<script src="http://latex.codecogs.com/latex.js" type="text/javascript"></script>
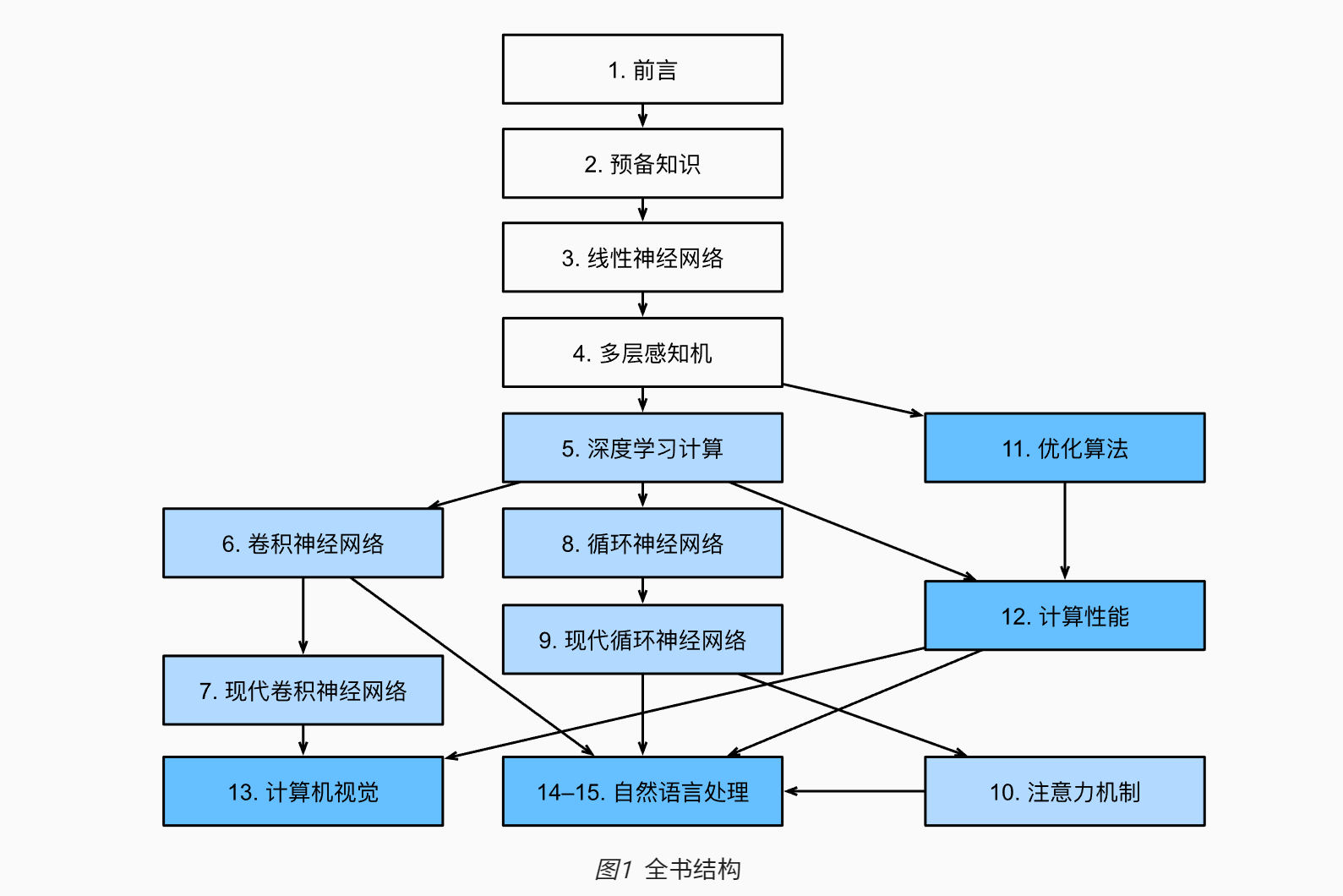
引言
一:过去⼗年中取 得巨⼤进步的想法
1.如dropout (Srivastava et al., 2014),有助于减轻过拟合的危险。这是通过在整个神 经⽹络中应⽤噪声注⼊ (Bishop, 1995) 来实现的,出于训练⽬的,⽤随机变量来代替权重
2.注意⼒机制解决了困扰统计学⼀个多世纪的问题:如何在不增加可学习参数的情况下增加系统的记忆 和复杂性。
3.多阶段设计
4.GAN
5.随机梯度下降
6.并行计算能力
7.深度学习框架
⼈⼯智能系统是以⼀种 特定的、⾯向⽬标的⽅式设计、训练和部署的。虽然他们的⾏为可能会给⼈⼀种通⽤智能的错觉,但设计的 基础是规则、启发式和统计模型的结合。其次,⽬前还不存在能够⾃我改进、⾃我推理、能够在试图解决⼀ 般任务的同时,修改、扩展和改进⾃⼰的架构的“⼈⼯通⽤智能”⼯具
预备知识
1.广播机制
形状不同的张量运算。复制/按元素操作
2.索引和切片
[1:3]选择第二个和第三个元素
[0:2,:] 第一行和第二行所有元素
3.注意原地分配内存
X[:] = X + Y或X += Y
4.pandas.get_dummies
是pandas中一种非常高效的方法。它最主要的作用是可以将分类变量转变成dummy变量,也就是虚拟变量
5.对⾮标量调⽤backward
需要传⼊⼀个gradient参数,该参数指定微分函数关于self的梯度
6.分离计算
u = y.detach()
7.b.norm()
是一个 PyTorch 中的方法,用于计算张量 b 的 L2 范数(也称为欧几里得范数)。具体地,L2 范数是指一个向量中所有元素的平方和的平方根2
8.torch.randn()
方法生成一个具有随机值的张量,其值是从均值为 0,标准差为 1 的正态分布中随机抽取的。这个方法的输入参数是一个元组,用于指定张量的形状
9.两次反向传播会报错
loss.backward(retain_graph=True)这样设置后就不会了,第二次的backward其实把梯度再次回传一遍叠加在了第一次上面10.执行loss.backward()时带参数,就可以计算随机向量或矩阵
11.multinomial.Multinomial(1, fair_probs)
是一个 PyTorch 中的方法,用于创建一个多项式分布对象,该分布对象的参数为 1 和 fair_probs。其中,第一个参数 1 表示抽样次数为 1,第二个参数 fair_probs 表示每个元素的概率分布
sample() 是一个 PyTorch 中的方法,用于从多项式分布中抽样
线性神经网络
1. 线性回归的解析解:
通过数学公式直接计算出最优的回归系数的方法,而不是通过迭代算法(如梯度下降)来计算
min ||y - Xb||2
其中,||.||2表示欧几里得范数,y是因变量向量,X是自变量矩阵,b是回归系数向量。
b = (XTX)-1XTy
这个公式就是线性回归的解析解,它直接计算出最优的回归系数
2. 泛化:
找到一组参数使得这组参数能够再我们从未见过的数据上实现较低的损失
3. 矢量化代码:
带来数量级的加速,更多的数学运算放到库中
4. f'{time.stop():.5f} sec'
- time.stop() 表示调用名为 stop 的函数,返回一个时间值(通常是秒数)。
- :.5f 表示将这个时间值格式化为一个浮点数,并保留 5 位小数。
- sec 表示在最后输出一个字符串 "sec",表示这个时间值是秒数
5. 高斯噪声的假设下,最小化均方误差等价于对线性模型的极大似然估计
6. 线性回归算法
过程:
简单表达:
next(iter(data_iter))
- iter(data_iter):表示使用 iter() 函数将数据迭代器 data_iter 转换为一个迭代器对象,以便在后续的代码中使用 next() 函数逐个取出数据样本。
- next(iter(data_iter)):表示使用 next() 函数从迭代器对象中取出下一个数据样本。在这里,iter(data_iter) 的作用是将数据迭代器转换为迭代器对象,以便使用 next() 函数逐个取出数据样本。
net[0].weight.data.normal_(0,0.01)
net[0].bias.data.fill_(0)
- net[0].weight.data.normal_(0,0.01):使用正态分布来初始化权重,其中平均值为0,标准差为0.01。这个操作将在net神经网络的第一层中的权重数据上执行,即net的第一个nn.Linear层的权重数据。这个操作将使权重数据随机地从一个平均值为0、标准差为0.01的正态分布中取样,然后用这些值来初始化权重。
- net[0].bias.data.fill_(0):将偏置设置为0。这个操作将在net神经网络的第一层中的偏置数据上执行,即net的第一个nn.Linear层的偏置数据。这个操作将把偏置数据设置为0。
7. softmax函数
非负和为1 同时让模型保持可导
$\hat{y}_{j}=\frac{\exp \left(o_{j}\right)}{\sum_{k} \exp \left(o_{k}\right)}$
通常用于多分类问题中,将一组任意实数转化为一个概率分布,exp是自然指数函数,sum是对所有j的求和。通过指数函数将原始的实数转化为正数,然后再将其归一化
从零开始实现:
8.计算损失的三种方法
a) 最小二乘
b) 极大似然估计 结果去反推概率模型
c) 交叉熵损失 i)从最大似然角度 ii)从信息量角度
加起来的熵越大系统越不确定
单个信息量想要贡献给整体需要乘以自己的比例
相对熵: KL散度
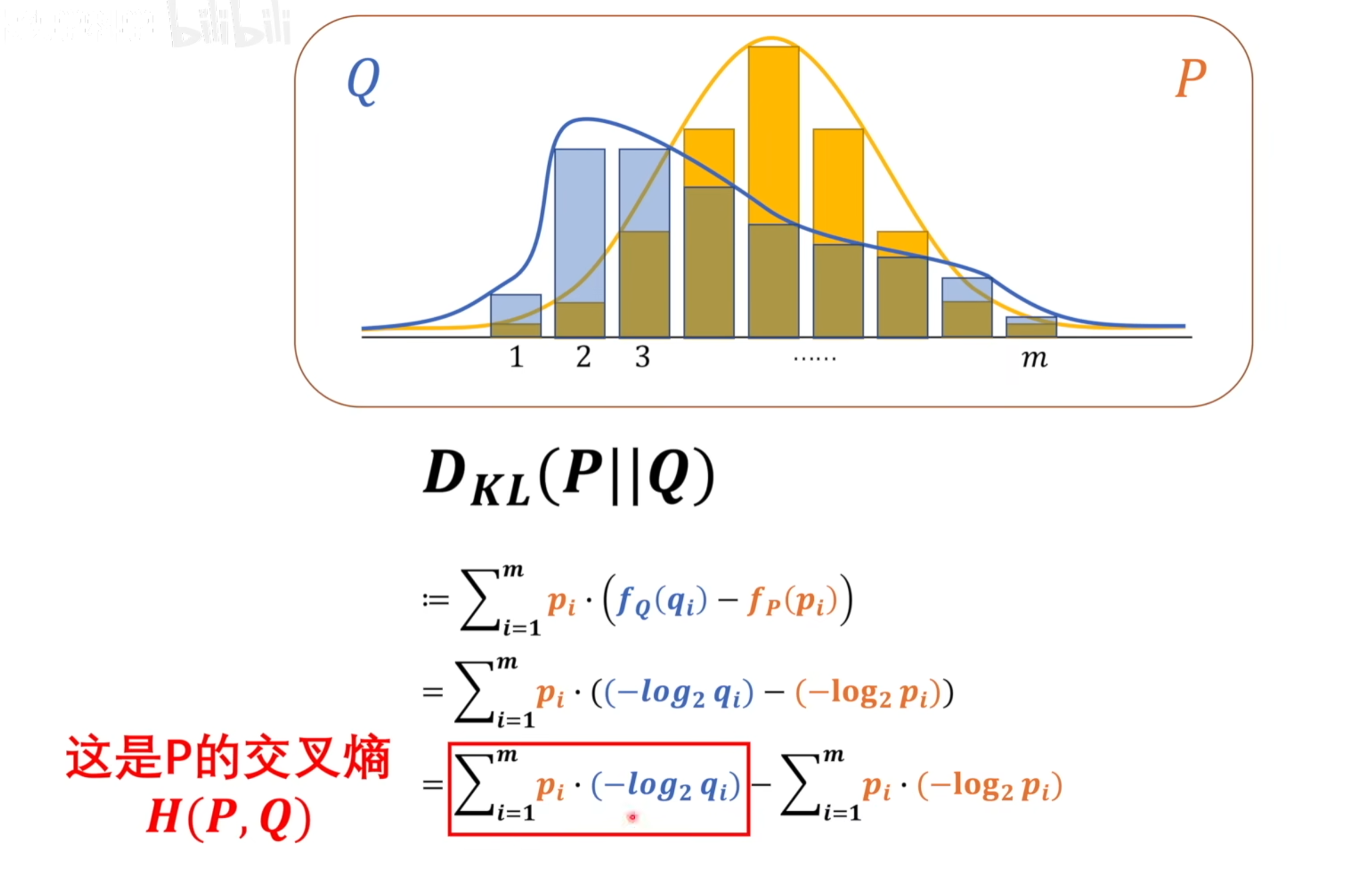
交叉熵越小,模型越接近,以2为底代表计算出来的信息熵单位比特,(纳特约等于1.44比特,以e为底的对数)
9. transforms.Compose(trans)
将这些变换组合在一起并返回一个新的变换对象 trans
10. net.eval()
将神经网络设置为评估模式。在评估模式下,神经网络的行为会有所不同,主要是为了减少内存占用和加快推理速度。在评估模式下,通常会关闭 dropout 和 batch normalization 层,并且不会计算梯度。这个函数通常用于在测试数据集上进行推理时,以确保神经网络的输出是正确的
11. metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
这行代码是用来更新指定的度量指标的。metric 是一个 AccuracyMetric 实例,它包含了准确率的计算方法。add 方法用来将当前批次的预测结果、真实标签和样本数量传递给 AccuracyMetric 实例,并更新准确率指标的值。具体来说,l.sum() 是当前批次的损失值之和,accuracy(y_hat, y) 是当前批次的准确率,y.numel() 是当前批次的样本数量。