CCNet: Criss-Cross Attention for Semantic Segmentation
* Authors: [[Zilong Huang]], [[Xinggang Wang]], [[Yunchao Wei]], [[Lichao Huang]], [[Humphrey Shi]], [[Wenyu Liu]], [[Thomas S. Huang]]
初读印象
comment:: (CCNet)每个像素通过一个十字注意力模块捕获十字路径上的语义信息,通过多次重复操作,每个点最终能够获得整张图的信息。
Why
CNN不能捕获全局信息,注意力太费计算和存储资源。
What
将nonlocal中稠密连接(每个点之间都会连接)的图换成连续的多个稀疏连接的图。CCNet使用了两个交错的注意力模块,分布汇聚了水平方向和垂直方向的上下文信息。能把复杂度从\(O(N^2)\)降低到\(O(N\sqrt{N})\)
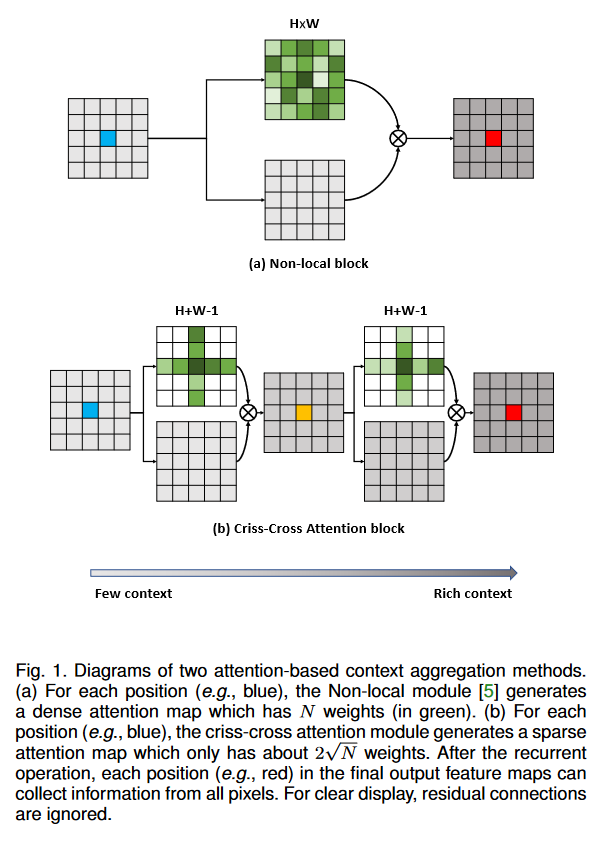 ###How
###How
网络总体架构
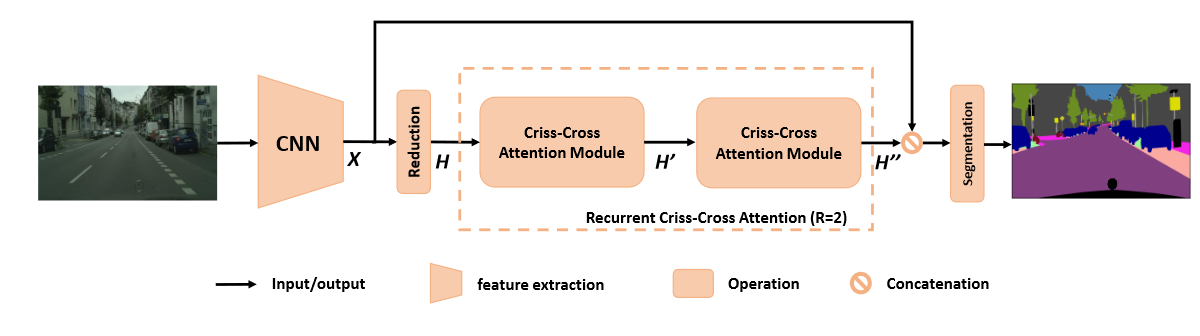
- CNN的下采样倍率为8。
- reduction。
- 经过recurrent criss-cross attention (RCCA)模块:
- 第一个CC注意力模块,使每个像素都汇集其十字路线上的语义信息。
- 第二个CC注意力模块,每个像素获得了所有点的语义信息。(这两个CC注意力模块是共享参数的,)。
- 拼接H''和X,经过多个卷积、BN、激活函数得到分割图。
Criss-Cross Attention
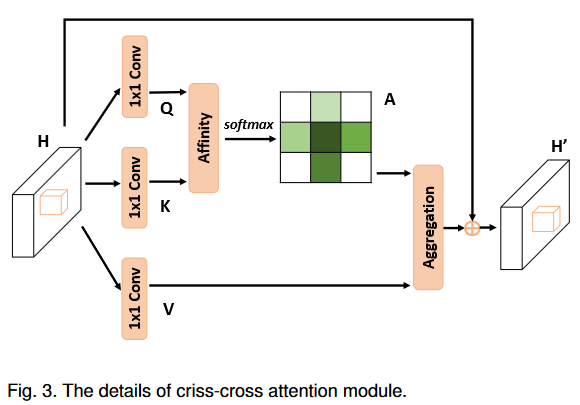
A
- 输入\(H\in R^{C\times H \times W}\)
- 使用\(1\times1\)卷积得到Q和K特征图(Reduction)
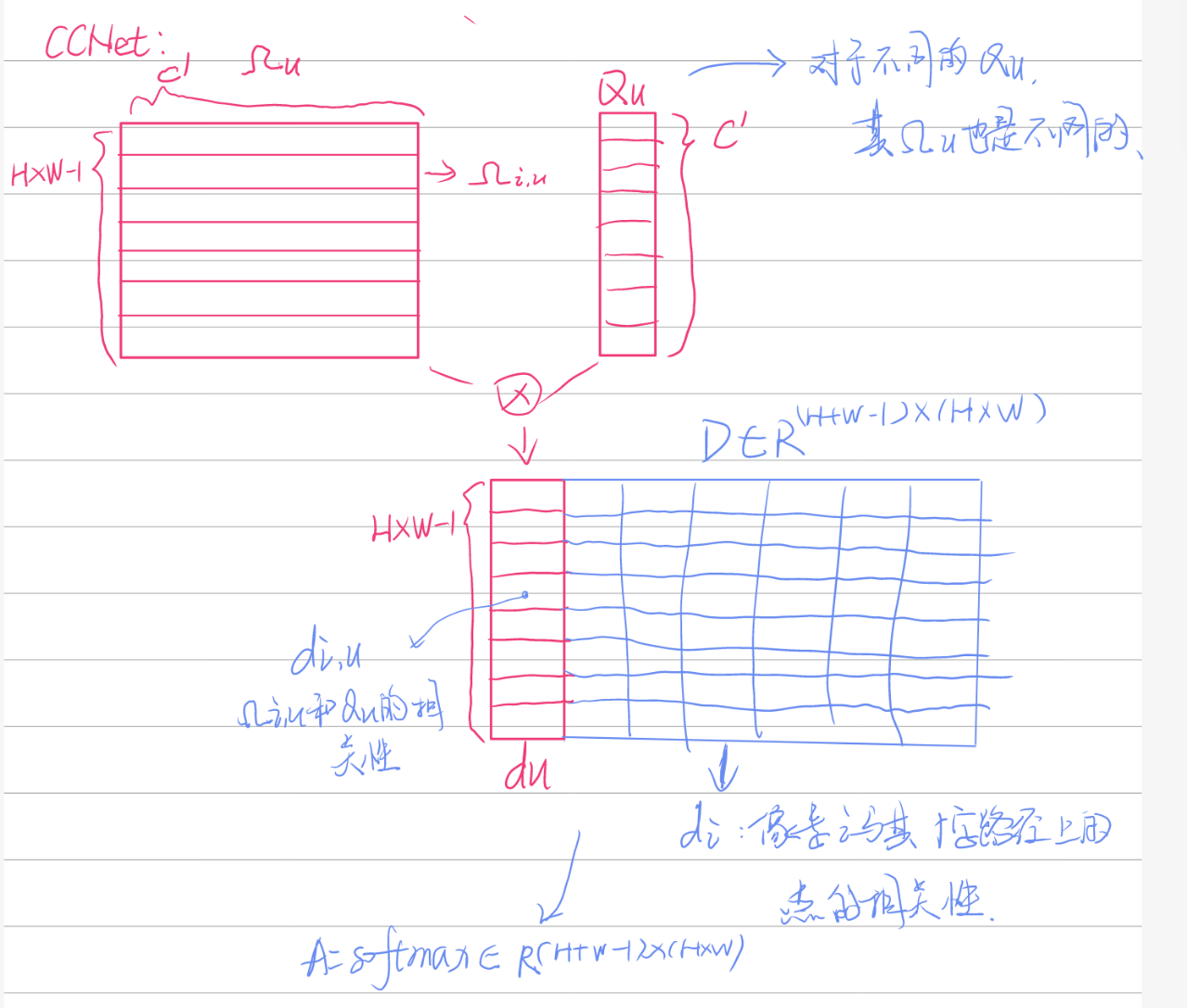
- 通过Affinity操作得到注意力图\(A\in R^{(H\times W -1)\times(W\times H)}\):
-
\(Q_u\in R^{C'}\)是\(Q\)中一个像素上的向量,\(\Omega_u\in R^{(H+W-1)\times C'}\)是\(K\)中与像素u同行同列的向量。
-
\(\Omega_{i,u}\in R^{C'}\)是\(\Omega_u\)的第i个向量,\(d_{i,u}\)是\(Q_u\)和 \(\Omega_{i,u}\)的相关度:
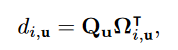
-
合并\(d_u\)得到D,经过softmax得到A
-
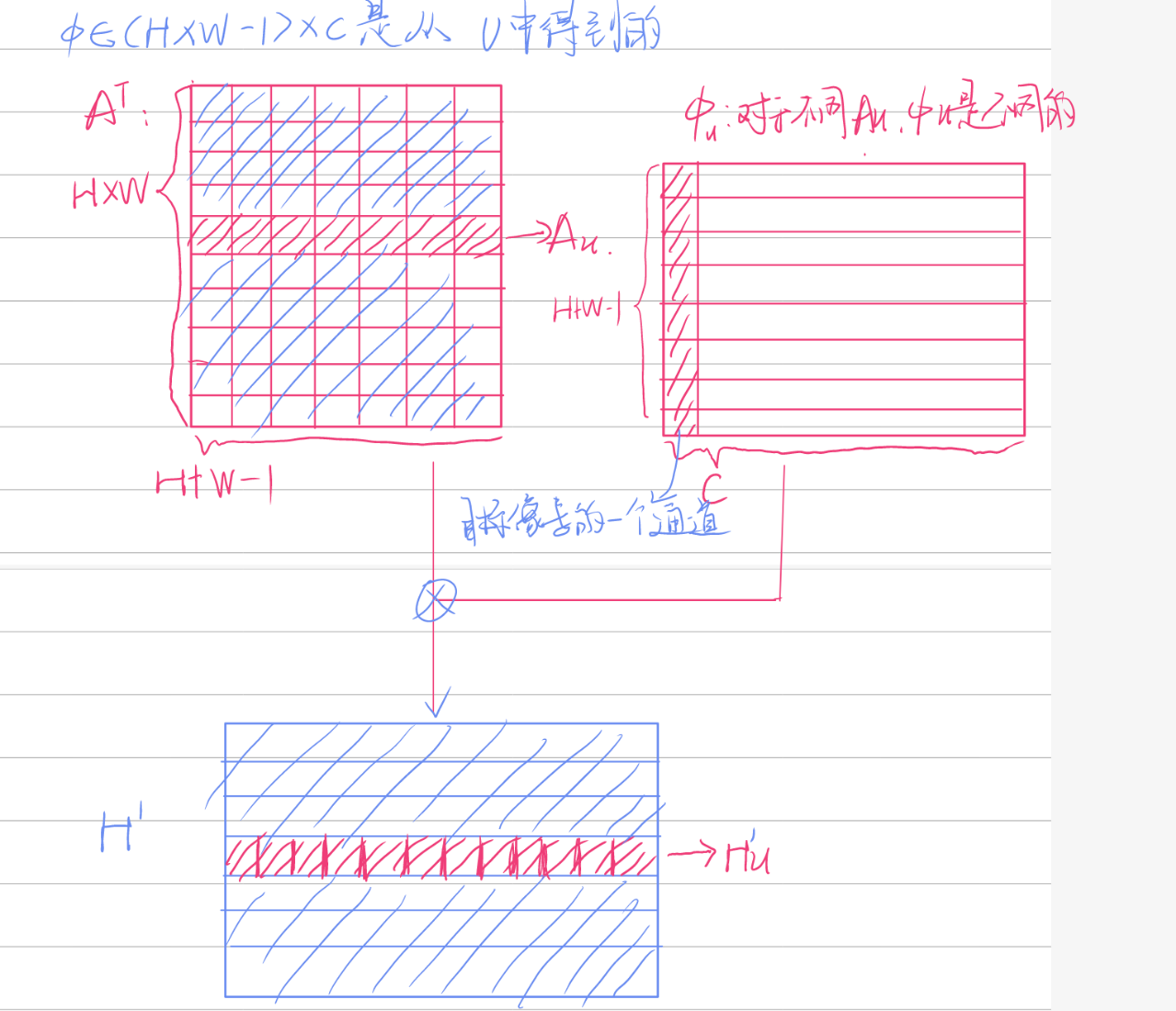
使用又一个\(1\times1\)卷积得到V特征图(通道数仍为C)。从V中得到像素u十字路径上的特征向量矩阵\(\Phi_u\),相乘得到\(H'_u\)。
-
与输入矩阵H相加得到最终结果:
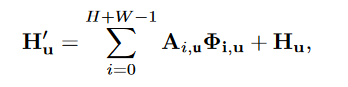 ####Recurrent Criss-Cross Attention (RCCA)
####Recurrent Criss-Cross Attention (RCCA)
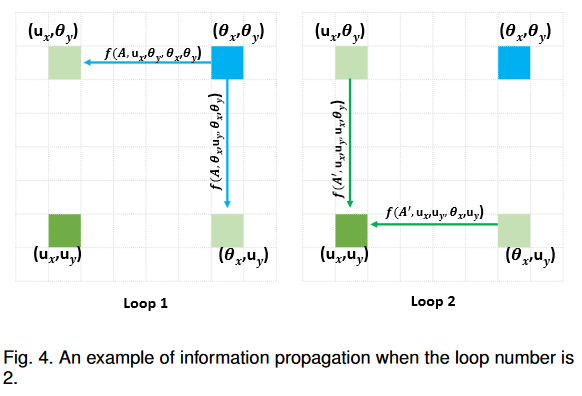
不在十字路径上的点(蓝色)到绿色点的信息流通路径。
-
类别一致性损失
将RCCA得到的特征图reduction后(一般通道数降低到16),使用了四种额外的损失:
- \(\ell_{seg}\):交叉熵损失
- \(\ell_{var}\):惩罚与相同类的特征向量过远的像素
- \(\ell_{dis}\):惩罚和不同类的特征向量过近的像素
- \(\ell_{reg}\):惩罚所有像素的平均特征向量与初始值过远的情况(类似于权重衰退的L2正则化?)
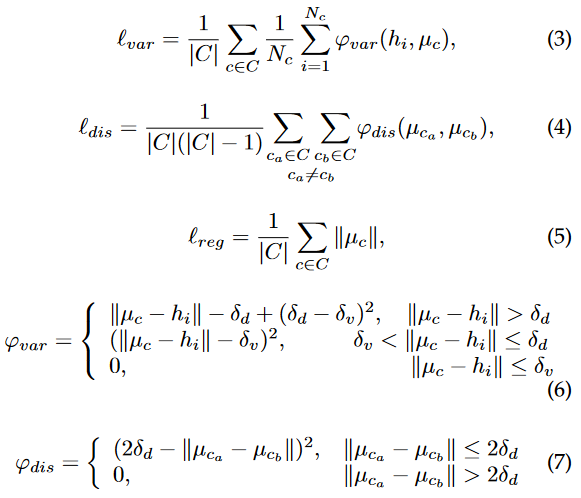 其中:* C是类别集合;
其中:* C是类别集合;
- \(N_C\)是属于c类的像素数;
- \(h_i\)是H矩阵中像素i的特征向量;
- \(\mu_C\)是C类的平均特征向量。
最终损失为:
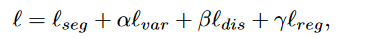
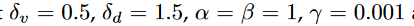
Experiment
网络细节
backbone:ResNet-101(去除最后两个stage的下采样,并换用空洞卷积)
学习率策略:SDG with mini-batch,poly(power=0.9)。动量(0.9),权重衰退(0.0001)
初始学习率:0.01for Cityscapes and ADE20K
数据增强: (pdf)
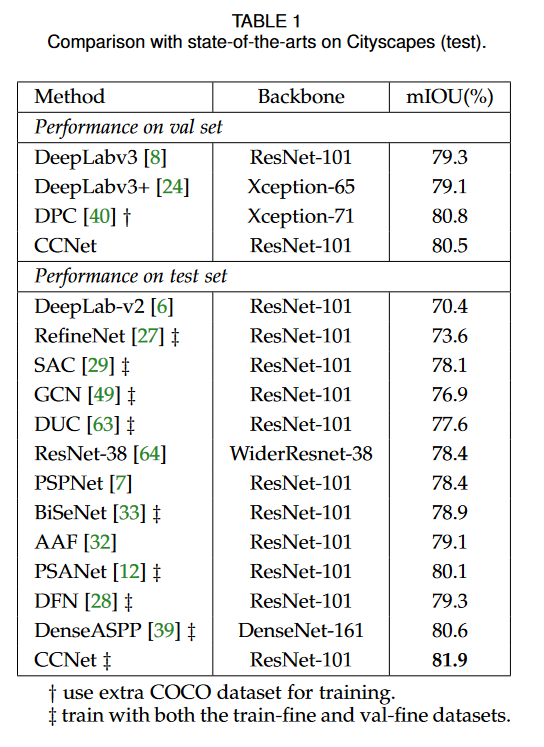
性能比较(Cityscapes)
 ####消融实验
####消融实验
RCCA
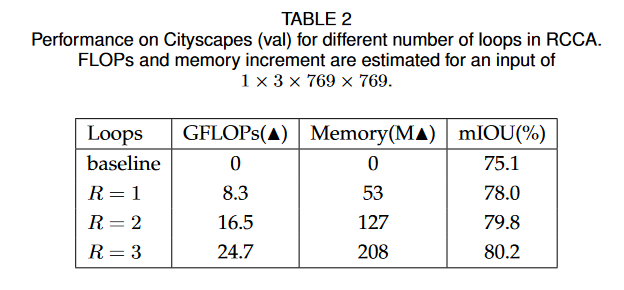
RCCA是有效的,但是当循环太多时,会浪费资源。
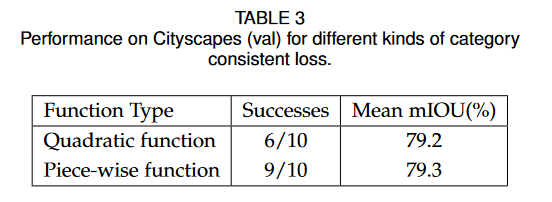
 #####类别一致损失
#####类别一致损失
损失值为NaN时代表训练失败,使用了CCL的训练成功率更高。
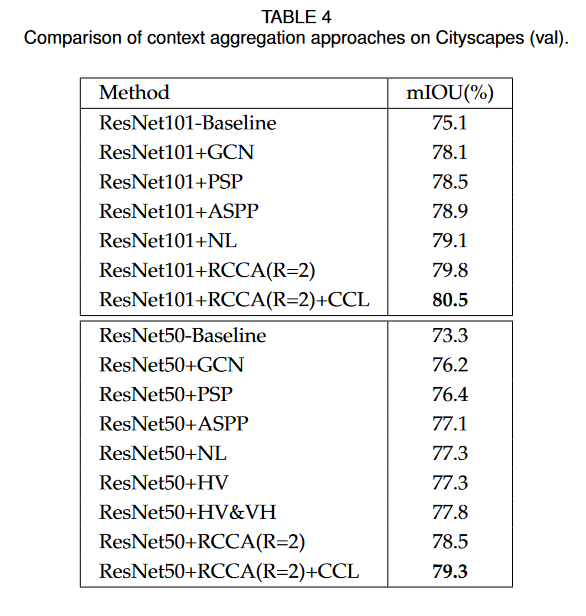
Conclusion
这篇文章总体思路应该和A Nonlocal是相同的,都是通过减少采样数量来降低运算量。不同的是,A Nonlocal是通过平均池化来采样,并融合了多尺度信息来弥补下降的精度,而CCNet是通过两次采样十字路径上的点来近似得到采样了所有点的效果。
- Segmentation Criss-Cross Attention Semantic CCNetsegmentation criss-cross attention semantic convolutional segmentation networks semantic segmentation generative gaussian semantic segmentation attentional semantic network segmentation transformers semantic segvit convolutional segmentation rethinking attention segmentation注意力attention network ccnet criss-cross segmentation