作业①
- 要求:指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。 - 输出信息
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。 - Gitee 文件夹链接为:https://gitee.com/zjy-w/crawl_project/tree/master/作业3/1
(1)代码
ImageSpider.py
import uuid
from bs4 import BeautifulSoup
from scrapy import Spider, Request
class ImageSpider(Spider):
name = 'image_spider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn']
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.2 Safari/605.1.15"
}
count = 0
urls = []
def parse(self, response):
soup = BeautifulSoup(response.text, features='html.parser')
images = soup.select('img')
for image in images:
src = image['src']
url = response.urljoin(src)
if url not in self.urls:
self.count += 1
self.urls.append(url)
yield Request(url, callback=self.download)
def download(self, response):
url = response.url
if url[-4] == '.':
ext = url[-4:]
elif url[-5] == '.':
ext = url[-5:]
else:
ext = ''
name = str(uuid.uuid1())
fobj = open(f"C:/Users/jinyao/PycharmProjects/杂七杂八/数据采集/数据采集实践3/images/{name}{ext}", 'wb')
fobj.write(response.body)
fobj.close()
print(f'downloaded image {name}{ext}')
if __name__ == '__main__':
spider = ImageSpider()
spider.parse(start_urls[0])
items.py
import scrapy
class ImageItem(scrapy.Item):
image_urls = scrapy.Field()
images = scrapy.Field()
pipelines.py
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy.http import Request
class ImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield Request(image_url)
def item_completed(self, results, item, info):
image_path = [x['path'] for ok, x in results if ok]
if not image_path:
raise DropItem('Item contains no images')
item['image_paths'] = image_path
return item
settings.py
BOT_NAME = "image"
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
#增加访问header,加个降低被拒绝的保险
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1
}
IMAGES_STORE = 'C:/Users/jinyao/PycharmProjects/杂七杂八/数据采集/数据采集实践3/images'
SPIDER_MODULES = ["image.spiders"]
NEWSPIDER_MODULE = "image.spiders"
ROBOTSTXT_OBEY = True
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl image_spider -s LOG_ENABLED=False".split())
多线程只要将setting中CONCURRENT_REQUESTS值改为32即可
运行结果
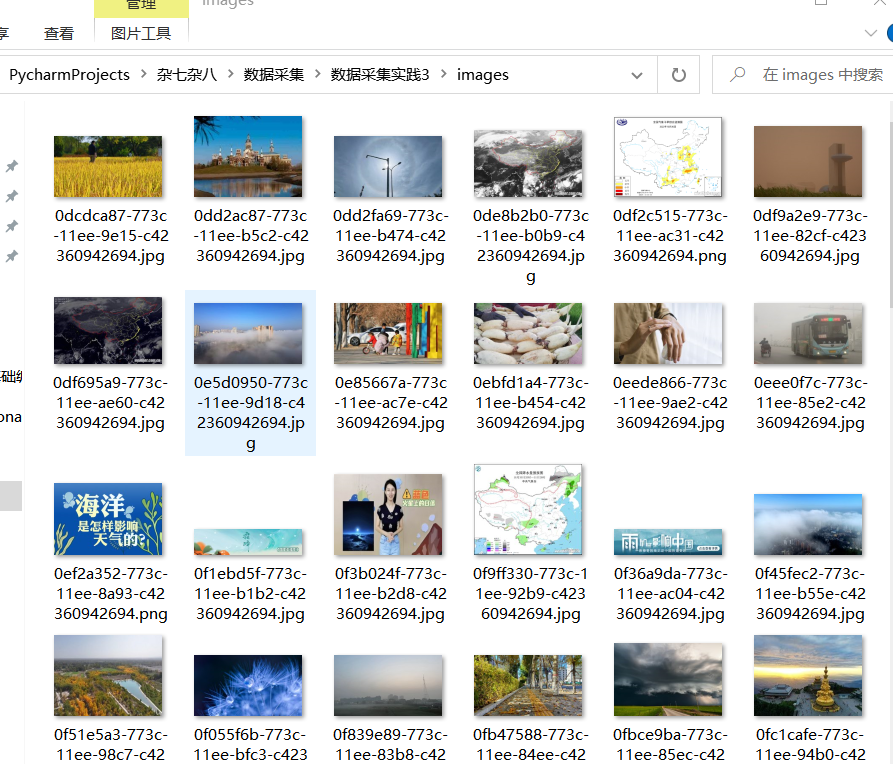
因为气象网没有翻页,且首页图片量难以达到题目所需要求,故增加爬取当当网,给出主要代码
DangdangSpider.py
from scrapy.spiders import Spider
from scrapy.http import Request
import re
from 数据采集.dangdang.dangdang.items import DangdangItem
class DangdangSpider(Spider):
name = 'dangdang'
allowed_domains = ['dangdang.com']
start_urls = ['http://search.dangdang.com/']
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"
}
def start_requests(self):
keyword = '书包'
start_page = 7
total_images = 107
params = {
'key': keyword,
'page_index': start_page
}
url = self.start_urls[0]
yield Request(url, headers=self.headers, params=params, meta={'start_page': start_page, 'total_images': total_images})
def parse(self, response):
start_page = response.meta['start_page']
total_images = response.meta['total_images']
text = response.text
urls = re.findall("<img src='(.*?)' alt", text)
url2 = re.findall("<img data-original='(.*?)' src", text)
urls.extend(url2)
print(f"正在爬取第{start_page}页")
count = 0
item = DangdangItem()
item['image_urls'] = []
for index, url in enumerate(urls, start=1):
if not url.startswith(('http://', 'https://')):
url = 'https:' + url
item['image_urls'].append(url)
count += 1
if count >= total_images:
break
item['image_paths'] = [f"第{start_page}页-第{index}张.jpg" for index in range(1, count+1)]
yield item
if count < total_images and start_page < 100:
params = {
'key': '书包',
'page_index': start_page + 1
}
yield Request(self.start_urls[0], headers=self.headers, params=params, meta={'start_page': start_page + 1, 'total_images': total_images - count})
运行结果


(2)心得体会
从单线程和多线程对比来说,很明显多线程远快于单线程。也对scrapy框架有了一个更深的了解和实操,scrapy可以自动调节机制自动调整爬取速度,是一个很有用强大的框架。
作业②
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
-
候选网站:东方财富网:https://www.eastmoney.com/
-
输出信息:MySQL数据库存储和输出格式如下:表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
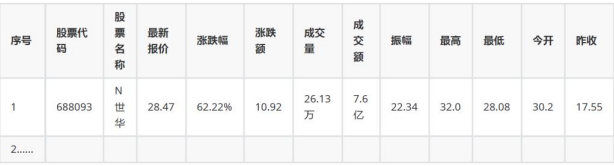
-
Gitee 文件夹链接为:https://gitee.com/zjy-w/crawl_project/tree/master/作业3/2
(1)代码
stock_spider.py
import scrapy
import json
from 数据采集.数据采集实践3.stocks.stocks.items import StocksItem
class StocksSpider(scrapy.Spider):
name = "stock_spider"
start_urls = [
"http://65.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124008516432775777205_1697696898159&pn=1&pz=100&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1697696898163"
]
def parse(self, response):
data = self.parse_json(response.text)
data_values = data['data']['diff']
items = self.parse_data_values(data_values)
yield from items
def parse_json(self, jsonp_response):
json_str = jsonp_response[len("jQuery1124008516432775777205_1697696898159("):len(jsonp_response) - 2]
return json.loads(json_str)
def parse_data_values(self, data_values):
return [StocksItem(
code=data_value['f12'],
name=data_value['f14'],
latestprice=data_value['f2'],
change_amount=data_value['f4'],
Rise_and_fall=data_value['f3'],
trading_volume=data_value['f5'],
turnover_value=data_value['f5'],
amplitude=data_value['f7'],
max=data_value['f15'],
min=data_value['f16'],
open_today=data_value['f17'],
received_yesterday=data_value['f18']
) for data_value in data_values]
items.py
import scrapy
class StocksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
latestprice = scrapy.Field()
change_amount = scrapy.Field()
Rise_and_fall = scrapy.Field()
trading_volume = scrapy.Field()
turnover_value = scrapy.Field()
amplitude = scrapy.Field() # 振幅
max = scrapy.Field()
min = scrapy.Field()
open_today = scrapy.Field()
received_yesterday = scrapy.Field()
pass
pipelines.py
from itemadapter import ItemAdapter
import pymysql
class StocksPipeline:
def open_spider(self, spider):
self.conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='123456', charset='utf8')
self.conn.autocommit(True)
with self.conn.cursor() as cursor:
cursor.execute('CREATE DATABASE IF NOT EXISTS stocks')
cursor.execute('USE stocks')
cursor.execute("""
CREATE TABLE IF NOT EXISTS stocks (
股票代码 VARCHAR(255),
股票名称 VARCHAR(255),
最新报价 VARCHAR(255),
涨跌幅 VARCHAR(255),
涨跌额 VARCHAR(255),
成交量 VARCHAR(255),
成交额 VARCHAR(255),
振幅 VARCHAR(255),
最高 VARCHAR(255),
最低 VARCHAR(255),
今开 VARCHAR(255),
昨收 VARCHAR(255)
)
""")
def process_item(self, item, spider):
sql = """
INSERT INTO stocks (股票代码, 股票名称, 最新报价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 最高, 最低, 今开, 昨收)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
data = (
item["code"], item["name"], item["latestprice"], item["change_amount"], item["Rise_and_fall"],
item["trading_volume"], item["turnover_value"], item["amplitude"], item["max"], item["min"],
item["open_today"], item["received_yesterday"]
)
with self.conn.cursor() as cursor:
try:
cursor.execute(sql, data)
except Exception as e:
print(e)
return item
def close_spider(self, spider):
self.conn.close()
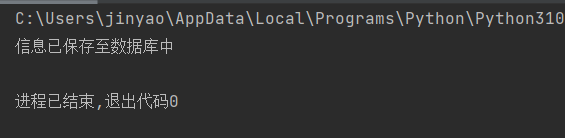
print("信息已保存至数据库中")
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl stock_spider -s LOG_ENABLED=False".split())
运行结果
数据库可视化
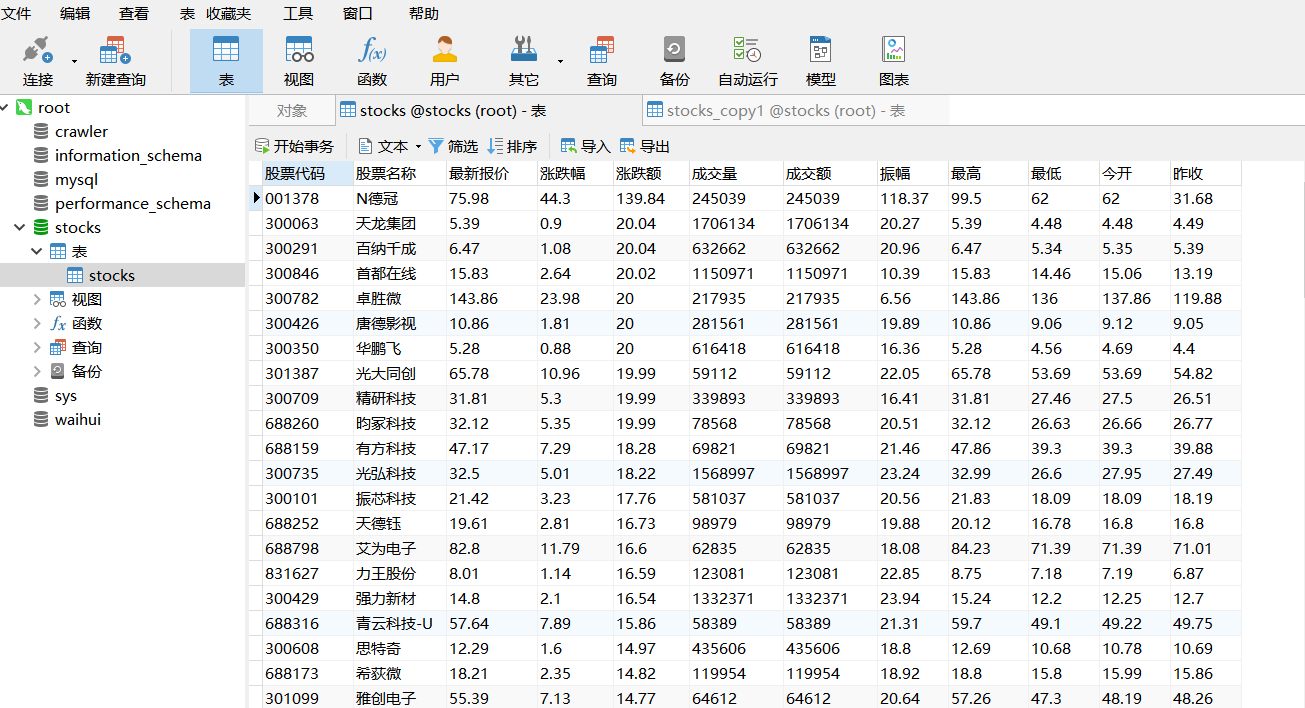
(2)心得体会
该代码主要为上一次作业的延申版本,即是使用scrapy进行。因为该页面的url没有改变,所以选择使用json进行抓包。该实验还学习了对mysql的使用与在代码中创建保存的方式,最后使用Navicat Premium进行数据库连接与可视化,更加简便。
作业③
-
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
-
输出信息

-
Gitee 文件夹链接为:https://gitee.com/zjy-w/crawl_project/tree/master/作业3/3
(1)代码
WaihuiSpider.py
import scrapy
from 数据采集.数据采集实践3.waihui.waihui.items import WaihuiItem
class WaihuiSpider(scrapy.Spider):
name = "waihui"
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
for tr in response.xpath("//div[@class='publish']/div[2]/table//tr")[2:]:
item = WaihuiItem(
Currency=tr.xpath('./td[1]/text()').extract_first(),
TBP=tr.xpath('./td[2]/text()').extract_first(),
CBP=tr.xpath('./td[3]/text()').extract_first(),
TSP=tr.xpath('./td[4]/text()').extract_first(),
CSP=tr.xpath('./td[5]/text()').extract_first(),
Time=tr.xpath('./td[7]/text()').extract_first()
)
yield item
items.py
import scrapy
class WaihuiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Currency=scrapy.Field()
TBP=scrapy.Field()
CBP=scrapy.Field()
TSP=scrapy.Field()
CSP=scrapy.Field()
Time=scrapy.Field()
pipelins.py
import pymysql
class WaihuiPipeline:
def __init__(self):
self.conn = None
self.cursor = None
def open_spider(self, spider):
self.conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123456',
charset='utf8'
)
self.cursor = self.conn.cursor()
self.create_database()
self.select_database()
self.create_table()
def process_item(self, item, spider):
try:
self.cursor.execute(
'INSERT INTO waihui VALUES(%s, %s, %s, %s, %s, %s)',
(item["Currency"], item["TBP"], item["CBP"], item["TSP"], item["CSP"], item["Time"])
)
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
def create_database(self):
self.cursor.execute('CREATE DATABASE IF NOT EXISTS waihui')
self.conn.commit()
def select_database(self):
self.conn.select_db('waihui')
def create_table(self):
create_table_sql = """
CREATE TABLE IF NOT EXISTS waihui (
Currency VARCHAR(255),
TBP VARCHAR(255),
CBP VARCHAR(255),
TSP VARCHAR(255),
CSP VARCHAR(255),
Time VARCHAR(255)
)
"""
self.cursor.execute(create_table_sql)
self.conn.commit()
def close_spider(self, spider):
self.conn.close()
print("信息已保存至数据库中")
run.py
from scrapy import cmdline
cmdline.execute("scrapy crawl waihui -s LOG_ENABLED=False".split())
运行结果

数据库可视化
(2)心得体会
在 Scrapy 中,可以使用 XPath 或 CSS Selector 来提取页面中的数据,就可以避免了手动解析 HTML的繁琐。同时该实验和第二个会较为相似,会更加顺手一些。同时还是加强了对数据库的了解与操作,从而更好保存所需数据。