Hash索引:
Hash索引引用其实不多,最主要是因为最常见的存储引擎InnoDB不支持显示地创建Hash索引,只支持自适应Hash索引。
虽然可以使用sql语句在InnoDB声明Hash索引,但是其实是不生效的。
在存储引擎中,Memory引擎支持Hash索引
Hash索引底层有点像Java中HashMap底层的数据结构,他也有很多槽点,存的也是键值对,键值为索引列,值为数据的这条数据的行指针,通过行指针就可以找到数据。
假设现在user表用Memory存储引擎,对name字段建立Hash索引。
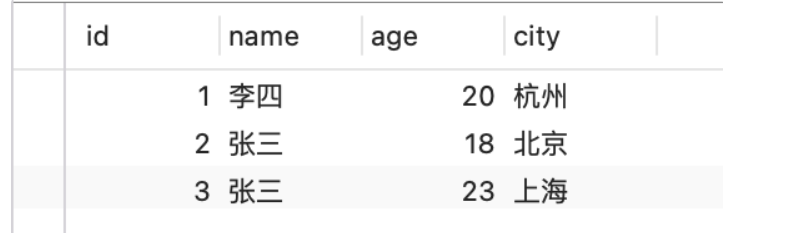
Hash索引就会对索引列name的值进行Hash计算,然后找到对应的槽点下面
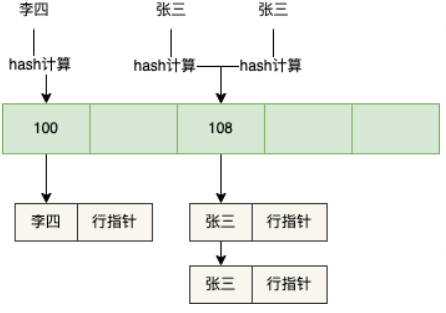
当遇到name字段的Hash值相同时,也就是Hash冲突,就会形成一个链表,比如name=张三就有两条数据,就会形成一个链表。
之后如果name=李四的数据,只需要对李四进行Hash计算,找到李四进行Hash计算,找到对应的槽点,遍历链表,取出name = 李四对应的行指针,然后根据行指针去查找对应的数据
Hash索引的缺点:
hash索引只能用于等值比较,所以查询效率非常高
不支持范围查询,也不支持排序,因为索引列的分布是无序的
什么是聚集索引与非聚集索引和区别?
按物理存储分类:InnoDB的存储方式是聚集索引,MyISAM的存储方式是非聚集索引。

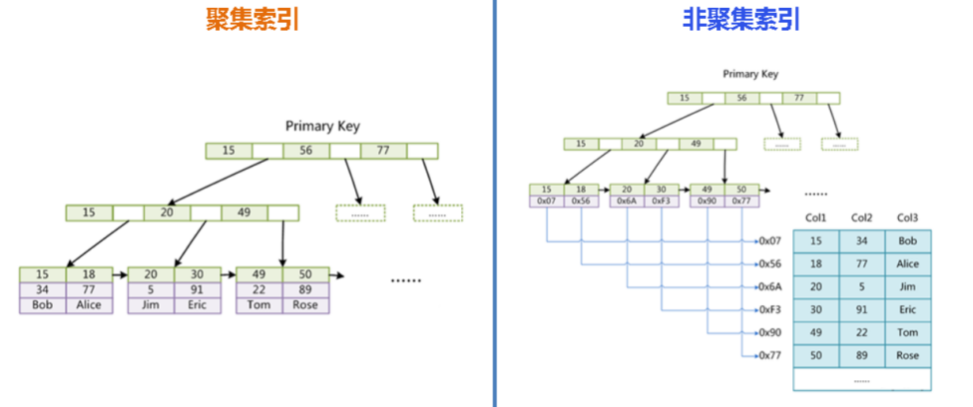
聚集索引:
1.聚集索引将数据存在索引树的叶子节点上。
2.聚集索引可以减少一次查询,因为查询索引树的同时就可以获取到数据。
3.聚集索引的缺点是,对数据进行修改或者删除操作时需要更新索引树,会增加系统的开销。
4.聚集索引通常用于数据库系统中,主要用于提高查询效率。
非聚集索引(又称二级索引 / 辅助索引)
1.非聚集索引不将数据存储到索引树的叶子节点上,而是存储在数据页中。
2.非聚集索引在查询数据时需要两次查询,一次查询索引树,获取数据页的地址,再通过数据页的地址查询数据(通常情况下来说是的,但是如果索引覆盖的话实际上是不用回表的)
3.非聚集索引的优点是:对数据进行修改或者删除时不需要更新索引树,减少系统的开销。
4.非聚集索引通常用于数据库系统中,主要用于提高数据更新和删除操作的效率。
二级索引:
在mysql中,创建一张表时会默认为主键创建聚集索引,B+树将表中所有的数据组织起来,即数据就是索引主键,所以在InnoDB里,主键索引也被称为聚集索引,索引的叶子节点存的是整行数据。
而除了聚集索引以外的所有索引都被称为二级索引,二级索引的叶子节点内容是主键的值。
可以理解为:除了主键索引以外,其他的所有索引都是非聚集索引
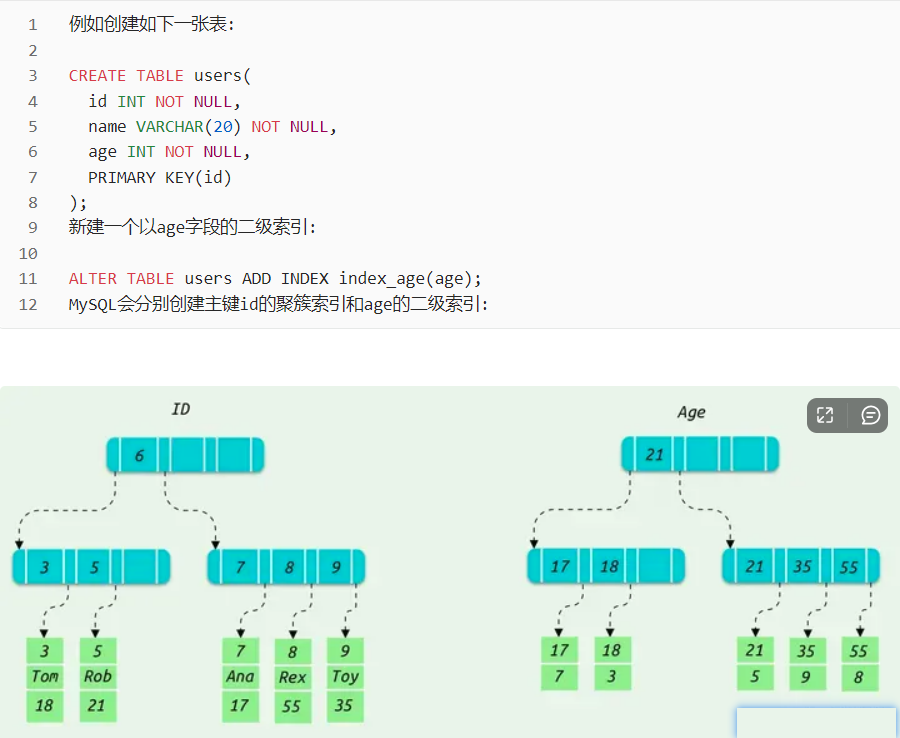
回表:
例如执行下面这条sql则需要进行回表:
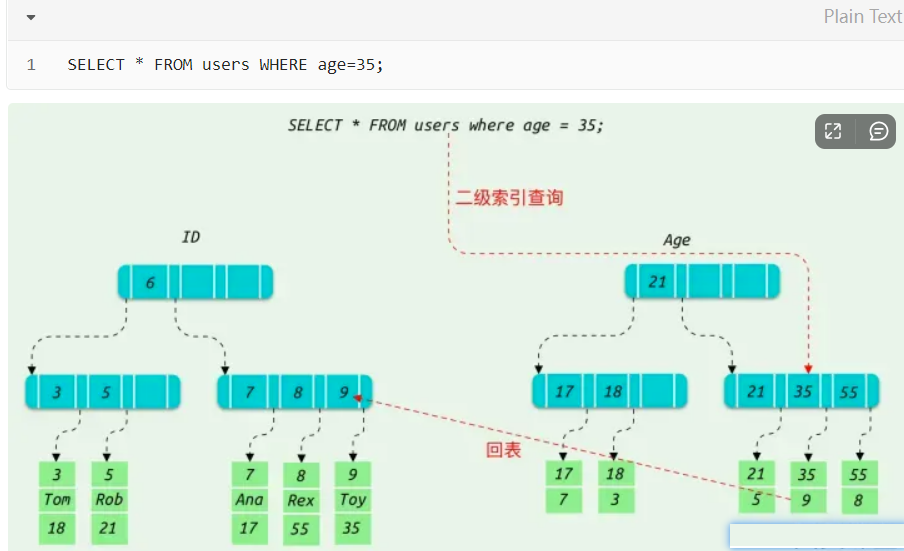
由于条件查询是 age = 35 所以会走age索引
整个过程大致分为以下几个步骤:
1:从根节点开始,21<35 定位右边存储的指针
2:在索叶子节点找到35的第一条数据记录,也就是id = 9的那条
3:由于select * 还要查询其他字段,此时就会根据id = 9到聚集索引(主键索引)中查找其他字段数据
这个根据id = 9到聚集索引中查找数据的过程就称为回表
覆盖索引
当执行select * from user where age = 35;这条sql的时候,会先从索页中查出来age = 35;对应的主键id,之后再回表,到聚簇索引中查询其它字段的值。
那么当执行
select id from user where age = 35;
又会怎样呢?
这次查询字段从select *变成select id,查询条件不变,所以也会走age索引
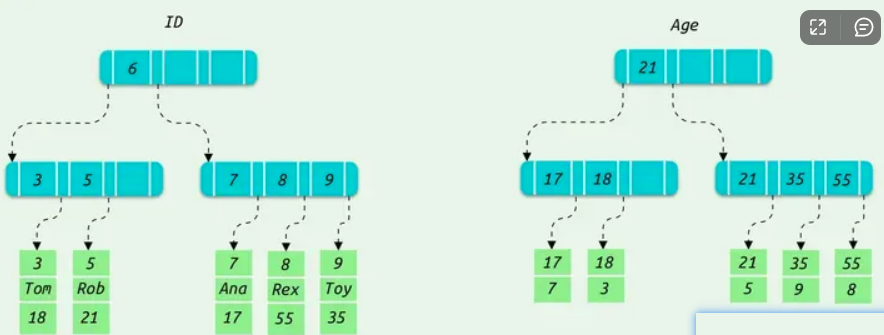
所以还是跟前面一样了,先从索引页中查出来age = 35;对应的主键id之后,惊讶的发现,sl中需要查询字段的id值已经查到了,那次此时压根就不需要回表了,已经查到id了。
这种需要查询的字段都在索引列中的情况就被称为覆盖索引,索引列覆盖了查询字段的意思。当使用覆盖索引时会减少回表的次数,这样查询速度更快,性能更高。
所以,在日常开发中,尽量不要select*,需要什么查什么,如果出现覆盖索引的情况,查询会快很多。
索引下推
是在 MySQL 5.6 针对描二级索引的一项优化改进。用来在范围查询时减少回表的次数。ICP 适用于 MYISAM 和INNODB。(模糊查询也算是范围查询)
ALTER TABLE user ADD INDEX ('name','age');
#不使用索引下推实现
SELECT * FROM user1 WHERE name LIKE 'A%' and age = 40;
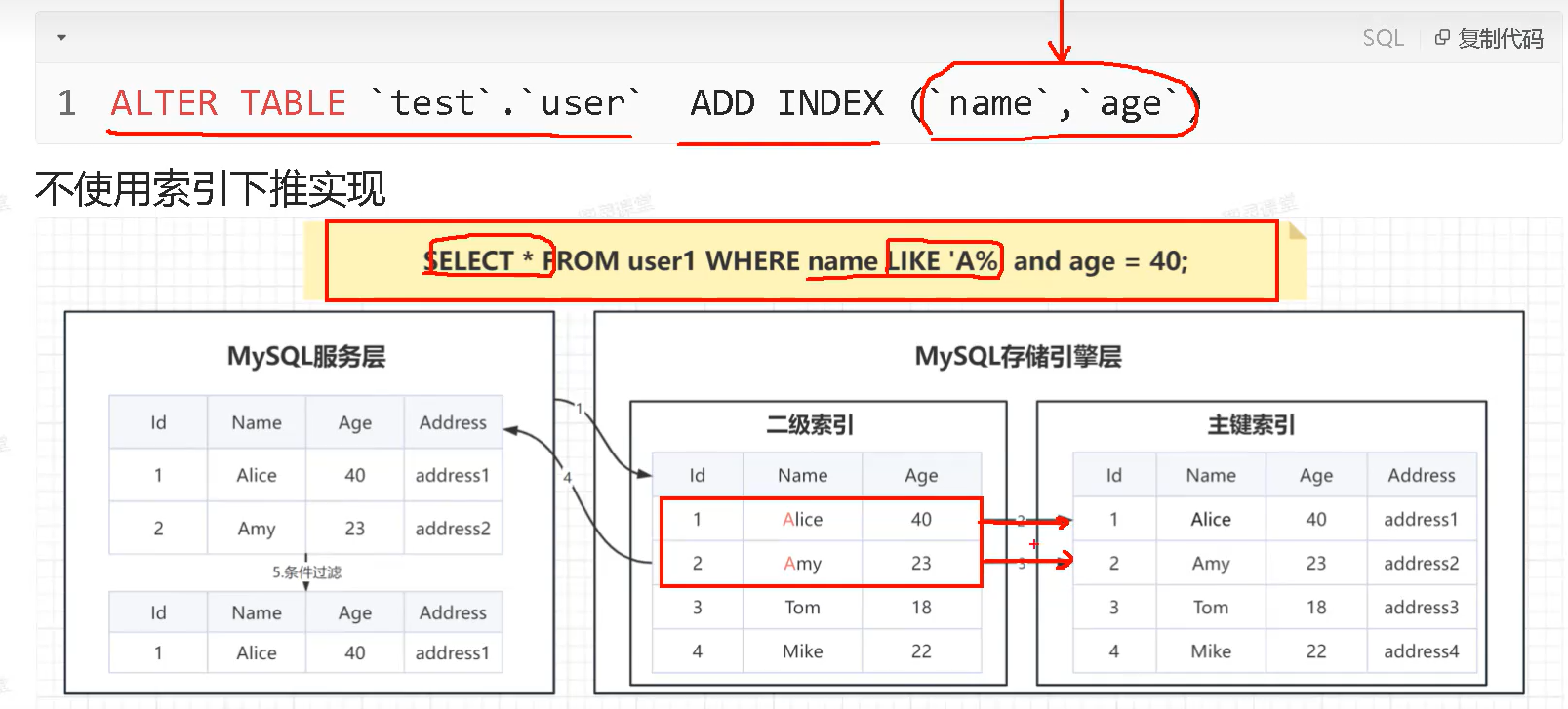
这里select * 查询了所有 然后又A后模糊查到了Alice 和Amy两条数据。因为二级索引没有报表user1所有的数据,所以要回表,有几条数据就要回几次表,特别慢哈~
所以在mysql5.6后更新了索引下推。就是在二级索引查询到Alice 和Amy两条数据后一次性回表。