1.决策树算法地位
决策树属于分类问题,是有监督学习的一部分,并且属于有监督学习里的分类问题;
2.决策树的结构
顾名思义:就是一个树结构(可以是二叉树也可以非二叉树):
-
树的非叶子节点表示一个特征属性上的测试;
-
树的每个分支代表这个特征属性在某个值域上的输出;
每个叶子节点存放的是一个类别。
3.决策树算法的核心思想:
- 从根节点开始,测试待分类项中的相应的特征属性;
- 并按照其值选择输出分支,直到到达叶子节点;
- 将叶子节点存放的类别作为决策结果。
我们用一张图来表示一下:

比如说给出特征:体积大+不会游泳+哺乳动物+食肉,根据这个决策树我们最可能得出的一类就是棕熊类,如果来新的特征的类别,就把他往里加。
4.决策树构建的关键点及决策树的指标
说白了,就是进行属性的选择,确定各个特征属性之间的树结构。
构架决策树的关键就是按所有的特征属性进行划分操作,对所有的划分操作的结果集的“纯度”进行比较,选择“纯度”最高的属性作为分割数据集的数据点。
那这个纯度的意思呢?
我们可以用一下几个指标来量化它:
- 信息熵

- GINI系数

其中pk是表示样本属于类别k的概率(共k类),分割前和后的纯度差异越大,说明决策树效果越好。
还有其他的决策树:
- ID3
- C4.5
- CART(常用作和集成学习一起的Boost构建决策森林,即多个决策树一起预测)
5.决策树构建过程
- 特征选择:从训练数据的特征中选择一个特征作为当前节点的分裂标准(特征选择的标准不用就会产生不同决策树算法)
简单地说,就是如何分叉; - 生成决策树:根据所选的特征评估标准,从上至下递归生成,知道数据集不可分,就停止决策树生长
递归调用手动生成还是很容易生成代码的
- 剪枝:决策树容易过拟合(因为如果对训练集训练太充分就会导致分成很多类,结果就是决策树非常长,深度很深),需要剪枝来缩小树的结构和规模(预剪枝+后剪枝)
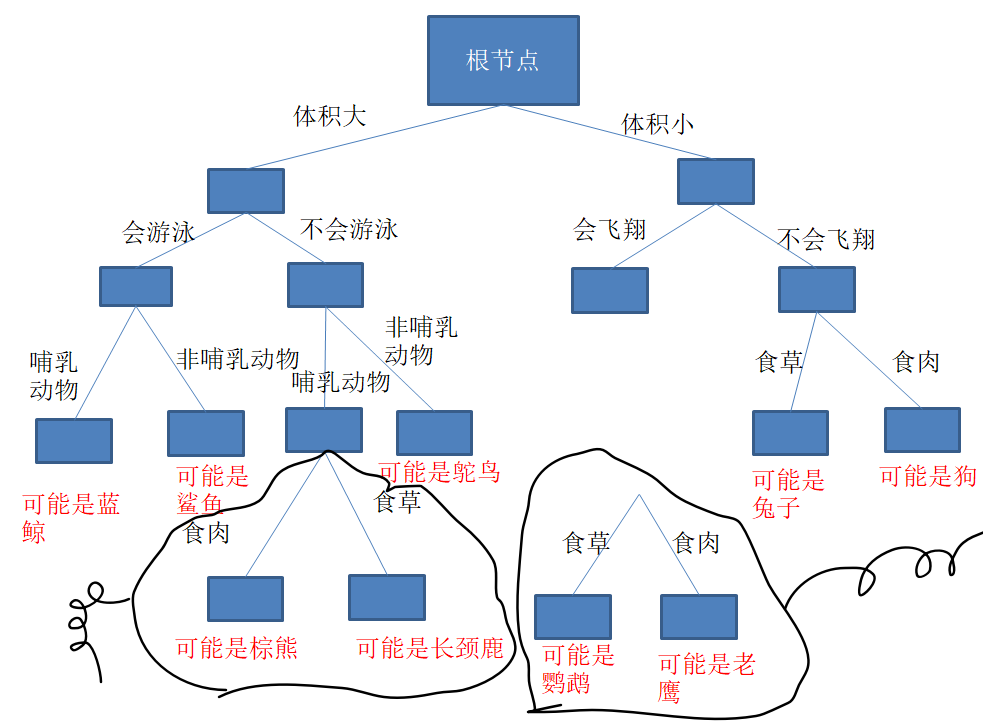
- 剪枝:如上图,过于复杂的分类,把“会飞翔”后面的全部删除,不需要那么多“食草食肉”的判断依据,左边也是,把他们从原来书上脱离,这里剪枝要把所在位置及其往下部分全部移走。
5.最后,总结
-
决策树属于分类问题,是有监督学习的一部分;
-
决策树可以是二叉树也可以非二叉树;
-
每个叶子节点存放的是一个类别;
-
核心思想:从根节点开始,一个一个去看样本的特征,并按照其值选择输出分支,直到到达叶子节点;
-
决策树构建的关键:特征属性的选择,不同选择生成不同决策树;
-
决策树分割前和后的纯度差异越大,说明决策树效果越好。
-
通过剪枝来缓解过拟合,因为可能有很多分支,决策树深度很深,分很多类;