1)把PDF切分成小的文本片段,通过OpenAI的Ada模型创建Embedding放到本地或远程向量数据库。2)把用户的提问也创建成Embedding,用它和之前创建的PDF向量比对,通过语义相似性搜索(余弦算法),找到最相关的文本片段。比关键词搜索好的一点是不要求关键词包含,也能发现文本相关性,比如汽车和公路。3)把用户提问和相似文本片段发给OpenAI,写Prompt要求ChatGPT基于给定的内容生成回答,如果没有相似文本或关联度不高,回答不知道。为避免ChatGPT乱发挥,一般Temperture会设置的很低甚至为0 注意:这种方法实用性仍然比较有限,质量也不好,虽有一定调优空间(文本切片,问答对) 现在这么做也是不得已,因为ChatGPT的上下文记忆token有限(32k会好一些),不能直接丢超长文档让它分析。by@向阳乔木
原推:by@Sully
https://twitter.com/SullyOmarr/status/1655626066331938818
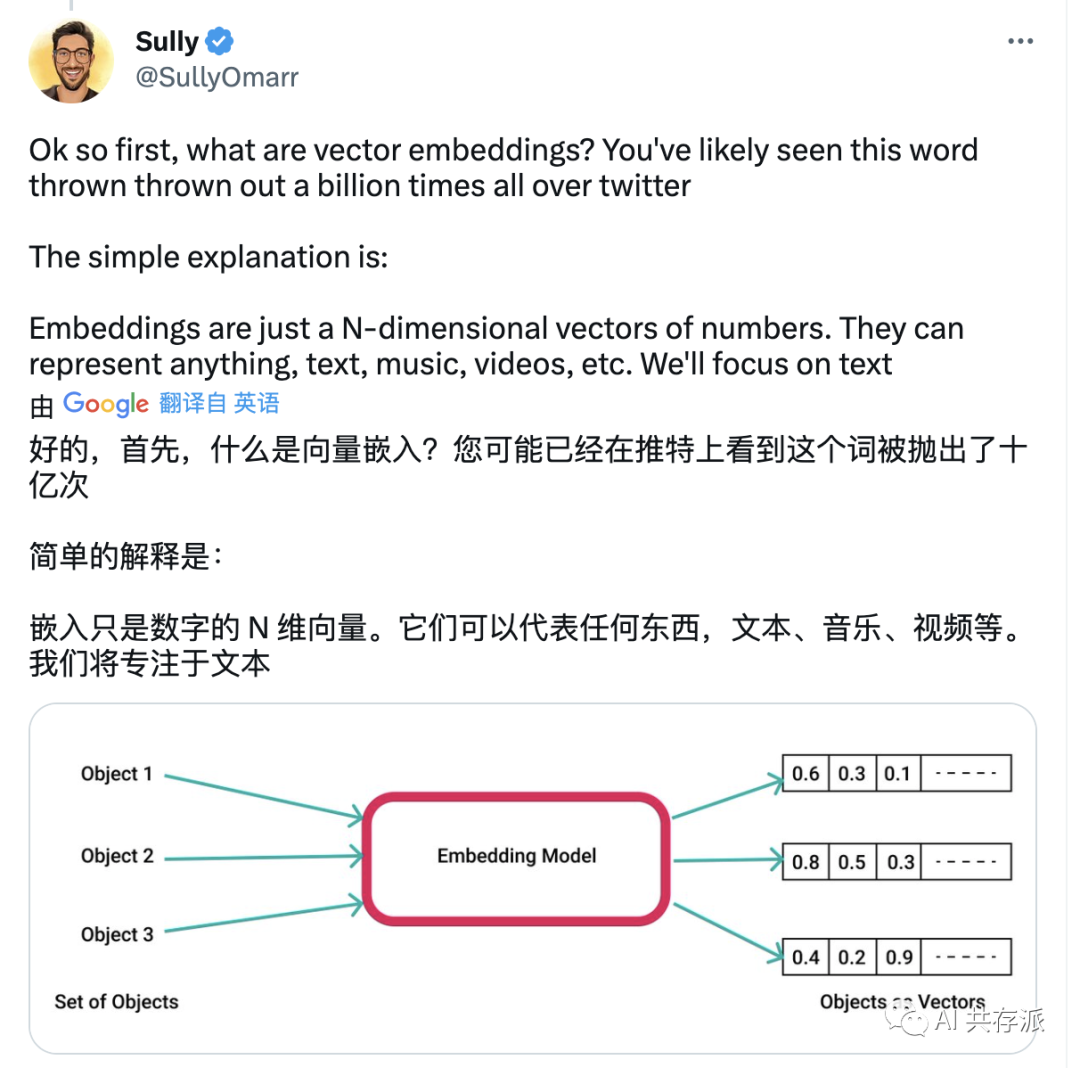


来源https://mp.weixin.qq.com/s/PHir_Qdo-8S30gG06VVNOA