凸优化【Convex Optimization】:
求取函数(凸函数)最小值的优化问题
自回归模型:
适合预测时间序列数据
过拟合:
训练集上好(训练误差小),测试集上差(测试误差大)。
或者说属于完全记忆式模型/过度复杂模型
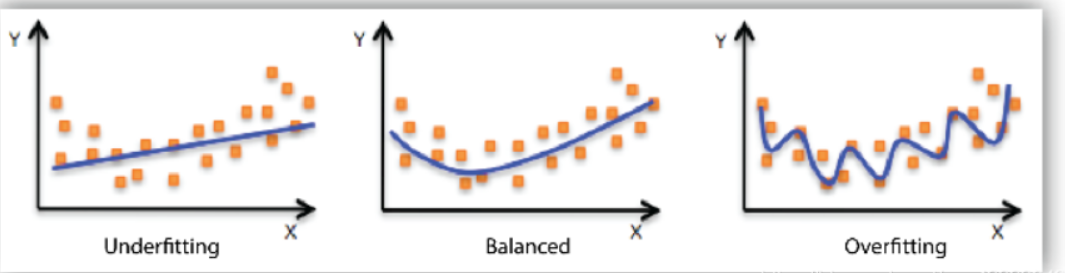
欠拟合 较好 过拟合
解决方法:
a.减少特征数量
b.正则化
L1(特征选择,亦可防止过拟合)
L2(防止过拟合)
激活函数:
引入非线性元素,使n层神经网络不会只是单纯的线性组合
包括:
a.饱和激活函数:Sigmoid tanh -->梯度消失
b.非饱和激活函数: ReLU LeakyReLU gelu -->梯度爆炸
输出置0:
去噪音、 稀疏矩阵
PCA【主成分分析】:
数据降维-->解决数据特征过于庞大
白化:
特征的各向异性变为各向同性-->去除输入信息的冗余性
shuffle:
将训练模型数据集打乱-->数据排列具有随机性,读取样本为任意类型的可能性相同
池化层:
其中没有要学习的参数,故没有梯度计算
包括:
a.平均池化
b.最大池化
卷积——激活——池化
全连接层【Fully Connected Layers】【FC】:
①通过特征提取,实现分类;
②层数增加->长度增加->模型的学习能力上升(如果模型太好了会导致过拟合)
x = x.view(x.size()[0], -1)
x.size()[0] 是选择批次; -1是取剩下的维度进行乘积->保持张量元素数量不变
该操作通常为了将多维张量转换为二维形式,以便后续操作,比如用在FC
感受野:
定义:CNN中每个网格层输出的feature map中的单个元素映射回原始输入特征中区域的大小
特点:
①层数越深,输出特征元素对应感受野越大
②输入结果感受野一致的前提下,连续使用小卷积核替换单个大卷积核,有如下好处:
a.降低网络训练的参数量
b.增加网络深度
c.引入更丰富非线性变换-->使其拟合更多可能性,从而更好缓解过拟合
③网络浅层提取的特征针对输入特征的局部区域进行,感受野较小;
深层对应的感受野更大,可体现原始输入更多的全局信息
④在分类问题中,合理设计网络深度,使最终输出结果感受野>=原始输入特征的大小,从而保证判断时所用特征能够体现原始输入的所有信息
⑤卷积核越大,其生成的feature map单节点的感受野会越大
卷积核:
(一)参数:
kernel_size, stride, padding, channels
(二)参数量计算:
输入卷积: win x Hin x Cin
卷积核:k x k
输出卷积: wout x Hout x Cout
则参数量为 k x k x Cin x Cout
(三) 1x1卷积核的作用:
①增加网络深度:
在不增加感受野的情况、保持feature map尺度不变的情况下,增加非线性特性(后接非线性激活函数,增加了网络的非线性)
②升维、降维
1x1卷积核会使用更少权重参数数量
③跨通道信息交互
如3x3x64的卷积核接1x1x28卷积核后,会变为3x3x28的卷积核-->64个通道通过跨通道线性组合变为28个通道
④减少卷积核参数
Drouput:
只在训练中使用【减少神经元对部分上层神经元的依赖,等价于将不同的网络结构模型组合起来】,测试时应该关闭之【测试时应该用整个训练好的模型】-->使得到的结果更准确
训练和测试过程:
训练: 把原料【训练数据】,按照丹方【如yolo】,倒进丹炉【如caffe框架】, 使用三昧真火【如GPU、CPU】,提炼丹药【模型参数】
测试:用测试数据走一遍上述流程
训练集、验证集、测试集:
训练集(60%):训练模型
验证集(20%):调整、选择模型
测试集(20%):评估最终模型
分类器:
①softmax
②在整个CNN中,FC起分类器作用
上采样:图像增大
下采样:图像缩小