Abstract
在实际的场景中,用户的行为数据往往是有噪声的,并且表现出偏态分布。所以需要利用自监督学习来改善用户表示。我们提出了一种新的自适应图对比学习(AdaGCL)框架,该框架使用两个自适应对比视图生成器来进行数据增强,以更好地增强CF范式。具体的说,我们使用了两个可训练的视图生成器,一个图形生成模型和一个图形去噪模型,来创建自适应的对比视图。通过两个自适应对比视图,AdaGCL在CF范式中引入了额外的高质量训练信号,帮助缓解了数据稀疏性和噪声问题
Introduction
考虑到现有解决方案的局限性和挑战,我们提出了一种新的自适应图对比学习框架,来提高推荐系统的鲁棒性和泛化性。目前的对比学习需要特定的方法来创建对比视图,这些方法的选择是繁重的,并且受限于预制视图池。为了解决这些问题,我们集成了图生成模型和图去噪模型来建立适应数据分布的视图,实现了图对比学习的自适应对比视图。通过提供两种不同的自适应视图,就可以提供额外的高质量的训练信号,可以增强图神经协同过滤范式。
本论文做出的贡献
- 提出了一种新的自监督模型,称为AdaGCL,它通过从自适应对比学习中提取额外的信号来增强图对比的鲁棒性
- AdaGCL使用了两个可训练的视图生成器,一个图生成器和一个图去噪模型来创建对比视图,这些视图解决了模型崩溃的问题,并且使自适应视图成为对比学习,最终提高了图神经网络协同过滤的范式
Methodology
AdaGCL的介绍由三部分组成
- 使用图形消息传递编码器来捕获用户和项目之间的本地协作关系
- 提出了一种新的自适应自监督学习框架,包括两个由变分图模型和去噪图模型组成的可训练视图生成器
- 介绍了模型优化的各个阶段
总体架构如图所示:
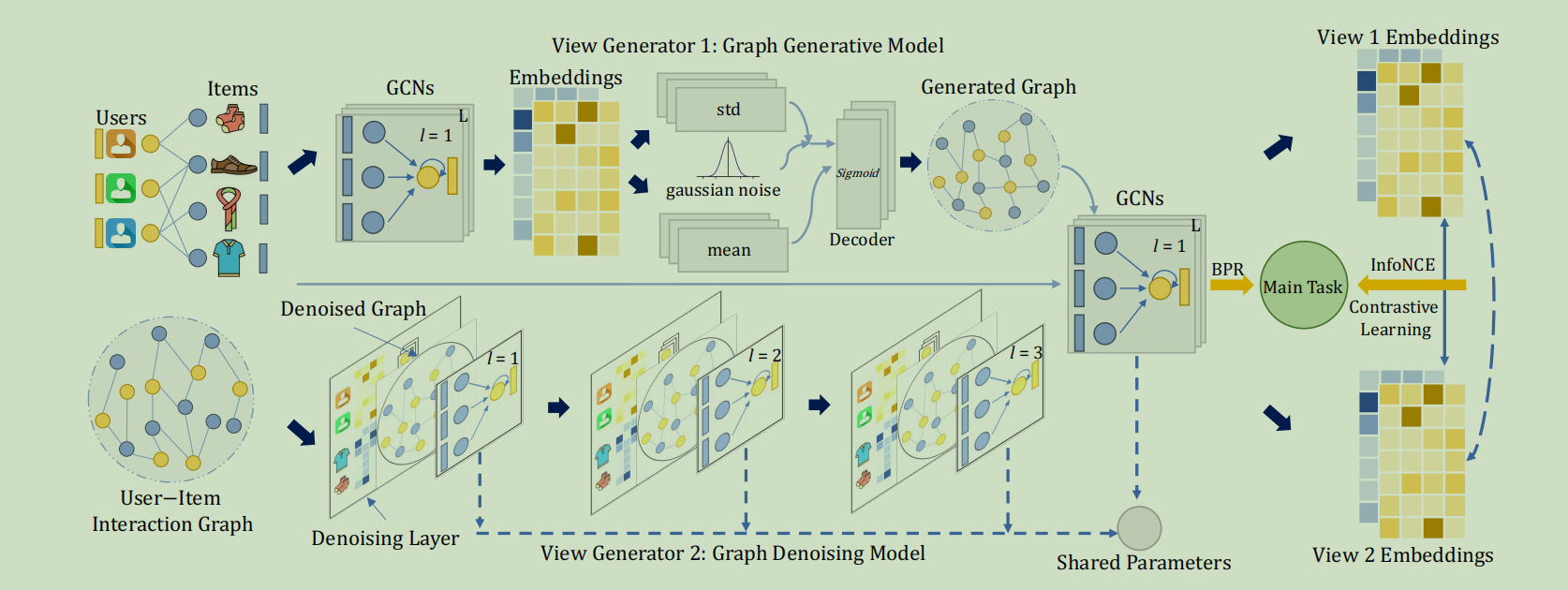
本地协作关系学习
为了编码用户和项目之间的交互模型,我们采用同样的协同过滤范式,将它们嵌入到一个d维的潜在空间中。嵌入传播层采用LightGCN使用的简化图卷积网络。
这个其实没啥新意,就是过了几层像LightGCN那样的GCN Layer,得到了输出的一个Embedding
图对比自适应视图生成器
双视图GCL范式
现有的图对比方式以特定的方式生成视图,选择合适的方式来生成视图可能是一项繁重的工作...总之就在说传统GCL生成对比模型的缺点。
目前模型存在崩溃的风险,即由同一生成器生成的两个视图共享相同的分布,可能会导致不准确的对比优化。所以为了解决这个,我们需要使用两个不同的视图生成器(这里有疑问,为什么原来用同一个,这里用不同的,用不同的会不会存在问题)从不同的角度增强用户-项目图。具体的说,使用一个图生成模型和一个图去噪模型作为我们的两个视图生成器。图生成模型负责基于图分布重建视图,而图去噪模型利用图的拓扑信息,并以更小的噪声生成新的视图
根据现有的自监督协同过滤范式,我们使用节点自识别来生成正对和负对。具体的来说,我们将同一个节点的视图视为正对,将任何两个不同节点的视图视为负对。在形式上,使正对的一致性最大,使负对的一致性最小的对比损失函数如下
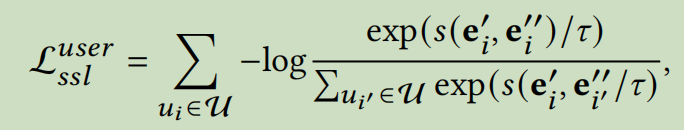
为了度量两个向量之间的相似性,我们使用余弦相似函数\(s(\cdot)\) 。然后用类似的方法计算项目的对比损失\(L_{ssl}^{item}\)。通过结合这两种损失,我们的得到了自监督任务的目标函数,\(L_{ssl}=L_{ssl}^{user}+L_{ssl}^{item}\)
图生成模型作为视图生成器
在本研究中,我们采用了广泛使用的变分图自编码器作为生成模型。与GAE相比,VGAE采用了KL散度,以减少过拟合的风险,允许通过增加不确定性来生成更多样化的图。并且VAE比其它目前流行的生成模型更容易训练而且速度更快。
我们在起始阶段,利用一个多层的GCN作为编码器来获得图的嵌入,使用两个MLP来分别推导出图嵌入的平均值和标准差,然后用另一个MLP作为解码器,对输入的均值和带有高斯噪声的标准差进行解码,生成一个新的图。VGAE的损失为:
\(L_{gen}=L_{kl}+L_{dis}\)
\(L_{kl}\)是节点嵌入分别和标准高斯分布之间的KL散度,\(L_{dis}\)是一种交叉熵损失,量化了生成的图和原始图之间的差异。
图去噪模型作为视图生成器
因为GNN使用消息传递机制来沿着输入图传播和聚合信息。所以输入图的之类会严重影响模型的性能。严重有噪声的边缘聚合的消息会降低节点嵌入的质量。所以在第二个视图生成器里,我们的目标是生成一个去噪视图,提高模型对有噪声数据的性能。
为了提高每一层GCN获得的节点嵌入的质量,我们用一个包含去噪层的图升神经网络来滤除输入图中的噪声边。
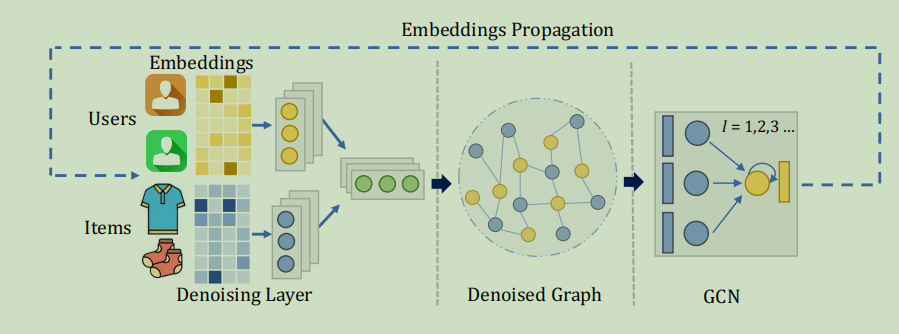
我们利用参数化网络来滤除输入图中的噪声边。对于第l个GCN层
,我们使用二进制矩阵\(M^l\in 0,1^{|V|\times|V|}\) ,\(m_{i,j}^l\)表示节点\(u_i\)和\(v_j\)之间的边是否存在,0表示有噪声的边.
得到的子图的邻接矩阵是\(A^l=A\odot M^l\),用对\(A_l\)进行最小的假设来减少噪声边的直接想法是惩罚不同层的\(M_l\)中的非0条目的数量
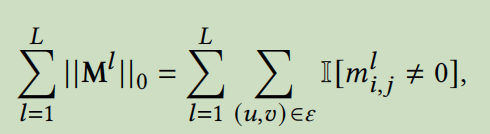
\(||\cdot||_0\)表示\(l_0\)范式,也就是向量中非0元素的个数,l代表层数。但是因为组合和不可微的性质,优化这个惩罚比较困难。想法就是每个\(m_{i,j}^l\)从一个伯努利分布\(\pi_{i,j}^l\)中提取。\(\pi_{i,j}^l\)代表了边(u,v)的质量。然后就是老生常谈的重参数技巧。将分布转化为由参数决定的确定性函数。分别为\(\alpha\)和\(\varepsilon\)
基于上述的操作,我们设计了一个去噪层来学习参数\(\alpha\),对于每层GNN,我们为用户节点和项目交互节点来计算\(\alpha\)
\(\alpha_{i,j}^l=f^l_{\theta^l}(e_i^l,e_j^l)\),f是由参数为\(\theta\)的MLP。为了得到\(m_{i,j}^l\),我们还在具体分布中使用了Sigmoid函数。所以对等式中\(M_l\)中非0条目的约束可以变为
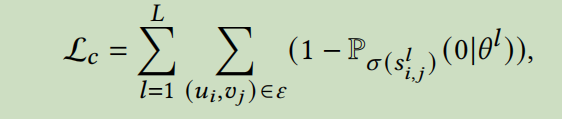
\(P\)是\(\sigma\)的CDF,\(\sigma\)是sigmoid函数,\(s_{i,j}^l\)是从由参数\(\alpha_{i,j}^l\)决定的二项离散分布中产生的
学习具有任务感知的视图生成器
虽然两个视图生成器可以学习从不同的方面生成更好的视图,但可能没有优化信号来将生成的视图调整为主CF任务,于是引入BPR Loss
为了训练图生产模型,我们使用由VGAE编码器编码的节点嵌入来计算BPR损失。于是损失函数为:
\(L_{gen}=L_{kl}+L_{dis}+L_{bpr}^{gen}+\lambda_2||\Theta||_F^2\)
为了训练图去噪模型,我们使用去噪神经网络的节点嵌入来计算BPR Loss,于是损失函数为:
\(L_{den}=L_c+L_{bpr}^{den}+\lambda_2||\Theta||_F^2\)
模型训练
上面的模型训练包括两部分,上层部分采用多任务训练策略来联合优化经典的推荐任务和自监督学习任务
\(L_{upper}=L_{bpr}+\lambda_1L_{ssl}+\lambda_2||\Theta||_F^2\)
训练的低层次部分包括优化生成式和去噪式视图生成器
\(L_{lower}=L_{gen}+L_{den}\)
Evaluation
AdaGCL有两个主要优势,首先是不依赖随机数据增强来生成对比视图,而是利用两个自适应视图生成器来创建保留有用信息的合理视图。生成视图捕获了原始数据的关键模式。而去噪发生器滤掉了可能干扰对比学习的噪声信号。其次就是使用两个不同的生成器从不同的方面创建对比视图来解决对比学习中的模型崩溃问题。
后面有点逆天,加了去噪的视图来跟没有任何去噪手段的方法比鲁棒性,不明白为啥要这样比。
Conclusion
在本篇论文中,我们提出了一种新的方法来改进对比推荐系统,通过使用自适应视图生成器。具体来说,我们引入了一个新的推荐框架,AdaGCL,它利用图形生成模型和图形去噪模型来创建对比视图,允许使用自增强的自监督信号来进行更有效的用户-项目交互建模。我们的框架证明了对噪声扰动的鲁棒性,从而提高了基于图的推荐系统的整体性能。
- Recommendation Contrastive Adaptive Learning 笔记recommendation contrastive adaptive learning lightgcl recommendation contrastive effective generative-contrastive recommendation contrastive representation recommendation degeneration contrastive recommendation contrastive effective lightgcl graph recommendation augmentations contrastive bayes-adaptive meta-learning adaptive learning contrastive embeddings learning sentence generalization contrastive proxy-based learning probabilistic contrastive adaptation learning