任何操作系统都希望运行比计算机所拥有的CPU数量更多的进程,所以,我们需要一个在进程之间时分CPU的计划,理想状态下,这种共享对用户进程透明。给每一个进程提供它拥有自己的虚拟CPU的通用方式是在多个硬件CPU上多路复用进程。这一张解释了xv6如何实现多路复用。
7.1. 多路复用
xv6会在每个CPU上从一个进程切换到另一个进程来多路复用,这会在两种情况下发生。第一,在一个进程等待设备或pipe I/O完成时,或等待子进程退出时,又或是在sleep系统调用中等待时,xv6的sleep和wakeup机制会执行切换;第二,xv6周期性的强制切换,以处理那种长时间计算又不睡眠的进程。这种多路复用创建了每一个进程拥有自己的CPU的假象,就好像xv6使用内存分配器和硬件页表来创建每一个进程拥有自己的内存的假象。
实现多路复用带来了一些挑战。第一,如何从一个进程切换到另一个?尽管上下文切换这个点子非常简单,但是它们却是xv6中最难以理解的代码;第二,如何以一种对用户进程透明的方式强制切换?xv6使用定时器中断这种驱动上下文切换的标准技术;第三,很多CPU可能并发的在进程间进行切换,为了避免竞争,我们必须要有一个锁计划;第四,一个进程内存以及其它资源必须在进程退出时得到释放,但是这不能完全由进程自己完成,因为(举个例子)它不能在使用内核栈的同时释放自己的内核栈;第五,多核机器的每一个核心必须记录它正在执行的进程,以让系统调用对正确的进程内核状态产生影响;最后,sleep和wakeup允许一个进程放弃CPU,睡眠等待一个事件,并且允许其它进程唤醒第一个进程,需要注意避免会导致丢失唤醒通知的竞争。xv6尝试尽可能简单的解决这些问题,但是尽管这样,最终的代码还是很棘手。
7.2. 代码:上下文切换
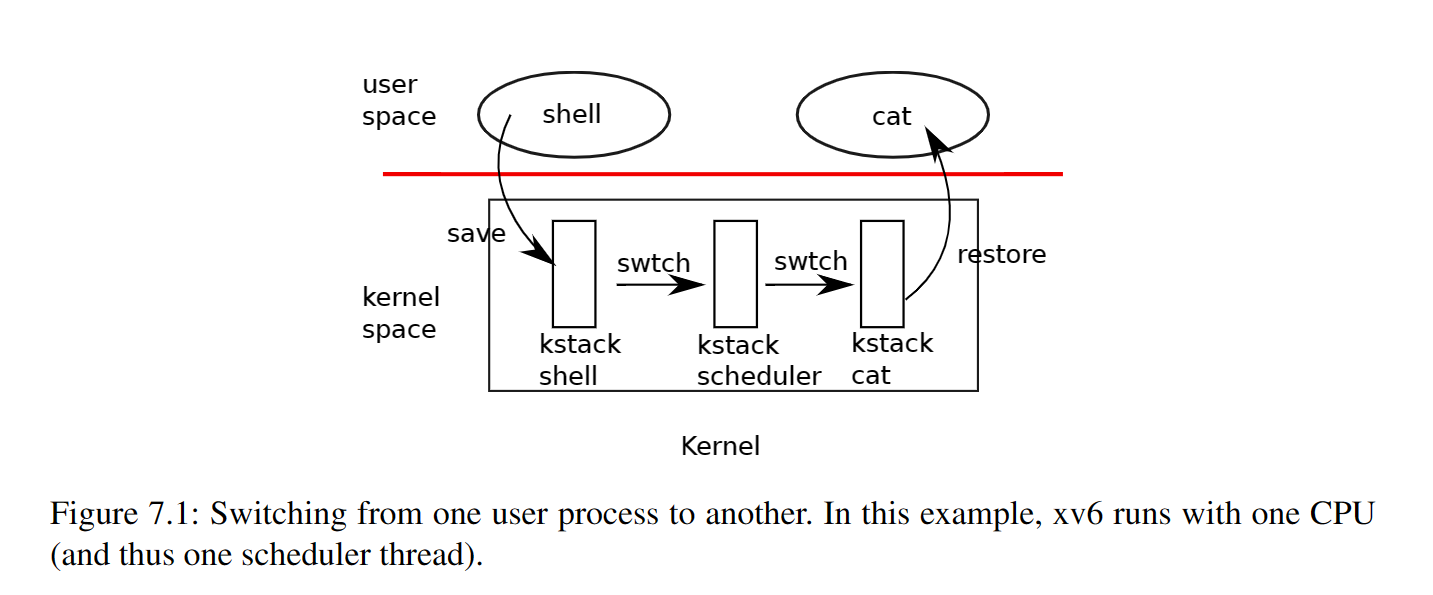
图7.1展示了从一个用户进程切换到另一个用户进程时涉及到的步骤:一个到老进程的内核线程的用户内核态转换(系统调用或中断);一个到当前CPU的调度器线程的上下文切换;一个到新进程内核线程的上下文切换;以及一个到用户级别进程的陷阱返回。xv6的调度器在每一个CPU上有一个专用线程(以及保存的寄存器和栈),因为对于调度器来说,执行在老进程的内核栈上是不安全的:一些其它的内核可能会唤醒进程并运行它,在两个不同的内核上使用相同的栈将会是一场灾难。在这一部分,我们将会介绍从内核线程和调度器线程之间的转换机制。
译者:虽然这里总是提到线程,比如内核线程、调度器线程,如果你看了公开课的话,甚至还有每个进程一个的用户线程,但实际上,xv6的代码中(至少是这一章涉及到的代码)中并没有线程的影子,这可能有点迷惑。实际上,所谓线程,不过就是一个独立的执行单元,它有自己的栈,独立运行在CPU上,并持有CPU状态(那些寄存器)。在xv6中,用户进程有自己的执行栈,它执行在CPU上,并且持有CPU的状态,当由于某些原因进入内核时(系统调用或中断),用户进程的CPU状态会得到保存(保存到进程的trapframe中),并切换到该进程的内核栈执行。到此为止,虽然xv6的代码中没有显式的写出线程的概念,但我们已经可以看作我们有了两个独立的线程,一个是进程的用户线程,一个是进程的内核线程。在内核由于某些原因决定切换进程时(当前进程等待IO或者发生时钟中断,此时一定在老进程的内核或者说内核线程中执行),此时需要将内核线程的CPU状态保存(保存到进程的context中),然后将当前执行栈由进程的内核栈切换到CPU调度程序的栈上。正是因为此,我们会说xv6中有三种线程,每个进程唯一的用户线程、每个进程唯一的内核线程以及每个CPU唯一的调度器线程。
由于很多东西还没解释,如果你没有看过公开课,那么上面所说的内容可能有点难以理解,反正,能理解多少理解多少,当你看到后面感觉自己被各种线程的概念弄得很迷糊,你就可以回来再看看这段话。
从一个线程切换到另一个线程需要涉及到保存老线程的CPU寄存器,以及恢复先前被保存的新线程的寄存器。栈指针以及程序计数器的保存和恢复意味着CPU将切换执行栈以及切换当前正在执行的代码。
对于一个内核线程的切换,swtch函数执行保存和恢复。swtch对线程一无所知,它只是保存并恢复寄存器集合,我们称之为上下文(context)。当一个进程已经到了要放弃CPU的时间,进程的内核线程调用swtch来保存它自己的上下文,并返回到调度器的上下文。每一个上下文都被保存在struct context(kernel/proc.h:2)中,而在一个进程中,context本身被保存在struct proc中,或在一个CPU上,它被保存在struct cpu中。swtch接收两个参数,struct context *old以及struct context *new,它将当前寄存器保存到old中,并从new中加载寄存器并返回。
# 上下文切换
#
# void swtch(struct context *old, struct context *new);
#
# 将当前寄存器保存到old中,并从new中加载恢复寄存器
.globl swtch
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
ret
译者:不同于
trampoline是通过跳转指令直接跳过来的,swtch是使用一次常规的函数调用进入的,所以swtch函数中只保存了callee-saved寄存器,那些caller-saved寄存器会被调用者自己保存到自己的栈上,也会被它们自己恢复,swtch无需关心这些。
// Saved registers for kernel context switches.
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
我们跟踪一个进程通过swtch到达调度器的过程。在第四章,我们看到过在一个中断的末尾,usertrap有可能调用yield。yield随即调用sched,sched调用swtch来向p->context中保存当前上下文,并切换到之前保存在cpu->scheduler中的调度器上下文(kernel/proc.c:509)。
void
usertrap(void)
{
int which_dev = 0;
// ...
// 判断是否是设备中断
} else if((which_dev = devintr()) != 0){
// ok
}
// ...
// 如果是一次时钟中断,主动放弃cpu
if(which_dev == 2)
yield();
usertrapret();
}
// 让出CPU
void
yield(void)
{
struct proc *p = myproc();
acquire(&p->lock);
p->state = RUNNABLE; // 设置当前进程状态为就绪态
sched(); // 调用sched,该函数的目的是从内核线程进入到调度器线程
release(&p->lock);
}
void
sched(void)
{
int intena;
struct proc *p = myproc();
// 一些合法性校验
if(!holding(&p->lock))
panic("sched p->lock");
if(mycpu()->noff != 1)
panic("sched locks");
if(p->state == RUNNING)
panic("sched running");
if(intr_get())
panic("sched interruptible");
// 记录当前中断状态
intena = mycpu()->intena;
// 切换到调度器线程上下文执行
swtch(&p->context, &mycpu()->context);
// 恢复中断状态
mycpu()->intena = intena;
}
swtch只保存了callee-saved寄存器:caller-saved寄存器会在栈上(如果需要的话)被正在发起调用的C代码保存。swtch知道载struct context中每一个寄存器属性的偏移量。它不保存程序计数器,取而代之的是,swtch保存了ra寄存器,它持有了swtch被调用处的返回地址。现在swtch从新上下文中恢复寄存器,新上下文中持有着被上一次调用时swtch保存的寄存器值。当swtch返回,它返回到被恢复的ra寄存器指向的指令,也就是新线程之前调用swtch处的指令,并且它返回到一个新的线程栈(通过恢复sp寄存器)。
在我们的例子中,sched调用swtch来切换到cpu->scheduler——也就是每一个CPU的调度器上下文。这个上下文被scheduler的swtch调用保存(kernel/proc.c:475)。当我们追踪的swtch返回,它并不会返回到sched,而是返回到scheduler,它的栈指针指向到当前CPU的调度器栈。
// 每个CPU上的进程调度器
// 在设置完自己后,每一个CPU都调用scheduler()
// scheduler永不反悔,它循环做下面的事:
// - 选择一个要运行的进程
// - swtch以开始执行这个进程
// - 最终这个进程通过swtch将控制转移回调度器
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
intr_on();
int nproc = 0;
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state != UNUSED) {
nproc++;
}
if(p->state == RUNNABLE) {
// 切换到选中的进程
// 该进程需要释放上面加的锁,并在跳回这里之前重新加锁
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
c->proc = 0;
}
release(&p->lock);
}
if(nproc <= 2) {
intr_on();
asm volatile("wfi");
}
}
}
译者:如果没在公开课里跟老师用GDB走一遍整个线程切换的过程,可能很难理解上面的内容,我尝试用语言来解释一下,不涉及到代码。
swtch在两个上下文间跳转,当内核感觉是时候从当前进程切换到另一个进程执行了(可能由于IO系统调用或定时器中断),它会调用swtch,将自己的上下文(实际上就是寄存器信息)保存在p->context中,ra指向了从另一个进程返回时要返回到的指令位置,实际上就是本次调用swtch的指令位置,sp指向了当前进程的(内核)栈。swtch从新的context中加载保存的寄存器,也就是CPU调度器的上下文,加载它的ra,这样当swtch执行ret返回时就会返回到CPU调度器上正确的指令位置,加载它的sp,以在CPU调度器的栈上执行,CPU调度器的上下文会在上一次调度器想要运行某一个线程时被保存在cpu->context中,同样也是通过swtch保存的。当调度器想要调度一个进程时,和上面的思路也一样,通过swtch保存自己的上下文到cpu->context,最重要的是保存下次切换过来时的ra,以及sp,然后加载要调度的进程的上下文。如果这样说,那么无论是进程还是CPU调度器,都必须有最初始的一次
context初始化,要不然切换的时候换到哪里?
实际上,在allocproc中(kernel/proc.c:126)处做了进程的context最初的初始化工作,将ra设置为forkret函数的位置,将sp设置为内核栈,将其它寄存器全都设置成0,所以一个进程最初被调度器调度时会由swtch返回到forkret,但在代码中看不到任何实际的调用。对于CPU调度器的初始化,我也不知道在哪......
7.3. 代码:调度
在最后一部分我们将看到swtch的底层细节,现在,我们假设swtch已经给定,然后来研究从一个进程的内核线程通过调度器到另一个进程的切换过程。调度器在每一个CPU上以一个特殊线程的形式存在,每一个都运行scheduler函数。这个函数负责选择接下来运行哪一个进程。一个想要放弃CPU的进程必须获取它自己的进程锁p->lock,释放任何它持有的其它锁,更新它自己的状态(p->state),然后调用sched。yield(kernel/proc.c:515)函数遵循了这个约定,我们稍后要介绍的sleep以及exit也是。sched重新检测了这些条件(kernel/proc.c:499-504)以及一个在这些条件中隐含的条件:一旦锁被持有了,中断必须被禁用。最后,sched调用swtch来在p->context中保存当前上下文,切换到在cpu->scheduler中的调度器上下文。swtch返回到调度器的栈上,就好像scheduler中的swtch真的已经返回了一样。调度器继续执行for循环,找到一个进程来运行,循环往复。
我们刚刚看到了xv6在调用swtch调用过程中持有了p->lock:swtch的调用者必须已经持有锁,然后该锁的控制权转移到了要切换到的代码中。这并不是一个常见的锁的用法。通常,获取锁的线程也有责任来释放锁,这让推理正确性变得简单。对于上下文切换,我们必须打破这个惯例,因为p->lock保护了在进程的state以及context属性上的不变式,当在swtch中执行时,这些不变式并不为真。如果在swtch期间没有持有p->lock,一个可能发生的问题的示例是:另一个CPU可能在yield已经将它的状态设置成RUNNABLE之后,但swtch还没有让它停止使用自己的内核栈之前决定执行该进程,最后的结果就是两个CPU在一个栈上运行,这不正确。
一个内核线程总是在sched中放弃它的CPU,并且总是切换到scheduler的相同位置,而scheduler(几乎)总是切换到之前调用sched的某个内核线程。因此,如果要打印出xv6切换线程的行号,你可以观察到如下的简单模式:(kernel/proc.c:475), (kernel/proc.c:509), (kernel/proc.c:475), (kernel/proc.c:509),等等。以这种风格在两个线程之间发生切换有时被称为协程:在这个例子中,sched和scheduler是对方的协程。
有一种情况下,调度器调用swtch不会走到sched中。当一个新进程第一次被调度,它从forkret(kernel/proc.c:527)开始。Forkret exists to release the p->lock; otherwise, the new process could start at usertrapret.
scheduler(kernel/proc.c:457)运行一个简单的循环:找到一个要运行的进程,运行直到它yield,重复这个过程。调度器循环遍历进程表来找到一个就绪进程,就是p->state == RUNNABLE的进程。一旦它找到一个进程,它设置CPU的当前进程变量c->proc,标记该进程为RUNNING状态,然后调用swtch以开始运行它(kernel/proc.c:470-475)
思考调度代码的一种方式是,它保护关于每一个进程的一组不变式,只要这些不变式不为真时就持有p->lock。一个不变式是如果一个进程是RUNNING,那么一个时钟中断的yield必须能够安全的从这个进程切换走,这意味着CPU寄存器必须保持着该进程的寄存器值(比如swtch没有将它们移动到一个context中),并且c->proc必须指向这个进程。另一个不变式是如果一个进程是RUNNABLE,对于一个空闲的CPU的scheduler,运行它必须是安全的,这意味着p->context必须保存了进程的寄存器(比如,它们实际上没有在真实的寄存器中),没有CPU正在这个进程的内核栈上执行,并且没有CPU的c->proc指向了这个进程。当p->lock被持有时,观察这些属性通常不会为真。
维护上面的不变式是xv6经常在一个线程中获取p->lock,并在另一个线程中释放它的原因,比如在yield中获取并在scheduler中释放。一旦yield开始修改运行进程的状态到RUNNABLE,这个锁必须保持持有,直到所有不变式都被恢复:最早的正确释放点是在scheduler(运行在它自己的栈上)清除了c->proc之后。相似的,一旦scheduler开始将一个RUNNABLE进程转换到RUNNING,直到内核线程完全运行前都不能释放锁(在yield的例子中是在swtch之后)。
p->lock也保护了其它东西:exit和wait之间的交互,避免丢失唤醒的机制(在第7.5章),以及在一个正在退出的进程以及另一个正在读取或写入它状态的进程之间避免竞争(比如exit系统调用查看p->pid并设置p->killed(kernel/proc.c:611))。为了清晰或者为了性能起见,考虑是否为不同的功能拆分p->lock是值得的。
7.4. 代码:mycpu和myproc
xv6通常需要一个指向当前进程的proc结构体的指针。在但处理器中,可能有一个全局的变量指向当前的proc,但这在多喝机器上不可行,因为每一个核心都执行一个不同的进程。解决这个问题的方式是利用每一个核心都有自己的寄存器集合的事实,我们可以使用这些寄存器中的一个来帮助我们找到每个核心的信息。
xv6为每个CPU(kernel/proc.h:22)维护了一个struct cpu,它可以记录当前运行在CPU上的进程(如果有),记录为CPU调度线程保存的寄存器,以及嵌套的自旋锁的个数,我们需要使用它管理中断的禁用。mycpu函数(kernel/proc.c:60)返回一个指向当前CPU的struct cpu的指针。RISC-V为它的CPU编号,给每一个CPU一个hartid。xv6确保在内核中时,每一个CPU的hartid存储在了这个CPU的tp寄存器上。这允许mycpu使用tp来索引cpu结构体的数组以找到正确的那个。
确保一个CPU的tp总是持有着CPU的hartid有一点点复杂。在CPU的启动序列的早期,mstart设置tp寄存器,此时还在machine模式(kernel/start.c:46)。在trampoline页面,usertrapret保存了tp,因为用户进程可能修改tp。最后,当从用户空间进入内核时(kernel/trampoline.S:70)uservec恢复保存的tp。编译器保证永远不会使用tp寄存器。如果RISC-V允许xv6直接读取当前的hartid将会更加方便,但是这只在机器模式下被允许,在supervisor模式下则不行。
cpuid以及mycpu的返回值是脆弱的:如果定时器中断导致线程让步,然后移动到另一个不同的CPU,那么之前的返回值将不再是正确的。为了避免这个问题,xv6要求调用者禁用中断,并且只有在用完返回的struct cpu后才能开启中断。
myproc函数(kernel/proc.c:68)返回了运行在当前CPU上的进程的struct proc指针。myproc禁用了中断,调用mycpu,从struct cpu中获取当前的进程指针c->proc,然后启用中断。myproc的返回值即使在中断开启的情况下也是安全的:如果一个时钟中断移动调用进程到另一个CPU,struct proc的指针将会保持一致。