from numpy import *
import pandas as pd
import matplotlib.pyplot as plt
# 计算两点之间的欧式距离
def dist(a, b):
return sqrt(sum((a - b) ** 2))
# 生成聚类中心
def create_center(data, k, defaultPts=[0,3,6]):
# 固定的几个点作为聚类中心
if defaultPts is not None:
# 存在默认点
pt = zeros((k, n), dtype=float64)
# 使用默认点作为聚类中心
for i in range(k):
dpt = defaultPts[i]
if dpt is None:
# 如果没有默认点,则随机选取一个点作为聚类中心
dpt = random.randint(0, len(data) - 1)
pt[i] = data[dpt]
return pt
# 随机选取k个数据作为聚类中心
return data[random.randint(0, len(data) - 1, k)]
# 聚类
def kMeans(data, k, dist, centroids):
# 样本个数
m = shape(data)[0]
# 聚类结果
init = zeros((m, 2), dtype=float64)
# 存储中间结果的矩阵
cluster_assment = mat(init)
for epoch in range(1):
for i in range(m):
# 计算每个样本到最近的聚类中心的距离
min_dist = inf
for j in range(k):
# 计算样本到聚类中心的距离
dist_ij = dist(data[i], centroids[j])
# 找到最近的聚类中心
if dist_ij < min_dist:
min_dist = dist_ij
# 更新样本所属的聚类中心,第1列为聚类中心的序号,第2列为距离
cluster_assment[i] = j, min_dist
# 对所有节点聚类之后,重新更新中心
for j in range(k):
pts_in_cluster = data[nonzero(cluster_assment[:, 0].A == j)[0]]
centroids[j,:] = mean(pts_in_cluster, axis=0)
# 返回聚类中心和聚类结果
return centroids, cluster_assment
if __name__ == '__main__':
# 数据集
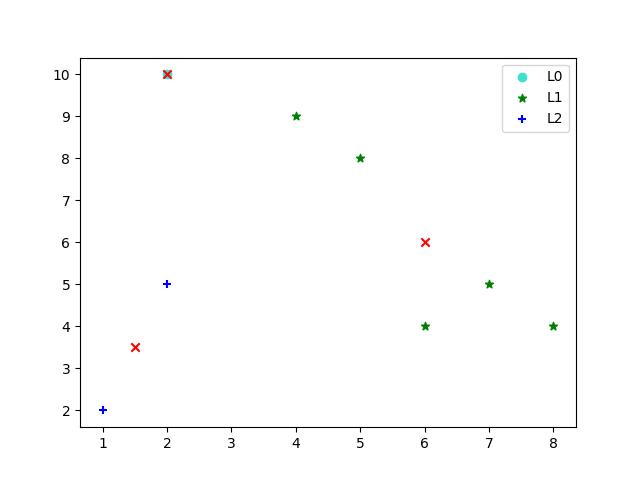
data = array([[2, 10], [2,5], [8, 4], [5, 8], [7, 5], [6, 4], [1, 2], [4, 9]])
# 聚类个数
k = 3
# 特征个数
n = 2
# 聚类
centroids, cluster_assment = kMeans(data, k, dist=dist, centroids=create_center(data, k))
# 聚类结果
predict_label = cluster_assment[:, 0]
# 给样本增加一列,表示样本所属的聚类结果
data_and_pred = column_stack((data, predict_label))
# 原始的数据样本和预测出来的类别
df = pd.DataFrame(data_and_pred, columns=['x1', 'x2', 'label'])
df0 = df[df['label'] == 0].values
df1 = df[df['label'] == 1].values
df2 = df[df['label'] == 2].values
# 画图
plt.scatter(df0[:, 0], df0[:, 1], c='turquoise', marker='o', label='L0')
plt.scatter(df1[:, 0], df1[:, 1], c='g', marker='*', label='L1')
plt.scatter(df2[:, 0], df2[:, 1], c='b', marker='+', label='L2')
plt.scatter(centroids[:, 0].tolist(), centroids[:, 1].tolist(), c='r', marker='x')
# 图例位置
plt.legend(loc=1)
# 显示图
plt.show()