于为何查看的标签属性值与爬取得到的标签属性值不同目前尚未弄清楚其中原因。测试发现标签只有src属性,则网址必为src属性值,若标签含有data-original属性,则网址必为data-original属性值。这里使用正则表达式判断爬取得到的标签是否存在data-original属性,若存在则获取data-original属性值,若不存在则获取src属性值。
r = r'data-original'
res = re.search(r, str(lis[i]))
if res:
pic = lis[i].xpath("@data-original").extract_first()
else:
pic = lis[i].xpath("@src").extract_first()
(2)心得体会
此次实验通过使用scrapy框架爬取下载网站图片,巩固了scrapy框架基础知识,加深了对scrapy框架的理解,同时深入理解了多线程运行机制。
作业②
(1)实验内容
o要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:
东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
新浪股票:http://finance.sina.com.cn/stock/
o输出信息:
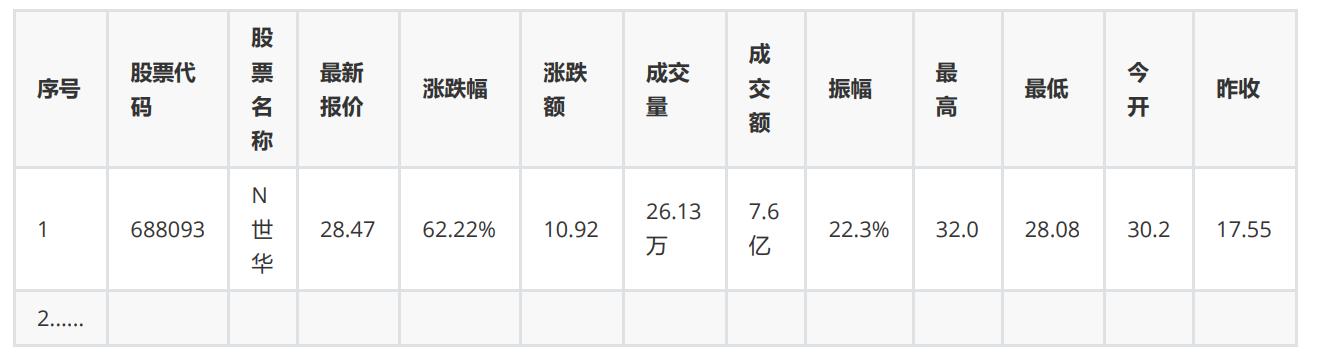
oGitee 文件夹链接:
技巧:
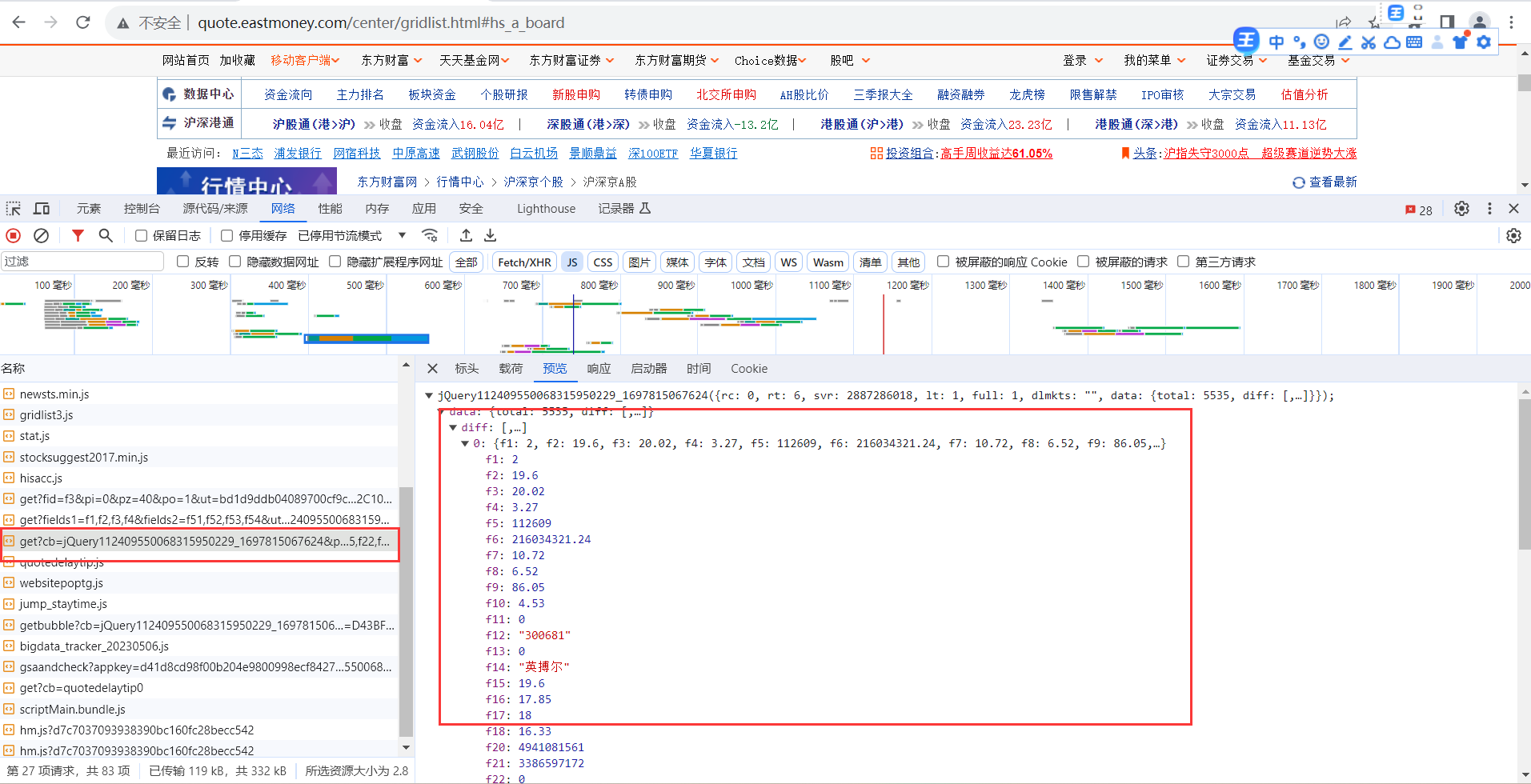
在谷歌浏览器中进入 F12 调试模式进行抓包,查找股票列表加载使用的 url,并分析 api 返回的值,并根据所要求的参数可适当更改api 的请求参数。
查看url的组成,存在一项“pz=20”,该值为返回股票数,通过设置该值获取所需股票数。
o核心代码文件配置:
配置文件 setting.py:
# Obey robots.txt rules
#默认是True,遵守robots.txt文件中的协议,遵守允许爬取的范围。
#设置为False,是不遵守robo协议文件。。。
ROBOTSTXT_OBEY = False
#把爬取的数据推送到 pipelines 的 ProjectTwoPipeline 类中
ITEM_PIPELINES = {
"project_two.pipelines.ProjectTwoPipeline": 300,
}
scrapy爬虫程序 mySpider.py:
import scrapy
import re
from project_two.items import StockItem
class mySpider(scrapy.Spider):
name="mySpider"
start_urls=[]
number = eval(input("请输入爬取股票数量:"))
url="https://50.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112409550068315950229_1697815067624&pn=1&pz={}&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1697815067625".format(number)
start_urls.append(url)
def parse(self, response):
try:
paper = response.text
results = []
# 通过正则表达式查找所需的所有数据
Code = re.findall('"f12":"(.*?)"', paper)
names = re.findall('"f14":"(.*?)"', paper)
Price = re.findall('"f2":(.*?),', paper)
Updown = re.findall('"f3":(.*?),', paper)
Updownnumber = re.findall('"f4":(.*?),', paper)
Trade = re.findall('"f5":(.*?),', paper)
Tradenumber = re.findall('"f6":(.*?),', paper)
Swing = re.findall('"f7":(.*?),', paper)
Highest = re.findall('"f15":(.*?),', paper)
Lowest = re.findall('"f16":(.*?),', paper)
Today = re.findall('"f17":(.*?),', paper)
Yesterday = re.findall('"f18":(.*?),', paper)
# 将数据加入列表进行后续处理
for i in range(len(Code)):
results.append(
[i + 1, Code[i], names[i], Price[i], Updown[i], Updownnumber[i], Trade[i], Tradenumber[i], Swing[i],
Highest[i], Lowest[i], Today[i], Yesterday[i]])
for result in results:
item = StockItem()
item["i"] = result[0] # 序号
item["f12"] = result[1] # 股票代码
item["f14"] = result[2] # 股票名称
item["f2"] = result[3] # 最新价
item["f3"] = result[4] # 涨跌幅
item["f4"] = result[5] # 涨跌额
item["f5"] = result[6] # 成交量
item["f6"] = result[7] # 成交额
item["f7"] = result[8] # 振幅
item["f15"] = result[9] # 最高
item["f16"] = result[10] # 最低
item["f17"] = result[11] # 今开
item["f18"] = result[12] # 昨收
yield item
except Exception as e:
print(e)
数据项目类 items.py:
import scrapy
class StockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
i = scrapy.Field()
f12 = scrapy.Field()
f14 = scrapy.Field()
f2 = scrapy.Field()
f3 = scrapy.Field()
f4 = scrapy.Field()
f5 = scrapy.Field()
f6 = scrapy.Field()
f7 = scrapy.Field()
f15 = scrapy.Field()
f16 = scrapy.Field()
f17 = scrapy.Field()
f18 = scrapy.Field()
数据处理类 pipelines.py:
import pymysql
class ProjectTwoPipeline(object):
def open_spider(self, spider):
try:
self.con = pymysql.connect(host='localhost', port=3306, user='root', password='985211', charset='utf8')
self.cursor = self.con.cursor()
self.cursor.execute("CREATE DATABASE IF NOT EXISTS stocks")
self.cursor.execute("USE stocks")
self.cursor.execute("CREATE TABLE IF NOT EXISTS stocks(Num varchar(16), Code varchar(16),names varchar(16),Price varchar(16),Updown varchar(16),Updownnumber varchar(16),Trade varchar(16),Tradenumber varchar(16),Swing varchar(16),Highest varchar(16),Lowest varchar(16),Today varchar(16),Yesterday varchar(16))")
self.opened = True
print("opened")
except Exception as e:
print(e)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print('%-8s %-6s %-8s %6s %10s %18s %10s %10s %12s %15s %15s %16s %10s' % (
'序号', '代码', '名称', '最新价', '涨跌幅(%)', '跌涨额(¥)', '成交量(手)', '成交额(¥)',
'振幅(%)', '最高', '最低', '今收', '昨收'))
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute("INSERT INTO stocks VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(item["i"],item["f12"],item["f14"],item["f2"],item["f3"],item["f4"],item["f5"],
item["f6"],item["f7"],item["f15"],item["f16"],item["f17"],item["f18"]))
print('%-8s %-10s %-10s %6s %10s %15s %15s %18s %12s %15s %15s %18s %12s' %(item["i"],item["f12"],
item["f14"],item["f2"],item["f3"],item["f4"],item["f5"],item["f6"],item["f7"],
item["f15"],item["f16"],item["f17"],item["f18"]))
return item
except Exception as err:
print(err)
执行爬虫程序 run.py:
from scrapy import cmdline
# mySpider 为爬虫程序name
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
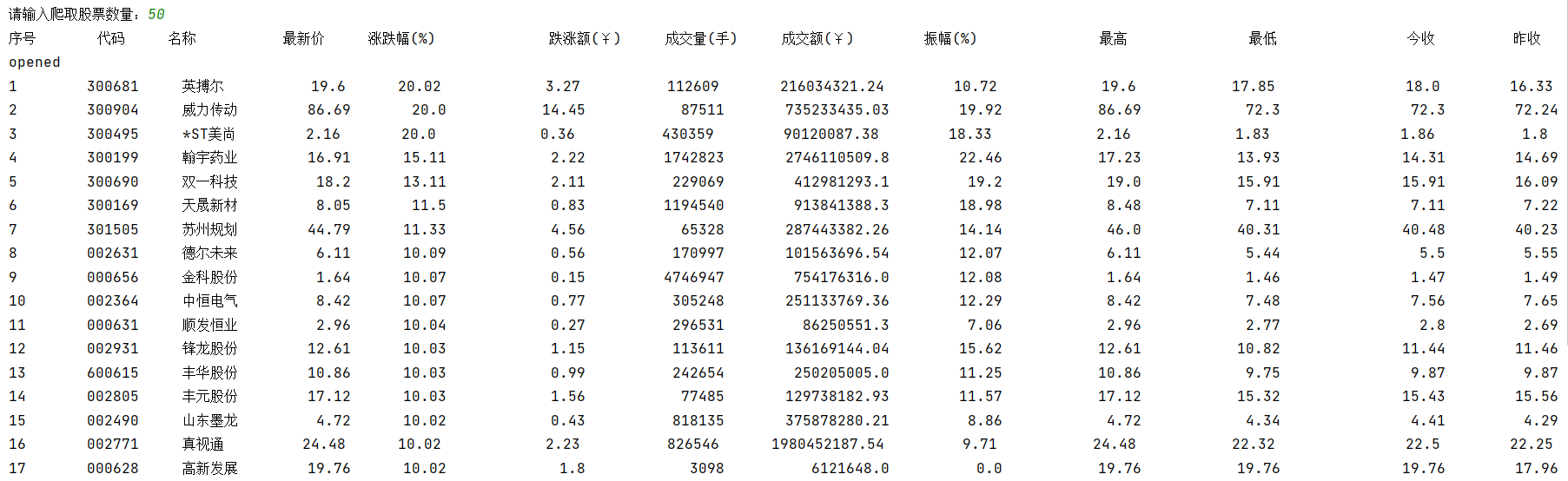
o运行结果:
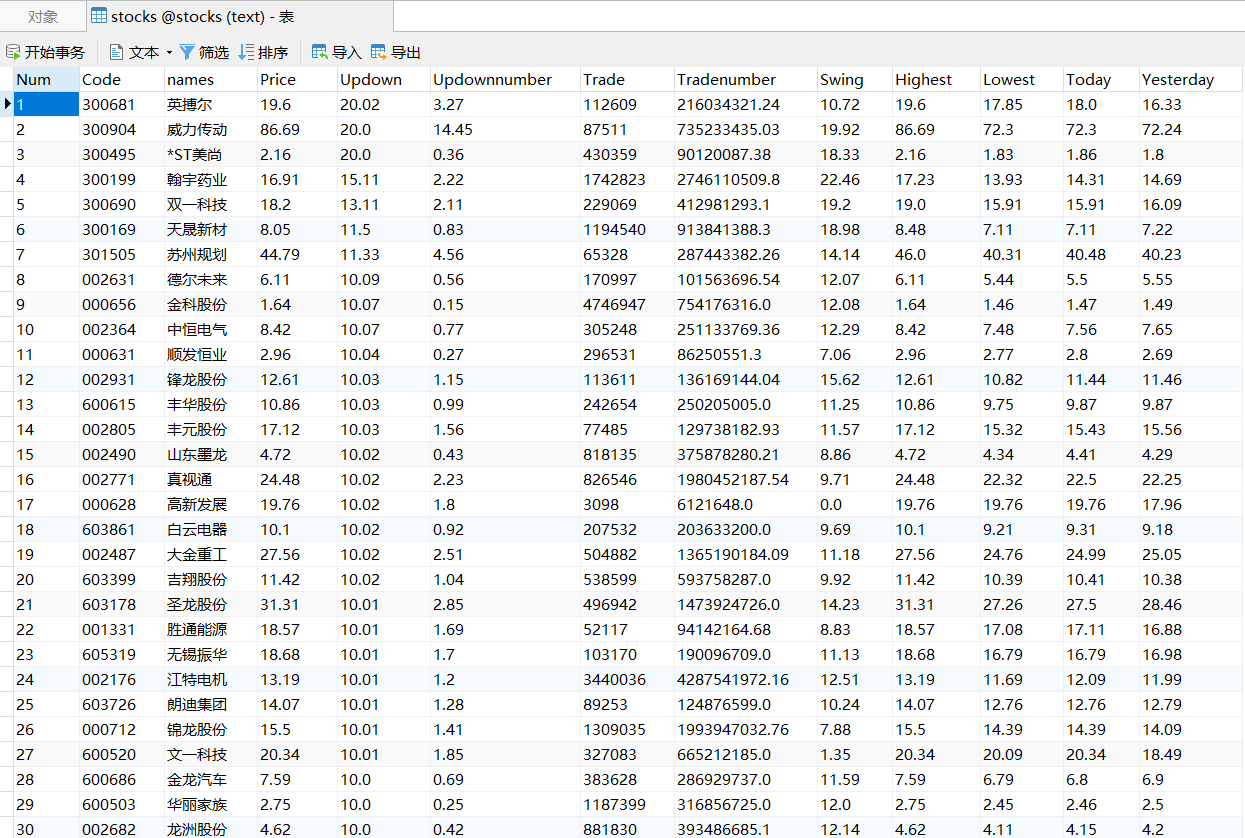
o查看MySQL数据库:
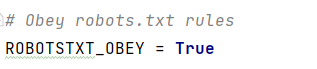
o问题与解决:
settings.py文件默认是True,遵守robots.txt文件中的协议,遵守允许爬取的范围。
当使用默认配置运行程序时,无法正常爬取到数据。

通俗来说, robots.txt 是遵循 Robot协议 的一个文件,它保存在网站的服务器中,它的作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页 不希望 你进行爬取收录。在Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
当然,我们并不是在做搜索引擎,而且在某些情况下我们想要获取的内容恰恰是被 robots.txt 所禁止访问的。所以,某些时候,我们就要将此配置项设置为 False ,拒绝遵守 Robot协议 !
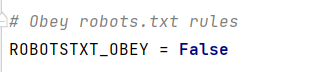
配置项设置为 False,运行程序即可爬取到所需数据。
(2)心得体会
此次实验通过使用scrapy框架爬取股票数据,再次巩固了scrapy框架基础知识,加深了对scrapy框架的理解,同时复习了re正则表达式,并了解scrapy框架不同配置。
作业③
(1)实验内容
o要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:
中国银行网:https://www.boc.cn/sourcedb/whpj/
o输出信息:(MySQL数据库存储和输出格式)

oGitee 文件夹链接:
o核心代码文件配置:
配置文件 setting.py:
# Obey robots.txt rules
#默认是True,遵守robots.txt文件中的协议,遵守允许爬取的范围。
#设置为False,是不遵守robo协议文件。。。
ROBOTSTXT_OBEY = False
#把爬取的数据推送到 pipelines 的 ProjectThreePipeline 类中
ITEM_PIPELINES = {
"project_three.pipelines.ProjectThreePipeline": 300
}
scrapy爬虫程序 mySpider.py:
from bs4 import UnicodeDammit
from scrapy.selector import Selector
import scrapy
from project_three.items import MoneyItem
class mySpider(scrapy.Spider):
name="mySpider"
start_urls=[]
url = "https://www.boc.cn/sourcedb/whpj/"
start_urls.append(url)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = Selector(text=data)
lis = selector.xpath("//table[@align='left']/tr")
for i in range(1, len(lis)):
Currency = lis[i].xpath("./td[position()=1]/text()").extract_first()
TBP=lis[i].xpath("./td[position()=2]/text()").extract_first()
CBP=lis[i].xpath("./td[position()=3]/text()").extract_first()
TSP=lis[i].xpath("./td[position()=4]/text()").extract_first()
CSP=lis[i].xpath("./td[position()=5]/text()").extract_first()
Time=lis[i].xpath("./td[position()=7]/text()").extract_first()
item = MoneyItem()
item["Currency"]=Currency if Currency else ""
item["TBP"] = TBP if TBP else ""
item["CBP"] = CBP if CBP else ""
item["TSP"] = TSP if TSP else ""
item["CSP"] = CSP if CSP else ""
item["Time"] = Time if Time else ""
yield item
except Exception as err:
print(err)
数据项目类 items.py:
import scrapy
class MoneyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency=scrapy.Field()
TBP=scrapy.Field()
CBP=scrapy.Field()
TSP=scrapy.Field()
CSP=scrapy.Field()
Time=scrapy.Field()
数据处理类 pipelines.py:
import pymysql
class ProjectThreePipeline(object):
def open_spider(self, spider):
try:
self.con = pymysql.connect(host='localhost', port=3306, user='root', password='985211', charset='utf8')
self.cursor = self.con.cursor()
self.cursor.execute("CREATE DATABASE IF NOT EXISTS money")
self.cursor.execute("USE money")
self.cursor.execute("CREATE TABLE IF NOT EXISTS money( Currency varchar(32), TBP varchar(8),CBP varchar(8), TSP varchar(8), CSP varchar(8), Time varchar(24))")
self.opened = True
print("opened")
except Exception as e:
print(e)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute("INSERT INTO money VALUES (%s,%s,%s,%s,%s,%s)",
(item["Currency"],item["TBP"],item["CBP"],
item["TSP"],item["CSP"],item["Time"]))
print('%15s %15s %15s %15s %15s %25s'%(item["Currency"],item["TBP"],item["CBP"],item["TSP"],item["CSP"],item["Time"]))
return item
except Exception as err:
print(err)
执行爬虫程序 run.py:
from scrapy import cmdline
# mySpider 为爬虫程序name
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
o运行结果:
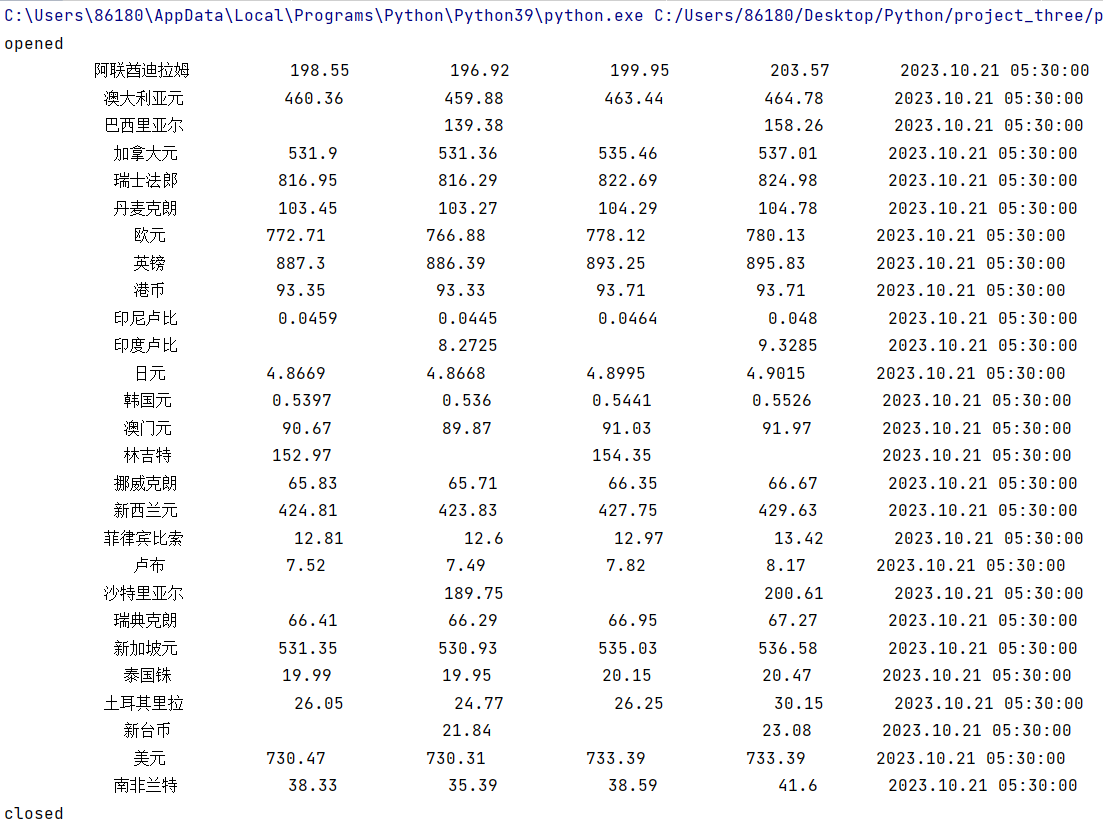
o查看MySQL数据库:
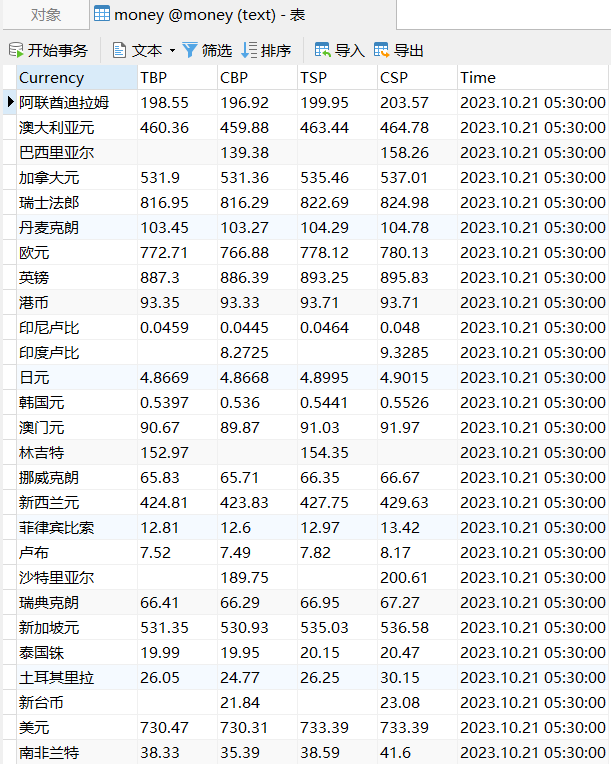
(2)心得体会
此次实验通过使用scrapy框架爬取中行汇率数据,再次巩固了scrapy框架基础知识,加深了对scrapy框架的理解,同时巩固了Xpath的使用。