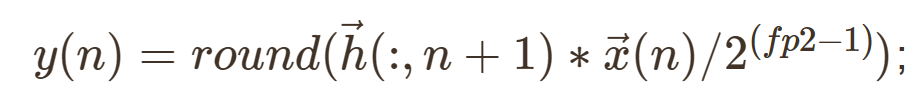1.verilog浮点表示
定点运算有两个缺点:①可处理动态范围小;②由截尾舍入产生的百分比误差随着数的绝对值的减小而增加,这个问题可利用浮点数来解决。根据IEE754-1985标准,非负数n可以用两个参数表示,即尾数M和指数E,其表示形式为:$\eta =M×2^{E}$
|
sign |
exponent |
significand |
|
符号S |
指数E |
尾数 |
指数 exponent的位宽决定了可以表示数据的范围,尾数的位宽决定了可以表示数据的精度
假设:浮点数整体位宽是14bits,指数 exponent位宽5bits,尾数Significand位宽8bits.
用14bit的浮点表示十进制数32:$32=1.0∗2^{5}=0.1∗2^{6}$,(0.1为2进制表示的0.1).
所以指数exponent=110,尾数1000_0000,符号位sign=0,所以32=0_00110_1000_0000,
这种表示方法的另一个问题是由于 exponent没有符号位,没法表示负指数(比如 )
为了解决编码浪费空间问题,可以规定significand的第一位必须是1,这一过程称作归一化( normalization),所有 significands以0.1xxxxx形式表示,例如$4.5=100.1∗2^0=0.1001∗2^3$
从而使得尾数M限制为在[0.5,1]范围内的二进制小数, significand的第一位必须是1.
为了使 exponents可以表示负指数,采用 biased exponent方法。
令偏置数据( bias number)是一个根据 exponent位宽而定的居中的数(5位表示最大为25 ,居中的数是16=24 ),负指数加上这个偏置数据后可以变为正数表达。从而得到指数E,为一个正的或负的二进制整数。
$0.0625(10)=1.0∗2−4=0.1∗2−3, bias exponent=16$,故在-3指数上加16,得到新的指数13(10)=01101(2)
0.0625(10)=0_01101_10000000
-26.625(10): $26.625(10)=11010.101(2)=0.11010101∗2^5$ ,在指数5上加 bias number16,得到最终指数项21(10)=10101(2) -26.625(10)=1_10101_11010101
IEEE浮点数标准
在IEEE标准中,significant的表示方法是:1.xxx….,例如$4.5=0.1001∗2^3$ ,在IEEE标准中就应该表示为$1.001∗2^2$ ,尾数的第一位1是隐含的,也就是说这个1不会出现在significant编码域,故significant编码中只包含001.
单精度浮点位宽32bit,其中指数E部分具有8位 (bias127),尾数部分则具有23位,还有一位用做符号位S(0正,1负)。
指数部分有偏编码为E-127。E的范围为:-126~127, $2^{128}=3.4×10^{38}$;
双精度浮点位宽64bit,其中指数E部分具有11位(bias1023),尾数部分则具有52位,还有一位用做符号位S(0正,1负)。
尾数域的最高有效位总是1,由此,该标准约定这一位不予存储,而是认为隐藏在小数点的左边,因此,尾数域所表示的值是1.M(实际存储的是M)
双精度浮点位宽64bit,其中指数E部分具有11位(bias1023),尾数部分则具有52位,还有一位用做符号位S(0正,1负)。
尾数域的最高有效位总是1,由此,该标准约定这一位不予存储,而是认为隐藏在小数点的左边,因此,尾数域所表示的值是1.M(实际存储的是M)
$−3.75=−11.11(2)=−1.111∗2^1 ,bias127,exponent=1+127=128$, 尾数的第一位1是隐藏的,
1_1000_0000_.1110_0000_0000_0000_0000_000
|
sign |
exponent |
significand |
|
符号S |
指数E |
尾数 f |
|
1bit |
w bits |
p-1 bits |
|
IEEE name |
format |
size |
w |
p |
||
|
Binary32 |
signal |
32 |
8 |
23 |
-126 |
127 |
|
Binary64 |
double |
64 |
11 |
52 |
-1022 |
1023 |
|
Binary128 |
quad |
128 |
15 |
113 |
-16382 |
16383 |
单精度浮点尾数位宽:23+1(hidden),尾数范围:[1,$2−2^{−23}$]最大为尾数全1的情况:1+2^{−1}+…+2^{−23}=2−2^{−23},最小为尾数全0的情况:1
指数位宽:8bit,指数偏置127,e+bias∈[1,254],e∈[-126,127]
所以正数范围中,单精度浮点最大数表示为:$2^{127}∗(2−2^{−23})≈2^{128}$; ,最小数: $2^{−126}∗1≈2^{−126}$;
特殊值
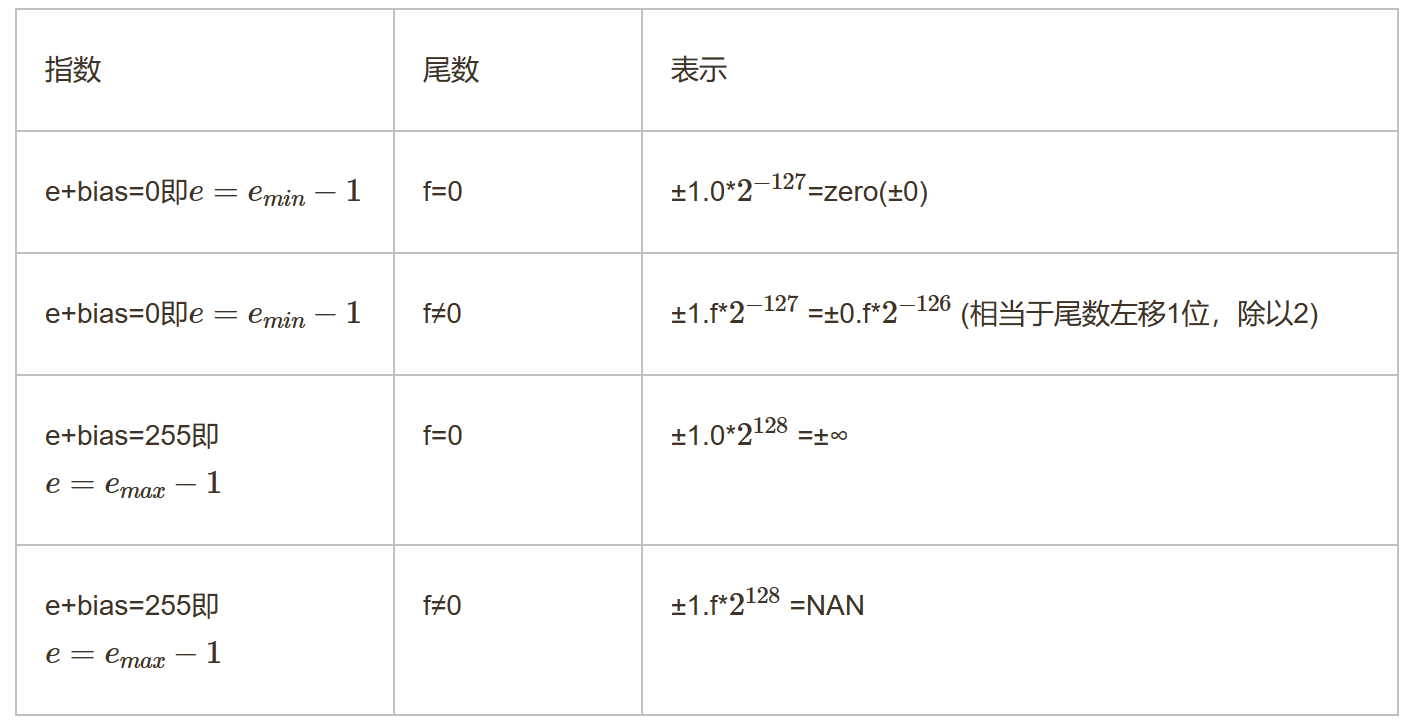
实际指数部分表示的值换算成指数值时需要减去这个偏置值。对于指码位00000001,它对应的指数值为(1 - 127 = -126)。
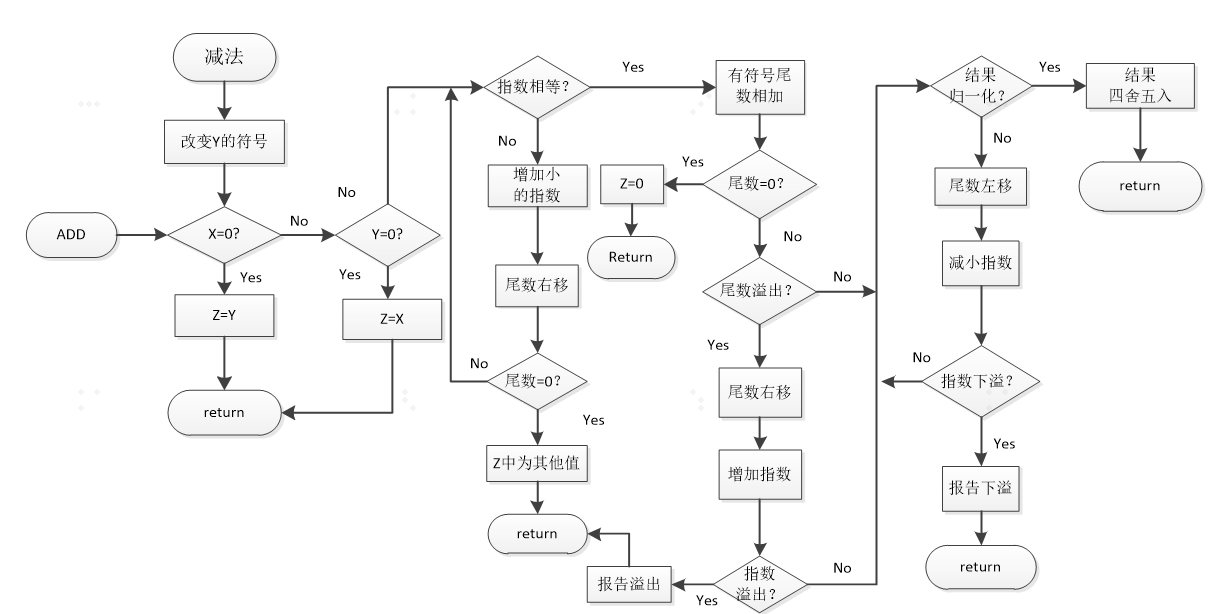
浮点加法
两个浮点数的相加:统一指数exponent对阶,先将较小的一个数的尾数右移几位,直到两个数的指数相同,然后再将尾数significant相加,最后归一化结果。
如$1001+10=1.001∗2^3+1.0∗2^1=1.001∗2^3+0.010∗2^3=1.011∗2^3$
运算过程:
(1) 首先比较阶码大小是否相等,并完成对阶: 原则是小阶向大阶看齐,即小阶的尾数向右移,相当于小数点左移,每右移一位,其指数加1,直到两数的指数相等为止。
(2) 尾数求和运算:其方法与定点加减法运算完全一样,需要把数据转换成补码形式后再进行加减法。最后结果规格化,尾数每左移一位,指数减1,每右移一位,指数加1.,转化为$1.f∗2^e$的格式
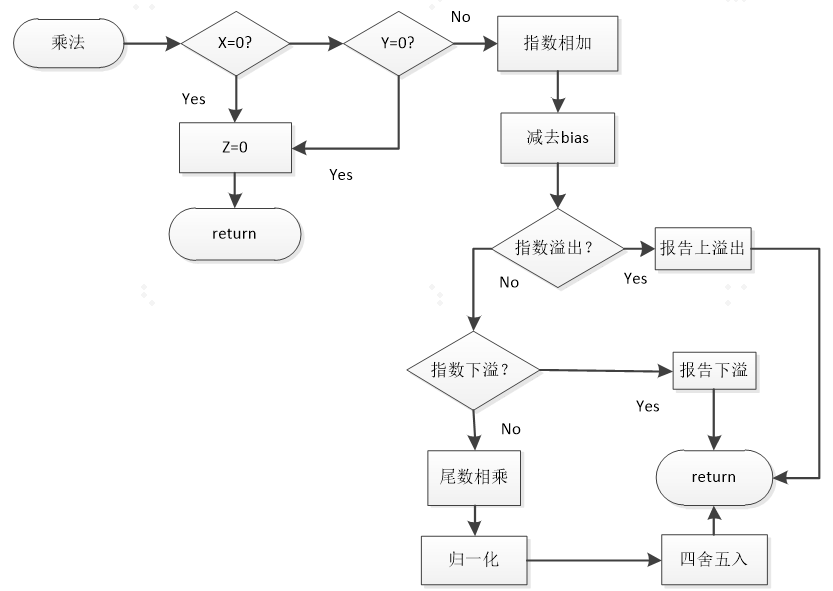
浮点乘法
浮点数的乘法运算是:尾数相乘,指数相加。乘、 除法运算步骤:
1.操作数检查;
2.阶码加操作;
3.尾数乘操作;
4.结果规格化及舍入处理。
5.浮点数的溢出判断
2. verilog数的定点化
数字设计中浮点数定点化的问题其实就是在电路中表示十进制的小数的问题。
位宽
- 一个浮点数用多少位的整数来表示
- 如(16, 2),则表示用16位整数来表达浮点数
- 假设为有符号数
- 则其中:1位为符号位,2位数为表达整数,剩余13位表达(0, 1)的小数
分布如图:
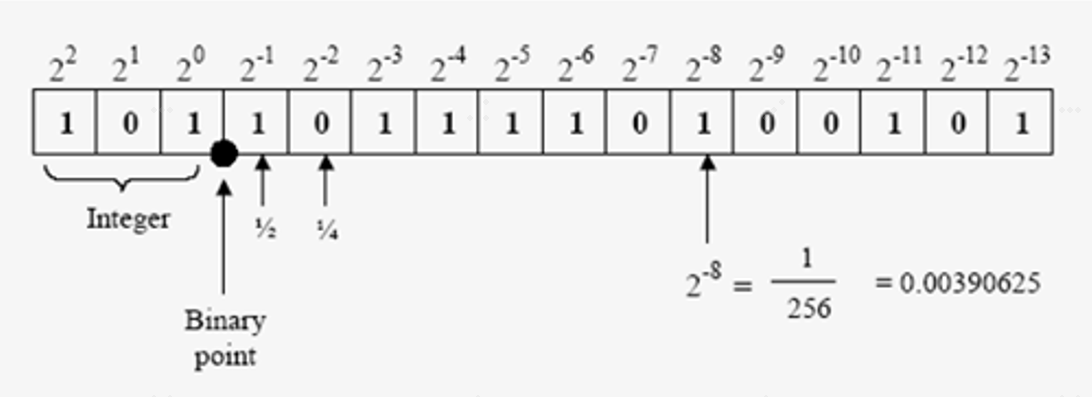
标值
- 即指用多少位,来保存小数
- 若位宽表示为(16, 2),则标值为Q13。
浮点到定点
一句话表达:浮点数乘以2^Q,然后圆整或截断成整数,即得定点数。其中Q为定标值。
总体过程如下图:

由于定点到浮点是浮点转换的逆过程,所以核心只要掌握浮点到定点的映射即可。
主要思路:
- 查看对应变量的浮点值范围
- 取绝对值后,找到最大值,并截断取整为maxNum
- 分析需要多少位来存maxNum,剩余的位数则一个留给符号位,其余位留给小数位
- 如用32位定点存浮点数,用25位来存整数,留1位符号位,剩6位给小数,故位宽表示(32, 25),标值为Q6
- 定点值 $fix=float∗2^6$,将整数左移6位,低6位则是小数转换而来
- 定点能表示的浮点数精度为:126=0.015625,用最小的定点数1,来转化成最小浮点数,得到精度值
定点到浮点
一句话表达:二进制转化为十进制整数,定点整数除以$2^Q$,做浮点运算,结果即为对应浮点数。
总体过程如下图:

主要步骤:
- 知道标值Q,则定点是浮点转换的逆过程
- 公式为 $float=fix*2^{-13}$
- 整数部分,fix右移13位后得到的结果
- 小数部分,就是用定点除法运算fix/2^13的余数mod,(47013%8192=6053*(1/2^13)=0.73889...)。
通常情况下,软件应该依据算法性能的指标推导出每个子算法模块需要用到的Bit_width数,但是由于分工不同,对硬件的sensor没有那么敏感,经常会造成过大的位宽定义,以及硬件接受不了的冗余设计。这里列举几点说明:
1、 通常情况下,权重weight的bit位宽为6~8之间,不建议超过此约束。
2、 数据路径上开窗的大小(3x3)或者(5x5)是非常关乎硬件资源的,决定line_buffer是否增加2行的存储深度。
3、 不建议算法设计除法运算,能用乘替换的替换掉。对于2^n次方的除法或者乘法,建议用左移或者右移来设计。
4、 不建议将中间的某个计算好的变量在后级算法中多次使用,因为硬件有时序的概念,后级需要使用的话,需要将前级的结果用fifo做delay之后再使用,损耗寄存器或者Mem。
5、 算法中的乘法操作数的位宽通常设计为20bit*20bit,不建议设计为40bit*40bit。
6、 在保证算法性能的基础之上,浮点数定点化之后的小数位的位宽能小就小,或者说整体位宽能做多小就做多小。
7、 详细的评估算法的位宽变化之后的面积数据需要综合来支撑,前期评估可以按照经验值系数来折算。
8、 算法中涉及256个32bit模板按照规则(取最大或者最小或者RR或者带权重weight取模板),软件看不到时序概念,硬件是需要分组分级来处理该事件的(指定工艺下时序不过,相当于功能bug,相当于白做),会消耗大的逻辑资源以及lantancy。
9、 软件需要有复用思维,加法器和乘法器能复用就复用,在写法上就能够做到。
自适应滤波器系数定点化举例
滤波器系数更新公式:
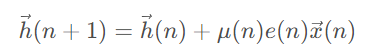
其中NLMS步长:
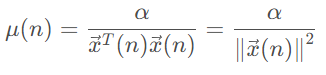
利用更新后的滤波器系数进行自适应滤波:
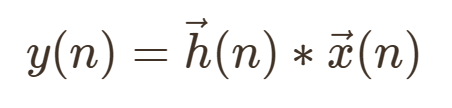
其中
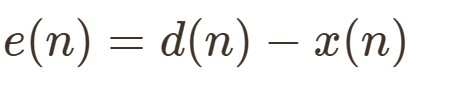
根据滤波器系数更新公式计算得到的自适应计算的滤波器系数$\overrightarrow{h}$总是处于(-1,1)的小数范围内,为了对自适应得到的滤波器系数进行表示,在对滤波器系数进行更新的过程中,稍作修改,手动乘以2的定点化的位数(fp2-1)次方,即$2^(fp2-1)$,改为如下形式,
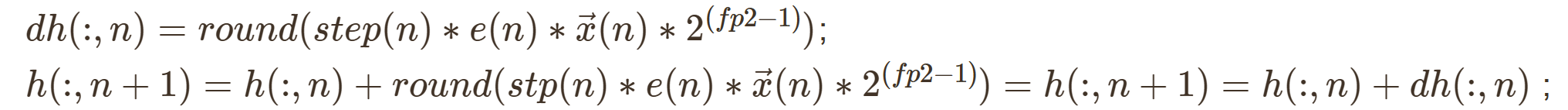
计算自适应滤波器输出