本人的学习环境:
操作系统:win10
java版本:jdk11
(仅作为环境介绍,不一致也无妨)
步骤一:
安装Tesseract环境
可去官网查看各个环境的安装教程,本次是使用的windows版本,windows安装地址
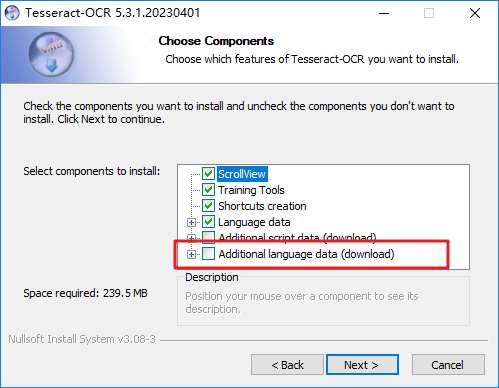
如需要使用简体中文,需要在安装过程中指定其他语言数据下载,如下图所示:
步骤二:
添加相关Maven依赖
<dependency> <groupId>org.bytedeco.javacpp-presets</groupId> <artifactId>tesseract-platform</artifactId> <version>4.0.0-1.4.4</version> </dependency>
步骤三:
java测试类代码
package wcontour.ocr; import org.bytedeco.javacpp.BytePointer; import org.bytedeco.javacpp.lept; import org.bytedeco.javacpp.tesseract; import static org.bytedeco.javacpp.lept.pixDestroy; import static org.bytedeco.javacpp.lept.pixRead; public class OCRTest { public static void main(String[] args) { //验证码路径 String filePath = "C:\\Pictures\\OCR\\yzm2.jpg"; //开始识别 ocrTest(filePath); } public static void ocrTest(String filePath) { BytePointer outText; tesseract.TessBaseAPI api = new tesseract.TessBaseAPI(); //s指定安装好的tessdata目录路径,s1指定语言 //chi_sim为简体中文(需要在安装tessdata过程中手动指定安装chi_sim语言),eng为英文(为默认安装语言) if (api.Init("E:\\ENV\\Tesseract-OCR\\tessdata", "chi_sim") != 0) { System.err.println("无法初始化tesseract"); return; } // 放入图片 lept.PIX image = pixRead(filePath); api.SetImage(image); // 获取OCR结果 outText = api.GetUTF8Text(); System.out.println("OCR output:\n" + outText.getString()); // 销毁使用过的对象并释放内存 api.End(); api.close(); outText.deallocate(); pixDestroy(image); } }
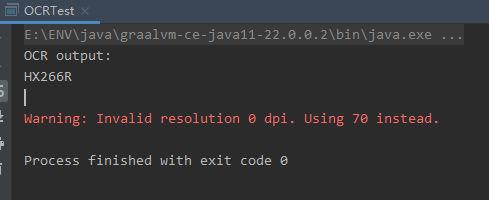
测试结果:
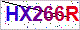
感谢观看!