这个阶段的内容,采用概率论的思想,从样本里面学到知识(训练模型),并对新来的样本进行预测。
主要算法:贝叶斯分类算法、隐含马尔可夫模型、最大熵模型、条件随机场。
通过本阶段学习,掌握NLP自然语言处理的一些基本算法,本阶段的理解对于后续完成NLP大项目很重要。
1. 复习条件概率
给定事件B的基础上,事件A发生的概率: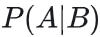
也就是在已经拿到某些证据下,再推断某个事件发生的可能性有多大,
比如说,我们认为在年终的时候有50%的可能会得到升职;如果我们从老板那里得到了正面且积极的反馈(老板,表扬了你一下),我们可能会上调这个概率值,反之会下调。
随着我们获得信息的增多,我们不断调整我们的估计值,直到它接近真正的答案。
再比如,一个人的血液检查结果为阳性,那么他得A病的概率有多大?再加上已有的经验,得A病的条件下,血液检查结果呈阳性的概率为95%。
所以一个人如果拿到血液检查结果为阳性的报告,心里是不是会很慌呢?
总结一下:
即在给定事件下,知道证据发生的概率 即P(B|A) --------得A病的条件下,血液检查结果呈阳性的概率为95%
贝叶斯公式可以在知道P(B|A)的情况下,可以计算出P(A|B)
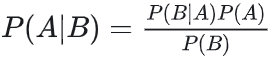
解释:
P(A|B)称为后验概率(posterior),这是我们需要结合先验概率和证据计算之后才能知道的。----血液检查结果为阳性,那么他得A病的概率有多大?
P(B|A)称为似然(likelihood),在事件A发生的情况下,事件B(或evidence)的概率有多大。----已有的经验,得A病的条件下,血液检查结果呈阳性的概率为95%。
P(A)称为先验概率(prior), 事件A发生的概率有多大。----什么证据都没有,得A病的概率
P(B)称为证据(evidence),即无论事件如何,事件B(或evidence)的可能性有多大 -- 所有人群中 不管其他的事件 血液呈阳性的概率
即将一些先验的信念(贝叶斯认为概率是对某种信念的度量)与观察到的数据结合起来,来更新信念,这个过程也称为“学习”
经常将其表述为在给定观测数据D的情况下,探究假设H:
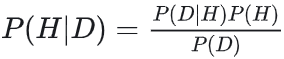
如何计算evidence,即P(D):
P(D)的计算可以理解为从联合分布P(H,D)求边缘分布P(D)
离散型: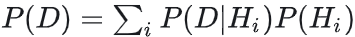
连续型: 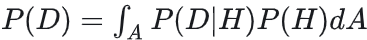
例子:
在不同时间点,入睡的概率
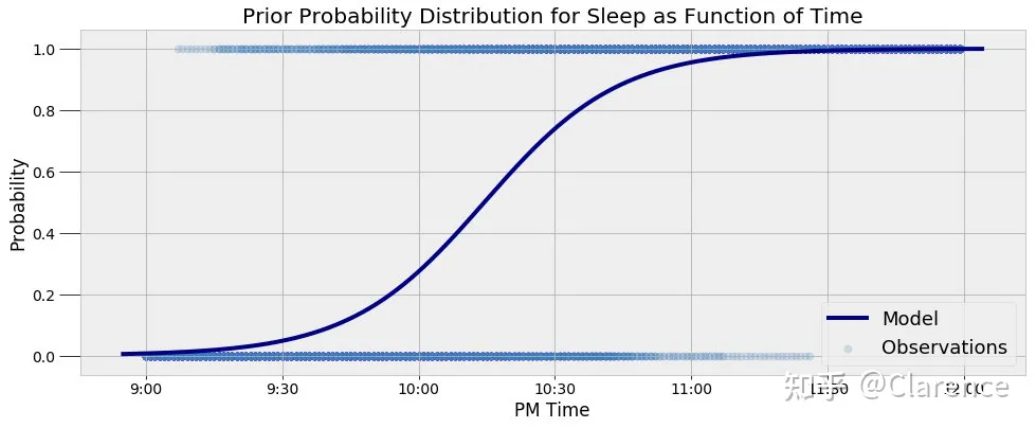
比如在九点及以前,入睡的概率为几乎为0,在十点入睡的概率为27.34,12点之后几乎全部入睡,
已知房间里面的灯是开的,再来推断主人入睡的概率,
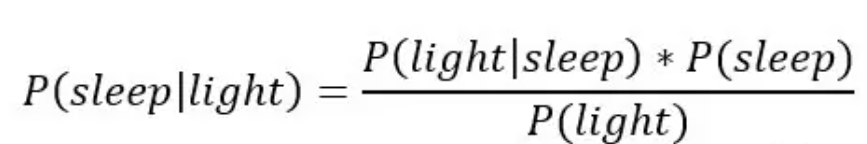
左边就是我们要计算的,在某个点在开灯或关灯的条件下,入睡的概率。
某个时间点入睡的概率,P(sleep),已经由上面的图片给出,作为先验概率。
入睡的情况下,灯开着的概率为0.01,则有入睡的条件下,灯关闭(p(-light))的概率为0.99
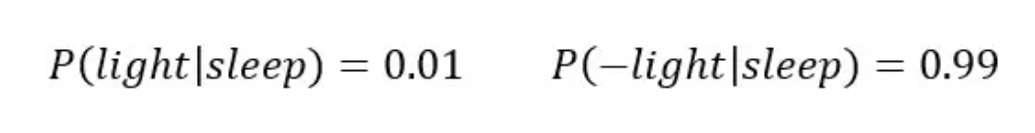
现在缺少的是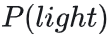
它表示灯开着的概率。这个概率有两部分组成,即在入睡的情况下,灯开着的概率, +, 未入睡的情况下,灯开着的概率。
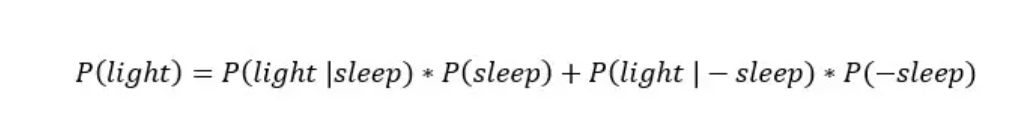
假设未入睡的情况下,灯开着的概率为80%。
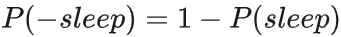
因此:
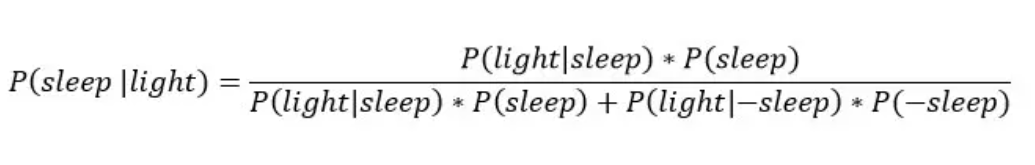
如果我们想要计算在十点半,灯开着的情况下,入睡的概率,则有以下等式:

知道灯是开着的,这使我们对入睡的概率估计从70%以上急剧下降到3.42%。通过这个例子,可以了解贝叶斯公式的作用与强大之处。
练习:
设某种病菌在人口中的带菌率为0.03,当检查时,由于技术及操作的不完善以及种种特殊原因,使带菌者未必能检出阳性反应,同样不带菌者也能呈现阳性反应。
假定P(阳性|带菌)=0.99,P(阴性|带菌)=0.01,P(阳性|不带菌)=0.05,P(阴性|不带菌)=0.95,假设某人检出阳性,问他带菌的概率是多少?

人群中带菌的概率为0.03,在已知检出阳性的证据下,带菌的概率提高到0.38.
2. 正式进入
概率图模型最为"精彩"的部分就是能够用简洁清晰的图,表达概率生成的关系。
先通过GMM感受概率图,
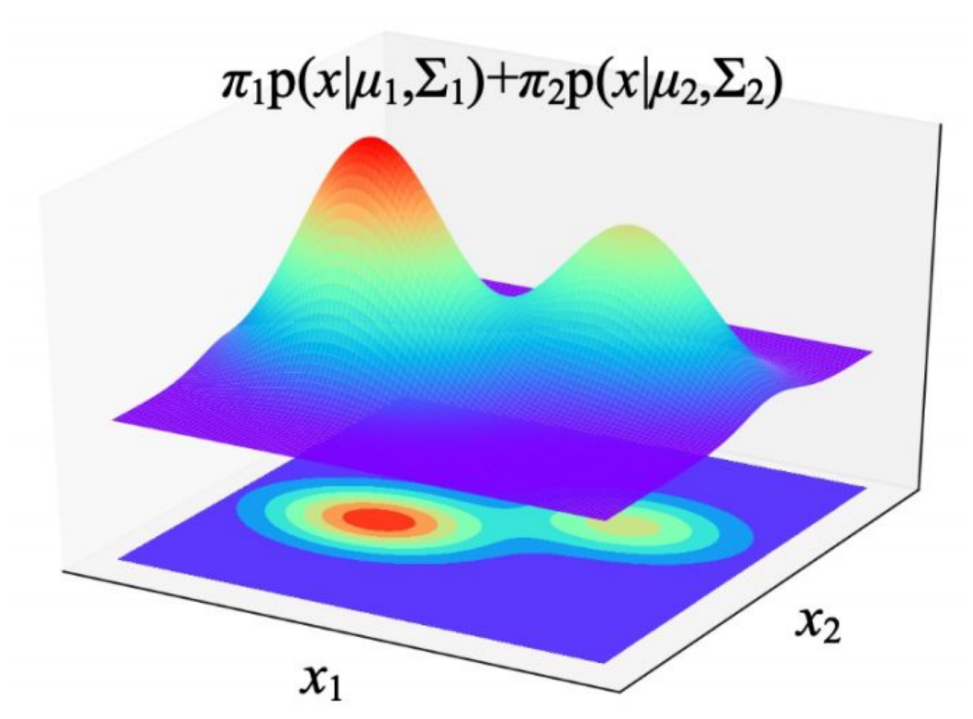
样本空间(X1,X2) 其背后的分布是有2个 高斯模型 混合在一起来决定的,即GMM是多个高斯分布叠加而成的加权求和的结果。
一天样本的概率分布:
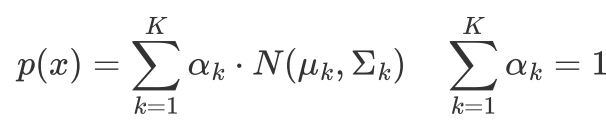
换个角度来 采用抽样的方式来认识GMM,
假设样本是从不同k个高斯分布生成的,每个样本是从某个高斯分布抽样得到的抽中这K个高斯分布的概率不一样,
用一个隐变量定义这种抽样概率大小,隐变量是服从某种概率分布的离散随机变量:
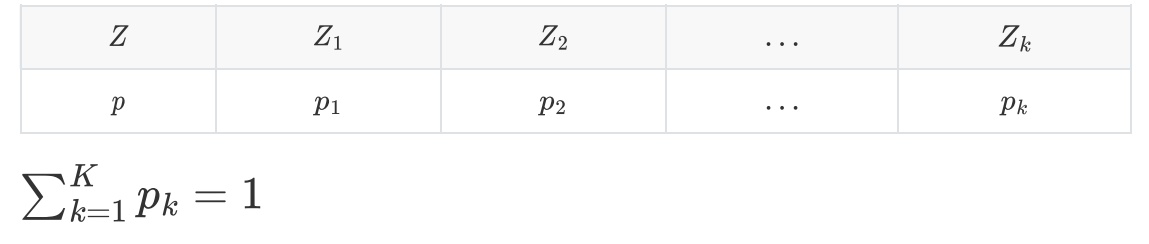
样本生成过程分俩步:
- 选定某个状态隐变量Z --(概率p1,... , pk抽取z1, ..., zk中的一个)
- 从该隐变量对应的高斯分布随机生成一个样本
重复上述过程m次;得到一共m个样本,这m个样本来自这K个高斯分布。
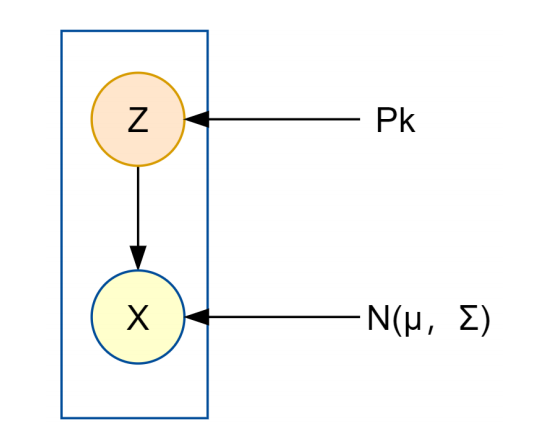
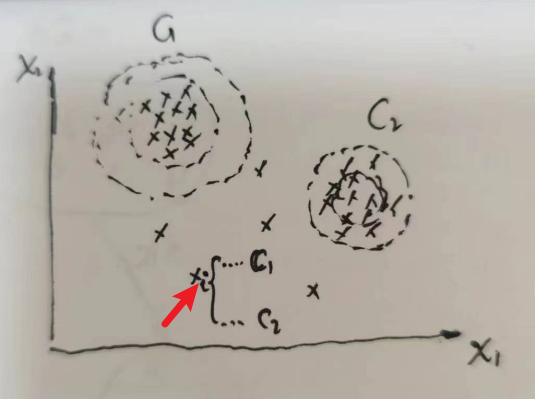
该模型由两个高斯分布混合而成,样本Xi既可以来自于C1 也可以来自于C2
3. 生成式 与判别式
假设可观测的变量集合为X,需要预测的变量集合为Y,其它的变量集合为Z。
生成式模型:对联合分布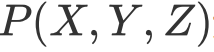 进行建模,在给定观测集合X
进行建模,在给定观测集合X
的条件下,通过计算边缘分布来得到对变量集合Y的推断,
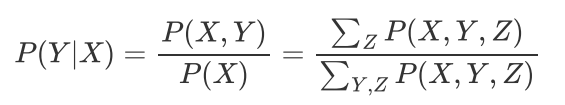
例如上面举的例子,血液检测阳性患A病的概率,晚上10点知道点灯开的情况下,预测已入睡的概率
判别式模型:
直接对条件概率分布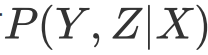
进行建模,然后消掉无关变量Z就可以得到对变量集合Y的预测,即:
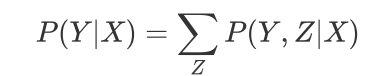
先预告一下,
朴素贝叶斯、隐马尔可夫模型属于生成式模型,---- 需要借助中间证据Z
最大熵模型、最大熵马尔可夫模型、条件随机场属于判别式模型;----直接输出属于哪一类。