YOLOV5.5-P5(640)部署到OpenVINO<一、环境安装与性能验证>
YOLOV5.5-P6(1280)部署到OpenVINO<二、环境安装与性能验证>
步骤和上一节差不多。
1、在yolov5.5 export.py中将yolov5s6.pt转为onnx
--weights yolov5s6.pt --img 1280 --batch 1
2、在网页版netron查看四个输出层,搜索Transpose就能看到
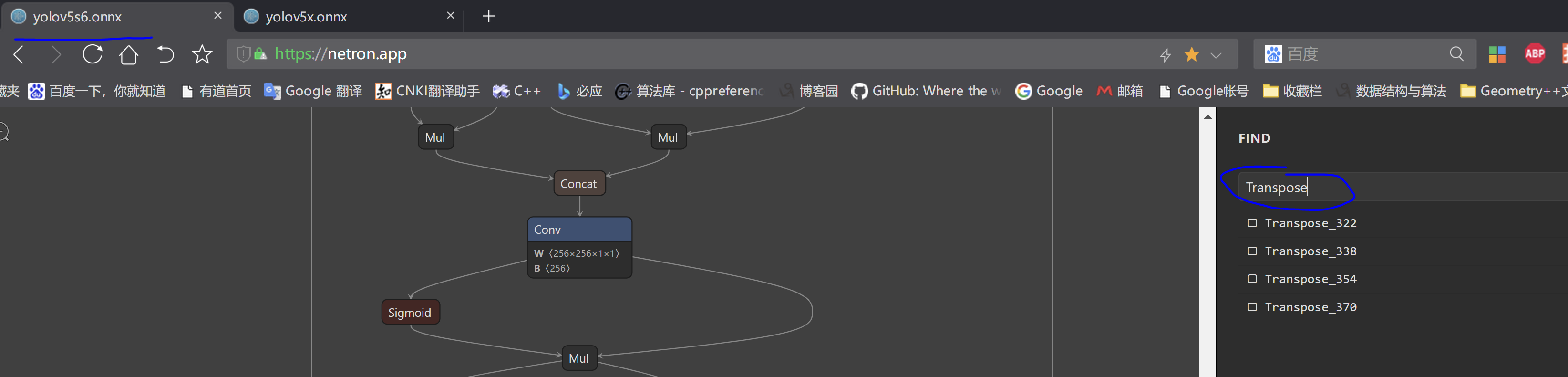
3、在openvino安装目录下执行mo.py
python mo.py --input_model yolov5s6.onnx --model_name yolov5s6 -s 255 --reverse_input_channels --output Conv_307,Conv_323,Conv_339,Conv_355
python mo.py --input_model yolov5m6.onnx --model_name yolov5m6 -s 255 --reverse_input_channels --output Conv_405,Conv_421,Conv_437,Conv_453
4、这里由于图像输入分辨率是1280*1280,并且输出四组特征图,所以和之前640分辨率的模型还是不一样,首先,先普及一个概念(以coco数据集为例子):
yolov5-p5(640)
对于5s、5m、5l、5x模型,有九个anchors:
# anchors anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32
而模型输出三组特征图:1*255*80*80、1*255*40*40、1*255*20*20,分别记为:P80、P40、P20,例如:P80中,本身包含3个候选框,和先验anchors的对应关系为:
- P80 的三个候选框 -> [10,13, 16,30, 33,23] # P3/8
- P40 的三个候选框 -> [30,61, 62,45, 59,119] # P4/16
- P20 的三个候选框 -> [116,90, 156,198, 373,326] # P5/32
yolov5-p6(1280)
同理,如果知道p6(1280)模型的anchors:
(P6的配置文件“yolov5s6.yaml”在:源码hub目录下)
# anchors anchors: - [ 19,27, 44,40, 38,94 ] # P3/8 - [ 96,68, 86,152, 180,137 ] # P4/16 - [ 140,301, 303,264, 238,542 ] # P5/32 - [ 436,615, 739,380, 925,792 ] # P6/64
就可以知道,p6模型输出的四个特征图和先验anchors的对应关系:
- P160 的三个候选框 -> [ 19,27, 44,40, 38,94 ] # P3/8
- P80 的三个候选框 -> [ 96,68, 86,152, 180,137 ] # P4/16
- P40 的三个候选框 -> [ 140,301, 303,264, 238,542 ] # P5/32
- P20 的三个候选框 -> [ 436,615, 739,380, 925,792 ] # P6/64
以下是代码:


1 # 命令行参数:-m data/yolov5m.xml -i D:/Data/dog.jpg -at yolov5 --labels data/coco.names -d CPU 2 from __future__ import print_function, division 3 import sys 4 from time import time 5 import numpy as np 6 7 import ngraph 8 import cv2 9 from openvino.inference_engine import IENetwork, IECore 10 11 labels = "data/coco.names" 12 device = "CPU" 13 img_file = "d:/Data/dog.jpg" 14 model_xml = "data/yolov5s6.xml" 15 prob_threshold = 0.25 16 iou_threshold = 0.45 17 in_res640 = 640 18 in_res1280 = 1280 # 640 for 5s 5m 5l 5x 19 20 class YoloParams: 21 # ------------------------------------------- Extracting layer parameters ------------------------------------------ 22 # Magic numbers are copied from yolo samples 23 def __init__(self, param, side): 24 self.coords = 4 if 'coords' not in param else int(param['coords']) 25 self.classes = 80 if 'classes' not in param else int(param['classes']) 26 self.side = side 27 self.num = 3 28 # self.anchors = [10.0, 13.0, 16.0, 30.0, 33.0, 23.0, 30.0, 61.0, 62.0, 45.0, 59.0, 119.0, 116.0, 90.0, 156.0, 198.0, 373.0, 326.0] 29 self.anchors = [ 19, 27, 44, 40, 38, 94, # P3/8 30 96, 68, 86, 152, 180, 137, # P4/16 31 140, 301, 303, 264, 238, 542, # P5/32 32 436, 615, 739, 380, 925, 792 ] # P6/64 33 34 def letterbox(img, size=(in_res1280, in_res1280), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True): 35 # Resize image to a 32-pixel-multiple rectangle(矩形推理) https://github.com/ultralytics/yolov3/issues/232 36 shape = img.shape[:2] # current shape [height, width] 37 w, h = size 38 39 # Scale ratio (new / old) 40 r = min(h / shape[0], w / shape[1]) 41 if not scaleup: # only scale down, do not scale up (for better test mAP) 42 r = min(r, 1.0) 43 44 # Compute padding 45 ratio = r, r # width, height ratios 46 new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) 47 dw, dh = w - new_unpad[0], h - new_unpad[1] # wh padding 48 if auto: # minimum rectangle 49 dw, dh = np.mod(dw, 64), np.mod(dh, 64) # wh padding 50 elif scaleFill: # stretch 51 dw, dh = 0.0, 0.0 52 new_unpad = (w, h) 53 ratio = w / shape[1], h / shape[0] # width, height ratios 54 55 dw /= 2 # divide padding into 2 sides 56 dh /= 2 57 58 if shape[::-1] != new_unpad: # resize 59 img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR) 60 top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1)) 61 left, right = int(round(dw - 0.1)), int(round(dw + 0.1)) 62 img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border 63 64 top2, bottom2, left2, right2 = 0, 0, 0, 0 65 if img.shape[0] != h: 66 top2 = (h - img.shape[0]) // 2 67 bottom2 = top2 68 img = cv2.copyMakeBorder(img, top2, bottom2, left2, right2, cv2.BORDER_CONSTANT, value=color) # add border 69 elif img.shape[1] != w: 70 left2 = (w - img.shape[1]) // 2 71 right2 = left2 72 img = cv2.copyMakeBorder(img, top2, bottom2, left2, right2, cv2.BORDER_CONSTANT, value=color) # add border 73 return img 74 75 """ 76 @brief: 77 x、y、height、width:网络最后三个尺度特征图对应在640*640 or 1280*1280图像上的先验眶 78 class_id: 0-80 79 confidence: Pr(object)*Pr(Classi|Object) 80 im_h: 原始图高度 81 im_w: 原始图宽度 82 """ 83 def scale_bbox(x, y, height, width, class_id, confidence, im_h, im_w, resized_im_h=in_res1280, resized_im_w=in_res1280): 84 gain = min(resized_im_w / im_w, resized_im_h / im_h) # gain = old / new 85 pad = (resized_im_w - im_w * gain) / 2, (resized_im_h - im_h * gain) / 2 # wh padding 86 x = int((x - pad[0]) / gain) 87 y = int((y - pad[1]) / gain) 88 89 w = int(width / gain) 90 h = int(height / gain) 91 92 xmin = max(0, int(x - w / 2)) 93 ymin = max(0, int(y - h / 2)) 94 xmax = min(im_w, int(xmin + w)) 95 ymax = min(im_h, int(ymin + h)) 96 # Method item() used here to convert NumPy types to native types for compatibility with functions, which don't 97 # support Numpy types (e.g., cv2.rectangle doesn't support int64 in color parameter) 98 return dict(xmin=xmin, xmax=xmax, ymin=ymin, ymax=ymax, class_id=class_id.item(), confidence=confidence.item()) 99 100 101 def entry_index(side, coord, classes, location, entry): 102 side_power_2 = side ** 2 103 n = location // side_power_2 104 loc = location % side_power_2 105 return int(side_power_2 * (n * (coord + classes + 1) + entry) + loc) 106 107 108 # 解析特征图,x y w h 坐标复原,类别置信度计算 109 def parse_yolo_region(blob, resized_image_shape, original_im_shape, params, threshold): 110 # ------------------------------------------ Validating output parameters ------------------------------------------ 111 out_blob_n, out_blob_c, out_blob_h, out_blob_w = blob.shape 112 predictions = 1.0 / (1.0 + np.exp(-blob)) # sigmoid,是所有的值都要sigmoid 113 114 assert out_blob_w == out_blob_h, "Invalid size of output blob. It sould be in NCHW layout and height should " \ 115 "be equal to width. Current height = {}, current width = {}" \ 116 "".format(out_blob_h, out_blob_w) 117 118 # ------------------------------------------ Extracting layer parameters ------------------------------------------- 119 orig_im_h, orig_im_w = original_im_shape 120 resized_image_h, resized_image_w = resized_image_shape # 640 640 or 1280 1280 121 objects = list() 122 123 side_square = params.side[1] * params.side[0] # 80*80 124 125 # ------------------------------------------- Parsing YOLO Region output ------------------------------------------- 126 bbox_size = int(out_blob_c / params.num) # 4+1+num_classes 255 / 3 = 85 127 # print('bbox_size = ' + str(bbox_size)) 128 # print('bbox_size = ' + str(bbox_size)) 129 for row, col, n in np.ndindex(params.side[0], params.side[1], params.num): # 160, 160, 3 or 80, 80, 3; 40, 40, 3; 20, 20, 3 130 # 取出1*255*80*80 中的一个元素,大小为 85 131 bbox = predictions[0, n * bbox_size:(n + 1) * bbox_size, row, col] 132 # print("n * bbox_size = ", n * bbox_size) 133 # print("bbox_size = ", (n + 1) * bbox_size) 134 135 x, y, width, height, object_probability = bbox[:5] 136 137 if object_probability < threshold: 138 continue 139 class_probabilities = bbox[5:] 140 # print('resized_image_w = ' + str(resized_image_w)) 141 # print('out_blob_w = ' + str(out_blob_w)) 142 143 x = (2 * x - 0.5 + col) * (resized_image_w / out_blob_w) 144 y = (2 * y - 0.5 + row) * (resized_image_h / out_blob_h) 145 # 下面的if elif判断语句(用于计算idx)可以拿到for循环外边!!! 146 if int(resized_image_w / out_blob_w) == 8 & int(resized_image_h / out_blob_h) == 8: # 80x80, 147 idx = 0 148 elif int(resized_image_w / out_blob_w) == 16 & int(resized_image_h / out_blob_h) == 16: # 40x40 149 idx = 1 150 elif int(resized_image_w / out_blob_w) == 32 & int(resized_image_h / out_blob_h) == 32: # 20x20 151 idx = 2 152 elif int(resized_image_w / out_blob_w) == 64 & int(resized_image_h / out_blob_h) == 64: # 20x20 153 idx = 3 154 elif int(resized_image_w / out_blob_w) == 128 & int(resized_image_h / out_blob_h) == 128: # 20x20 155 idx = 4 156 # idx表示步距;n表示通道 157 # idx = 0, n = 0 1 2 -> 0 1, 2 3, 3 4;第一行anchors 158 # idx = 1, n = 0 1 2 -> 第二行anchors 159 # idx = 2, n = 0 1 2 -> 第三行anchors 160 # idx = 3, n = 0 1 2 -> 第四行anchors 161 # 结论: 162 # 对于1*160*160*255的特征图,每3个点(即:1*1*1*255)对应3个anchors,即:第一行anchors 163 # 对于1*80*80*255的特征图, 每3个点(即:1*1*1*255)对应3个anchors,即:第二行anchors 164 # 对于1*40*40*255的特征图, 每3个点(即:1*1*1*255)对应3个anchors,即:第三行anchors 165 # 对于1*20*20*255的特征图, 每3个点(即:1*1*1*255)对应3个anchors,即:第四行anchors 166 width = (2 * width) ** 2 * params.anchors[idx * 6 + 2 * n] 167 height = (2 * height) ** 2 * params.anchors[idx * 6 + 2 * n + 1] 168 169 class_id = np.argmax(class_probabilities) # max(Pr(classi|Object)) 170 # confidence = class_probabilities[class_id] 171 confidence = class_probabilities[class_id] * bbox[4] # sry 这里改成这个才对???????????????? 172 objects.append(scale_bbox(x=x, y=y, height=height, width=width, class_id=class_id, confidence=confidence, 173 im_h=orig_im_h, im_w=orig_im_w, resized_im_h=resized_image_h,resized_im_w=resized_image_w)) 174 return objects 175 176 177 # 计算IOU 178 def intersection_over_union(box_1, box_2): 179 # 计算交集 180 width_of_overlap_area = min(box_1['xmax'], box_2['xmax']) - max(box_1['xmin'], box_2['xmin']) 181 height_of_overlap_area = min(box_1['ymax'], box_2['ymax']) - max(box_1['ymin'], box_2['ymin']) 182 if width_of_overlap_area < 0 or height_of_overlap_area < 0: 183 area_of_overlap = 0 184 else: 185 area_of_overlap = width_of_overlap_area * height_of_overlap_area 186 # 计算并集 187 box_1_area = (box_1['ymax'] - box_1['ymin']) * (box_1['xmax'] - box_1['xmin']) 188 box_2_area = (box_2['ymax'] - box_2['ymin']) * (box_2['xmax'] - box_2['xmin']) 189 area_of_union = box_1_area + box_2_area - area_of_overlap 190 if area_of_union == 0: 191 return 0 192 return area_of_overlap / area_of_union 193 194 195 def main(): 196 # ------------- 1. Plugin initialization for specified device and load extensions library if specified ------------- 197 ie = IECore() 198 # -------------------- 2. Reading the IR generated by the Model Optimizer (.xml and .bin files) -------------------- 199 net = ie.read_network(model=model_xml) 200 # ---------------------------------- 3. Load CPU extension for support specific layer ------------------------------ 201 # ... 202 # ---------------------------------------------- 4. Preparing inputs ----------------------------------------------- 203 input_blob = next(iter(net.input_info)) 204 # sry 205 output_blob = list() 206 for output in iter(net.outputs): 207 output_blob.append(output) 208 # Defaulf batch_size is 1 209 net.batch_size = 1 210 # Read and pre-process input images 211 n, c, h, w = net.inputs[input_blob].shape 212 213 # api:https://docs.openvino.ai/latest/api/ngraph_python_api/_autosummary/ngraph.html#module-ngraph 214 ng_func = ngraph.function_from_cnn(net) # 这里的计算图是转IR格式以后(优化以后),得到的新的优化版网络架构 215 yolo_layer_params = {} 216 for node in ng_func.get_ordered_ops(): 217 layer_name = node.get_friendly_name() 218 # print(node, "||||||", layer_name) 219 if layer_name not in net.outputs: # 拿到最后三个输出层 220 continue 221 222 shape = list(node.inputs()[0].get_source_output().get_node().shape) 223 # yolo中的一些参数:先验框宽高、数量、类别数等 224 yolo_params = YoloParams(node._get_attributes(), shape[2:4]) 225 yolo_layer_params[layer_name] = (shape, yolo_params) 226 # 读labels文件 227 with open(labels, 'r') as f: 228 labels_map = [x.strip() for x in f] 229 wait_key_code = 0 230 # ----------------------------------------- 5. Loading model to the plugin ----------------------------------------- 231 exec_net = ie.load_network(network=net, device_name=device) 232 cost_time = 0 233 # ----------------------------------------------- 6. Doing inference ----------------------------------------------- 234 frame = cv2.imread(img_file) 235 in_frame = letterbox(frame, (w, h)) # 这里没有用到矩形推理 236 # resize input_frame to network size 237 in_frame = in_frame.transpose((2, 0, 1)) # Change data layout from HWC to CHW 238 in_frame = in_frame.reshape((n, c, h, w)) 239 240 # 推理&得到很多候选框 241 objects = list() 242 start_time = time() 243 # 1*80*80*255 1*40*40*255 1*20*20*255 (1*160*160*255) 244 output = exec_net.infer(inputs={input_blob: in_frame}) 245 cost_time = time() - start_time 246 for layer_name, out_blob in output.items(): 247 """ 248 可以看到,目前就是anchors取值不对,因为有四个尺度的特征图,去看看yolo5.5的源码 249 另外注意,大图有关预测框的缩放也要注意!大不了拷贝过来啊! 250 """ 251 # if out_blob.shape[2] == 20: 252 # continue 253 layer_params = yolo_layer_params[layer_name] 254 out_blob.shape = layer_params[0] 255 objects += parse_yolo_region(out_blob, in_frame.shape[2:], frame.shape[:-1], layer_params[1], prob_threshold) 256 257 # 从三个尺度的featureMap得到一堆候选框,对候选框进行NMS(这里的NSM比较简答粗暴,不仅慢,而且会导致漏检?) 258 objects = sorted(objects, key=lambda obj: obj['confidence'], reverse=True) # 依据置信度,按从大到小进行排序 259 for i in range(len(objects)): 260 if objects[i]['confidence'] == 0: # 这句有点扯,这里是浮点数 261 continue 262 for j in range(i + 1, len(objects)): 263 # 不分类别,仅按照IOU进行排序,凡是后续框和当前框(最大置信度)的IOU太大的,都删除 264 if intersection_over_union(objects[i], objects[j]) > iou_threshold: 265 objects[j]['confidence'] = 0 266 267 # 如果Pr(classi|Object) > threshold,则保留 268 objects = [obj for obj in objects if obj['confidence'] >= prob_threshold] 269 origin_im_size = frame.shape[:-1] 270 for obj in objects: 271 # Validation bbox of detected object 272 if obj['xmax'] > origin_im_size[1] or obj['ymax'] > origin_im_size[0] or obj['xmin'] < 0 or obj['ymin'] < 0: 273 continue 274 color = (int(max(255 - obj['class_id'] * 7.5, 0)), max(255 - obj['class_id'] * 10, 0), max(255 - obj['class_id'] * 12.5, 0)) 275 det_label = labels_map[obj['class_id']] if labels_map and len(labels_map) >= obj['class_id'] else str(obj['class_id']) 276 cv2.rectangle(frame, (obj['xmin'], obj['ymin']), (obj['xmax'], obj['ymax']), color, 2) 277 cv2.putText(frame, "#" + det_label + ' ' + str(round(obj['confidence'] * 100, 1)) + ' %', (obj['xmin'], obj['ymin'] - 7), cv2.FONT_HERSHEY_COMPLEX, 0.6, color, 1) 278 # Draw performance stats over frame 279 cost_time_message = "inference time: {:.3f} ms".format(cost_time * 1e3) 280 cv2.putText(frame, cost_time_message, (15, 45), cv2.FONT_HERSHEY_COMPLEX, 0.5, (10, 10, 200), 1) 281 cv2.imshow("DetectionResults", frame) 282 cv2.waitKey(0) 283 cv2.destroyAllWindows() 284 285 if __name__ == '__main__': 286 sys.exit(main() or 0)

P6比P5慢,但是对于同一个目标置信度更高,recall也更高。