挑战最通俗的KMP算法讲解
什么是 \(KMP\)
KMP是一种用于模式串匹配问题的算法。
给出一个文本串和模式串,查询模式串在文本串中的(出现次数、出现位置等等)的问题称为“模式串匹配问题”。
KMP算法的本质是:针对模式串构建一个特定的数组,用于在匹配失败时减少后续匹配过程中的无用比较,可以将时间复杂度优化到线性。
\(next\) 数组
设文本串为 \(s\),长度为 \(n\);模式串为 \(t\),长度为 \(m\)。
预处理一个 \(next\) 数组,对于 \(next[i]\),它表示在 \(t\) 的前 \(i\) 个字母中,最长公共前后缀的长度。
什么意思呢?我们举个栗子:
比如 \(t\) 是 \(ababaca\),则对应的 \(next\) 数组如下所示:
| \(i\) | \(1\) | \(2\) | \(3\) | \(4\) | \(5\) | \(6\) | \(7\) |
|---|---|---|---|---|---|---|---|
| \(next[i]\) | \(0\) | \(0\) | \(1\) | \(2\) | \(3\) | \(0\) | \(1\) |
\(next[1]\):前缀:{空};后缀:{空}。\(next\):\(0\)
\(next[2]\):前缀:{\(a\)};后缀:{\(b\)}。\(next\):\(0\)
\(next[3]\):前缀:{\(\color{red}a\), \(ab\)};后缀:{\(\color{red}a\), \(ba\)}。\(next\):\(1\)
\(next[4]\):前缀:{\(a\), \(\color{red}ab\), \(aba\)};后缀:{\(b\), \(\color{red}ab\), \(bab\)}。\(next\):\(2\)
\(next[5]\):前缀:{\(a\), \(ab\), \(\color{red}aba\), \(abab\)};后缀:{\(a\), \(ba\), \(\color{red}aba\), \(baba\)}。\(next\):\(3\)
\(next[6]\):前缀:{\(a\), \(ab\), \(aba\), \(abab\), \(ababa\)};后缀:{\(c\), \(ac\), \(bac\), \(abac\), \(babac\)}。\(next\):\(0\)
\(next[7]\):前缀:{\(\color{red}a\), \(ab\), \(aba\), \(abab\), \(ababac\)};后缀:{\(\color{red}a\), \(ca\), \(aca\), \(baca\), \(abaca\), \(babaca\)}。\(next\):\(1\)
如何进行匹配?
这里我们先假设我们已经求出了 \(next\) 数组(马上讲怎么求),我们来看看怎么进行匹配。
因为“next”这个词有可能被判断为关键字,所以接下来我们用“ne”来表示。
首先我们建立两个指针,分别为文本串的和模式串的。
int i = 0, j = 0;
然后,当文本串的指针还没有到达终点时,我们就接着匹配。
while (i < s.size()) {
...
}
如果当前的字母匹配,那就把两个指针都往后移一个字符。
if (s[i] == t[j]) i++, j++;
如果不匹配,那就把 \(j\) 挪动 \(next[j - 1]\) 格。
else if (j > 0) j = ne[j - 1];
如果还是不行,说明这是第一格就不匹配,把 \(i\) 往后挪。
else i++;
如果 \(j\) 到了终点,说明匹配成功。返回模式串匹配的起始坐标即可。
if (j == t.size()) return i - j;
\(next\) 数组的原理 & 如何求 \(next\) 数组?
刚才我们说了:如果不匹配,那就把 \(j\) 挪动 \(next[j - 1]\) 格。为什么可以这么做呢?
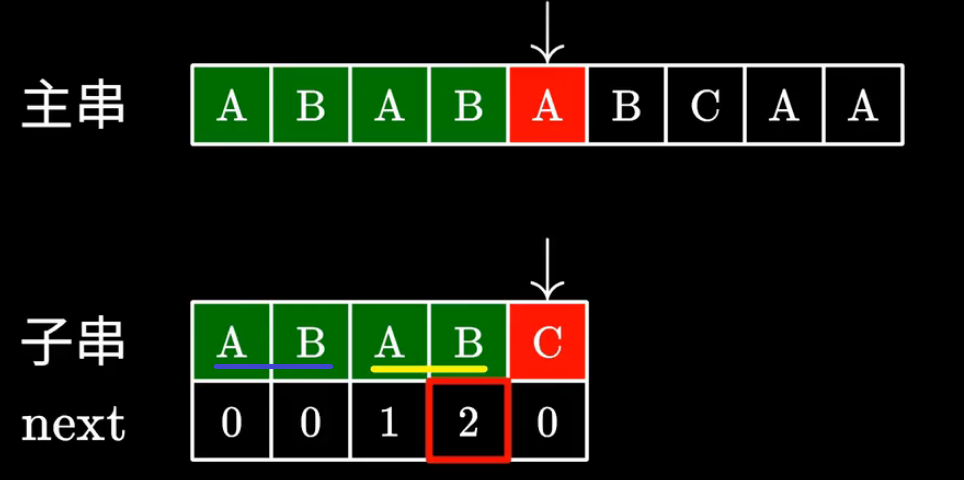
(这里用了一个b站大佬的图)
如上图,可以发现,我们成功匹配的画黄线的两个 \(AB\),和前面跳过的画蓝线的两个 \(AB\) 是完全一样的。所以我们可以直接跳过后两个 \(AB\) 接着匹配;这也就证实了 \(next\) 数组的本质:最长公共前后缀的长度(注意:最长公共前后缀不可以是子串本身,否则我们的移动就没有意义了)。
我们可以用递推的方式来求解 \(next\) 数组,比如我们现在已经知道当前的公共前后缀了,接下来分两种情况讨论:
- 下一个字符还是相同,直接构成了一个更长的公共前后缀;
- 下一个字符不相同了,那我们就再次察看左边的前缀,与右面的后缀再次进行检查下一个字符是否相同,就可以得到下一个字符的 \(next\) 数组了!
那么这样我们的代码实现就很简单了:
void buildnext(string t) {
memset(ne, 0, sizeof ne);
int len = 0; // 当前公共前后缀的长度
int i = 1;
while (i < t.size()) { // 依次生成每个next数值
if (t[len] == t[i]) { // 下一个字符依然相同
len++; // 长度+1
ne[i] = len;
i++;
} else {
if (len == 0) {
ne[i] = 0; // 不存在直接为0
i++;
} else len = ne[len - 1]; // 是否存在更短的前后缀
}
}
}
最后放一下题和代码:

#include <bits/stdc++.h>
using namespace std;
int ne[100010];
void buildnext(string t) {
memset(ne, 0, sizeof ne);
int len = 0;
int i = 1;
while (i < t.size()) {
if (t[len] == t[i]) {
len++;
ne[i] = len;
i++;
} else {
if (len == 0) {
ne[i] = 0;
i++;
} else len = ne[len - 1];
}
}
}
void kmp(string s, string t) {
buildnext(t);
int i = 0, j = 0;
while (i < s.size()) {
if (s[i] == t[j]) i++, j++;
else if (j > 0) j = ne[j - 1];
else i++;
if (j == t.size()) cout << i - j << ' ';
}
}
int main() {
int n, m;
string s, t;
cin >> n >> t >> m >> s;
kmp(s, t);
return 0;
}
码字不易qwq
如果觉得这篇文章还不错的话,请点个赞吧!
如果有任何问题,欢迎在评论区提问,我会尽可能的第一时间回复!