通过之前的学习,我们已经对 Kubernetes 有了一定的理解,也知道如何在 Kubernetes 中部署自己的业务系统。
Kubernetes 强大的能力让我们非常方便地使用容器部署业务。Kubernetes 自带的副本保持能力,可以避免部署的业务系统出现单点故障,提高可用性。各种探针也可以帮助我们对运行中的容器进行一些简单的周期性检查。
但是要想知道业务真实运行的一些指标,比如并发请求数、IOPS、线程数,等等,就需要通过监控系统来获取了。此外,我们还需要监控系统支持将不同数据源的指标进行收集、分类、汇总聚合以及可视化的展示等。
今天我们就来聊聊 Kubernetes 的监控体系,以及目前主流的监控方案。首先来看看 Kubernetes 监控系统所遇到的挑战。
Kubernetes 监控系统面临的挑战
以往的业务应用在部署的时候,大都固定在某几台节点上,各种指标监控起来也很方便。通过在每个节点上部署对应的监控 agent,用来收集对应的监控指标。
而到了Kubernetes 体系中,监控的问题开始变得复杂起来。
首先,业务应用的 Pod 会在集群中“漂移”且捉摸不定。你无法预知 Pod 会在哪些节点上运行,而且运行时间有可能也只是短暂的,随时可能会被新的、健康的 Pod 所取代。而且业务还有需要扩缩容的场景,你无法提前预知哪些 Pod 会被销毁掉。这里还有两点非常值得关注,那就是:
-
除了 StatefulSet 管理的 Pod 名字是固定不变的以外,通过 Deployment/ReplicaSet/DaemonSet 等工作负载管理的 Pod 的名字是随机的;
-
Pod 的 IP 不是固定不变的。
这样的话,如果我们还是通过以往固定 IP 或者固定域名的方式去拿监控数据,这就不太可行了。
其次,转向了微服务架构以后,就不可避免地出现“碎片化”的问题。从以前的单体架构,变成微服务架构,模块和功能被逐步拆解成一组小的、松耦合的服务。各个小的服务可以单独部署,这也给监控带来了麻烦。
再次,通过前面的学习,你已经知道Kubernetes 通过 label 和 annotation 来管理 Pod ,这一全新的理念对以往传统的监控方式带来了冲击。所以评判一个监控方案是不是能够完美适配 Kubernetes 体系的标准就是,它有没有采用 label 和 annotation 这套思路来收集监控指标。
最后,Kubernetes 强大的能力,让我们在部署应用的时候更加随心所欲。Kubernetes可以对接各个 Cloud Provider (云服务提供商),比如 AWS、GCP、阿里云、VMWare,等等。这就意味着我们部署业务的时候,可以选择让 Pod 运行在公有云、私有云或者混合云中。这也给监控体系带来前所未有的挑战。
尽管存在这么多的挑战,我们还是有很多方案可以采用的。现在我们先来看看 Kubernetes 中几种常见的监控数据类别。
常见的监控数据类别
在 Kubernetes 中,监控数据大致分为两大类。
一种是应用级别的数据,主要帮助我们了解应用自身的一些监控指标。常见的应用级别的监控数据包括:CPU 使用率、内存使用率、磁盘空间、网络延迟、并发请求数、请求失败率、线程数,等等。其中并发请求数这类指标,就需要应用自己暴露出监控指标的接口。
除了应用自身的监控数据外,另外一种就是集群级别的数据。这个数据非常重要,它可以帮助我们时刻了解集群自身的运行状态。通过监控各个 Kubelet 所在节点的 CPU、Memory、网络吞吐量等指标,方便我们及时了解 Kubelet 的负载情况。还有 Kubernetes 各个组件的状态,比如 ETCD、kube-scheduler、kube-controller-manager、coredns 等。
在集群运行过程中,Kubernetes 产生的各种 Event 数据,以及 Deployment/StatefulSet/DaemonSet/Pod 等的状态、资源请求、调度和 API 延迟等数据指标也是必须要收集的。
下面我们先来看看如何来收集这些监控数据。
常见的监控数据采集工具
Kubernetes 集群的数据采集工具主要有以下几种工具。
1. cAdvisor
cAdvisor 是 Google 专门为容器资源监控和性能分析而开发的开源工具,且不支持跨主机的数据监控,需要将采集的数据存到外部数据库中,比如 influxdb,再通过图形展示工具进行可视化。一开始 cAdvisor 也内置到了 Kubelet 中,不需要额外部署。但是社区从 v1.10 版本开始,废弃了 cAdvisor 的端口,即默认不开启,并于 v1.12 版本正式移除,转而使用 Kubelet 自身的/metrics接口进行暴露。
2. Heapster
Heapster 是一个比较早期的方案,通过 cAdvisor 来收集汇总各种性能数据,是做自动伸缩(Autoscale)所依赖的组件。你在网上查找 Kubernetes 各种监控方案的时候可能还会见到。但是现在 Heapster 已经被社区废弃掉了,后续版本中推荐你使用 metrics-server 代替。我们在下一节中,会来介绍如何通过 metrics-server 来实现自动扩缩容,控制资源水位。
3. metrics-server
metrics-server是一个集群范围内的监控数据聚合工具,用来替代 Heapster 。下一节我们会学习具体如何使用,这里先了解一下就可以了。
4. Kube-state-metrics
Kube-state-metrics 可以监听 kube-apiserver 中的数据,并生成有关资源对象的新的状态指标,比如 Deployment、Node、Pod。这也是 kube-state-metrics 和 metrics-server 的最大区别。
5. node-exporter
node-exporter 是 Prometheus 的一个 exporter,可以帮助我们获取到节点级别的监控指标,比如 CPU、Memory、磁盘空间、网络流量,等等。
当然,还有很多类似的工具可以采集数据,在此不一一列举。有了这么多数据采集工具可以帮助我们采集数据,我们就可以根据自己的需要自由组合,形成我们的监控方案体系。
在 Kubernetes 1.12 版本以后,我们通常选择 Prometheus + Grafana 来搭建我们的监控体系,这也是社区推荐的方式。
Prometheus + Grafana
Prometheus 功能非常强大,于 2012 年由 SoundCloud 公司开发的开源项目,并于 2016 年加入 CNCF,成为继 Kubernetes 之后第二个被 CNCF 接管的项目,于 2018 年8月份毕业,这意味着 Prometheus 具备了一定的成熟度和稳定性,我们可以放心地在生产环境中使用,也可以集成到我们自建的监控体系中(很多厂商的自建监控体系就是这么打造的)。
Prometheus 在早期开发的时候,参考了Google 内部 Borg 的监控实现 Borgmon。所以非常合适和源自 Borg 的 Kubernetes 搭配使用。
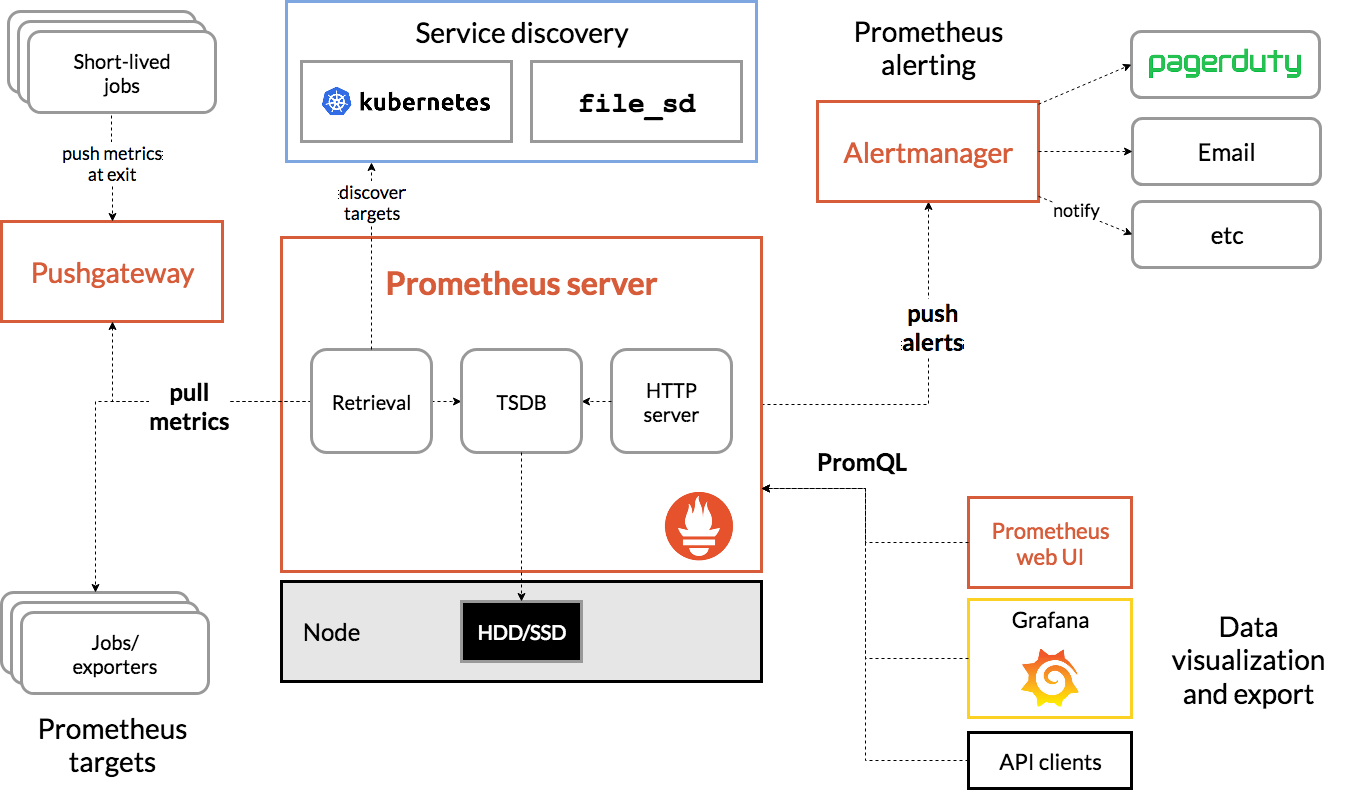
我们来看一个例子,如下图是 Prometheus + Grafana 组成的监控方案。

(https://www.prometheus.io/assets/architecture.png)
{kind=link}
最左边的 Prometheus targets 就是我们要采集的数据。Retrieval 负责采集这些数据,并同时支持 Push 和 Pull 两种采集方式。
-
Pull 模式是最常用的拉取式数据采集方式,大部分使用数据都是通过这种方式采集的。只需要在应用里面实现一个
/metrics接口,然后把这个接口写到Prometheus 的配置文件即可。你可以参照这份官方文档,学习如何在自己的应用中添加监控指标。 -
Push 模式则是由各个数据采集目标主动向 PushGateway 推送指标,再由服务器端拉取。
为了保证数据持久化,Prometheus 采集到的这些监控数据会通过时间序列数据库 TSDB 进行存储,支持以时间为索引进行存储。TSDB 在提供存储的同时,还提供了非常强大的数据查询、数据处理功能,这也是告警系统以及可视化页面的基础。
此外,Prometheus 还内置了告警模块 Alertmanager,它支持多种告警方式,比如 pagerduty、邮件等,还有对告警进行动态分组等功能。
最后这些监控数据通过 Grafana 进行多维度的可视化展示,方便通过大盘进行分析。
我们会在第 17 讲中来详细说明这套监控系统的搭建过程及相关配置。
写在最后
Kubernetes 的副本保持及自愈能力,可以尽可能地保持应用程序的运行,但这并不意味着我们就不需要了解应用程序运行的情况了。因此,当我们开始将业务部署到 Kubernetes 中时,还需要去部署一套监控系统,来帮助我们了解到业务内部运行的一些细节情况,同时我们也需要监控 Kubernetes 系统本身,帮助我们了解整个集群当前的形态,指导我们作出决策。Prometheus 和 Grafana 是目前使用较广泛的监控组合方案,很多监控方案也都是基于此做了二次开发和定制。
这节课到这里就结束了,如果你有什么想法或者疑问,欢迎你在留言区留言,我们一起讨论。