前言
对于测试人员而言,不管是进行性能测试还是自动化测试,验证码的处理都是棘手的存在,在WEB应用中,大部分系统在用户登录的时候都要求用户输入验证码,且验证码的种类繁多,如纯数字、纯字母、汉子组合、数学题运算、滑动图标、图片、短信、邮箱、语音等。
既然要实现验证码的处理操作,那么就需要了解验证码的作用和实现原理,才能更好的实现
在很多的网站中,尤其是在注册登录的时候基本都会嵌入验证码功能,其作用是能有效的防止恶意的注册和登录。因为每次刷新后验证码都不同,这就可以排除用病毒或者软件自动申请注册用户和自动登录的操作,基于此,可以减少网站的并发量。
程序员会通过一系列的代码处理在服务端生成验证码,然后将其发送给客户端,客户端最终会以图像的格式进行显示(当然会对图像进行处理:添加干预、添加干扰像素、添加噪点等)。客户端提交显示的验证码,服务端会接受并进行对比,若对比失败则不能实现注册登录操作。反之,成功后跳转至相应界面。
根据验证码的实现原理,可以给出以下几种自动化测试中处理验证码的方式。
- 去掉验证码
- 设置万能验证码
- 只保留一个验证码(固定验证码)
- 光学字符识别
- 打码平台识别
- 记录cookie
正文
1、去掉验证码
去掉验证码操作是所有实现验证码处理方式中最简单的。对于开发人员而言,只需要将与验证码有关的代码注释掉即可。当然此方法如果是在测试环境中是可以的,但是在生成环境中,就不能轻易的去掉,这样会存在比较大的风险。
2、设置万能码
在生成环境中如果去掉验证码,必然会存在安全问题。为了能够解决在线系统的安全性问题,可以不注释验证码功能,只需让开发人员在程序中声明一个万能验证码,该验证码只提供给测试人员,用户无法获取。这样程序就可以使用万能码进行验证,从而完成操作。
3、只保留一个验证码
如果是图片资源,实际就是在指定的文件夹资源中随机抽取一张,只需要将服务器上的所有图片删除只保留一张即可,相当于固定验证码。(在生产环境不宜使用)
4、光学字符识别
光学字符识别实际就是通过Python-tesseract模块来只能只能识别图片中的验证码。Python-tesseract表示光学字符识别Tesseract OCR引擎对应的Python封装类,它能够读取任何常规的图片文件,如JPG\GIF\PNG\TIFF等,先如今由于验证码的形式繁多,所以光学字符的识别率非常低。
5、打码平台识别
通过主流的打码平台完成,如斐斐、超人、图鉴等
6、记录cookie
如果登录页面存在验证码,还可以在浏览器中添加登录成功时所携带的cookie来跳过登录,这是比较有意思的一种方式。例如,在第一次登录某网站时,可以勾选“记住密码”选项。当下次再访问这个网站的时候就处于登录状态了。这样其实也绕过了验证码问题,这个“记住密码”,其实就是将密码记录在了浏览器的cookie中。selenium中可以通过add_cookie()方法将用户名、密码的登录信息写入浏览器的cookie中,当再次访问网站服务时,服务器只需要读取浏览器的cookie就可以完成登录。
此处着重介绍后三种验证码的处理方式
光学字符识别
使用pycharm或者pip命令安装第三方模块pytessract和图像处理库
pip install pytesseract
pip install Pillow
注意:Python 2.X版本使用的库是PIL,但是在Python 3.X版本中图像处理库必须安装Pillow或者Pillow-PIL
安装OCR识别库,可通过官网地址进行下载,:Home · UB-Mannheim/tesseract Wiki (github.com)
默认安装,并将安装路径手动配置到环境变量中。
完成上述操作之后,就可以实现简单的识别了。简单识别的一般思路就是通过图片降噪、图片切割,最后输出图像文本等。其中图片降噪的含义就是将图片中一些不需要的信息全部去除,如背景、干扰像素、干扰线等,只留下需要识别的文字,所以让图片变成二进制点阵最好。
如果验证码是彩色背景,其实是把每个像素都放在一个五维的空间里,这五个维度分别是X Y R G B 其中X、Y代表的就是这个像素的二维平面坐标,R、G、B代表的是这个像素所对应的颜色。
灰度处理
把彩色图像转化为灰度图像,RGB转化为HSI彩色空间,采用L分量
from PIL import Image image = Image.open('image.png') ima_new = image.convert('L') ima_new.show()
图像分割
常用方法:二值化处理。指的是在二值化图像时,将大于某个临界灰度值的像素设置为灰度的极大值,把小于这个值的像素灰度设为灰度的极小值,其值设置范围一般为0~1.由于阈值选择的不同,二值化的算法也有所不同,主要分固定阈值和自适应阈值,这里选择固定阈值。
from PIL import Image image = Image.open('image.png') ima_new = image.point(lambda x: 0 if x < 143 else 255) ima_new.show()
get_result = pytesseract.image_to_string(ima_new)
print(get_result)
转成黑白图片
如果验证码图片的干扰过多,很容易识别错误。为了解决识别率低的问题,可以增强图片显示效果,或者将其转换成黑白的,这样可以使其识别率提升不少,完整代码如下:
from PIL import Image from PIL import ImageEnhance from pytesseract import pytesseract image = Image.open('image.png') ima_new = image.convert('L') ima_new = image.point(lambda x: 0 if x < 143 else 255) # ima_new.show() enhancer = ImageEnhance.Contrast(ima_new) image2 = enhancer.enhance(4) get_result = pytesseract.image_to_string(image2) print(get_result)
基于cookie登录操作
# ----------------------------------- ''' @Author:C_N_Candy @Date :2023/6/29 14:57 @File :cookie_login.py @Desc : ''' # ------------------------------------ from selenium import webdriver class CookieLogin(object): def __init__(self): self.driver = webdriver.Chrome() self.driver.get('http://192.168.235.128/index.php/Admin/login/index.html') # 建立session链接 self.driver.add_cookie({'name': 'login', 'value': 'cookie'}) # 基于此session执行操作 self.driver.refresh() # 刷新 self.driver.get('http://192.168.235.128/index.php/Admin/login/index.html') if __name__ == '__main__': login = CookieLogin()
想要获得验证码,那就先要获取到验证码的图片,实例代码:
使用电脑自带的画图工具,获取截图中的验证码图片X、Y轴坐标
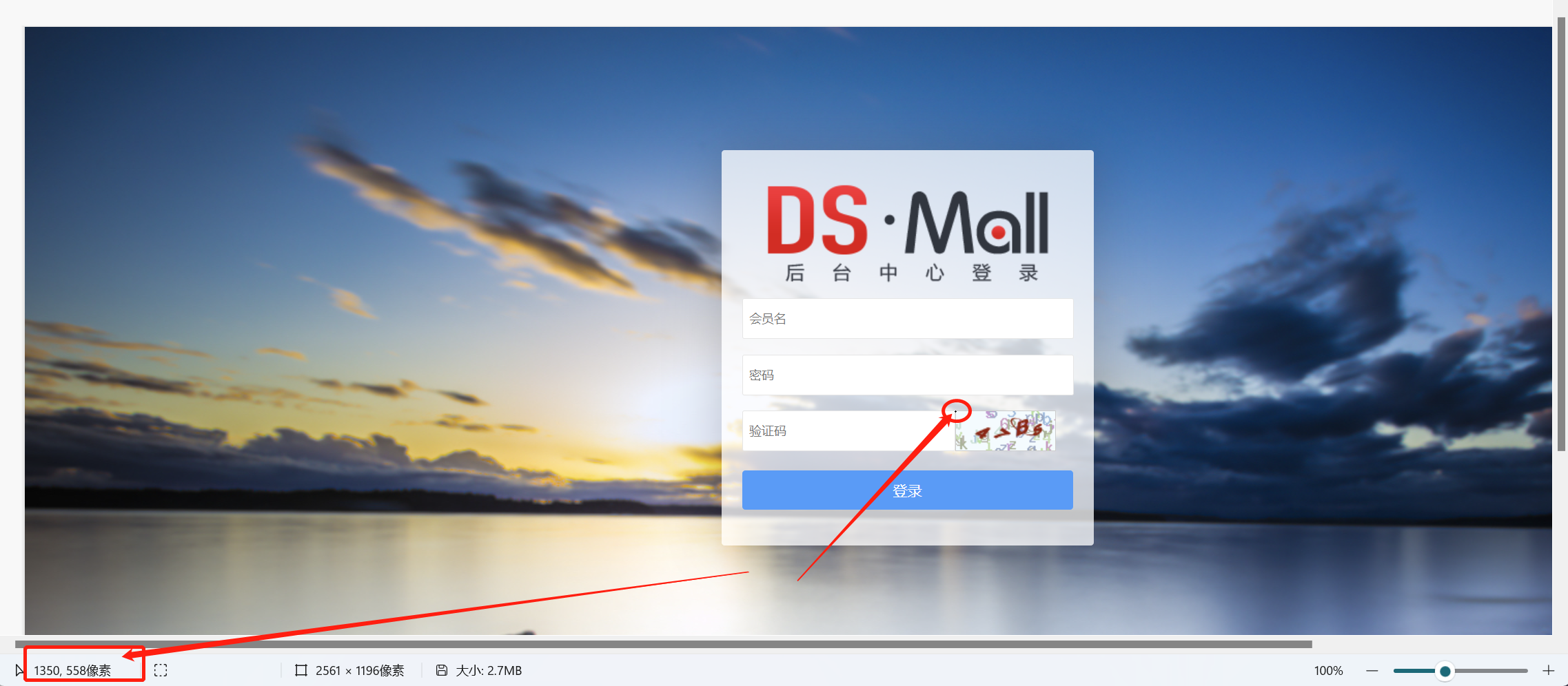
# ----------------------------------- ''' @Author:C_N_Candy @Date :2023/6/29 15:06 @File :get_code_image.py @Desc :获取页面中的验证码图片 ''' # ------------------------------------ import time from selenium import webdriver from selenium.webdriver.common.by import By from PIL import Image class GetCodeImage(object): def __init__(self): url = 'http://192.168.235.128/index.php/Admin/login/index.html' self.driver = webdriver.Chrome() self.driver.maximize_window() self.driver.get(url) self.driver.implicitly_wait(10) def get_code_image(self): self.driver.get_screenshot_as_file('index.png') # 需要获取验证码的位置 code_element = self.driver.find_element(By.ID, 'change_captcha') # 这里输出定位到的x,y坐标,根据画图工具查看的坐标,进行相加或者相减,这个数值不是固定的,每个人的电脑型号不同分辨率不同,坐标不同 # loct = self.driver.find_element(By.ID, 'change_captcha').location # print(loct) # 输出{'x': 900, 'y': 372},画图工具显示的坐标是{'x': 1350, 'y': 558},补上相差的数据450,186 # 获取验证码图片在截图中的坐标位置和大小 left = code_element.location['x']+450 upper = code_element.location['y']+186 right = code_element.size['width']+52 + left bottom = code_element.size['height']+12 + upper # 创建image对象,打开之前的截图 image = Image.open('index.png') # 根据坐标点截取图片,另存为 code_image = image.crop((left, upper, right, bottom)) code_image.save('code.png') print("Success") self.driver.quit() if __name__ == '__main__': get_code_png = GetCodeImage() get_code_png.get_code_image()

注意:
# 这里输出定位到的x,y坐标,根据画图工具查看的坐标,进行相加或者相减,这个数值不是固定的,每个人的电脑型号不同分辨率不同,坐标不同 # loct = self.driver.find_element(By.ID, 'change_captcha').location # print(loct) # 输出{'x': 900, 'y': 372},画图工具显示的坐标是{'x': 1350, 'y': 558},补上相差的数据450,186
获取到图片之后,通过打码平台完成验证码的读取,每个打码平台都有对应的开发文档,根据所提供的的API接口进行调用,在这里使用图鉴打码平台来完成:http://www.ttshitu.com/
访问图鉴打码平台官网,打开开发者文档,选择Python接口,会有相应的脚本显示,直接调用并做相应的信息修改即可。
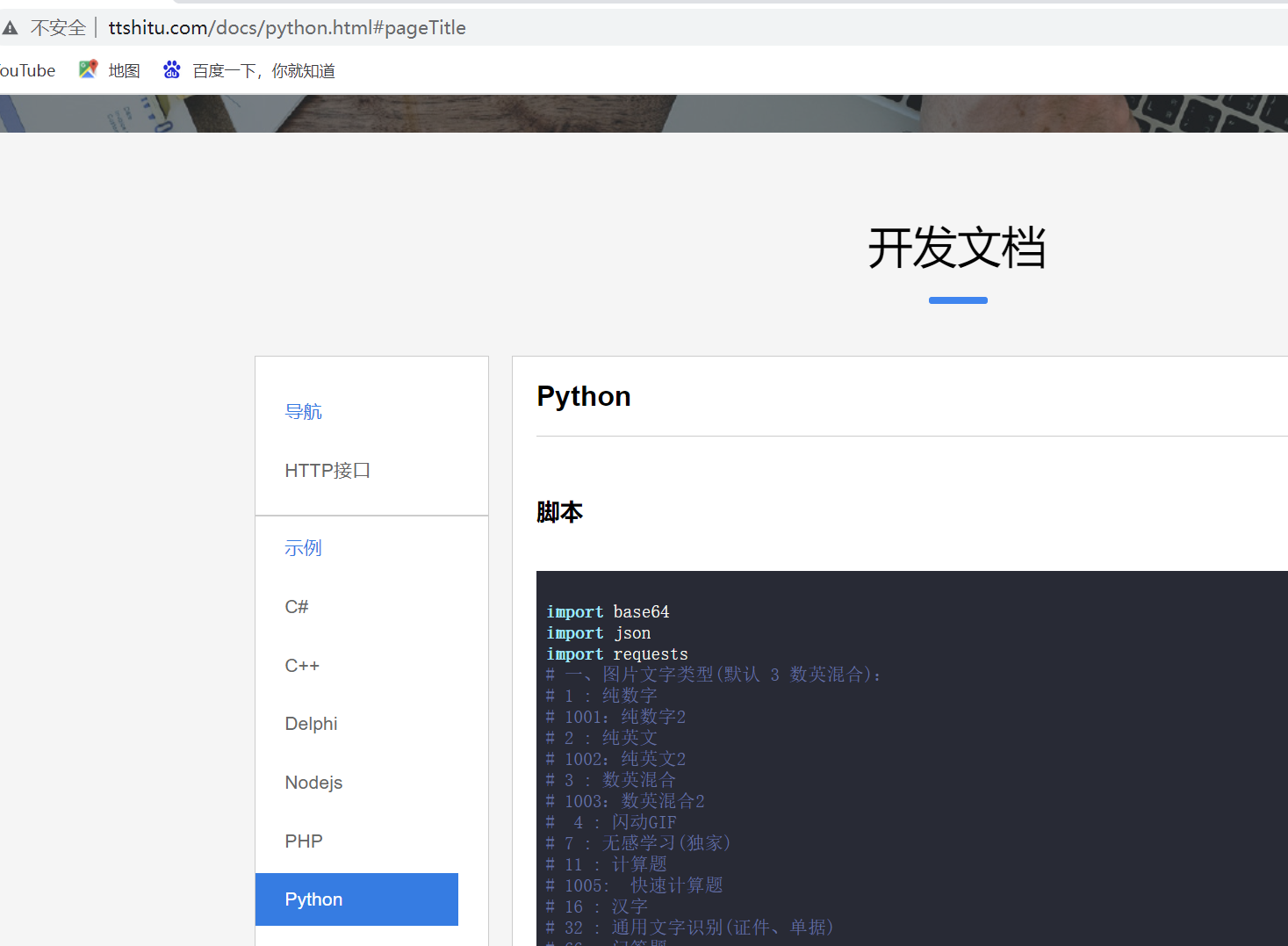
实现代码如下:
# ----------------------------------- ''' @Author:C_N_Candy @Date :2023/6/29 19:04 @File :Cloud_Code.py @Desc :将图片发送给打码平台,返回验证码 ''' # ------------------------------------ import json import requests import base64 from io import BytesIO from PIL import Image from sys import version_info """ version_info是sys模块中的一个函数,主要用于返回你当前所使用的Python版本号。 version_info是一个包含了版本号5个组成部分的元祖,这5个部分分别是主要版本号(major)、次要版本号(minor)、微型版本号(micro)、发布级别(releaselevel)和序列号(serial) """ def base64_api(username, password, image): # 图片转换成JPEG格式 img = image.convert('RGB') buffered = BytesIO() img.save(buffered, format="JPEG") # 判断当前Python版本(版本不一样,使用的编码要求不同) if version_info.major >= 3: b64 = str(base64.b64encode(buffered.getvalue()), encoding='utf-8') else: b64 = base64.b64encode(buffered.getvalue()) data = {"username": username, "password": password, "image": b64} result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text) if result["success"]: return result["data"]["result"] else: return result["message"] return "" if __name__ == '__main__': img_path = "code.png" img = Image.open(img_path) result = base64_api(username='图鉴打码平台的账号', password="密码", image=img) print(result)

DSMALL商城后台登录,验证码处理完整代码
# ----------------------------------- ''' @Author:C_N_Candy @Date :2023/6/29 18:44 @File :Dsmall_Login.py @Desc :登录商城后台,验证码处理 ''' # ------------------------------------ from BaseMoudule.Base_Class import BaseClass from Check_Code.Cloud_Code import base64_api from selenium.webdriver.common.by import By from PIL import Image class Dsmall_Login(BaseClass): def __init__(self, url, browserType): super().__init__(url, browserType) def get_code_image(self): self.driver.get_screenshot_as_file('index.png') # 需要获取验证码的位置 code_element = self.driver.find_element(By.ID, 'change_captcha') # 获取验证码图片在截图中的坐标位置和大小 left = code_element.location['x'] + 450 upper = code_element.location['y'] + 186 right = code_element.size['width'] + 52 + left bottom = code_element.size['height'] + 12 + upper # 创建image对象,打开之前的截图 image = Image.open('index.png') # 根据坐标点截取图片,另存为 code_image = image.crop((left, upper, right, bottom)) code_image.save('code.png') # print("Success") # self.driver.quit() # 把验证码发送给第三方服务器识别,获取并输入验证码 def get_code(self, username, password, image): get_code = base64_api(username, password, image) print(get_code) self.driver.find_element(By.NAME, "captcha").send_keys(get_code) if __name__ == '__main__': ds = Dsmall_Login("http://192.168.235.128/index.php/Admin/login/index.html", "Chrome") ds.get_code_image() ds.get_code(username='打码平台账号', password='密码', image=Image.open("code.png"))
参考扩展:
利用selenium实现验证码获取并验证 - 知乎 (zhihu.com)
快速查看图片中某点的像素 X、Y 坐标_图片坐标_罐装三斤的博客-CSDN博客
python3定位并识别图片验证码实现自动登录_python识别矢量图验证码,自动输入_茶几mzcy的博客-CSDN博客