1. 源码编译
1.1 为什么要编译?
a. Native Library 本地库
Native Library,一般译为本地库或原生库,是由 C/C++ 编写的动态库(*.so),并通过 JNI 机制为 Java 层提供接口。应用一般会出于性能、安全等角度考虑将相关逻辑用 C/C++ 实现并编译为库的形式提供接口,供上层或其他模块调用。
Hadoop 是使用 Java 语言开发的,但是有一些需求和操作并不适合使用 Java,所以就引入了本地库(Native Library)的概念。说白了,就是 Hadoop 的某些功能,必须通过 JNI 来协调 Java 类文件和 Native 代码生成的库文件一起才能工作。系统要运行 Native 代码,首先要将 Native 编译成目标 CPU 架构的动态库文件。
不同的处理器架构,需要编译出相应平台的动态库文件(Linux 下对应 [.so] 文件,Windows 下对应 [.dll] 文件),才能被正确的执行。
Hadoop 本地库主要组件有:
- 压缩编解码器(bzip2,lz4,snappy,zlib)
- HDFS 的本地 IO 实用程序,用于 HDFS 短路本地读取和集中式缓存管理
- CRC32 校验和实现
b. 源码修改
Hadoop 属于 Apache 开源软件,如果用户在使用中发觉某些组件或者功能不能满足于自己的企业需求,可以基于开源协议对 Hadoop 源码进行修改,改成符合自己性能要求。此时也是需要重新编译源码然后部署安装。
1.2 Linux 编译
(1)安装编译相关的依赖
$ yum install gcc gcc-c++ kernel-devel
$ yum install autoconf automake libtool curl
$ yum install lzo-devel zlib-devel openssl openssl-devel ncurses-devel
$ yum install bzip2 bzip2-devel lzo lzo-devel lzop libXtst
(2)手动安装 cmake
$ yum erase cmake
$ tar zxvf cmake-3.13.5.tar.gz
$ cd /export/server/cmake-3.13.5
$ ./configure
$ make && make install
$ cmake -version
(3)手动安装 snappy
$ cd /usr/local/lib
$ rm -rf libsnappy*
$ tar zxvf snappy-1.1.3.tar.gz
$ cd snappy-1.1.3
$ ./configure
$ make && make install
$ ls -lh /usr/local/lib | grep snappy
(4)安装配置 JDK8、Maven3.5+
# 解压安装包
$ tar zxvf apache-maven-3.5.4-bin.tar.gz
# 配置环境变量
$ vim /etc/profile
export MAVEN_HOME=/export/server/apache-maven-3.5.4
export MAVEN_OPTS="-Xms4096m -Xmx4096m"
export PATH=:$MAVEN_HOME/bin:$PATH
source /etc/profile
# 验证是否安装成功
$ mvn -v
Apache Maven 3.5.4
# 添加maven 阿里云仓库地址 加快国内编译速度
$ vim apache-maven-3.5.4/conf/settings.xml
<mirrors>
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
(5)安装 ProtocolBuffer 2.5.0
$ tar zxvf protobuf-2.5.0.tar.gz
$ cd protobuf-2.5.0
$ ./configure
$ make && make install # 我在这一步一直报错...
$ protoc --version
(6)编译 Hadoop
$ tar zxvf hadoop-3.1.4-src.tar.gz
$ cd hadoop-3.1.4-src
$ mvn clean package -Pdist,native -DskipTests -Dtar -Dbundle.snappy -Dsnappy.lib=/usr/local/lib
# - Pdist,native 把重新编译生成的hadoop动态库
# - DskipTests 跳过测试
# - Dtar 最后把文件以tar打包
# - Dbundle.snappy 添加snappy压缩支持(默认官网下载的是不支持的)
# - Dsnappy.lib=/usr/local/lib 指snappy在编译机器上安装后的库路径
(7)编译后安装包路径:hadoop-3.1.4-src/hadoop-dist/target
1.3 本地编译
源码地址:https://archive.apache.org/dist/hadoop/core/hadoop-3.1.3/hadoop-3.1.3.tar.gz
(1)解压后打开主目录下的 BUILDING.txt 文件,可以看到编译所需环境
Requirements:
* Unix System
* JDK 1.8
* Maven 3.3 or later
* ProtocolBuffer 2.5.0
* CMake 3.1 or newer (if compiling native code)
* Zlib devel (if compiling native code)
* openssl devel (if compiling native hadoop-pipes and to get the best HDFS encryption performance)
* Linux FUSE (Filesystem in Userspace) version 2.6 or above (if compiling fuse_dfs)
* Internet connection for first build (to fetch all Maven and Hadoop dependencies)
* python (for releasedocs)
* bats (for shell code testing)
* Node.js / bower / Ember-cli (for YARN UI v2 building)
(2)安装 JDK、Maven
略
(3)安装 openssl
brew install openssl
(4)安装 cmake
brew install cmake
(5)安装 protocbuf-2.5.0
// => 1. 下载安装包:https://github.com/protocolbuffers/protobuf/releases/tag/v2.5.0
// => 2. 解压并修改文件 ./src/google/protobuf/stubs/platform_macros.h
#elif defined(__arm64__)
#define GOOGLE_PROTOBUF_ARCH_ARM 1
#define GOOGLE_PROTOBUF_ARCH_64_BIT 1
#else /* 在该文件中定位到这两行,然后在这两行上面添加上面这三行 */
#error Host architecture was not detected as supported by protobuf
// => 3. 依次执行如下命令进行安装
./configure // 默认安装到
make
make check
sudo make install
protoc --version // 查看是否安装成功
(6)在 JAVA_HOME 目录下创建 Classes 目录,并在 JAVA_HOME 目录下执行软链接:
sudo ln -s ./lib/tools.jar ./Classes/classes.jar
(7)进入下载好的 hadoop3.0.* 源码目录下执行:
mvn package -Pdist,native -DskipTests -Dtar
这一步也在报错,反正我看我是甭想编译了哈。
2. HDFS 源码结构分析
2.1 HDFS 工程结构

(1)hadoop-hdfs
在 hadoop-hdfs 模块中,主要实现了网络、传输协议、JN、安全、server 服务等相关功能,是 hdfs 的核心模块。并且提供了 hdfs web UI 页面功能的支撑。
(2)hadoop-hdfs-client
在 hadoop-hdfs-client 模块中,主要定义实现了和 hdfs 客户端相关的功能逻辑。
(3)hadoop-hdfs-httpfs
hadoop-hdfs-httpfs 模块主要实现了通过 HTTP 协议操作访问 hdfs 文件系统的相关功能。
HttpFS 是一种服务器,它提供到 HDFS 的 REST HTTP 网关,具有完整的文件系统读写功能。
HttpFS 可用于在运行不同 Hadoop 版本的群集之间传输数据(克服 RPC 版本问题),例如使用 Hadoop DistCP。

(4)hadoop-hdfs-native-client
hadoop-hdfs-native-client 模块定义了 hdfs 访问本地库的相关功能和逻辑。该模块主要是使用 C 语言进行编写,用于和本地库进行交互操作。
(5)hadoop-hdfs-nfs
hadoop-hdfs-nfs 模块是 Hadoop HDFS 的 NFS 实现。
NFS(Network File System)网络文件系统,能使使用者访问网络上别处的文件就像在使用自己的计算机一样。
(6)hadoop-hdfs-rbf
hadoop-hdfs-rbf 模块是 Hadoop3.0 之后的一个新的模块,主要实现了 RBF(Router-based Federation)功能:基于路由的 Federation 方案。
简单来说就是:HDFS 将路由信息放在了服务端来处理,而不是在客户端。以此完全做到对于客户端的透明。

2.2 HDFS 客户端核心类
a. Configuration
Provides access to configuration parameters.
Configuration 提供对配置参数的访问,通常称之为配置文件类。主要用于加载或者设定程序运行时相关的参数属性。
(1)Configuration 加载默认配置
在程序中打上断点,看一下新建 Configuration 对象的时候加载了什么:
public class HdfsConfiguration extends Configuration {
static {
addDeprecatedKeys();
// adds the default resources
Configuration.addDefaultResource("hdfs-default.xml");
Configuration.addDefaultResource("hdfs-site.xml");
}
// ...
}
(2)Configuration 加载用户设置
当到达 FileSystem.get(conf) 这一行代码的时候,可以发现用户通过 conf.set 设置的属性也会被加载。

b. FileSystem
FileSystem 类是一个通用的文件系统的抽象基类。具体来说它可以实现为一个分布式的文件系统,也可以实现为一个本地文件系统。所有的可能会使用到 HDFS 的用户代码在进行编写时都应该使用 FileSystem 对象。
代表本地文件系统的实现是 LocalFileSystem,代表分布式文件系统的实现是 DistributedFileSystem。当然针对其他 Hadoop 支持的文件系统也有不同的具体实现。因此 HDFS 客户端在进行读写操作之前,需要创建 FileSystem 对象的实例。
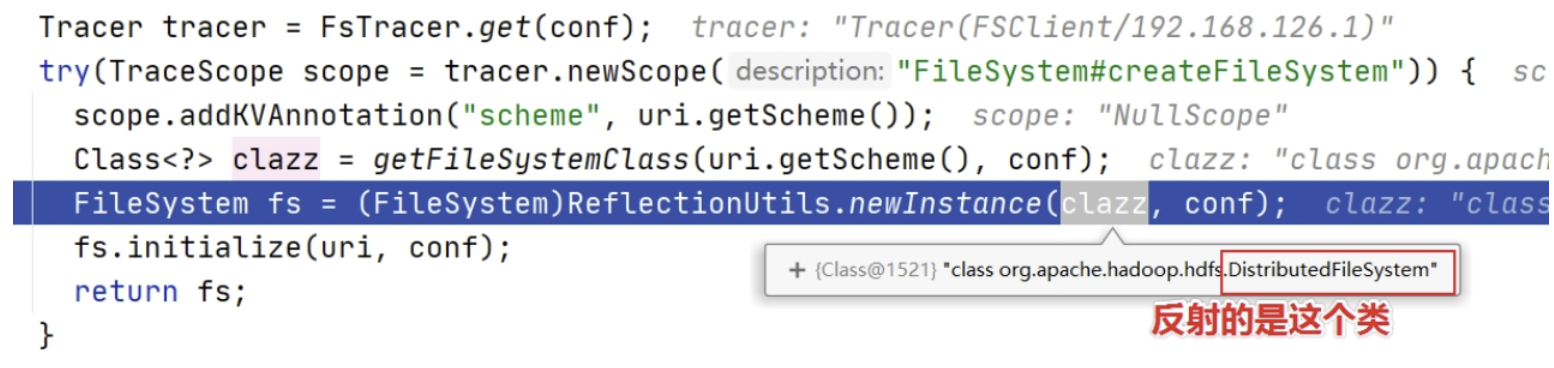
(1)获取 FileSystem 实例
经过方法的层层调用,最终找到了 FileSystem 对象是通过调用 getInternal() 方法得到的。

首先在 getInternal() 方法中调用了 createFileSystem() 方法:
原来,FileSystem 实例是通过反射的方式获得的,具体实现是通过调用反射工具类 ReflectionUtils 的 newInstance 方法并将 class 对象以及 Configuration 对象作为参数传入最终得到了 FileSystem 实例。
3. HDFS 通信协议
HDFS 作为一个分布式文件系统,它的某些流程是非常复杂的(例如读、写文件等典型流程),常常涉及数据节点、名字节点和客户端三者之间的配合、相互调用才能实现。为了降低节点间代码的耦合性,提高单个节点代码的内聚性, HDFS 将这些节点间的调用抽象成不同的接口。
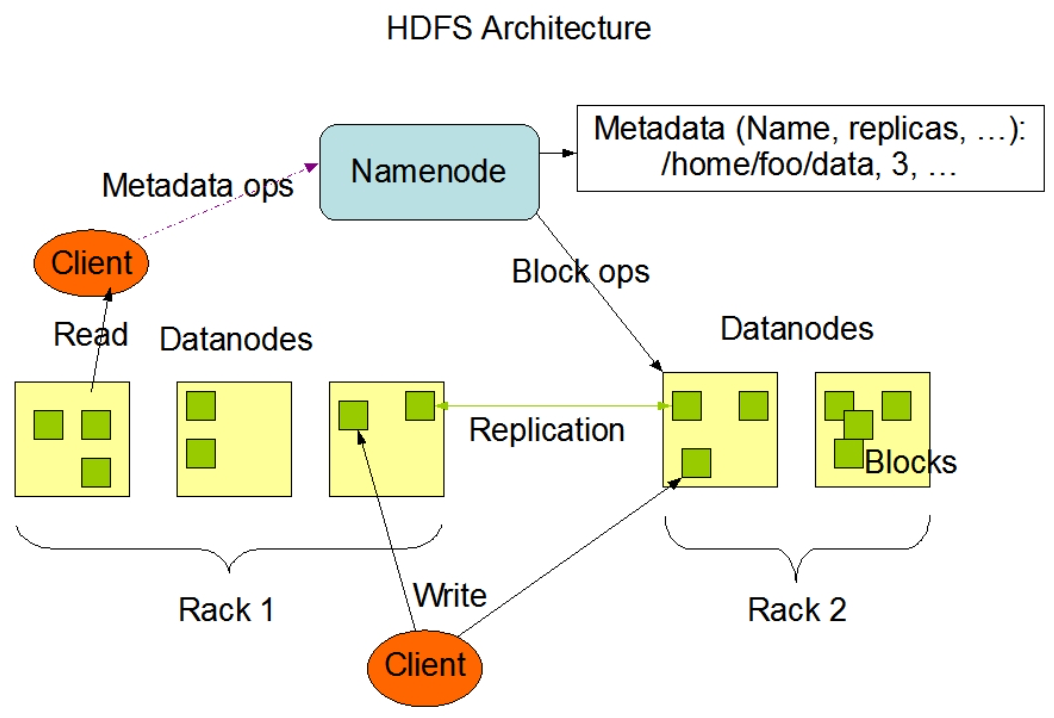
HDFS 节点间的接口主要有两种类型:
- Hadoop RPC 接口:基于 Hadoop RPC 框架实现的接口
- 流式接口:基于 TCP 或 HTTP 实现的接口
3.1 Hadoop RPC 接口
RPC 全称 Remote Procedure Call —— 远程过程调用。就是为了解决远程调用服务的一种技术,使得调用者像调用本地服务一样方便透明。
Hadoop RPC 调用使得 HDFS 进程能够像本地调用一样调用另一个进程中的方法,并且可以传递 Java 基本类型或者自定义类作为参数,同时接收返回值。如果远程进程在调用过程中出现异常,本地进程也会收到对应的异常。目前 Hadoop RPC 调用是基于 Protobuf 实现的。
Protobuf(Google Protocol Buffers)是 Google 提供一个具有高效的协议数据交换格式工具库(类似 Json),但相比于 Json,Protobuf 有更高的转化效率,时间效率和空间效率都是 JSON 的 3~5 倍。

- 【通信模块】传输 RPC 请求和响应的网络通信模块,可以基于 TCP 协议,也可以基于 UDP 协议,可以是同步,也可以是异步的。
- 【客户端 Stub 程序】服务器和客户端都包括 Stub 程序。在客户端,Stub 程序表现的就像本地程序一样,但底层却会将调用请求和参数序列化并通过通信模块发送给服务器。之后 Stub 程序等待服务器的响应信息,将响应信息反序列化并返回给请求程序。
- 【服务器端 Stub 程序】在服务器端,Stub 程序会将远程客户端发送的调用请求和参数反序列化,根据调用信息触发对应的服务程序,然后将服务程序返回的响应信息序列化并发回客户端。
- 【请求程序】请求程序会像调用本地方法一样调用客户端 Stub 程序,然后接收 Stub 程序返回的响应信息。
- 【服务程序】服务器会接收来自 Stub 程序的调用请求,执行对应的逻辑并返回执行结果。
Hadoop RPC 接口主要定义在 org.apache.hadoop.hdfs.protocol 包和 org.apache.hadoop.hdfs.server.protocol 包中,核心的接口有:ClientProtocol、ClientDatanodeProtocol、DatanodeProtocol。
a. ClientProtocol
ClientProtocol 定义了客户端与名字节点间的接口,这个接口定义的方法非常多,客户端对文件系统的所有操作都需要通过这个接口,同时客户端读、写文件等操作也需要先通过这个接口与 Namenode 协商之后,再进行数据块的读出和写入操作。
ClientProtocol 定义了所有由客户端发起的、由 Namenode 响应的操作。这个接口非常大,有 80 多个方法,核心的是:HDFS 文件读相关的操作、HDFS 文件写以及追加写的相关操作。
(1)读数据相关的方法
ClientProtocol 中与客户端读取文件相关的方法主要有两个: getBlockLocations() 和 reportBadBlocks()。
客户端会调用 ClientProtocol#getBlockLocations() 方法获取 HDFS 文件指定范围内所有数据块的位置信息。这个方法的参数是 HDFS 文件的文件名以及读取范围,返回值是文件指定范围内所有数据块的文件名以及它们的位置信息,使用 LocatedBlocks 对象封装。每个数据块的位置信息指的是存储这个数据块副本的所有 Datanode 的信息,这些 Datanode 会以与当前客户端的距离远近排序。
客户端读取数据时,会首先调用该方法获取 HDFS 文件的所有数据块的位置信息,然后客户端会根据这些位置信息从数据节点读取数据块。
客户端会调用 ClientProtocol#reportBadBlocks() 方法向 Namenode 汇报错误的数据块。当客户端从数据节点读取数据块且发现数据块的校验和并不正确时,就会调用这个方法向 Namenode 汇报这个错误的数据块信息。
(2)写、追加数据相关方法
在 HDFS 客户端操作中最重要的一部分就是写入一个新的 HDFS 文件,或者打开一个已有的 HDFS 文件并执行追加写操作。
ClientProtocol 中定义了 8 个方法支持 HDFS 文件的写操作: create()、 append()、 addBlock()、 complete(), abandonBlock()、getAddtionnalDatanodes()、updateBlockForPipeline() 和 updatePipeline()。
create() 方法用于在 HDFS 的文件系统目录树中创建一个新的空文件,创建的路径由 src 参数指定。这个空文件创建后对于其他的客户端是“可读”的,但是这些客户端不能删除、重命名或者移动这个文件,直到这个文件被关闭或者租约过期。客户端写一个新的文件时,会首先调用 create() 方法在文件系统目录树中创建一个空文件,然后调用 addBlock() 方法获取存储文件数据的数据块的位置信息,最后客户端就可以根据位置信息建立数据流管道,向数据节点写入数据了。
当客户端完成了整个文件的写入操作后,会调用 complete() 方法通知 Namenode。这个操作会提交新写入 HDFS 文件的所有数据块,当这些数据块的副本数量满足系统配置的最小副本系数(默认值为 1),也就是该文件的所有数据块至少有一个有效副本时, complete() 方法会返回 true,这时 Namenode 中文件的状态也会从构建中状态转换为正常状态;否则, complete() 会返回 false,客户端就需要重复调用 complete() 操作,直至该方法返回 true。
b. ClientDatanodeProtocol
客户端与数据节点间的接口。
ClientDatanodeProtocol 中定义的方法主要是用于客户端获取数据节点信息时调用,而真正的数据读写交互则是通过「流式接口」进行的。
ClientDatanodeProtocol 中定义的接口可以分为两部分:一部分是支持 HDFS 文件读取操作的,例如 getReplicaVisibleLength() 以及 getBlockLocalPathInfo();另一部分是支持 DFSAdmin 中与数据节点管理相关的命令。
重点关注第一部分。
(1)getReplicaVisibleLength(...)
客户端会调用 getReplicaVisibleLength() 方法从数据节点获取某个数据块副本真实的数据长度。
当客户端读取一个 HDFS 文件时,需要获取这个文件对应的所有数据块的长度,用于建立数据块的输入流,然后读取数据。但是 Namenode 元数据中文件的最后一个数据块长度与 Datanode 实际存储的可能不一致,所以客户端在创建输入流时就需要调用 getReplicaVisibleLength() 方法从 Datanode 获取这个数据块的真实长度。
(2)getBlockLocalPathInfo(...)
HDFS 对于本地读取,也就是 Client 和保存该数据块的 Datanode 在同一台物理机器上时,是有很多优化的。
Client 会调用 ClientProtocol#getBlockLocalPathInfo() 方法获取指定数据块文件以及数据块校验文件在当前节点上的本地路径,然后利用这个本地路径执行本地读取操作,而不是通过流式接口执行远程读取,这样也就大大优化了读取的性能。
c. DatanodeProtocol
Datanode 通过这个接口与 Namenode通信,同时 Namenode 会通过这个接口中方法的返回值向 Datanode 下发指令。
注意,这是 Namenode 与 Datanode 通信的唯一方式。这个接口非常重要,Datanode 会通过这个接口向 Namenode 注册、汇报数据块的全量以及增量的存储情况。同时,Namenode 也会通过这个接口中方法的返回值,将 Namenode 指令带回该数据块,根据这些指令,Datanode 会执行数据块的复制、删除以及恢复操作。
可以将 Datanode Protocol 定义的方法分为 3 种类型: Datanode 启动相关、心跳相关以及数据块读写相关。
(1)Datanode 启动相关:registerDatanode
(2)Datanode 心跳相关:sendHeartbeat
sendHeartbeat() 方法用于告诉 NameNode 该 DataNode 仍然有效,也包括一些 DataNode 状态信息。该方法的返回值是 HeartbeatResponse 类,类中封装了一个 DatanodeCommand 对象的数组。该数组中存放的就是 NameNode给DataNode 下发的指令:比如删除本地无效 block,或将 block 复制到其他 DataNode 等。
(3)Datanode 数据块汇报相关:blockReportblockReport
告知 NameNode 自己所有本地持有存储的块。该功能旨在上传所有本地存储的块。它在启动时被调用,然后在以后很少被调用(默认汇报间隔 6h)。
3.2 TCP/HTTP 流式接口
HDFS 除了定义 RPC 调用接口外,还定义了流式接口,流式接口底层是基于 TCP 或者 HTTP 实现的。
在 HDFS 中,流式接口包括了基于 TCP 的 DataTransferProtocol 接口,以及 HA 架构中 Active Namenode 和 Standby Namenode 之间的 HTTP 接口。
DataTransferProtocol 是用来描述写入或者读出 Datanode 上数据的基于 TCP 的流式接口,HDFS 客户端与数据节点以及数据节点与数据节点之间的数据块传输就是基于 DataTransferProtocol 接口实现的。
HDFS 没有采用 Hadoop RPC 来实现 HDFS 文件的读写功能,是因为 Hadoop RPC 框架的效率目前还不足以支撑超大文件的读写,而使用基于 TCP 的流式接口有利于批量处理数据,同时提高了数据的吞吐量。
DataTransferProtocol 中最重要的方法就是 readBlock() 和 writeBlock()。
- readBlock:从当前 Datanode 读取指定的数据块
- writeBlock:将指定数据块写入数据流管道(pipeLine)中
底层定义了用于发送 DataTransferProtocol 请求的 Sender 类,以及用于响应 DataTransferProtocol 请求的 Receiver 类。Sender 类和 Receiver 类都实现了 DataTransferProtocol 接口。
我们假设 DFSClient 发起了一个 DataTransferProtocol#readBlock() 操作,那么 DFSClient 会调用 Sender 将这个请求序列化,并传输给远端的 Receiver。远端的 Receiver 接收到这个请求后,会反序列化请求,然后调用代码,执行读取操作。

4. 数据读写流程分析
4.1 数据写入
public class HDFSWriteDemo {
public static void main(String[] args) throws IOException {
// 设置客户端用户身份:root 具备在hdfs读写权限
System.setProperty("HADOOP_USER_NAME", "root");
// 创建Conf对象
Configuration conf = new Configuration();
// 设置操作的文件系统是 HDFS,默认是file:///
conf.set("fs.defaultFS", "hdfs://node1:8020");
// 创建 FileSystem 对象(通用的文件系统的抽象基类)
FileSystem fs = FileSystem.get(conf);
// 设置文件输出的路径
Path path = new Path("/helloworld.txt");
// 调用 create 方法创建文件
FSDataOutputStream out = fs.create(path);
// 创建本地文件输入流
FileInputStream in = new FileInputStream("helloworld.txt");
// IO 工具类实现流对拷贝
IOUtils.copy(in, out);
// 关闭连接
fs.close();
}
}
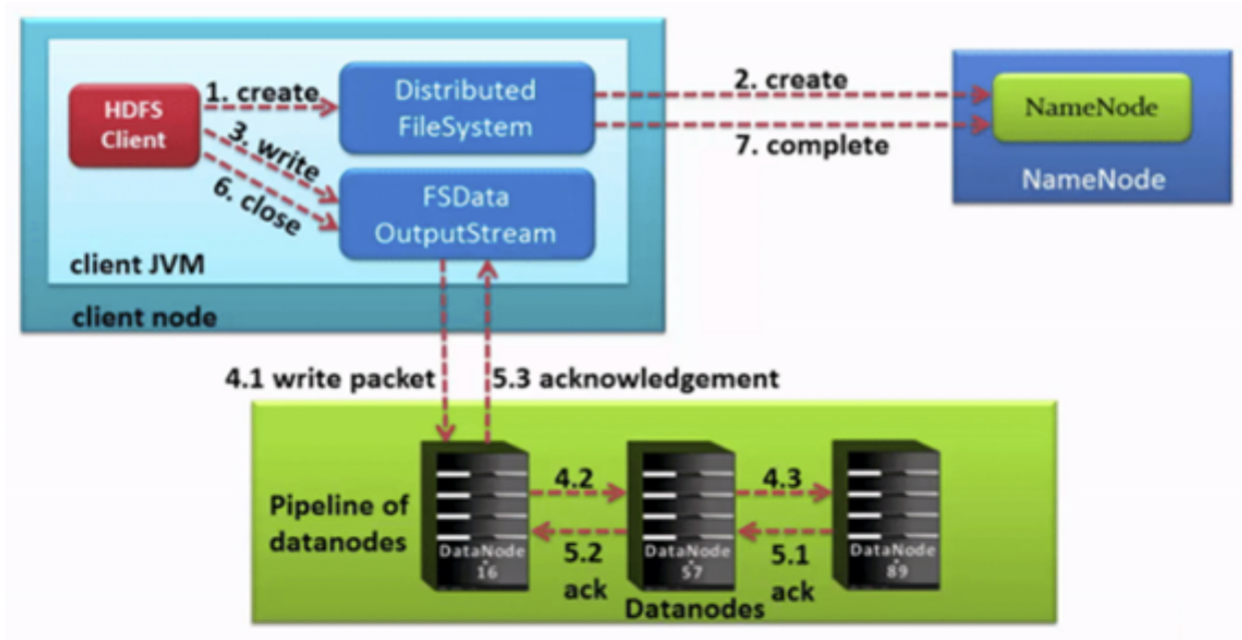
a. 客户端请求 NameNode
HDFS 客户端通过对 DistributedFileSystem 对象调用 create() 请求创建文件。DistributedFileSystem 为客户端返回 FSDataOutputStream 输出流对象。
通过源码注释可以发现 FSDataOutputStream 是一个包装类,所包装的是 DFSOutputStream。可以通过 create() 方法调用不断跟下去,可以发现最终的调用也验证了上述结论,返回的是 DFSOutputStream 。
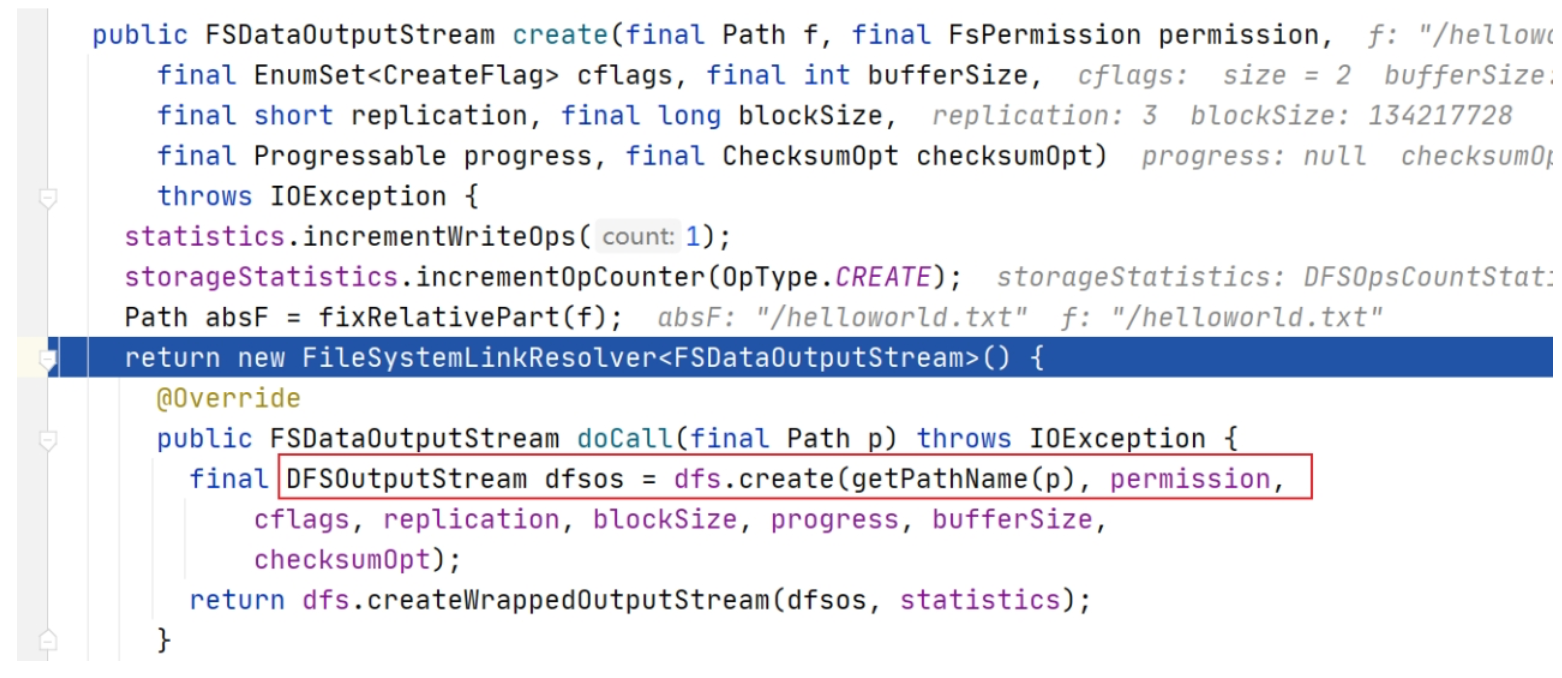
点进代码可以发现,DFSOutputStream 这个类是从 DFSClient 类的 create() 方法中返回过来的。

进来之后点进去发现,DFSClient 类中的 DFSOutputStream 实例对象是通过调用 DFSOutputStream 类的 newStreamForCreate() 方法产生的。
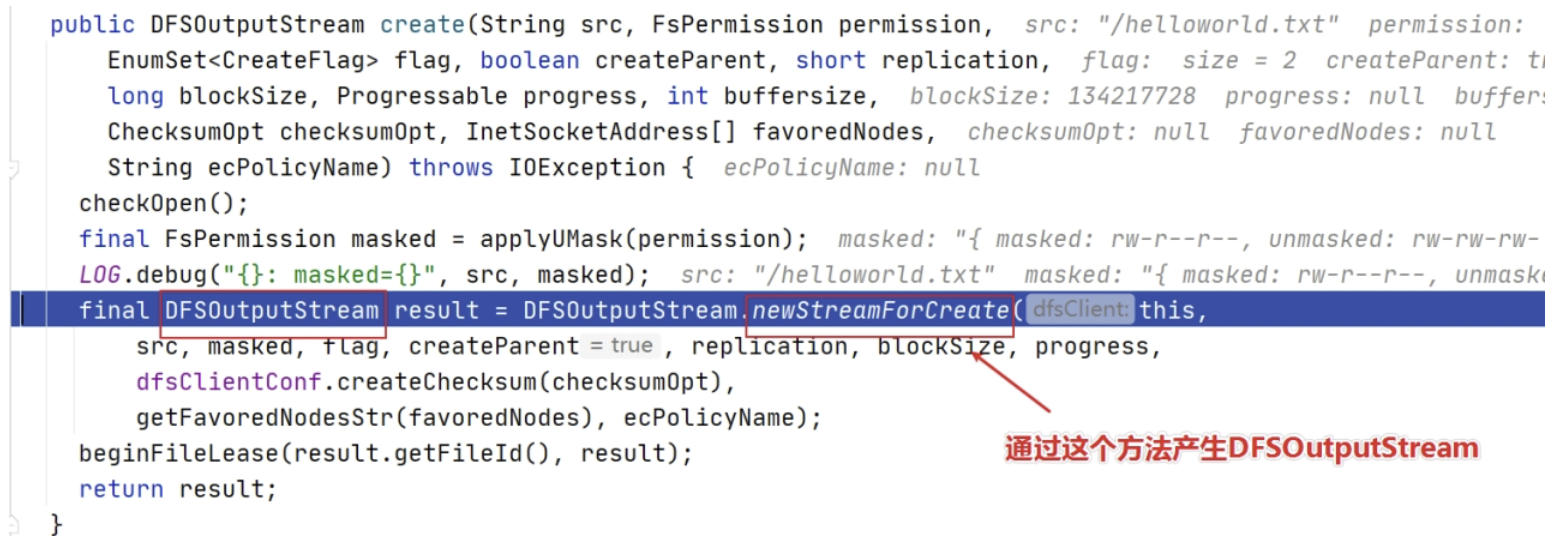
点击进入这个方法,找到了客户端请求 NameNode 新建元数据的关键代码。

代码 dfsClient.namenode.create 中 namenode 是 ClientProtocol 类实例。DFSClient 使用 ClientProtocol 与 Namenode 守护程序进行通信。
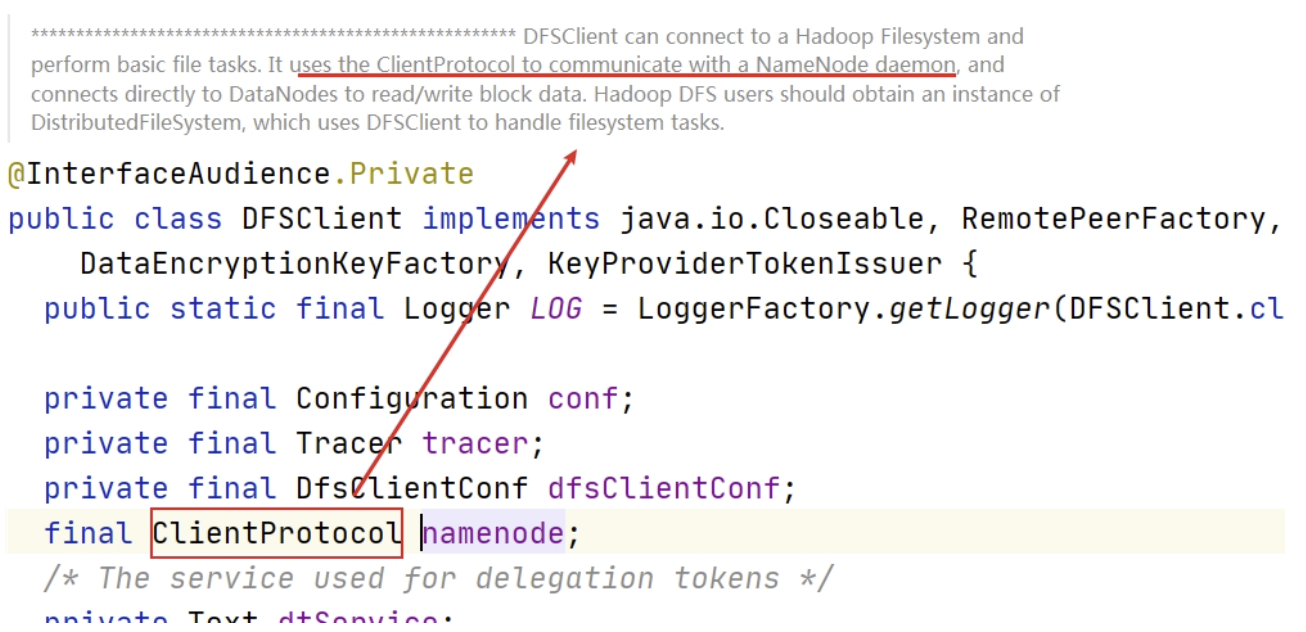
b. NameNode 执行请求检查
dfsClient.namenode.create 方法会请求 Namenode 在文件系统名称空间中创建一个新的文件条目。点击进入该方法,可以发现该方法位于 ClientProtocol 接口中,这是客户端和 Namenode 之间 RPC 接口。
打开接口的实现类 NameNodeRpcServer:
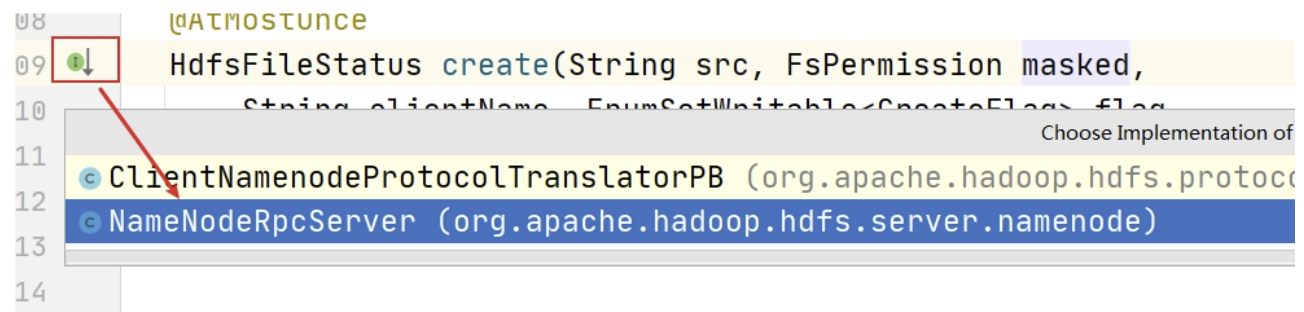
NameNodeRpcServer 中 status = this.namesystem.startFile 就是实际请求创建文件的方法。点击进去:
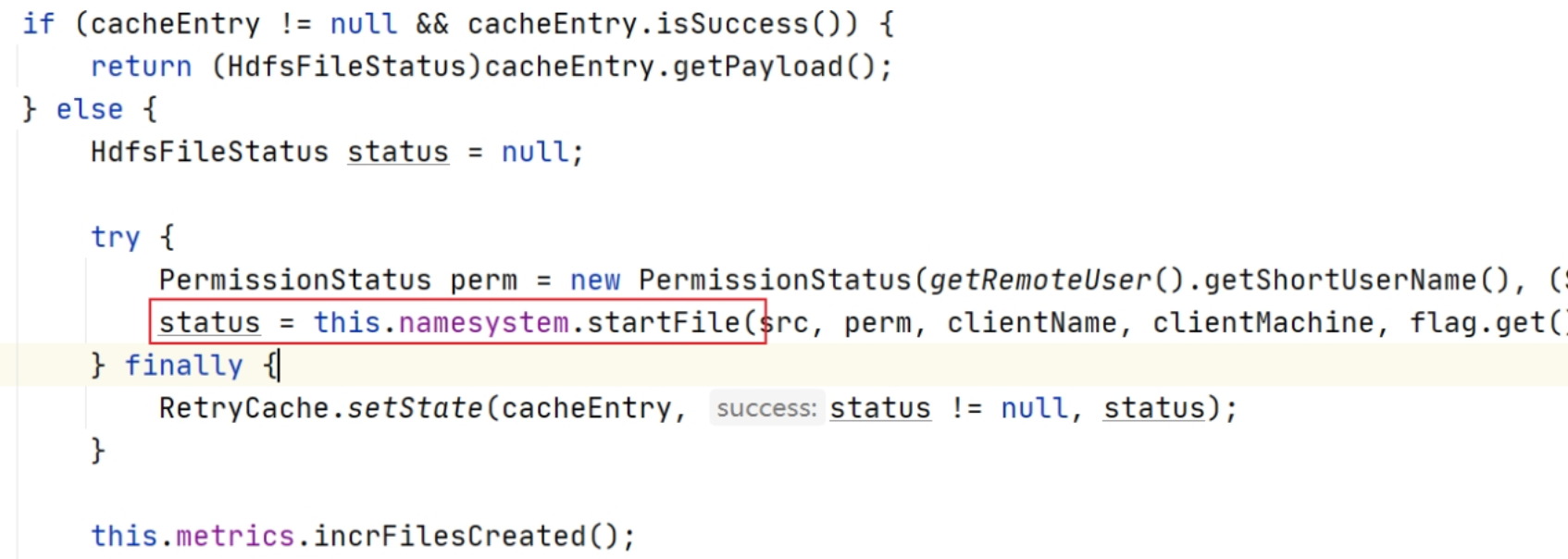
继续追踪 status = startFileInt() ,点击进去:

可以发现,Namenode 执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,Namenode 就会为创建新文件记录一条记录。否则,文件创建失败并向客户端抛出一个 IOException。

c. DataStreamer 类
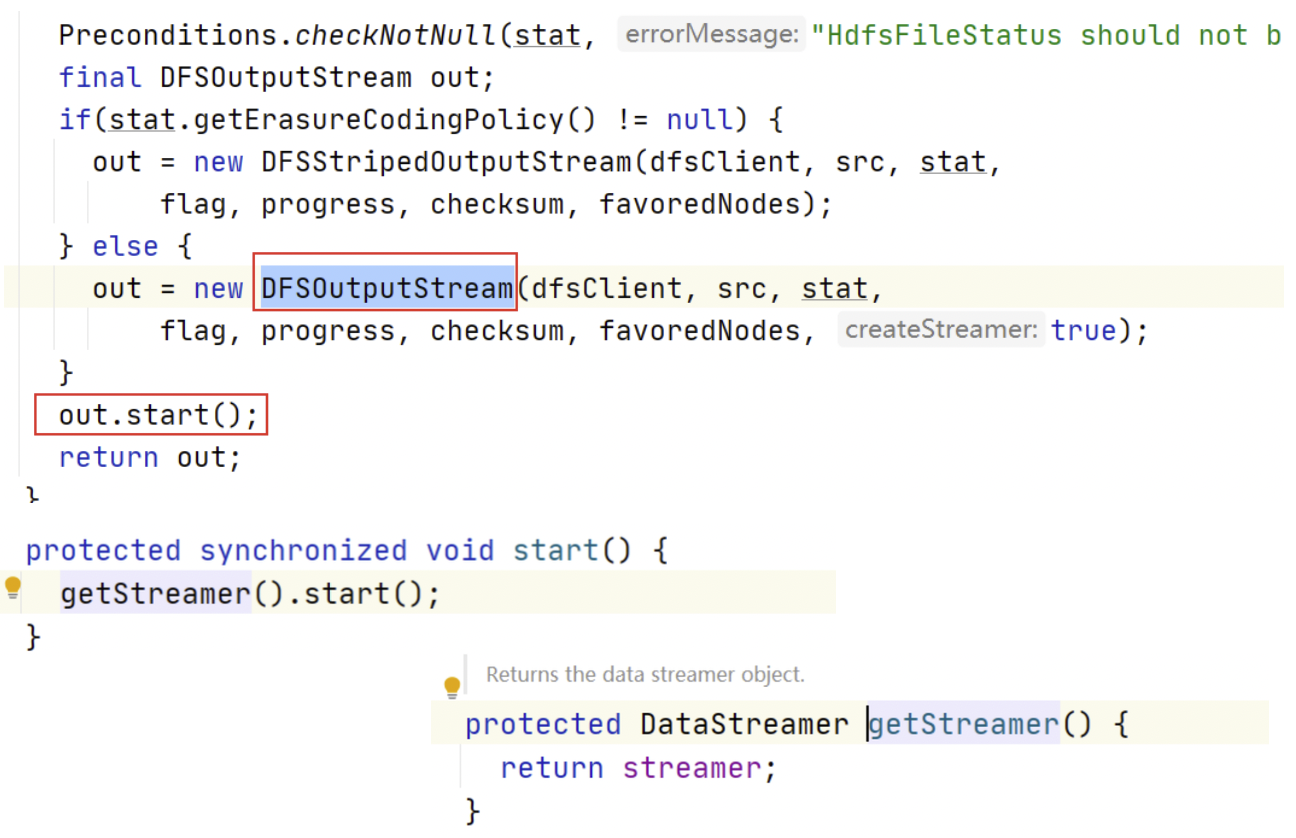
在 DFSOutputStream.newStreamForCreate() 方法的最后发现了 DFSOutputStream 的创建;并且在返回之前,调用了 out 对象的 start() 方法。点进 start 方法,发现最终调用的是 DataStreamer 对象的 start 方法。
DataStreamer 类是 DFSOutputSteam 的一个内部类,本质是一个线程。数据写入的关键代码就在 run 方法中实现。

d. DataStreamer 写数据
在 DataStreamer 的 run 方法中实现了数据写入的关键代码,概况起来:
- DataStreamer 类负责将数据包发送到 pipeline(管道)中的 Datanodes 节点上。它从 Namenode 检索新的 blockid 和块位置,然后开始将数据包流传输到 Datanodes 的管道中。
- 每个数据包都有与之关联的序列号。当发送完一个数据块的所有数据包并接收到每个数据包的确认后,DataStreamer 将关闭当前数据块。
- DataStreamer 线程从 dataQueue 中拾取数据包,将其发送到管道中的第一个 DataNode,然后将其从 dataQueue 中移动到 ackQueue 中。ResponseProcessor 从数据节点接收 ack 信息。当从所有数据节点接收到成功的数据包确认后,ResponseProcessor 将从 ackQueue 中删除相应的数据包。
(1)在客户端写入数据时,DFSOutputStream 将它分成一个个数据包(Packet 默认 64KB),并写入一个称之为数据队列(Data Queue)的内部队列。DataStreamer 请求 NameNode 挑选出适合存储数据副本的一组 DataNode。这一组 DataNode 采用 pipeline 机制做数据的发送。默认是 3 副本存储。

(2)DataStreamer 将数据包流式传输到 pipeline 的第一个 Datanode,该 DataNode 存储数据包并将它发送到 pipeline 的第二个 DataNode。同样,第二个 DataNode 存储数据包并且发送给第三个(也是最后一个)DataNode。

(3)DFSOutputStream 也维护着一个内部数据包队列来等待 DataNode 的收到确认回执,称之为确认队列(ackQueue)。发送 Packet 的时候,会把 Packet 从 dataQueue 移动到 ackQueue。收到 pipeline 中所有 DataNode 确认信息后,该数据包才会从 ackQueue 删除。
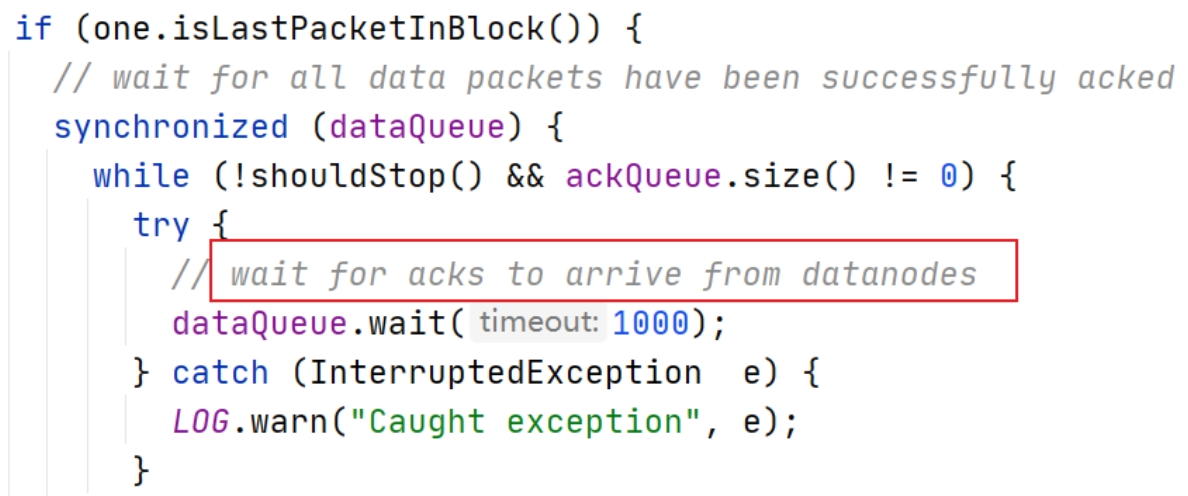
客户端完成数据写入后,将在流上调用 close() 方法关闭。该操作将剩余的所有数据包写入 DataNode pipeline,并在联系到 NameNode 告知其文件写入完成之前,等待确认。因为 NameNode 已经知道文件由哪些块组成(DataStream 请求分配数据块),因此它仅需等待最小复制块即可成功返回。数据块最小复制是由参数 dfs.namenode.replication.min 指定,默认是 1。
4.2 数据读取
public class HDFSReadDemo {
public static void main(String[] args) throws Exception {
// 设置客户端用户身份:root 具备在hdfs读写权限
System.setProperty("HADOOP_USER_NAME", "root");
// 创建Conf对象
Configuration conf = new Configuration();
// 设置操作的文件系统是HDFS 默认是file:///
conf.set("fs.defaultFS", "hdfs://node1:8020");
// 创建FileSystem对象
FileSystem fs = FileSystem.get(conf);
// 调用open方法读取文件
FSDataInputStream in = fs.open(new Path("/helloworld.txt"));
// 创建本地文件输出流
FileOutputStream out = new FileOutputStream("D:\\helloworld.txt");
// IO工具类实现流对拷贝
IOUtils.copy(in, out);
// 关闭连接
fs.close();
}
}
a. 客户端请求 NameNode
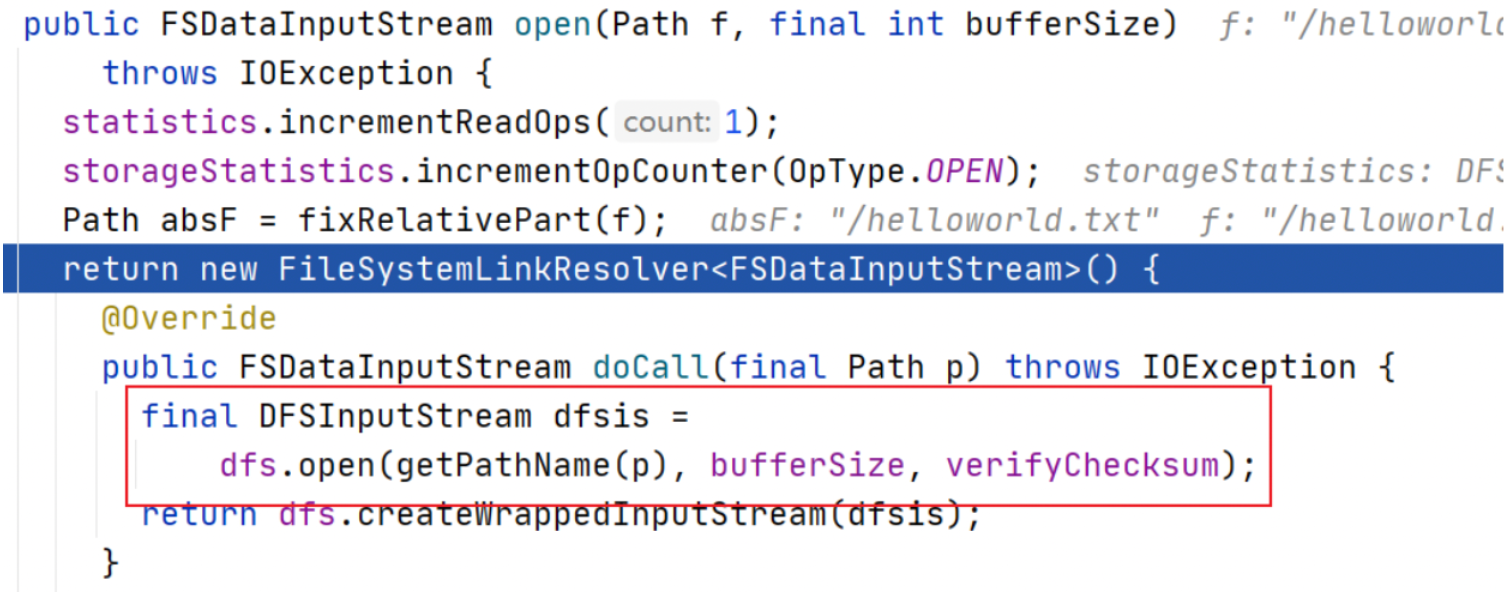
客户端通过调用 DistributedFileSystem 对象上的 open() 来打开希望读取的文件。DistributedFileSystem 为客户端返回 FSDataInputStream 输入流对象。通过源码注释可以发现 FSDataInputStream 是一个包装类,所包装的是 DFSInputStream。
可以通过 open 方法调用不断跟下去,可以发现最终的调用也验证了上述结论,返回的是 DFSInputStream。
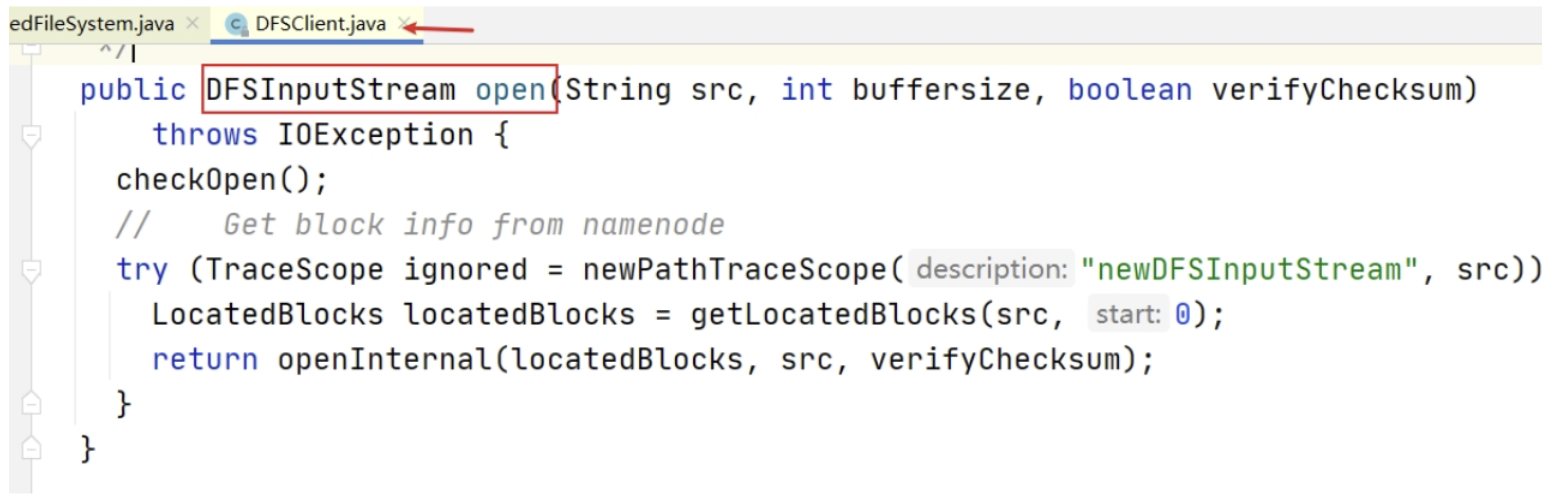
点击进入代码 DFSInputStream dfsis = dfs.open 可以发现,DFSInputStream 这个类是从 DFSClient 类的 open 方法中返回过来的。该输入流从 NameNode 获取 block 的位置信息。
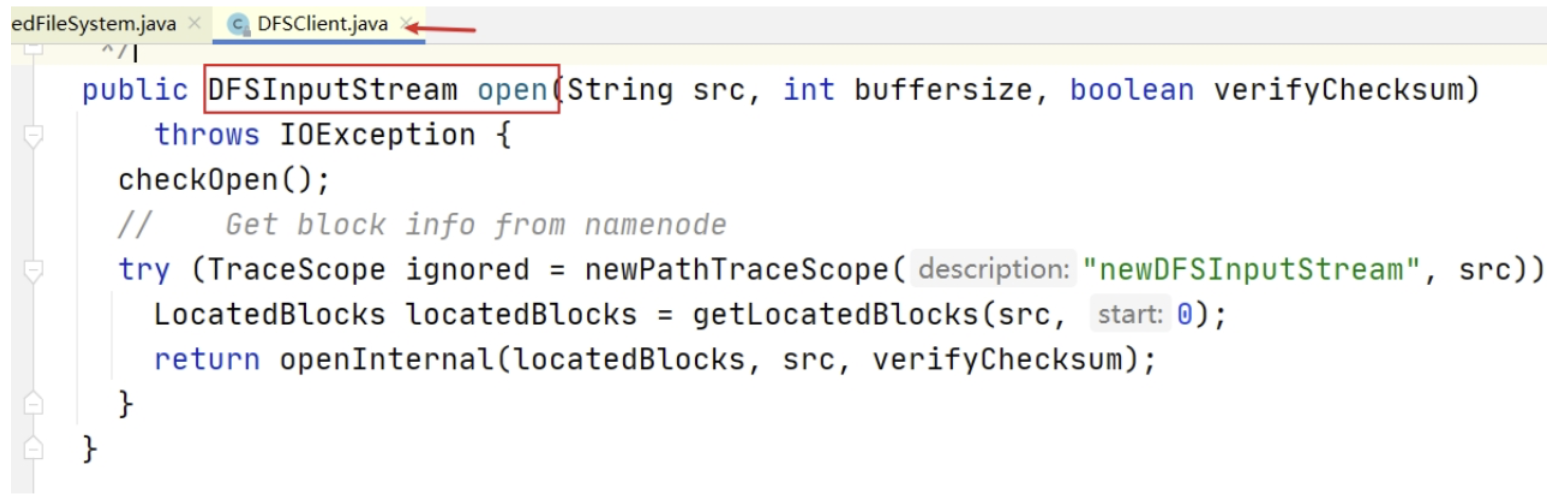
b. getLocatedBlocks
在上述 open 方法中,有一个核心方法调用叫做 getLocatedBlocks,见名知意,该方法是用于获取块位置信息的。

点击方法进去之后发现,最终调用的是 callGetBlockLocations():

继续点下去,发现最终调用的是 getBlockLocations() 方法。
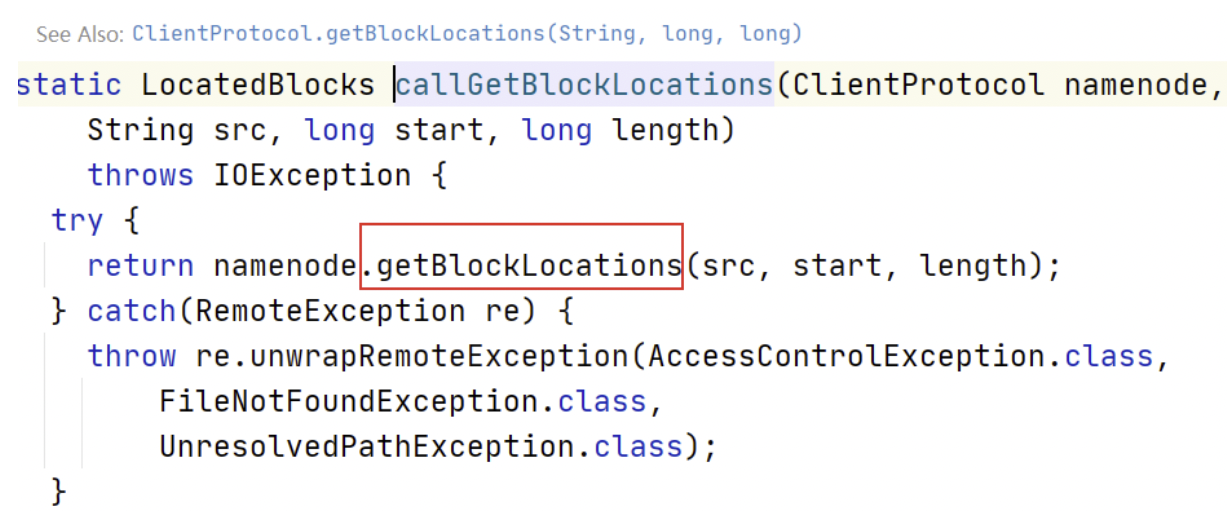
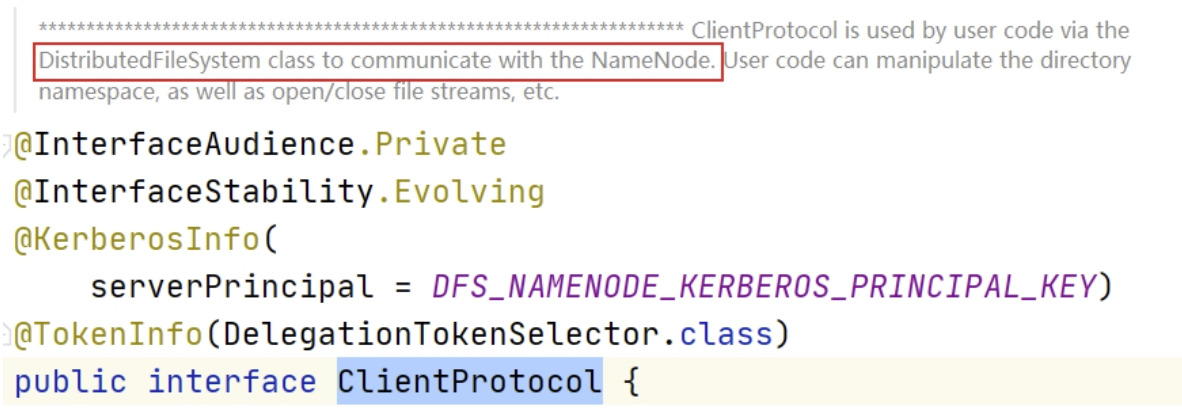
通过源码可以发现,getBlockLocations() 方法是位于 ClientProtocol 这个接口中。在 ClientProtocol 的注释上可以得出信息,这是客户端和 NameNode 进行通信的。
c. NameNode 返回块信息
DistributedFileSystem 使用 RPC 调用 NameNode 来确定文件中前几个块的块位置。对于每个块,NameNode 返回具有该块副本的 DataNode 的地址,并且DataNode 根据块与客户端的距离进行排序。
注意此距离指的是网络拓扑中的距离。比如客户端的本身就是一个 DataNode,那么从本地读取数据明显比跨网络读取数据效率要高。之前的 getBlockLocations() 方法在源码注释上也描述了这段逻辑。

获取指定范围内指定文件的块位置。 每个块的 DataNode 位置按与客户端的接近程度进行排序。返回 LocatedBlocks,其中包含文件长度,块及其位置。 每个块的 DataNode 位置按到客户端地址的距离排序。然后,客户端将必须联系指示的 DataNode 之一以获得实际数据。
d. 客户端读数据
DFSClient 在获取到 block 的位置信息之后,继续调用 openInternal() 方法。

点击进入该方法可以发现,分了两种不同的输入流。这取决于文件的存储策略是否采用 EC 纠删码。如果未使用 EC 编码策略存储,那么直接创建 DFSInputStream。

最终将 block 位置信息保存到 DFSInputStream 输入流对象中的成员变量中返回给客户端。
客户端在 DFSInputStream 流上调用 read() 方法,然后 DFSInputStream 连接到文件中第一个块的最近的 DataNode 节点(最优的)。通过对数据流反复调用 read() 方法,将数据从 DataNode 传输到客户端(数据会以数据包 Packet 为单位从数据节点通过流式接口传送到客户端 # DataTransferProtocol)。

当该块快要读取结束时,DFSInputStream 将关闭与该 DataNode 的连接,然后寻找下一个块的最佳 DataNode。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。
客户端从流中读取数据时,也会根据需要询问 NameNode 来检索下一批数据块的 DataNode 位置信息。一旦客户端完成读取,就对 FSDataInputStream 调用 close() 方法。
如果 DFSInputStream 与 DataNode 通信时遇到错误,它将尝试该块的下一个最接近的 DataNode 读取数据。并将记住发生故障的 DataNode,保证以后不会反复读取该 DataNode 后续的块。此外,DFSInputStream 也会通过校验和(checksum)确认从 DataNode 发来的数据是否完整。如果发现有损坏的块,DFSInputStream 会尝试从其他 DataNode 读取该块的副本,也会将被损坏的块报告给 NameNode 。