一、简介
雪花算法【Snowflake】是一种分布式唯一ID生成算法。能够生成唯一的,有序列的,高可用的ID,常用于分布式系统中作为全局唯一标识符【GUID】。雪花算法生成的ID是一个64位的整数,其中高位是时间戳,中间位是机器ID,低位是序列号。
二、组成
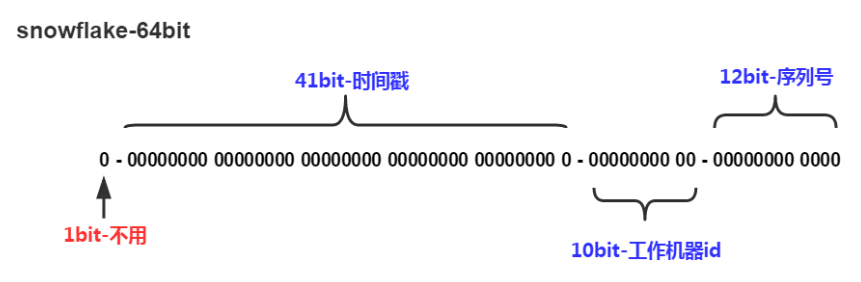
1、1位符号位:0表示正数,1表示负数(不适用,因为生成的ID都是正整数);
2、41位时间戳:精确到毫秒级别,可以支持69年的时间戳;
3、10位机器ID:支持1024台机器;
4、12位序列号:支持每台机器每毫秒生成4096个ID。
三、优点
1、全局唯一:由于每个 ID 都包含了时间戳和机器 ID 等信息,所以生成的 ID 是全局唯一的,不会出现重复的情况。
2、有序递增:由于时间戳和序列号等信息的设计,生成的 ID 是有序递增的,可以方便地按照时间顺序排序。
3、高性能:雪花算法生成 ID 的速度非常快,可以在短时间内生成大量的唯一 ID。
4、易于部署:由于雪花算法是基于时间戳和机器 ID 等信息生成 ID,可以方便地进行分布式部署。
因此,雪花算法常用于分布式系统中作为全局唯一标识符(GUID),例如订单号、流水号、消息 ID 等。
四、应用场景
1、订单系统:订单系统中,通常需要生成唯一的订单号。使用雪花算法可以生成全局唯一的、有序递增的订单号,方便系统进行订单的管理和查询。
2、日志系统:在日志系统中,每个日志记录通常都需要一个唯一的 ID,用于标识这条日志记录。使用雪花算法可以快速生成唯一的、有序递增的日志 ID,方便系统进行日志的分析和查询。
3、分布式任务系统:在分布式任务系统中,通常需要将任务分配给多个节点进行处理,为了避免重复执行任务,需要给每个任务分配一个唯一的 ID。使用雪花算法可以生成全局唯一的、有序递增的任务 ID,方便系统进行任务的分配和跟踪。
4、分布式缓存系统:在分布式缓存系统中,每个缓存项通常都需要一个唯一的 ID,用于标识这个缓存项。使用雪花算法可以生成全局唯一的、有序递增的缓存项 ID,方便系统进行缓存的管理和查询。
5、消息队列系统:在消息队列系统中,每个消息通常都需要一个唯一的 ID,用于保证消息的唯一性和顺序性。使用雪花算法可以生成全局唯一的、有序递增的消息 ID,方便系统进行消息的管理和追踪。
小结:任何需要实现全局唯一的、有序递增的 ID 的业务场景,都可以考虑使用雪花算法来生成 ID。
五、使用
1、定义一个Snowflake类,包含以下3个属性:
机器ID:用来区分不同的机器,范围是 0~1023
序列号:用来区分同一毫秒内生成的不同 ID,范围是 0~4095
上次生成ID的时间戳:用来记录上次生成 ID 的时间戳,单位是毫秒
2、实现Snowflash类的nextid()方法,用来生成下一个ID。


public synchronized long nextId() { // 获取当前时间戳 long timestamp = System.currentTimeMillis(); // 如果当前时间戳小于上次生成 ID 的时间戳,则说明系统时钟回退过,需要重新生成 ID if (timestamp < lastTimestamp) { throw new RuntimeException("Clock moved backwards. Refusing to generate id."); } // 如果当前时间戳和上次生成 ID 的时间戳相同,则在序列号上加 1 if (timestamp == lastTimestamp) { sequence = (sequence + 1) & sequenceMask; // 如果序列号超过了最大值,则需要等待到下一毫秒再生成 ID if (sequence == 0) { timestamp = tilNextMillis(lastTimestamp); } } else { // 如果当前时间戳大于上次生成 ID 的时间戳,则序列号重置为 0 sequence = 0; } // 更新上次生成 ID 的时间戳 lastTimestamp = timestamp; // 生成 ID long id = ((timestamp - twepoch) << timestampLeftShift) | (workerId << workerIdShift) | sequence; return id; }
3、在使用雪花算法生成 ID 的地方创建 Snowflake 实例,并调用 nextId() 方法生成 ID
Snowflake snowflake = new Snowflake(0, 0); long id = snowflake.nextId();
上述代码中,创建了一个机器 ID 和序列号都为 0 的 Snowflake 实例,然后调用 nextId() 方法生成 ID。
需要注意的是,雪花算法的机器 ID 和序列号都需要进行配置,保证在不同的机器和同一毫秒内生成的 ID 不重复。另外,如果系统时钟回退,需要等待到下一毫秒再生成 ID,避免生成重复的 ID。