一、 实验内容及目的
实验内容:
分析合并排序、快速排序、堆排序在不同规模数据、不同数据下的性能。
实验目的:
深入理解合并排序、快速排序、堆排序的思想,掌握三种排序的排序方法,对三种排序进行算法分析,通过与算法比较,体会三种排序算法的优缺点,进而了解在何种情况下使用何种算法。
分析的指标:
在相同数据规模的情况下的算法代码运行时间,和所占空间。
二、实验方案
实验环境:Windows10 + Dev-C++ + 硬盘大小100GB + 8核处理器 + 16GB内存
合并排序伪代码:


快速排序伪代码:


堆排序伪代码:



我们将每个测试数据记录在txt文件中,在测试时进行读取文件
三、结果及分析
测试数据规模:


|
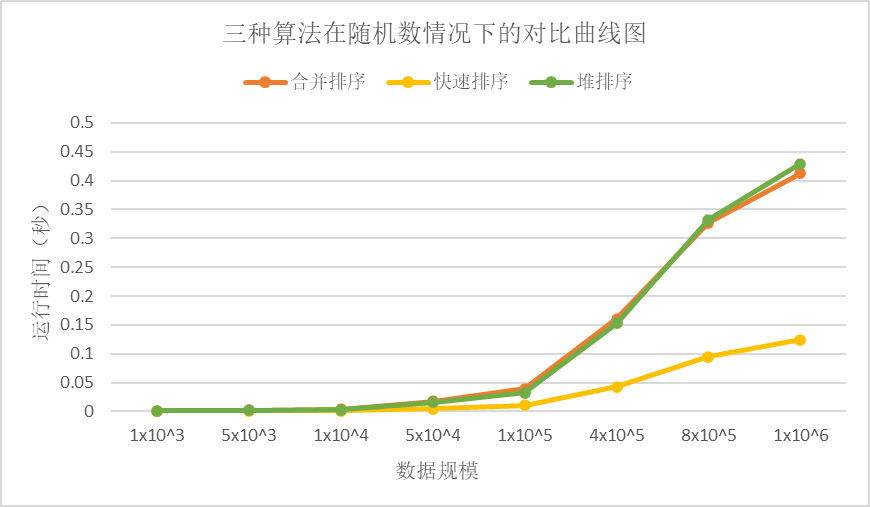
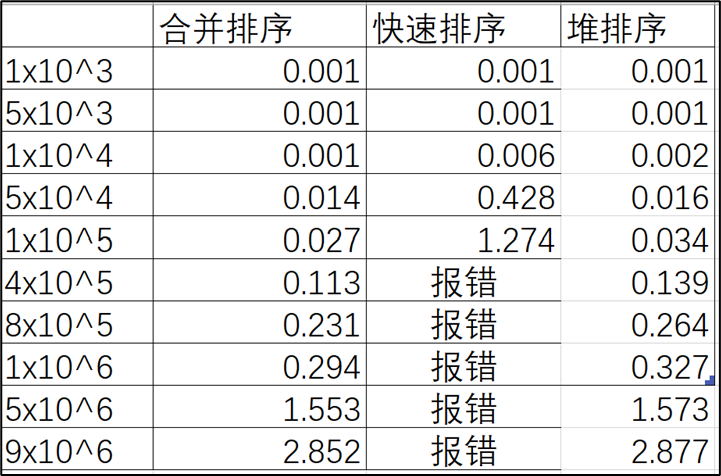
表1 三种算法在随机数情况下的时间数据 |
由上统计图和表中我们可以看出,在随机数的情况下,无论是哪个数据规模下快速排序是最快的,合并排序和堆排序所用时间相近,在数据规模较小的情况下,堆排序的时间稍快,在数据规模较大的情况下,合并排序快。
|
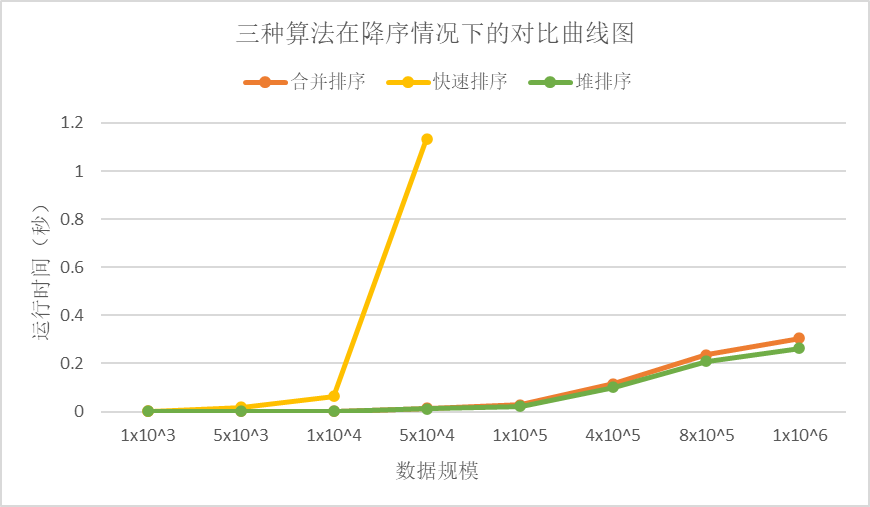
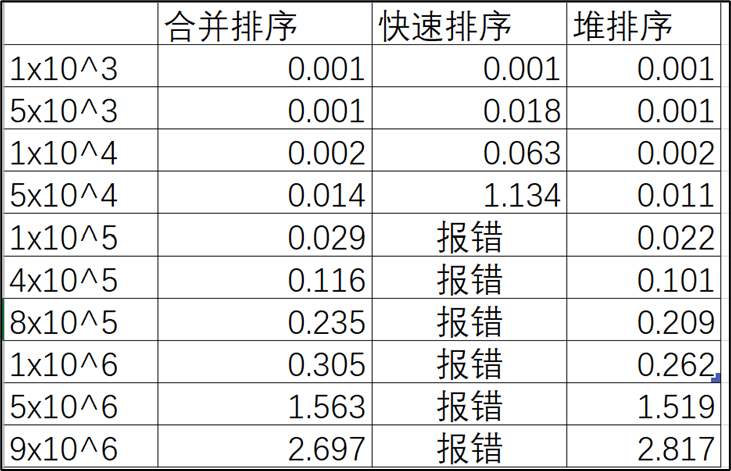
表2 三种算法在降序情况下的时间数据 |
从降序情况下的对比曲线图中我们可以看出,堆排序是最快的,其次是合并排序,最后是快速排序。快速排序因为递归调用次数太多导致内存溢出,无法正常进行排序。
|
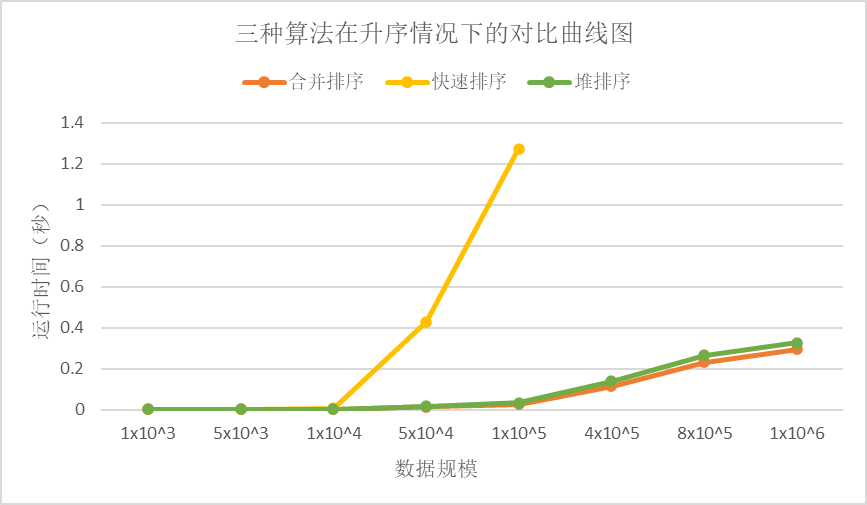
表3 三种算法在升序情况下的时间数据
|
从升序情况下的对比曲线图中我们可以看出,合并排序是最快的,其次是堆排序,最后是快速排序。快速排序因为递归调用次数太多导致内存溢出,无法正常进行排序。
由于我们自己手写的快速排序算法在数据规模超过10^5时会报错,于是我们用C++库中自带的sort函数进行比较
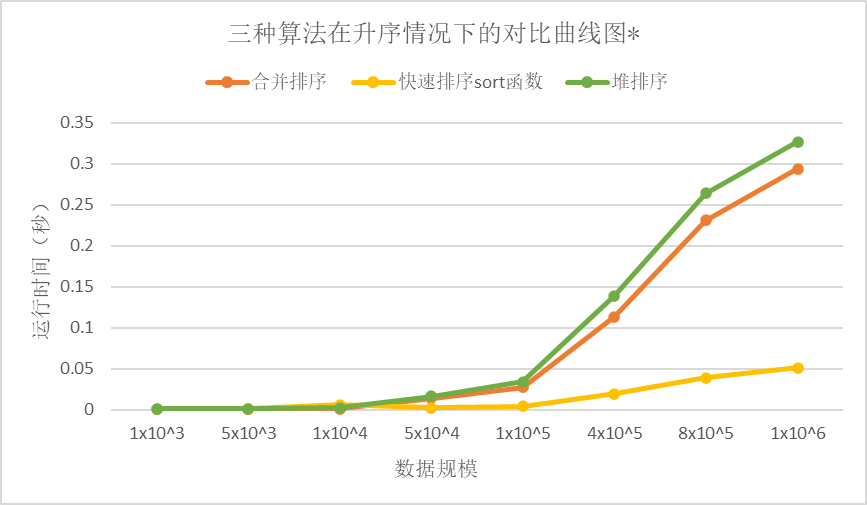
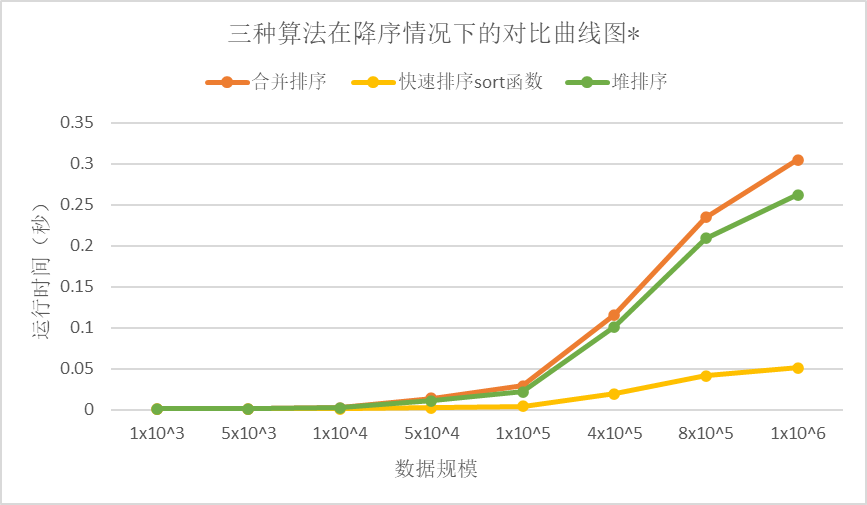
可以看见快速排序无论是在哪种情况下都是最快的。
但有一点需要说明,sort函数并不完全是使用的快速排序算法,在sort函数内部会选择使用哪种排序算法,而且快速排序算法也与我们自己写的有所区别,这也是为什么sort函数又快又好用的原因。


通过研究sort函数和网络其他文章,我改进了原来的快速排序算法,使用尾递归优化,现在我们自己手写的代码就没有了报错,但是时间很长。
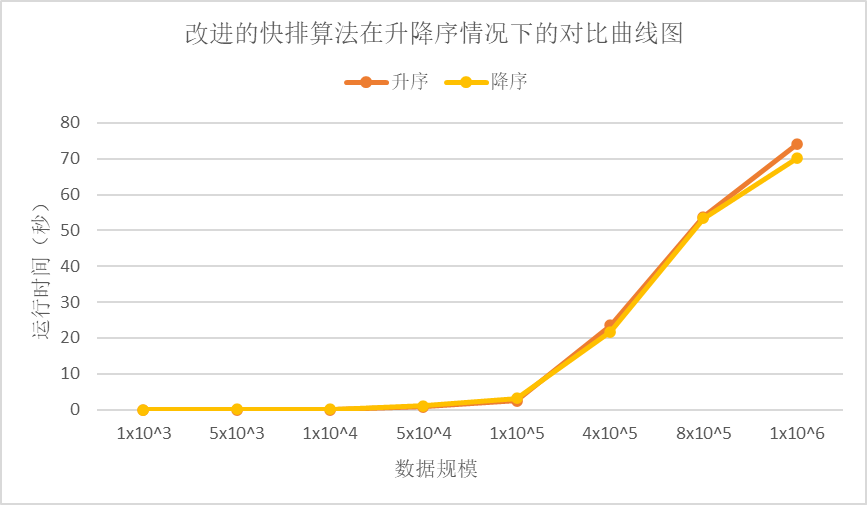
尾递归原理:
当编译器检测到一个函数调用是尾递归的时候,它就覆盖当前的活动记录而不是在栈中去创建一个新的。编译器可以做到这点,因为递归调用是当前活跃期内最后一条待执行的语句,于是当这个调用返回时栈帧中并没有其他事情可做,因此也就没有保存栈帧的必要了。通过覆盖当前的栈帧而不是在其之上重新添加一个,这样所使用的栈空间就大大缩减了,这使得实际的运行效率会变得更高。减少爆栈风险。
对于合并排序来说:

可以看出,随机情况下合并排序的速度相比于升序和降序情况下要慢。升序和降序情况下合并排序速度几乎相同。比较稳定。
对于堆排序来说:

可以看出,待排序的数据的顺序对堆排序的影响要大于对合并排序的影响,这是由于堆排序的特点造成的。因为堆排序要构造大根堆,而降序几乎就已经是大根堆了,所以需要的时间就少。而升序需要先构造大根堆,时间就会比降序要多。
四、总结
一般来说,我们遇到有序的数据的情况太少。因此,通过比较三种算法,可以说快速排序在绝大多数情况下是最快的。合并排序和堆排序在随机情况下差别不大,在升序情况下合并排序稍快,在降序排序情况下堆排序稍快。从空间复杂度来看,因为堆排序只需要一个数组,因此空间开销最小,合并排序和快速排序都需要递归调用,因此开销比较大。在数据规模很大的时候,没有改进的快速排序容易爆栈。而通过对sort函数源代码的了解,发现有的时候需要多种排序算法相结合,这样即能节省内存,又能节省时间。
五、参考文献及附录
clayyjh. C语言 记录程序的执行时间[EB/OL] [2021-03-12].https://www.cnblogs.com/clayyjh/p/14526665.html
小乔流水人家. C语言 查看运行程序所需要的时间和占用的内存[EB/OL] [2017-02-22].https://www.cnblogs.com/BeautyFuture/articles/6428551.html
挺的博客 归并排序(C语言版)[EB/OL] [ 2019-05-02 ]. https://blog.csdn.net/baidu_15547923 7
Owl丶 快速排序 的 尾递归优化 详细分析 [EB/OL] [ 2020-04-26 ].https://blog.csdn.net/qq_40586164/
朱铭德 看看C++快排(sort)源码 [EB/OL] [ 2017-07-25 ].https://blog.csdn.net/zmdsjtu/article/details/76050939
附录:
合并排序
#include<bits/stdc++.h> using namespace std; void merge(int A[], int L[], int R[], int l, int r); void mergesort(int A[],int n) { if(n>1) { //多于一个元素才需要排序 int mid=n/2; int *B=(int*)malloc(sizeof(int)*mid); int *C=(int*)malloc(sizeof(int)*(n-mid)); for(int i=0; i<mid; i++) B[i]=A[i]; //左半部分 for(int j=mid; j<n; j++) C[j-mid]=A[j]; //右半部分序列 mergesort(B,mid); mergesort(C,n-mid); merge(A,B,C,mid,n-mid); free(B); free(C); } } void merge(int A[],int B[],int C[],int p,int q) { int i=0,j=0,k=0; while(i<p&&j<q) { if(B[i]<=C[j]) A[k]=B[i++]; else A[k]=C[j++]; k++; } while(i<p) { A[k++]=B[i++]; } while(j<q) { A[k++]=C[j++]; } } int main(){ int A[1010]; int n; cin >> n; for(int i = 0 ; i < n ; i++){ cin >> A[i]; } mergesort(A,n); for(int i=0;i<n;i++){ if((i+1)%10==0){ printf("%d\n",A[i]); }else{ if(i==n-1){ printf("%d\n",A[i]); }else{ printf("%d ",A[i]); } } } }
快速排序
#include<bits/stdc++.h> using namespace std; int a[10] = {2,3,5,6,1,10,4,7,8,9}; int partition(int a[],int first,int end) { int i = first,j = end; while(i < j) { while(i < j && a[i] <= a[j])j --; if(i < j && a[i] > a[j]) { int temp = a[i]; a[i] = a[j]; a[j] = temp; i ++; } while(i < j && a[i] <= a[j])i ++; if(i < j && a[i] > a[j]) { int temp = a[i]; a[i] = a[j]; a[j] = temp; j --; } } return i; } void quickSort(int r[],int first,int end) { if(first < end) { int pos = partition(r,first,end); quickSort(r,first,pos - 1); quickSort(r,pos + 1,end); } } int main() { quickSort(a,0,9); for(int i = 0 ; i < 10 ; i++) { cout << a[i] << " "; } }
堆排序
#include<bits/stdc++.h> using namespace std; void swap(int a[],int i,int j) { int temp = a[i]; a[i] = a[j]; a[j] = temp; } void heapify(int a[],int index,int size) { int left = 2 * index + 1; int right = 2 * index + 2; while(left < size) { int big; //父节点 左 右节点 节点中最大的 if(a[left] < a[right] && right < size) big = right; else big = left; if(a[index] > a[big]) big = index; //如果父结点索引是最大值的索引,那已经是大根堆了,则退出循环 if (index == big) { break; } swap(a,big,index); index = big; left = 2 * index + 1; right = 2 * index + 2; } } void heapInsert(int a[], int n) { for(int i = 0 ; i < n ; i++) { int currentIndex = i; int fatherIndex = (i-1)/2; while (a[currentIndex] > a[fatherIndex]) { swap(a,currentIndex, fatherIndex); currentIndex = fatherIndex; fatherIndex = (currentIndex - 1) / 2; } } } void heapSort(int a[],int n) { heapInsert(a,n); while (n > 1) { swap(a,0, n - 1); n--; heapify(a,0, n); } } int main() { int a[50000+9]; int n; cin >> n; for(int i = 0 ; i < n ; i++) { cin >> a[i]; } heapSort(a,n); for(int i = 0 ; i < n ; i++) { cout << a[i] << " "; } cout << endl; }