目录
资料参考地址1: HashMap源码学习笔记
资料参考地址2: jdk8之HashMap resize方法详解(深入讲解为什么1.8中扩容后的元素新位置为原位置+原数组长度)
资料参考地址3:HashMap 容量为什么总是为 2 的次幂?
putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
//尾插法
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
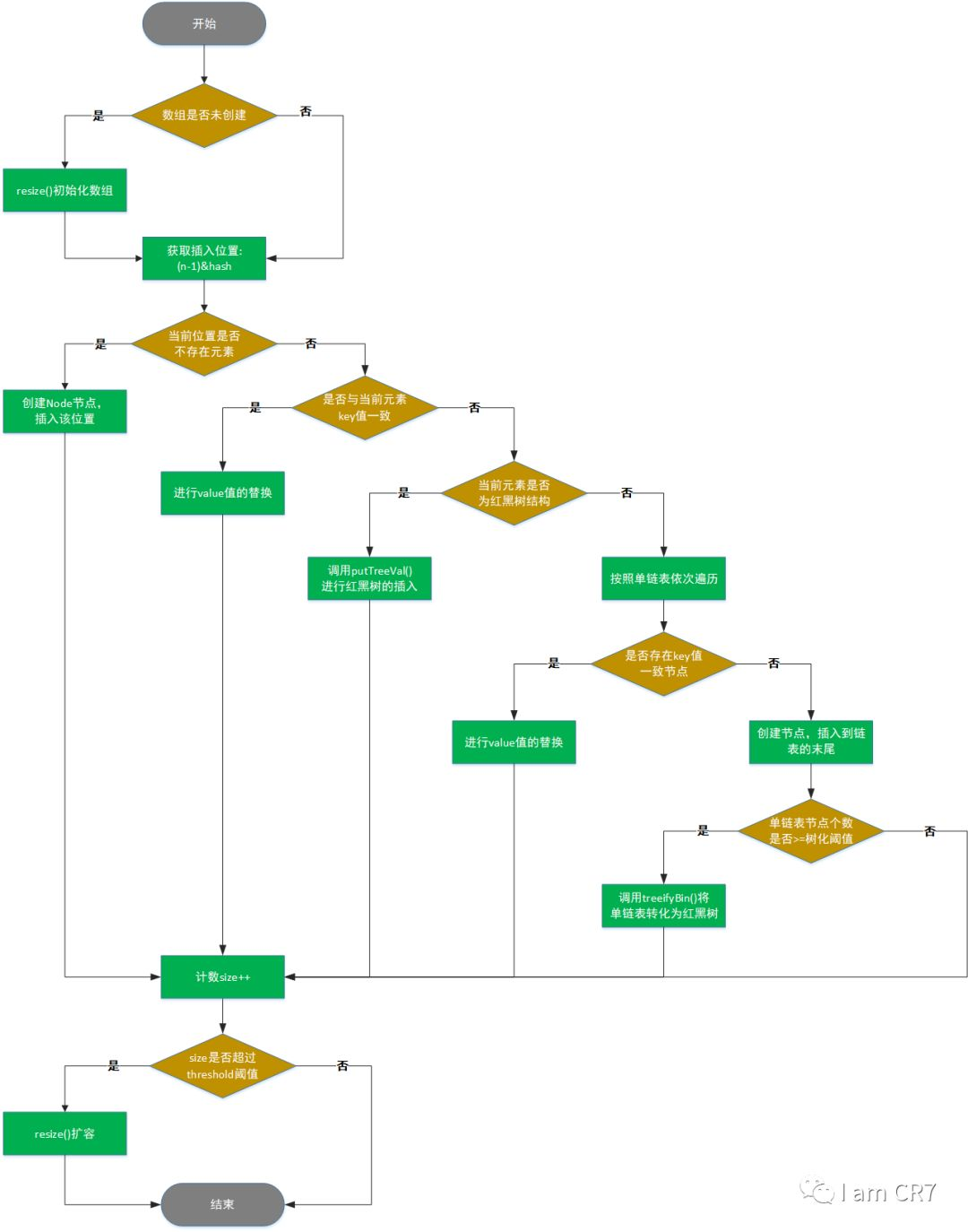
流程
- 如果table为null,则代表第一次插入元素,需要进行首次扩容,此时n为首次扩容后的长度
- 计算键值对在table表中的索引位置
- 判断索引位置是否有元素,如果没有元素,则直接将元素插入该位置,如果有元素,且key值相同,则覆盖该元素。
- 如果有元素但key值不相同,则判断是否为红黑树,如果为红黑树则在红黑树插入
- 如果不为红黑树则遍历该元素对应的链表,找到key值相同的元素并覆盖,然后退出,如果没有找到该元素,则在链表尾部新建一个节点(尾插法),jdk1.7为头插法。
- 如果插入节点成功,判断链表长度是否大于树化阈值,大于则转化为红黑树
- 最后判断数组长度是否大于扩容阈值,大于则进行扩容
resize(重点)
首次调用扩容方法流程图

非首次调用扩容方法
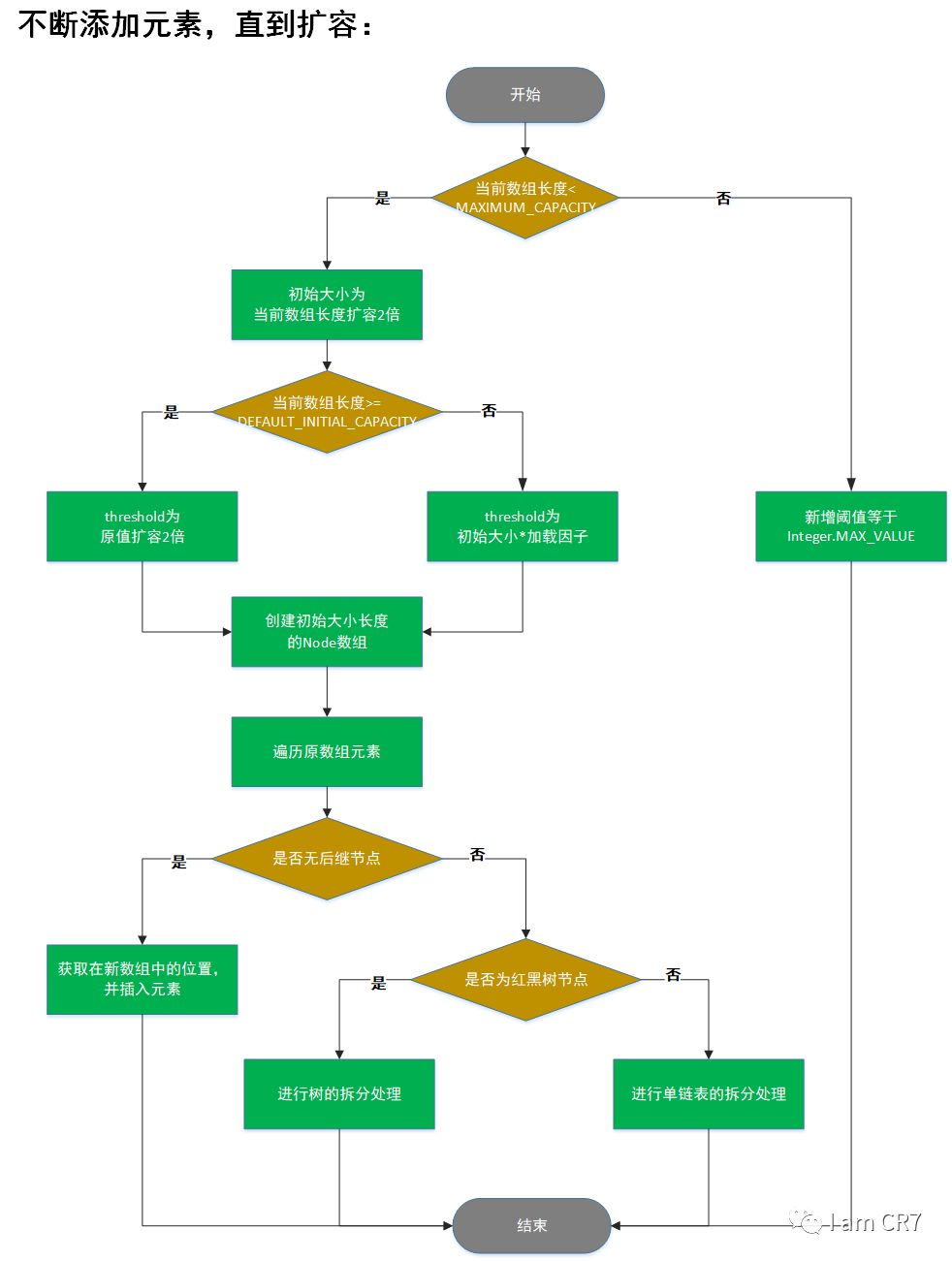
resize方法的作用
- 当数组并未初始化时,对数组进行初始化;
- 若数组已经初始化,则对数组进行扩容,也就是创建一个两倍大小的新数组,并将原来的元素放入新数组中;
resize关键代码
经过rehash之后,元素的位置要么是在原位置,要么是在原位置加原数组长度的位置。
单链表拆分
判断元素在扩容后的位置
确保它们均匀地分布在新的内部数组中
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
//判断元素在扩容后在低位还是高位(原来的位置还是新的位置)
if ((e.hash & oldCap) == 0) {
//低位
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
低位放到原来的位置,高位放在原位置加原数组长度的位置
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
红黑树拆分
作用和单链表一样,都是判断并放置元素在新数组中的位置
else if (e instanceof HashMap.TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
ps
jdk1.8中在计算新位置的时候并没有跟1.7中一样重新进行hash运算,而是用了原位置+原数组长度这样一种很巧妙的方式,而这个结果与hash运算得到的结果是一致的,只是会更块。
至于为什么新位置要么是原位置,要么是原位置+原数组长度的位置是由于每次扩容相当于数组长度的高位多了一个1,新的hash运算取决于hashCode在这一位上的值是0还是1,如果是0则无需变化位置,如果是1则位置为原位置+原数组长度的位置
面试题
HashTable 的区别
- HashMap 是线程不安全的,HashTable是线程安全的。
- HashMap 允许 key 和 Vale 是 null,但是只允许一个 key 为 null,且这个元素存放在哈希表 0 角标位置。 HashTable 不允许key、value 是 null
- HashMap 内部使用hash(Object key)扰动函数对 key 的 hashCode 进行扰动后作为 hash 值。HashTable 是直接使用 key 的 hashCode() 返回值作为 hash 值。
- HashMap默认容量为 2^4 且容量一定是 2^n ; HashTable 默认容量是11,不一定是 2^n
- HashTable 取哈希桶下标是直接用模运算,扩容时新容量是原来的2倍+1。HashMap 在扩容的时候是原来的两倍,且哈希桶的下标使用 &运算代替了取模。
为何数组容量必须是2次幂?
索引计算公式为i = (n - 1) & hash,如果n为2次幂,那么n-1的低位就全是1,哈希值进行与操作时可以保证低位的值不变,从而保证分布均匀,效果等同于hash%n;
- 是2次幂位能保证 (n - 1) & hash=hash%n一定成立而位与运算比取余运算要高效的多。
- 保证索引在范围内