ntpdate ntp.aliyun.com
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
java -version
-
-
查看防火墙状态:systemctl status firewalld
-
-
-
直接使用图形化界面配置(不推荐)
-
1、编辑网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
BOOTPROTO=static
HWADDR=00:0C:29:E2:B8:F2
NAME=ens33
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.190.100
GATEWAY=192.168.190.2
NETMASK=255.255.255.0
DNS1=192.168.190.2
DNS2=223.6.6.6
需要修改:HWADDR(mac地址,centos7不需要手动指定mac地址)
IPADDR(根据自己的网段,自定义IP地址)
GATEWAY(根据自己的网段填写对应的网关地址)
2、关闭NetworkManager,并取消开机自启
systemctl stop NetworkManager
systemctl disable NetworkManager
systemctl status NetworkManager
3、重启网络服务
systemctl restart network
以上在配置虚拟机时应该就已经做好了
配置好映射文件:/etc/hosts
192.168.190.100 master
192.168.190.101 node1
192.168.190.102 node2
#配置好后使用scp /etc/hosts node1:/etc/hosts命令将hosts文件复制给node1与node2
免密登录(三台虚拟机都应配置一遍)
# 1、生成密钥
ssh-keygen -t rsa
# 2、配置免密登录
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
# 3、测试免密登录
ssh node1
DataNode:真实数据存储的地方(block)
| 进程 | master(主) | node1(从) | node2(从) |
|---|---|---|---|
| NameNode | √ | ||
| SecondaryNameNode | √ | ||
| ResourceManager | √ | ||
| DataNode | √ | √ | |
| NodeManager | √ | √ |
# 1、解压
tar -xvf hadoop-3.1.1.tar.gz.gz
# 2、配置环境变量
vim /etc/profile
# 3、在最后增加配置
export HADOOP_HOME=/usr/local/soft/hadoop-3.1.1
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
# 4、使环境变量剩下
source /etc/profile
# 1、进入hadoop配置文件所在位置,修改hadoop配置文件
cd /usr/local/soft/hadoop-3.1.1/etc/hadoop
# 2、修改core-site.xml配置文件,在configuration中间增加配置
vim core-site.xml
# 增加配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-3.1.1/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
# 3、修改hdfs-site.xml配置文件,在configuration中间增加配置
vim hdfs-site.xml
# 增加配置
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
# 4、修改yarn-site.xml配置文件,在configuration中间增加配置
vim yarn-site.xml
# 增加配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
> mapreduce.framework.name:用于执行MapReduce作业的运行时框架。
> mapreduce.jobhistory.address:Hadoop自带了一个历史服务器,可以通过历史服务器查看已经运行完的Mapreduce作业记录,比如用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息。默认情况下,Hadoop历史服务器是没有启动的,我们可以通过*mr-**jobhistory-daemon.sh start historyserver**命令来启动Hadoop历史服务器。我们可以通过Hadoop jar的命令来实现我们的程序jar包的运行,关于运行的日志,我们一般都需要通过启动一个服务来进行查看,就是我们的JobHistoryServer,我们可以启动一个进程,专门用于查看我们的任务提交的日志。mapreduce.jobhistory.address和mapreduce.jobhistory.webapp.address默认的值分别是0.0.0.0:10020和0.0.0.0:19888
vim mapred-site.xml
# 2、修改
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
# 5、修改hadoop-env.sh配置文件
vim hadoop-env.sh
# 增加配置
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_202.jdk/Contents/Home
# 6、修改hadoop-env.sh配置文件
vim workers
# 增加配置
node1
node2
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#master与node1,node2节点都在 /usr/local/soft/路径下 或者直接写明路径
scp -r hadoop-3.1.1 node1:`pwd`
scp -r hadoop-3.1.1 node2:`pwd`
# 初始化 只在第一次启动时进行
hdfs namenode -format
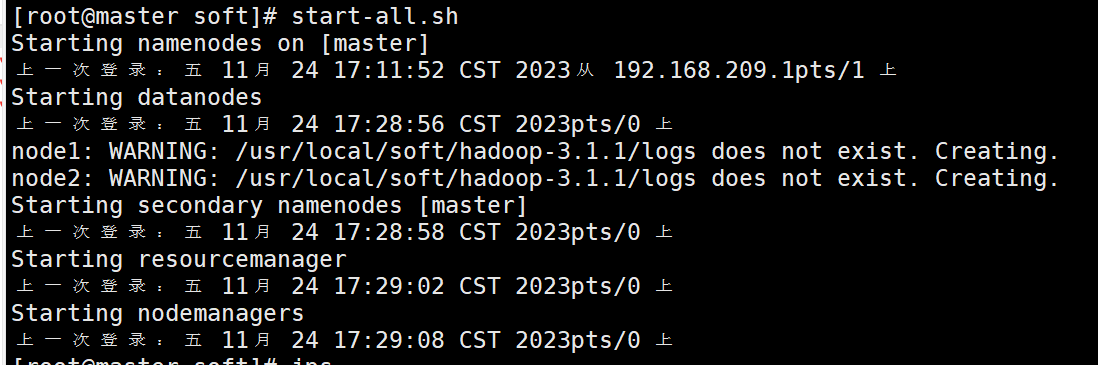
# 启动hadoop
start-all.sh
# 停止hadoop
# stop-all.sh
# hdfs web ui
http://master:9870
# yarn web ui
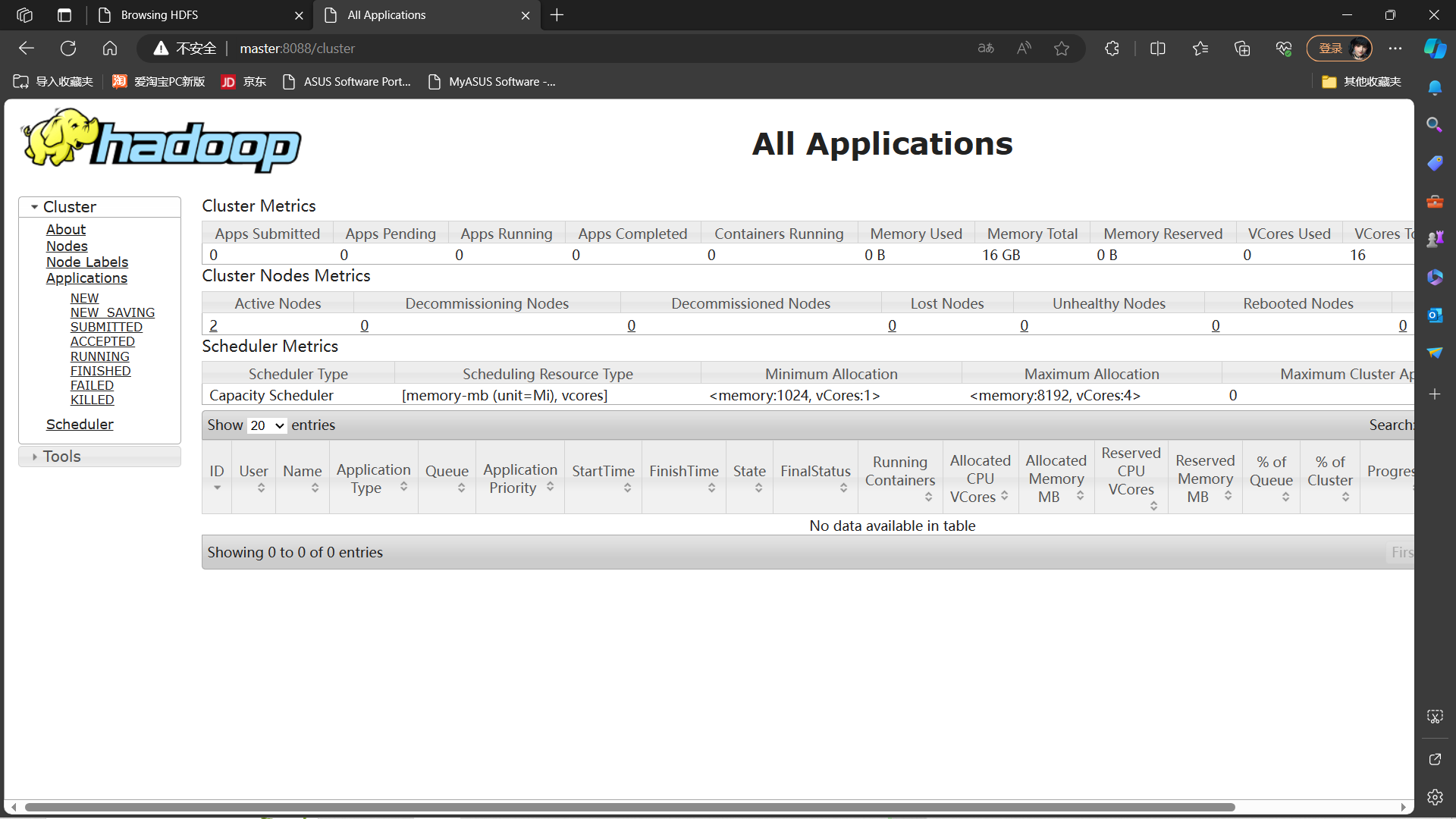
http://master:8088
# 进入日志所在目录
cd /usr/local/soft/hadoop-3.1.1/logs
# 1、namenode启动失败
cat hadoop-root-namenode-master.log
# 2、resourcemanager启动失败
cat hadoop-root-resourcemanager-master.log
# 3、datanode启动失败
cat hadoop-root-datanode-master.log
stop-all.sh
rm -rf tmp/
hdfs namenode -format
start-all.sh

node1:

node2:

Hadoop中的常见的shell命令
推荐第一种格式
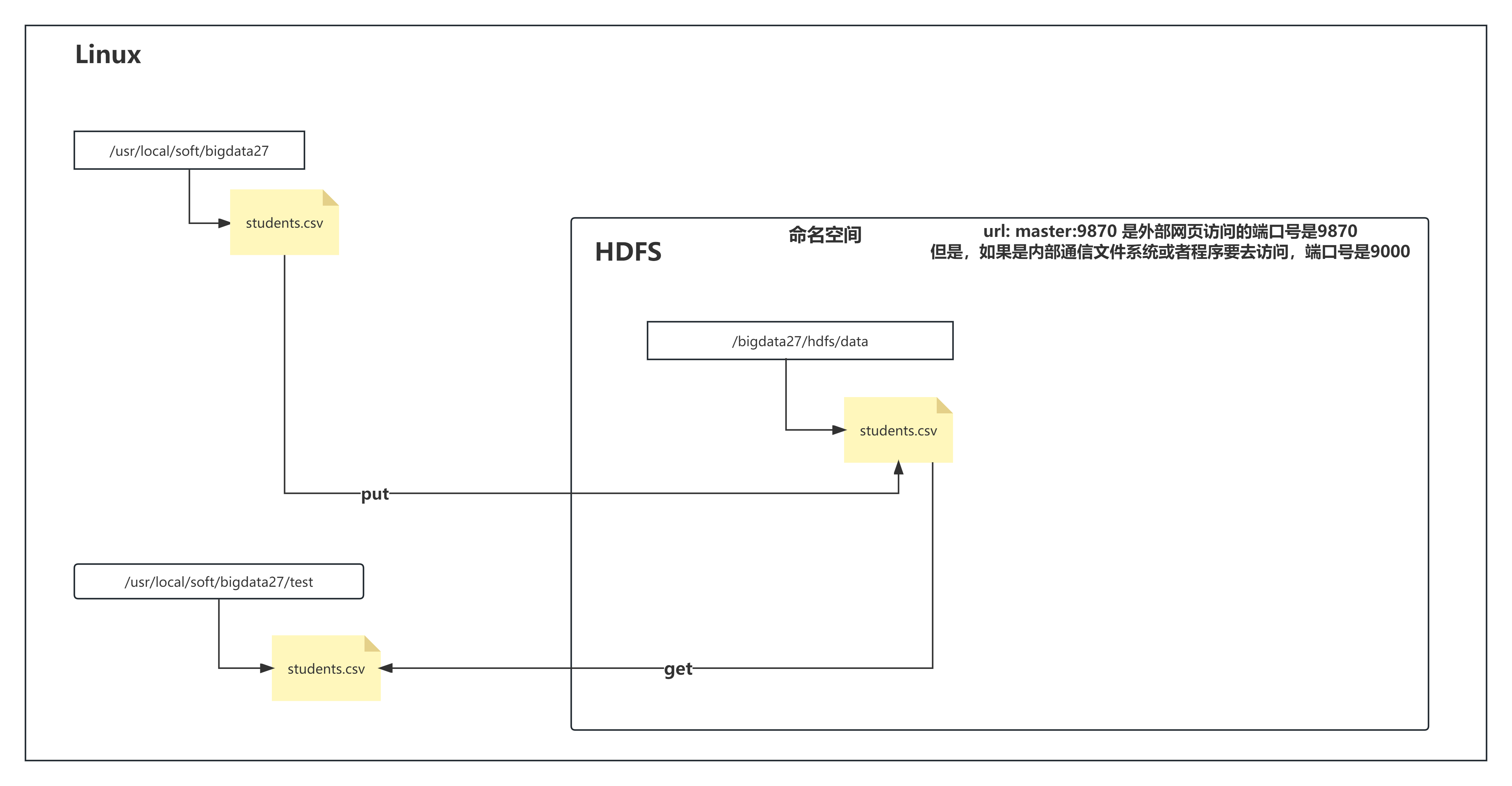
1、如何将linux本地的数据上传到HDFS中呢?tuijian
hadoop fs -put 本地的文件 HDFS中的目录
hdfs dfs -put 本地的文件 HDFS中的目录
2、如何创建HDFS中的文件夹呢?
需求:想创建/shujia/bigdata17
hadoop fs -mkdir /shujia/bigdata17
hdfs dfs -mkdir /shujia/bigdata17
注意:如果要创建多级目录,加上-p参数 :hadoop fs -mkdir -p /bigdata27/hdfs/data
3、查看当前HDFS目录下的文件和文件夹
hadoop fs -ls /shujia/bigdata17
hdfs dfs -ls /shujia/bigdata17
4、将HDFS的文件下载到Linux本地中
hadoop fs -get HDFS中的文件目录 本地要存放文件的目录
hdfs dfs -get HDFS中的文件目录 本地要存放文件的目录
5、删除命令(如果垃圾回收站大小小于被删除文件的大小,直接被删除,不经过回收站)
hadoop fs -rm .... # 仅删除文件
hadoop fs -rmr .... # 删除文件夹
6、移动文件
hadoop fs -mv 目标文件 目的地路径
7、HDFS内部复制文件
hadoop fs -cp [-p] ... ... # 如果想复制文件夹,加上-p参数
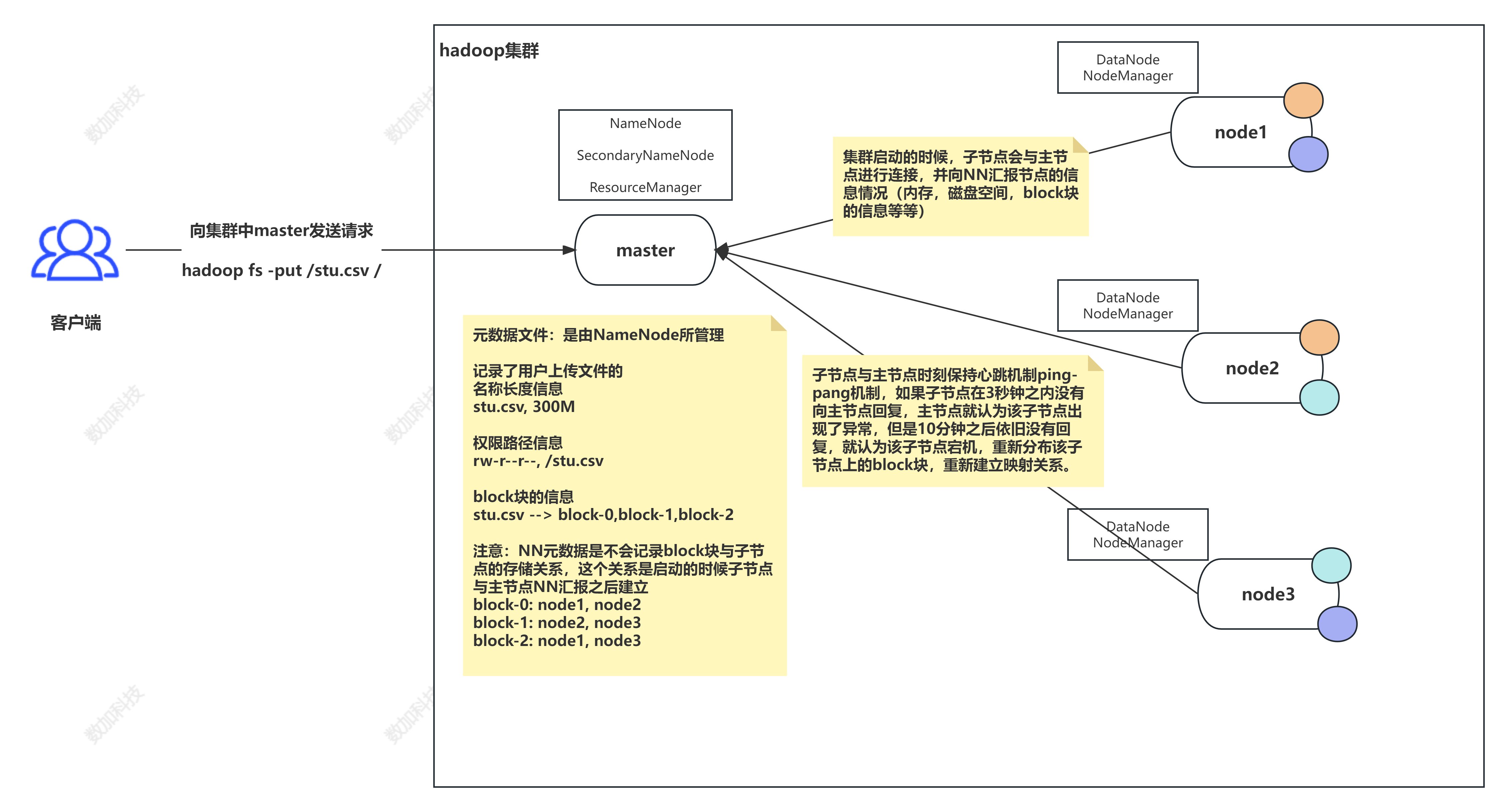
进程理解
HDFS相关(NN,DN,SSN)
NameNode(NN)
1、接受客户端的读/写服务
因为NameNode知道数据文件与DataNode的对应关系
2、保存文件的时候会保存文件的元数据信息
a. 文件的归属
b. 文件的权限
c. 文件的大小,时间
d. Block信息,但是block的位置信息不会持久化,需要每次开启集群的时候DN向NN汇报。(带同学们画图讲解,引出这4个点)
面试题:为什么hadoop不适合存储小文件(1、从NN角度去分析 2、DN角度分析 3、从MR角度分析)
3、收集Block的位置信息
3.1 系统启动
a. NN关机的时候是不会存储任何的Block与DataNode的映射信息的
b. DN启动的时候会自动将自己节点上存储的Block信息汇报给NN
c. NN接收请求之后会重新生成映射关系
File ----> Block
Block---> DN
d. 如果数据块的副本数小于设置数,那么NN会将这个副本拷贝到其他节点
3.2 集群运行中
a. NN与DN保持心跳机制,三秒钟发送一次
b. 如果客户端需要读取或者上传数据的时候,NN可以知道DN的健康情况
c. 可以让客户端读取存活的DN节点
d. 如果NN与DN三秒没有心跳则认为DN出现异常,此时不会让新的数据写到这个异常的DN中,客户端访问的时候不提供异常DN节点地址
e. 如果超过十分钟没有心跳,那么NN会将当前DN节点存储的数据转移到其他的节点
4、NameNode为了效率,将所有的操作都在内存中进行
a. 执行速度快
b. NameNode不会和磁盘进行任何的数据交换
但是会存在两个问题:
1)数据的持久化
2、数据会存放在硬盘上
a. 1m=1条元数据
b. 1G=1条元数据
c. NameNode非常排斥存储小文件(能存,但是不推荐!!面试必问)
一般小文件在存储之前需要进行压缩
3、汇报
1)启动时
汇报之前会验证Block文件是否被损坏
向NN汇报当前DN上block的信息
2)运行中
向NN保持心跳机制
1)日志机制
a. 做任何操作之前先记录日志
b. 在数据改变之前先记录对应的日志,当NN停止的时候
c. 当我下次启动的时候,只需要重新按照以前的日志“重做一遍”即可
缺点:
a. log日志文件的大小不可控,随着时间的发展,集群启动的时间会越来越长
b. 有可能日志中存在大量的无效日志
优点:
a. 绝对不会丢失数据
2)拍摄快照
a. 我们可以将内存中的数据写出到硬盘上(序列化)
b. 启动时还可以将硬盘上的数据写回到内存中(反序列化)
缺点:
a. 关机时间过长
b. 如果是异常关机,数据还在内存中,没法写入到硬盘
c. 如果写出的频率过高,导致内存使用效率低
优点:
启动时间较短
2、SNN的解决方案(面试题)
1)解决思路
a. 让日志大小可控(每64M)
b. 快照需要定时保存(每隔1h)
c. 日志+快照
2)解决方案
a. 当我们启动一个集群的时候,会产生4个文件 ..../name/current/
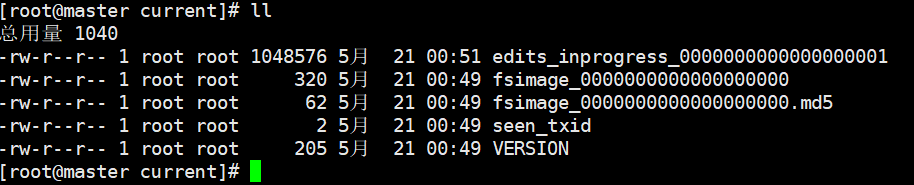
b.
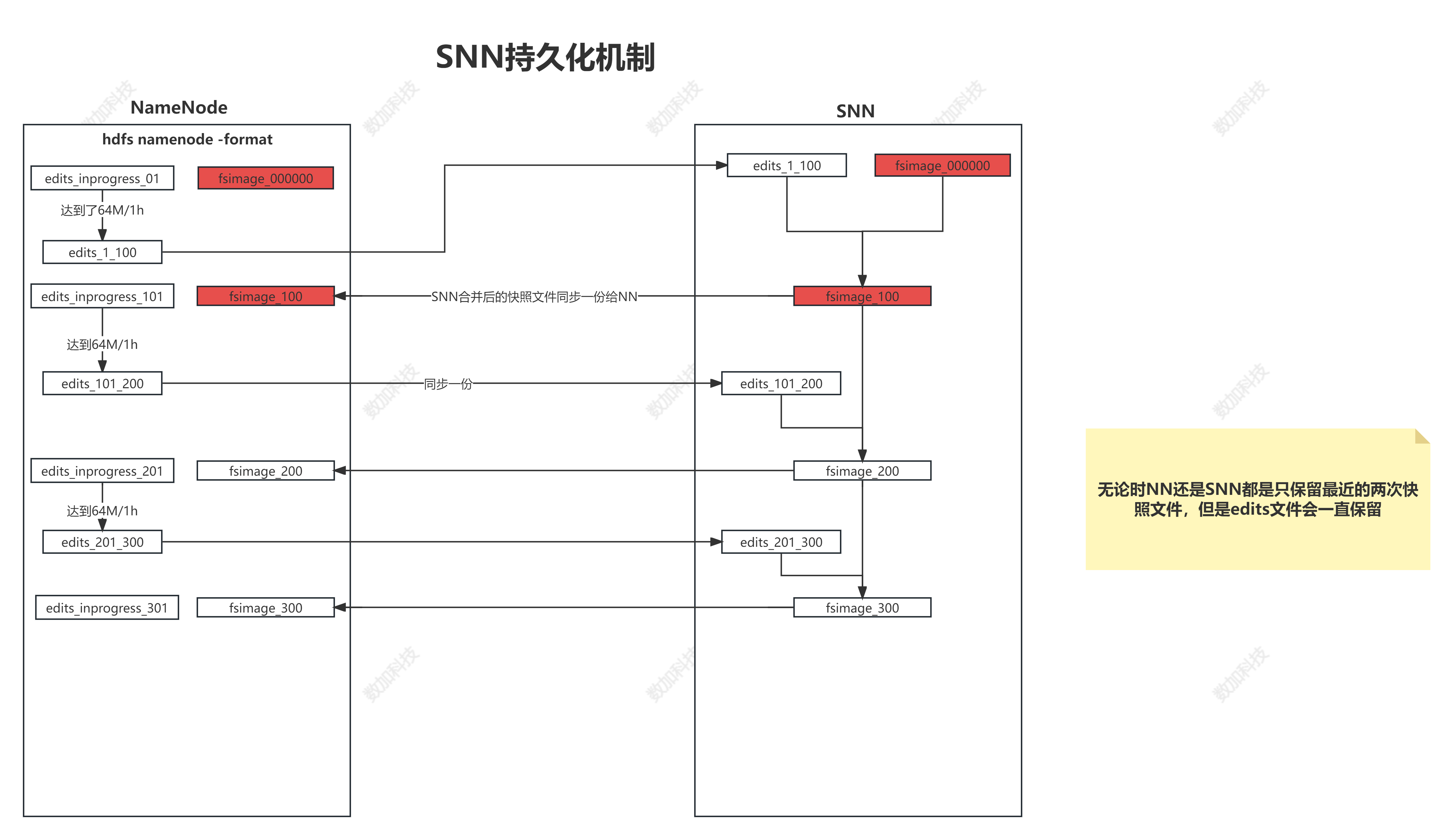
# 对安全模式的理解
# 1.工作流程
a.启动 NameNode,NameNode 加载 fsimage 到内存,对内存数据执行 edits log 日 志中的事务操作。
b.文件系统元数据内存镜像加载完毕,进行 fsimage 和 edits log 日志的合并,并创 建新的 fsimage 文件和一个空的 edits log 日志文件。
c.NameNode 等待 DataNode 上传 block 列表信息,直到副本数满足最小副本条件。
d.当满足了最小副本条件,再过 30 秒,NameNode 就会退出安全模式。最小副本条件指 整个文件系统中有 99.9%的 block 达到了最小副本数(默认值是 1,可设置)
# 在 NameNode 安全模式(safemode)
对文件系统元数据进行只读操作
当文件的所有 block 信息具备的情况下,对文件进行只读操作
不允许进行文件修改(写,删除或重命名文件)
# 2.注意事项
a.NameNode 不会持久化 block 位置信息;DataNode 保有各自存储的 block 列表信息。 正常操作时,NameNode 在内存中有一个 blocks 位置的映射信息(所有文件的所有文 件块的位置映射信息)。
b.NameNode 在安全模式,NameNode 需要给 DataNode 时间来上传 block 列表信息到 NameNode。如果 NameNode 不等待 DataNode 上传这些信息的话,则会在 DataNode 之间进行 block 的复制,而这在大多数情况下都是非必须的(因为只需要等待 DataNode 上传就行了),还会造成资源浪费。
c.在安全模式 NameNode 不会要求 DataNode 复制或删除 block。
d.新格式化的 HDFS 不进入安全模式,因为 DataNode 压根就没有 block。
# 4.命令操作
# 通过命令查看 namenode 是否处于安全模式:
hdfs dfsadmin -safemode get
Safe mode is ON HDFS 的前端 webUI 页面也可以查看 NameNode 是否处于安全模式。 有时候我们希望等待安全模式退出,之后进行文件的读写操作,尤其是在脚本中,此时:
`hdfs dfsadmin -safemode wait`
# your read or write command goes here 管理员有权在任何时间让 namenode 进入或退出安全模式。进入安全模式:
`hdfs dfsadmin -safemode enter`
Safe mode is ON 这 样 做 可 以 让 namenode 一 直 处 于 安 全 模 式 , 也 可 以 设 置 `dfs.namenode.safemode.threshold-pct` 为 1 做到这一点。 离开安全模式:
`hdfs dfsadmin -safemode leave`
Safe mode is OFF
安全模式下
a. 安全模式下,各个 DataNode 会向 NameNode 发送自身的数据块列表
b. 当 NameNode 有足够的数据块信息后,便在 30 秒后退出安全模式
c. NameNode 发现数据节点过少会启动数据块复制过程
如果 NN 收集的 Block 信息没有达到最少副本数,就会将缺失的副本 , 从有的 DN 上拷贝到其他 DN
a. dfs.replication.min=2
b. 但是默认最低副本数为 1
c. 在拷贝的过程中系统还是处于安全模式
安全模式相关命令
hadoop dfsadmin -safemode leave 强制 NameNode 退出安全模式
hadoop dfsadmin -safemode enter 进入安全模式
hadoop dfsadmin -safemode get 查看安全模式状态
a. 只能防止好人做错事
b. 不能防止坏人做坏事

