链表
25. K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:

输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]
示例 2:
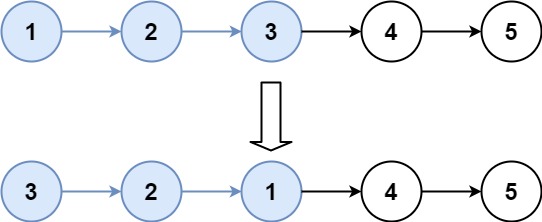
输入:head = [1,2,3,4,5], k = 3
输出:[3,2,1,4,5]
提示:
- 链表中的节点数目为
n 1 <= k <= n <= 50000 <= Node.val <= 1000
关键在于分组 By 笨鸟先飞保间距(注意截断以保证分组无状态),再复用先前的原子操作(逆转链表)
class Solution {
public:
ListNode* reverse(ListNode* head){
ListNode* pre = nullptr;
ListNode* cur = head;
while(cur != nullptr){
ListNode* next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
return pre;
}
ListNode* reverseKGroup(ListNode* head, int k) {
if(head == nullptr || head->next== nullptr || k == 1)
return head;
ListNode* dummy = new ListNode(0);
dummy->next = head;
ListNode* cur = dummy;
while(cur->next != nullptr){
//设置起点在原链表头节点
ListNode* start = cur->next;
//设置终点在新虚拟头节点,保证走 n 步刚好位于原链表的第 n 个位置
ListNode* end = cur;
for(int i = 0; i < k && end!=nullptr; i++){
end = end->next;
}
//长度不足时,直接退出循环,不用进行逆转
if(end == nullptr){
break;
}
//分组处理,保存 next
ListNode* next = end->next;
//保证分组无状态,设置 end->next = nullptr
end->next = nullptr;
//组内翻转
cur->next = reverse(start);
//翻转后 start 为 end,恢复状态
start->next = next;
//更新游标,足量情况下,游标每次步进 k
cur = start;
}
return dummy->next;
}
};
138. 复制带随机指针的链表
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:

输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]
提示:
0 <= n <= 1000-104 <= Node.val <= 104Node.random为null或指向链表中的节点。
关键在于引入哈希表记录原链表的信息,再利用信息构建链表
两次遍历都是利用原链表游标 node,注意在第二次遍历之前重置 node 的值为 head
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
if(!head){
return nullptr;
}
// 创建哈希表
unordered_map<Node*, Node*> map;
// 遍历原链表,创建新节点
Node* node = head;
while(node){
map[node] = new Node(node->val);
node = node->next;
}
// 更新新节点的 next 和 random 指针
node = head;
while(node){
map[node]->next = map[node->next];
map[node]->random = map[node->random];
node=node->next;
}
//注意返回值为 map[head]
return map[head];
}
};
148. 排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:

输入:head = [4,2,1,3]
输出:[1,2,3,4]
示例 2:

输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
示例 3:
输入:head = []
输出:[]
提示:
- 链表中节点的数目在范围
[0, 5 * 104]内 -105 <= Node.val <= 105
class Solution {
public:
ListNode* sortList(ListNode* head) {
//空链表或单节点,直接返回
if (head == nullptr || head->next == nullptr) {
return head;
}
//快慢指针找中点
ListNode* slow = head;
ListNode* fast = head->next;
while (fast != nullptr && fast->next != nullptr) {
slow = slow->next;
fast = fast->next->next;
}
//分治
//获取右侧开头
ListNode* rightHead = slow->next;
//截断
slow->next = nullptr;
//左边归并排序
ListNode* left = sortList(head);
//右边归并排序
ListNode* right = sortList(rightHead);
//归并
return merge(left, right);
}
//归并
ListNode* merge(ListNode* l1, ListNode* l2) {
ListNode dummy(0);
ListNode* cur = &dummy;
// 等效写法,但是这种写法需要手动释放内存
// ListNode* dummy = new ListNode(0);
// ListNode* cur = dummy;
while (l1 != nullptr && l2 != nullptr) {
//将数值较小的接到 cur 上
if (l1->val < l2->val) {
cur->next = l1;
l1 = l1->next;
} else {
cur->next = l2;
l2 = l2->next;
}
cur = cur->next;
}
if (l1 != nullptr) {
cur->next = l1;
}
if (l2 != nullptr) {
cur->next = l2;
}
//注意:声明方法不同,使用方法也不同
return dummy.next;
}
};
23. 合并 K 个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6
示例 2:
输入:lists = []
输出:[]
示例 3:
输入:lists = [[]]
输出:[]
提示:
k == lists.length0 <= k <= 10^40 <= lists[i].length <= 500-10^4 <= lists[i][j] <= 10^4lists[i]按 升序 排列lists[i].length的总和不超过10^4
本质上就是复用上述排序链表的操作,但是引入归并k个链表的逻辑
class Solution {
public:
ListNode* mergeKLists(vector<ListNode*>& lists) {
//若列表为空,直接返回
if (lists.empty()) {
return nullptr;
}
//若列表不为空,即至少存在 2 个需要排序的链表
while (lists.size() > 1) {
//取头两个链表进行归并排序
ListNode* mergedList = mergeTwoLists(lists[0], lists[1]);
//去除已执行过排序的头两个链表
lists.erase(lists.begin());
lists.erase(lists.begin());
//将排好序的链表插入尾部
lists.push_back(mergedList);
}
//全部排序后,得到一个链表
return lists[0];
}
private:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
if (l1 == nullptr) {
return l2;
}
if (l2 == nullptr) {
return l1;
}
ListNode* dummy = new ListNode(-1);
ListNode* curr = dummy;
while (l1 && l2) {
//取数值小的插入到 cur 之后
if (l1->val < l2->val) {
curr->next = l1;
l1 = l1->next;
} else {
curr->next = l2;
l2 = l2->next;
}
curr = curr->next;
}
if (l1) {
curr->next = l1;
}
if (l2) {
curr->next = l2;
}
return dummy->next;
}
};
146. LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 30000 <= key <= 100000 <= value <= 105- 最多调用
2 * 105次get和put
class LRUCache {
private:
int capacity;
list<pair<int, int>> cache;
unordered_map<int, list<pair<int, int>>::iterator> cacheMap;
public: LRUCache(int capacity) {
this->capacity = capacity;
}
int get(int key) {
// 判断key是否存在于缓存中
if (cacheMap.find(key) != cacheMap.end()) {
// 将key对应的pair移到缓存列表的最前面
pair<int, int> keyValue = *cacheMap[key];
cache.erase(cacheMap[key]);
cache.push_front(keyValue);
// 更新key对应的迭代器
cacheMap[key] = cache.begin();
return cacheMap[key]->second;
}
// 如果key不存在,返回-1
return -1;
}
void put(int key, int value) {
// 判断key是否存在于缓存中
if (cacheMap.find(key) != cacheMap.end()) {
// 将key对应的pair移到缓存列表的最前面
cache.erase(cacheMap[key]);
}
// 创建新的pair,并将其放到缓存列表的最前面
cache.push_front(make_pair(key, value));
// 更新key对应的迭代器
cacheMap[key] = cache.begin();
// 如果缓存超过容量,删除最近最久未使用的pair
if (cache.size() > capacity) {
int lastKey = cache.back().first;
cacheMap.erase(lastKey);
cache.pop_back();
}
}
};