有过量的题和比赛要补。
Tricks
- 双指针(不删除双指针)
- 二分(wqs 二分),倍增
- 分治(归并,二维分治,对操作序列分治,决策单调性优化 dp,CDQ,线段树分治,猫树分治)
- 扫描线 & 二维扫描线(莫队)
- 补完题要填的科技坑:wqs 二分,吉司机线段树
二分与倍增
CF1548B Integers Have Friends
不删除双指针板子,但是孤陋寡闻的樱雪喵第一次听说这个 trick。
首先题意里要求 \(\bmod\, m\) 全相等,这个奇怪的条件可以转化为在差分数组上区间 \(\gcd\) 不为 \(1\)。
发现 \(\gcd\) 是可以快速合并两部分但不容易删除的,所以要用到不删除的双指针。
具体地,我们记录三个变量 \(l,mid,r\),并用一个数组维护 \(t_i=\gcd(a_i,\dots,a_{mid})\)。
如果处理过程中 \(l>mid\) 了,就令 \(mid=r\),并重构这个数组。因为这时 \(l\) 更小一定是没有用的,只需要重构 \([l,mid]\) 这一段即可。
那么每个数至多被重构了一次,加上 \(\gcd\) 的总时间复杂度是 \(O(n)\)。
P6003 [USACO20JAN] Loan Repayment S
首先这个 \(x\) 可以套一层二分,问题在于如何对 \(10^{12}\) 级别的数据 check。
答案是一个下取整的形式,可以仿照整除分块的过程优化到根号。然后就做完了。
CF1661F Teleporters
题中给出的 \(a_i\) 已经将序列分成了若干段,我们只需要依次考虑每一段的最优策略。
设 \(f(x,y)\) 表示把一个初始长度为 \(x\) 的段分成 \(y\) 小段,这一部分所要花费的最少能量。根据均值不等式,我们希望分成的 \(y\) 段长度尽可能均匀。那么可以得到式子
发现 \(f(x,y)\) 是凸的,也就是说当 \(x\) 一定时,\(f(x,y)-f(x,y+1)\) 的值随 \(y\) 的增大单调递减。所以我们可以得到这样的暴力做法:
维护一个大根堆和每段已经安装的传送机数 \(c_i\),每次选择 \(f(a_i,c_i)-f(a_i,c_i+1)\) 最大的段安装。
考虑优化这个暴力,由于大根堆的堆顶值单调不增,我们可以二分最后结束时的堆顶 \(k\)。
那么最终的 \(c_i\) 就是令 \(f(a_i,x)-f(a_i,x+1)\ge k\) 的最大的 \(x\)。这个同样可以二分,这样我们已经知道在大根堆顶为 \(k\) 时结束整个过程时的答案,把它与 \(m\) 比较即可。
而这样做不一定是最优的,因为我们要在 \(k\) 不变且答案不大于 \(m\) 的情况下最小化 \(c_i\) 的和。每个 \(c_i\) 减 \(1\) 会令总代价增加 \(k\),设当前的总代价为 \(sum\),则答案为 \((\sum c_i)-\lfloor\frac{m-sum}{k}\rfloor\)。
时间复杂度是 \(O(n\log^2 V)\),\(V\) 为值域。
P4694 [PA2013] Raper
题意可以转化为把 \(k\) 对 \(a_i\) 和 \(b_j\) 配对,要求每对的 \(i\le j\),最小化总代价。
设 \(f(i)\) 表示共生产 \(i\) 个光盘的最小代价。发现 \(f\) 是一个下凸函数,可以使用 wqs 二分。
这里我们给每次配对操作一个附加权值 \(-t\),考虑在没有配对数限制的情况下怎么求答案。
从小到大枚举 \(i\),将 \(a_i\) 加入候选,考虑 \(b_i\) 的配对情况。这样做的好处是所有在候选集合内的 \(a_i\) 都满足先后顺序的限制。
对 \(a_i\) 维护一个小根堆。那么 \(b_i\) 分为三种情况:
- 和以前没配对过的 \(a_j\) 配对;
- 把一个以前配对过的 \(a_j\) 拆开,再让它和 \(b_i\) 配对;
- 如果上面两种不能让答案更优,不配对。
对于第二种情况,我们可以反悔贪心,在 \(a_j\) 匹配后,把它对应的 \(-b_i+t\) 放进小根堆。这样在下次匹配时,\(-b_j+t+b_i-t\) 就消掉了上一次对答案的已有贡献。
这里需要同时维护堆中的每个元素是否被匹配过,以求出匹配数。
根据二分的实现方式,如果斜率恰好切到了凸壳的一条边上,我们希望在代价相同的情况下找到匹配数最少的切点。也就是说在贪心匹配时,要注意在代价相同的情况下优先匹配已经匹配过的点,否则无法通过 hack。
然后就是注意 wqs 二分经典错误,减掉附加权值的贡献应该用 \(k\) 而不是实际选出来的匹配数。
时间复杂度 \(O(n\log V\log n)\)。
AGC020D Min Max Repetition
要令连续的相同字符个数的最大值最小,可以直接贪心将 A 和 B 尽可能分开,得出答案 \(k=\lfloor\frac{A+B}{\min(A,B)+1}\rfloor\)。
接下来要在这个基础上构造字典序最小的答案。
我们显然希望 A 尽量靠前,直到超出限制时再用 B 分开,即靠前部分的答案形如 AAABAAABAAAB...。但是后面大量的 B 还需要用 A 分开,我们希望尽量少的 A 被放在后面,则后面部分的答案形如 BBBABBBABBB...。
也就是说,完整的答案字符串由前后两部分拼成,前半部分每放 \(k\) 个 A 放 \(1\) 个 B;后半部分每放 \(k\) 个 B 放 \(1\) 个 A。
那么我们可以二分这个位置 \(p\),\(\text{check}\) 时分别求出前后所需的两种字符个数即可。
注意 \(\text{check}\) 的时候别爆 int。
CF1764G1 Doremy's Perfect DS Class (Easy Version)
考虑 \(1\) 和其他的数有什么不同点。我们令询问的 \(k=2\),那么只有 \(1\) 的值是 \(0\),其余都不是。这看起来并没有什么用,因为我们只能知道不同的数的个数。
但是真的没有用吗?可以发现,若 \(k=2\),则所有数下取整后是两两配对的,\(\lfloor\frac{2}{2}\rfloor=\lfloor\frac{3}{2}\rfloor,\lfloor\frac{4}{2}\rfloor=\lfloor\frac{5}{2}\rfloor,\dots\)。当 \(n\) 为奇数时,只有 \(1\) 是单出来的;\(n\) 为偶数时,\(1\) 和 \(n\) 两个数都是单出来的。
先考虑奇数的情况怎么做。
对于一个区间 \([l,r]\),若 \(\text{query}(l,r,2)=x\),可以得到 \([l,r]\) 中有 \(2x-(r-l+1)\) 个数字没有被配对。所以假设我们找了一个分界点 \(mid\),并求出 \([1,mid]\) 中有 \(L\) 个没配对,\([mid+1,n]\) 中有 \(R\) 个没配对。那么如果同一组的数分到了一边一个,它们可以互相消掉,只有 \(1\) 是无论如何都无法被配对的。
这就是说,若 \(L<R\),\(1\) 就在 \([mid+1,n]\) 中;否则 \(1\) 在 \([1,mid]\) 中。那么我们可以二分这个 \(mid\) 的位置,求出答案,询问次数 \(2\log n\le 20\)。
再考虑 \(n\) 是偶数的情况。
现在,我们同样询问得到了 \(L\) 和 \(R\) 的值。分类讨论 \(1\) 和 \(n\) 的位置情况:
- 如果都在左侧,应该是 \(L=R+2\);
- 如果都在右侧,应该是 \(R=L+2\);
- 如果一左一右,\(L=R\)。
发现在一左一右的情况下,我们没法判断哪一边是 \(1\)。
但仔细思考一下,发现 \(n\) 的位置是好找的:令 \(k=n\),这样只有 \(n\) 的答案是 \(1\),其他都是 \(0\)。因此可以在一开始先二分找出 \(n\) 的位置,就能知道 \(L=R\) 时 \(1\) 在哪边了。
找 \(n\) 的位置只需要询问一边,所以总询问次数是 \(3\log n\le 30\)。
CF1764G2 Doremy's Perfect DS Class (Medium Version)
发现找 \(1\) 的位置的过程是不好优化的,现在的询问次数瓶颈在找 \(n\) 的位置。
实际上,我们只关心 \(n\) 在 \(mid\) 的哪一侧,而不关心它的具体位置。可以这样优化:
- 当第一次出现 \(L=R\) 的情况时,我们通过一次 \(\text{query}(1,mid,n)\) 判断 \(n\) 在 \(mid\) 的哪一侧。
- 当再次出现这个情况时,发现有一条性质:如果之前判断过 \(n\) 在 \(mid\) 的右侧,我们的二分区间只会往左不会往右,也就是说以后 \(n\) 永远在 \(mid\) 的右侧,反之同理。
因此,在第一次判断时记录 \(n\) 在 \(mid\) 的哪一侧,以后不需要再次判断。总询问次数为 \(2\log n+1\le 21\)。
CF1764G3 Doremy's Perfect DS Class (Hard Version)
限制是 \(20\),还需要再卡掉一次询问。
考虑二分的终止状态,在 \(l+1=r\) 的情况下,把两边都问一遍看起来就不太划算。能不能只问一边呢?
Case 1
如果我们现在还没询问过 \(n\) 在 \(mid\) 的哪一侧,说明 \(n\) 还在区间 \([l,r]\) 中。换句话讲,\(l\) 和 \(r\) 的位置上一个是 \(n\) 一个是 \(1\)。
这种情况是好办的:一次询问就能找出 \(n\) 的位置,剩下的那个自然是 \(1\)。
Case 2
\(n\) 不在区间里,考虑我们已经知道了哪些信息。
在达成当前局面之前,我们曾令 \(mid=l-1\),也曾令 \(mid=r\)。也就是说,我们知道 \(\text{query}(1,l-1,2)\) 和 \(\text{query}(r+1,n,2)\) 的答案。
设 \([1,l-1]\) 未配对的个数为 \(L\),\([r+1,n]\) 为 \(R\)。因为已经知道 \(n\) 在哪一侧,可以在这步直接减掉 \(n\) 的贡献。
那么若 \(L<R\),表明 \([l,r]\) 中剩余的两个数,除了 \(1\) 以外的那个是跟 \([1,l-1]\) 中的某个数配对的。
因此我们询问 \([1,l]\) 中未配对的个数为 \(L'\),若 \(L'<L\),说明这个数与左边配对成功了,\(1\) 在 \(r\) 位置上;否则说明配对失败了,\(1\) 在 \(l\) 位置。
\(L>R\) 同理。
至此,最后一步二分被优化到一次询问,询问次数上界为 \(2\log n\le 20\)。
分治
AGC001F Wide Swap
令 \(a_i=pos_{p_i}\),这仍是一个排列。题意转化为如果相邻两项的差大于等于 \(k\),可以交换它们。
我们希望原序列字典序最小,即希望小的数的 \(pos\) 值更小。在这一点上,原序列的字典序与新序列的字典序关系是一致的,我们只需最小化新序列的字典序。
考虑这样的暴力:每次在排列中找到任意一对相邻的 \(x,y\),满足 \(x\ge y+k\),并交换它们,重复该操作直到不存在这样的数对。
这样做是正确的,具体的证明可以看 Link。
上面做法的本质是冒泡排序,我们把它换成归并排序,右区间的开头 \(R\) 能被放入当前序列末尾的条件是 \(R+k\) 小于等于左区间剩下数的后缀最小值。时间复杂度 \(O(n\log n)\)。
CF1442D Sum
对修改序列分治 & 缺一背包。
有一个结论:至多有一个数组选了一部分,剩下的要么全选要么一个都不选。
考虑用调整法证明,设两个数组都只选了一部分,设它们选的最后一个数分别是 \(a_x,b_y\)。
根据数组单调不降的性质,若 \(a_x<b_y\),我们把 \(a_x\) 改为选 \(b_{y+1}\) 一定更优,反之同理。
现在的问题变成了求除第 \(i\) 个物品以外的 01 背包。
一个比较好理解的办法是把物品分块,预处理出除第 \(i\) 块以外的背包,每次只修改或撤销这个块内的物品的贡献。
不过这里是分治专题,所以要写分治。
我们令 \(\text{solve}(l,r)\) 表示除掉 \([l,r]\) 以外所有物品的背包。
分治过程中,先将 \([mid+1,r]\) 的物品加入背包,\(\text{solve}(l,mid)\);再将 \([mid+1,r]\) 的物品删除,加入 \([l,mid]\),\(\text{solve}(mid+1,r)\)。
这样当 \(l=r\) 时的背包数组就是除掉 \(l\) 以外所有物品的背包。
CF364E Empty Rectangles
二维分治。
Solution 1
分治题当然不能写分治了!
提供一个不用分治的做法,时间复杂度 \(O(nmk^2)\)。
看到题就觉得它神似 CF627E,考虑把做法搬过来。
发现那个题的时间复杂度有保证是因为它保证了点数与矩阵边长同阶,而本题的点数最多可以达到 \(nm\)。
然而不是所有点都有用,可以去掉无效的点。具体地,我们枚举了矩形的上边界后,每一列只有从上到下的前 \(k+1\) 个点会对答案产生贡献。这样,点数被优化到 \(mk\)。
然后照搬那题的做法就行了。
以下是写给没做过 627E 的人的部分:
将所有给定的点按纵坐标为第一关键字,横坐标为第二关键字排序,并重新标号。对点 \(i\) 维护 \(cnt_i\) 表示 \(i\) 往后数第 \(k\) 个点,这个点所在的纵坐标。
那么我们只要维护了 \(cnt_i\),就能在修改 \(cnt_i\) 的同时维护出答案。
首先枚举矩形的上边界,用双向链表按纵坐标顺序维护上下边界之间的所有点。
不过链表中加点比较复杂,考虑倒序枚举下边界,并依次从集合中删点。注意到,一次删点至多会对它前面的 \(k\) 个点的 \(cnt\) 值产生贡献,暴力更新他们即可。
Solution 2
突然想起来我开这题是为了学二维分治的,所以象征性写一下分治做法。
设 \(\text{solve}(a,b,c,d)\) 表示仅考虑左上角为 \((a,c)\),右下角为 \((b,d)\) 这个矩形内部的答案。
分治时每次选较长的那一维分成两部分,假设这里把矩形横着切,\(mid=\lfloor\frac{a+b}{2}\rfloor\)。
那么不跨越隔板的贡献是 \(\text{solve}(a,mid,c,d)+\text{solve}(mid+1,b,c,d)\)。
对于跨越隔板的贡献,枚举纵坐标的范围 \([l,r]\),维护 \(up_i\) 和 \(dw_i\) 分别表示最大令隔板上方有 \(i\) 个点,最小令下方有 \(i\) 个点的横坐标。这两个东西在 \(l\) 固定,\(r\) 增加的过程中是单调的,因此对于每个 \(l\) 每个 \(up_i\) 只会移动 \(n\) 次,可以暴力维护。
时间复杂度 \(O(nmk\log n)\)。
*[Ynoi2016] 镜中的昆虫
gugugu.
CF868F Yet Another Minimization Problem
决策单调性优化 dp。
分治优化 dp 很套路了,我们说说怎么维护 \(w(l,r)\)。暴力维护的时间复杂度不正确(大家好我真的写 T 了一发),考虑使用类似莫队的思想:
维护当前指针 \(L,R\) 表示答案,每次询问时暴力移动指针。这样做我们在 solve 完 \((l,r)\),处理 \((l,mid)\) 时,可以发现要询问的区间恰好是连着的。因此这样维护询问区间代价的时间复杂度均摊为 \(O(1)\)。
CF576E Painting Edges
明明觉得我前几天学线段树分治的时候写过这个题的题解啊,记忆错乱了?
二分图就是经典的对每种颜色的边维护并查集。
设一条边相邻两次染色的时间为 \(l,r\),那么时间 \(l\) 的这次操作的影响范围就是 \([l,r-1]\)。但是这个区间染没染色成功我们是不知道的,这时就需要半在线地进行线段树分治。
我们把 \([l,r-1]\) 拆成单点 \(l\) 和 \([l+1,r-1]\) 两部分。
在线段树分治到点 \(l\) 时,判断是否合法。如果不合法,就不操作;否则把 \([l+1,r-1]\) 这条线段塞进线段树。
令区间左端点为 \(l+1\) 的原因是要保证加入线段的位置我们还没访问到,这样半在线地加入线段和一开始就能处理好所有线段的题目没有本质区别。
P6240 好吃的题目
猫树分治能解决的问题通常有以下条件:
- 静态区间,多组询问
- 我们不会快速求处理询问,但如果知道区间中一点 \(mid\) 分别到区间左右端点的答案,可以快速地合并这两部分得到完整区间的答案。
对于本题,假设我们已经知道了 \([l,mid]\) 和 \([mid+1,r]\) 的背包 \(L,R\),直接合并这两部分是 \(O(t^2)\) 的。
但是因为这道题给定了询问的 \(t_i\),我们并不需要真的把两个背包合并起来,直接求 \(\max L_j+R_{t_i-j}\) 就好了,这样时间复杂度只有 \(O(t)\)。
接下来考虑如何充分利用已知区间中一点的条件,求出答案。
分治,设 \(\text{solve}(l,r)\) 表示当前仅考虑被 \([l,r]\) 包含的询问区间。令 \(mid\) 为 \(l,r\) 的中点。
那么这些区间分为两种,不跨越 \(mid\) 的区间直接分到两边递归处理;只考虑求出所有跨过 \(mid\) 的区间的答案。
这时候上面所说的就能用到了:我们以 \(O(t(r-l))\) 的复杂度处理出所有 \([i,mid](l\le i\le mid)\) 和 \([mid+1,i](mid<i\le r)\) 的背包,则可以以 \(O(t)\) 的时间复杂度处理一个跨过隔板的询问。
实现上把未处理的询问塞进两边递归的过程和整体二分类似。
CF232E Quick Tortoise
设一次询问的四个参数为 \((a,b,c,d)\)。
采用类似猫树分治的思想,对 \(x\) 坐标进行分治。
\(\text{solve}(l,r)\) 表示仅考虑起点终点的横坐标均在 \([l,r]\) 内的询问,设区间中点为 \(mid\)。
那么起点、终点在 \(mid\) 同侧的可以分治到两边递归处理,我们只考虑起点在 \(mid\) 上面,终点在 \(mid\) 下面的询问的答案。
设 \(f_{i,j,k}\) 表示从 \((i,j)\) 出发能否到达 \((mid,k)\),\(g_{i,j,k}\) 表示从 \((mid,k)\) 出发能否到达 \((i,j)\)。则我们可以用 \(O((r-l)m)\) 的复杂度预处理这两个数组,并 \(O(m+q)\) 地计算所有符合条件的询问的答案。
算上外层分治,总时间复杂度为 \(O((nm^2+q)\log n)\)。
过不去,但 dp 转移和判断合法的部分都可以使用 bitset 优化,时间复杂度 \(O((\frac{nm^2}{\omega}+q)\log n)\)。
扫描线
[Ynoi2015] 即便看不到未来
在 Ynoi 里算是代码比较好写的题了。
把询问离线下来,从左到右处理右端点,设当前处理到右端点 \(r\)。则 \(s_{i,j}\) 表示区间 \([i,r]\),长度为 \(j\) 的值域连续段个数。
考虑 \(r\) 从 \(r-1\) 移动过来对 \(s\) 数组产生的影响。设 \(lst_i\) 表示值 \(i\) 上一次出现的位置,那么只有 \(l>lst_{a_i}\) 的位置出现的数的集合发生了改变。
又因为我们只关心长度 \(\le 10\) 的连续段个数,也就是只关心 \([a_i-10,a_i+10]\) 的数字最后一次出现的位置 \(pos_j\)。把它们的 \(lst\) 值升序排序,并从右向左处理。记 \(L,R\) 分别表示 \(x\) 所在的连续段最小值和最大值。那么可以分为三种情况:
- \(L=x\),\(x\) 是这个连续段的开头,则在答案中减掉原连续段长度为 \(R-L\) 的贡献,增加长度为 \(R-L+1\) 的贡献。
- \(x=R\),\(x\) 是结尾,贡献同理。
- \(L<x<R\),说明 \(x\) 连接了两个连续段,则它们原来的长度分别是 \(x-L\) 和 \(R-x\),新的长度是 \(R-L+1\)。
发现它们三个的修改本质上一样:减掉 \(x-L\) 和 \(R-x\) 的贡献,加上 \(R-L+1\) 的贡献。设排序后现在处理到下标 \(j\),那么这些修改的影响区间是 \([pos_{j-1}+1,pos_j]\)。
我们需要一个支持区间加单点查询的数据结构,这里使用树状数组。
然后有个细节。虽然我们本不关心 \(a_i-11\) 和 \(a_i+11\) 这两个数,但按照上述做法实现,如果 \(x\) 成为了一个原来长度为 \(10\) 的连续段的开头,我们只有在新长度为 \(11\) 时才能把原来 \(10\) 这个段的贡献撤掉。故这里应当多循环一位。
[THUPC2022 决赛] rsraogps
看起来不太好做,考虑找特殊性质。
以按位与运算为例,当区间左端点 \(l\) 固定,向右延伸 \(r\) 的过程中,区间按位与的结果至多只会改变 \(\log n\) 次(考虑每次在二进制中把一个 \(1\) 变成 \(0\))。另外两种运算是同理的。
这启发我们使用扫描线来维护答案。
设现在处理到右端点 \(r\),设 \(s_i\) 表示所有 \(i= L\),$ R\le r$ 的区间 \([L,R]\) 的答案之和。则询问 \([l,r]\) 的答案即为 \(s_r-s_{l-1}\)。
当 \(r\) 右移一位时,根据上述的性质,我们只需要对区间值改变的位置暴力修改,可以保证至多修改 \(n\log n\) 次。其余位置本质上是一个区间加法,需要通过打标记记录增加的次数和值。
CF793F Julia the snail
电脑写一半蓝屏了,没心情重写一遍。
不会吉司机线段树,所以只能写和扫描线没啥关系的分块了 /youl
设 \(f_{i,j}\) 表示起点为 \(i\),终点为 \(ed_j\)(第 \(j\) 块结尾)的答案。那么如果我们知道了 \(f_{i,j}\),就能在 \(O(\sqrt{n})\) 的时间复杂度内处理一个询问。
考虑如何预处理,设 \(g_{i,j}\) 表示起点为 \(i\),终点在第 \(j\) 块内最靠右的线段。这个是好处理的。
从 \(f_{k,j}\) 递推 \(f_{i,j}\),有 \(f_{i,j}=\max\limits_{k=i+1}^{g_{i,j}}(g_{i,j},f_{k,j})\)。使用单调栈维护。
[CERC2015] Cow Confinement
题解看不懂,所以试图不差分直接大力维护,过了。
从右往左,对 \(y\) 坐标扫描线。设现在处理到第 \(j\) 列,那么 \(tr_i\) 就表示点 \((i,j)\) 出发的答案(这里就是题里问的答案,不是差分数组)。
假设我们现在扫描线向左移动了一列,按如下顺序依次处理这一列上的东西对答案的影响:
- 矩形的右边界
- 矩形的左边界
- 花
- 统计这一列的答案
Part 1. 矩形右边界
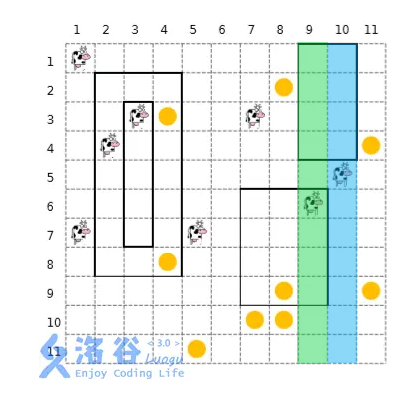
假设我们处理完了蓝色的列,现在要处理的是绿色的列。

那么可以发现,矩形的右边界 \([6,9]\) 影响了标记为黄色的这一段区间。因为新加的列上的花都还没有被考虑,其余位置的 \(tr_i\) 不改变。而黄色的部分被竖线挡住,这部分答案必然是 \(0\)。
把它们区间清零即可。
Part 2. 矩形左边界
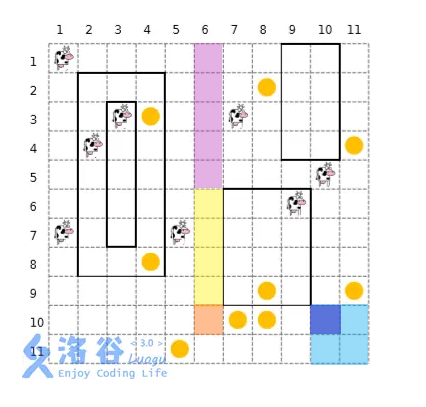
假设我们正在处理第 \(6\) 列,考虑 \([6,9]\) 这段区间的线消失对答案的影响。那么标记为黄色的部分应该舍弃原来的答案,它们现在唯一的走法是先走到橙色点再找答案,因此把黄色这段区间推平为橙色位置的值。
再考虑上面的紫色部分(其实这里应当延伸到上面的第一个障碍,这里没有就延伸到顶了)。
它们相比原来有一个新的选择,就是走到橙色那里获得橙色部分的答案。不过这样是有重复的,因为蓝色部分它们原来就能走到。整个蓝色部分的答案存在深蓝色点上,所以在紫色部分区间加上橙色点去掉深蓝色点的答案。
Part 3. 花

花是好处理的,一个花对它上面不越过障碍的位置都有 \(1\) 的贡献,区间加即可。
Part 4. 查询
存的本身就是答案,直接单点查就好了。
综上,我们需要一个支持区间推平、区间加、单点查询的数据结构,可以使用线段树维护。向上的第一个障碍使用 std::set 维护。