前言 从四篇论文入手,Sebastian 再谈 Transformer 架构图。
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
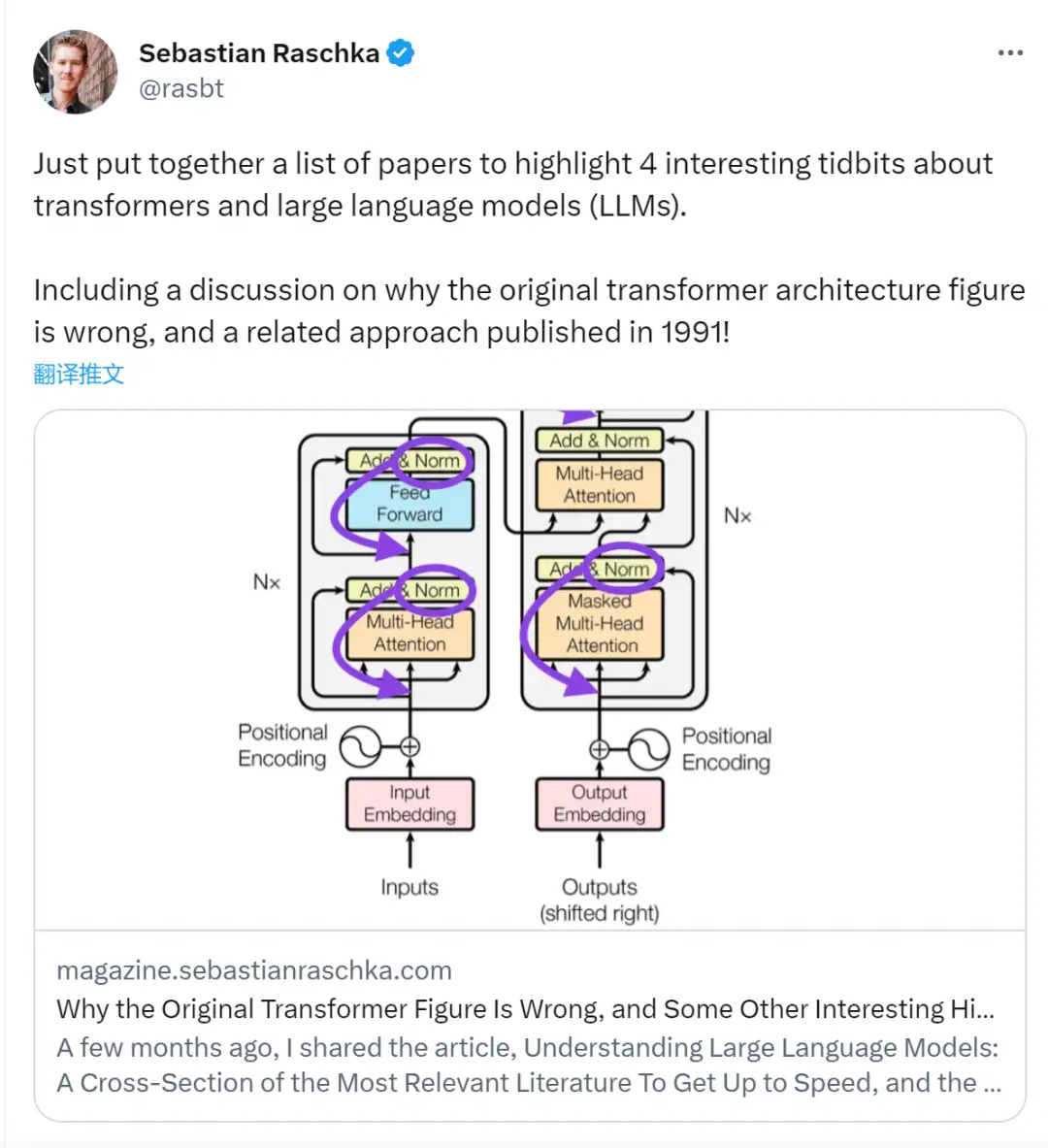
前段时间,一条指出谷歌大脑团队论文《Attention Is All You Need》中 Transformer 构架图与代码不一致的推文引发了大量的讨论。
对于 Sebastian 的这一发现,有人认为属于无心之过,但同时也会令人感到奇怪。毕竟,考虑到 Transformer 论文的流行程度,这个不一致问题早就应该被提及 1000 次。
Sebastian Raschka 在回答网友评论时说,「最最原始」的代码确实与架构图一致,但 2017 年提交的代码版本进行了修改,但同时没有更新架构图。这也是造成「不一致」讨论的根本原因。
随后,Sebastian 在 Ahead of AI 发布文章专门讲述了为什么最初的 Transformer 构架图与代码不一致,并引用了多篇论文简要说明了 Transformer 的发展变化。
以下为文章原文,让我们一起看看文章到底讲述了什么:
几个月前,我分享了《Understanding Large Language Models: A Cross-Section of the Most Relevant Literature To Get Up to Speed》,积极的反馈非常鼓舞人心!因此,我添加了一些论文,以保持列表的新鲜感和相关性。
同时,保持列表简明扼要是至关重要的,这样大家就可以用合理的时间就跟上进度。还有一些论文,信息量很大,想来也应该包括在内。
我想分享四篇有用的论文,从历史的角度来理解 Transformer。虽然我只是直接将它们添加到理解大型语言模型的文章中,但我也在这篇文章中单独来分享它们,以便那些之前已经阅读过理解大型语言模型的人更容易找到它们。
On Layer Normalization in the Transformer Architecture (2020)
虽然下图(左)的 Transformer 原始图(https://arxiv.org/abs/1706.03762)是对原始编码器 - 解码器架构的有用总结,但该图有一个小小的差异。例如,它在残差块之间进行了层归一化,这与原始 Transformer 论文附带的官方 (更新后的) 代码实现不匹配。下图(中)所示的变体被称为 Post-LN Transformer。
Transformer 架构论文中的层归一化表明,Pre-LN 工作得更好,可以解决梯度问题,如下所示。许多体系架构在实践中采用了这种方法,但它可能导致表征的崩溃。
因此,虽然仍然有关于使用 Post-LN 或前 Pre-LN 的讨论,也有一篇新论文提出了将两个一起应用:《 ResiDual: Transformer with Dual Residual Connections》(https://arxiv.org/abs/2304.14802),但它在实践中是否有用还有待观察。
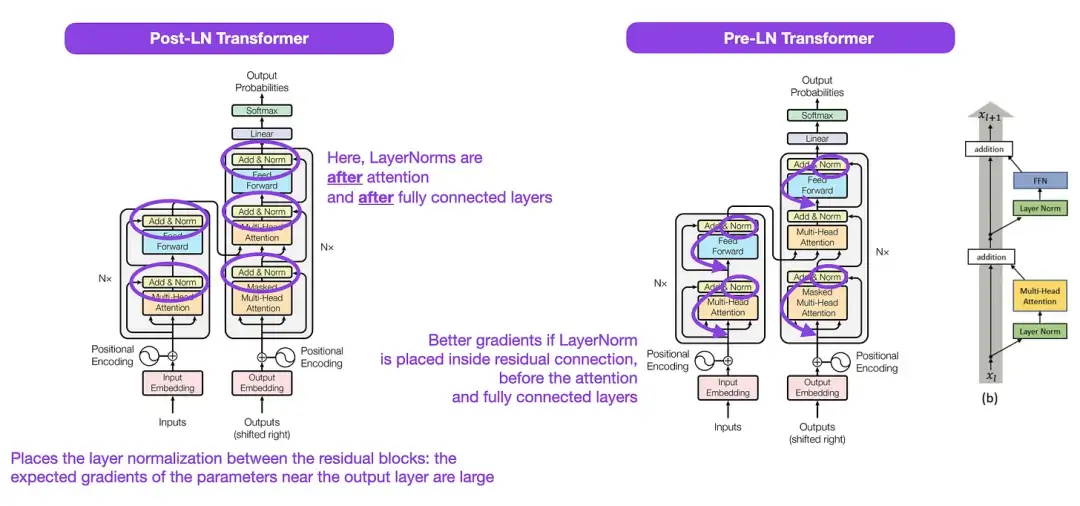
图注:图源 https://arxiv.org/abs/1706.03762 (左 & 中) and https://arxiv.org/abs/2002.04745 (右)
Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks (1991)
这篇文章推荐给那些对历史花絮和早期方法感兴趣的人,这些方法基本上类似于现代 Transformer。
例如,在比 Transformer 论文早 25 年的 1991 年,Juergen Schmidhuber 提出了一种递归神经网络的替代方案(https://www.semanticscholar.org/paper/Learning-to-Control-Fast-Weight-Memories%3A-An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922),称为 Fast Weight Programmers (FWP)。FWP 方法涉及一个前馈神经网络,它通过梯度下降缓慢学习,来编程另一个神经网络的快速权值的变化。
这篇博客 (https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2) 将其与现代 Transformer 进行类比,如下所示:
在今天的 Transformer 术语中,FROM 和 TO 分别称为键 (key) 和值 (value)。应用快速网络的输入称为查询。本质上,查询由快速权重矩阵 (fast weight matrix) 处理,它是键和值的外积之和 (忽略归一化和投影)。由于两个网络的所有操作都是可微的,我们通过加法外积或二阶张量积获得了端到端可微主动控制的权值快速变化。因此,慢速网络可以通过梯度下降学习,在序列处理期间快速修改快速网络。这在数学上等同于 (除了归一化之外) 后来被称为具有线性化自注意的 Transformer (或线性 Transformer)。
正如上文摘录所提到的,这种方法现在被称为线性 Transformer 或具有线性化自注意的 Transformer。它们来自于 2020 年出现在 arXiv 上的论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention 》(https://arxiv.org/abs/2006.16236)以及《Rethinking Attention with Performers》(https://arxiv.org/abs/2009.14794)。
2021 年,论文《Linear Transformers Are Secretly Fast Weight Programmers》(https://arxiv.org/abs/2102.11174)明确表明了线性化自注意力和 20 世纪 90 年代的快速权重编程器之间的等价性。
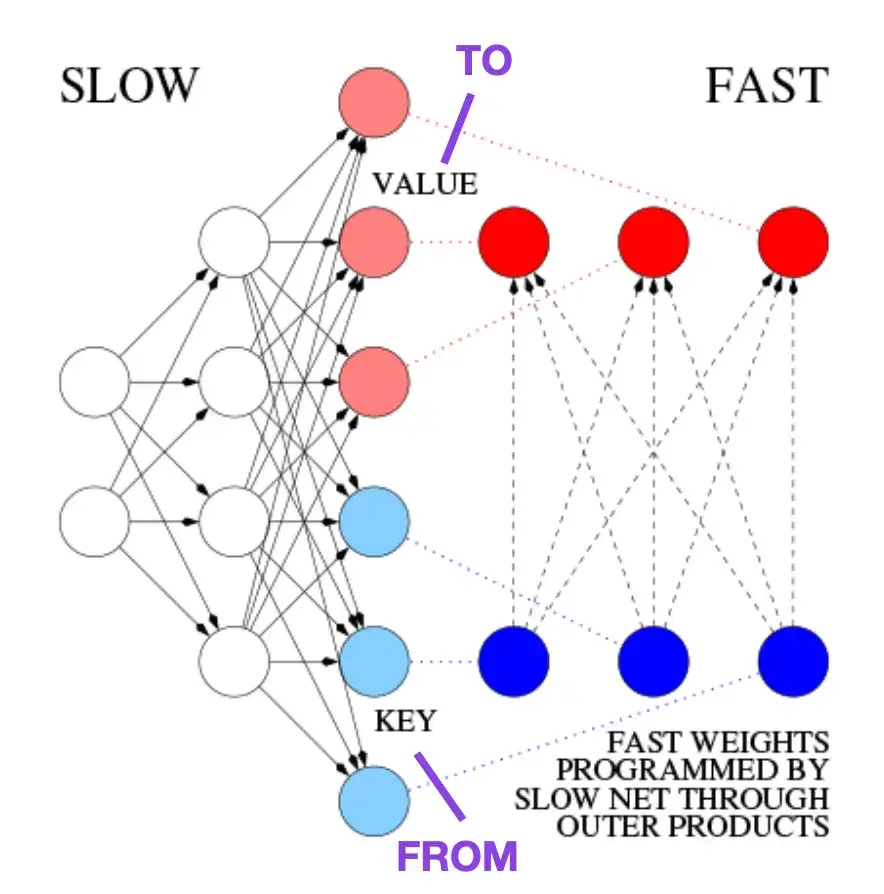
图源:https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2
Universal Language Model Fine-tuning for Text Classification (2018)
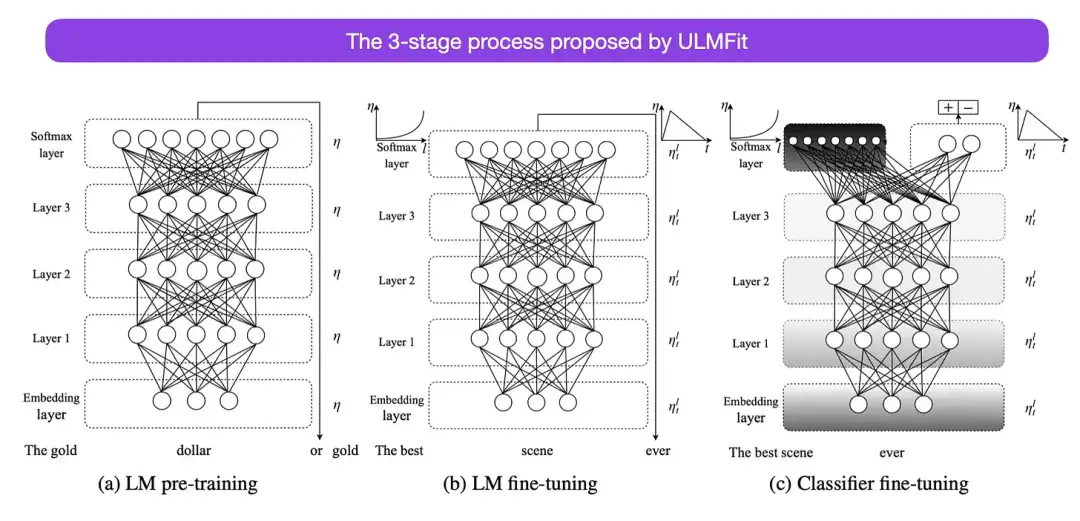
这是另一篇从历史角度来看非常有趣的论文。它是在原版《Attention Is All You Need》发布一年后写的,并没有涉及 transformer,而是专注于循环神经网络,但它仍然值得关注。因为它有效地提出了预训练语言模型和迁移学习的下游任务。虽然迁移学习已经在计算机视觉中确立,但在自然语言处理 (NLP) 领域还没有普及。ULMFit(https://arxiv.org/abs/1801.06146)是首批表明预训练语言模型在特定任务上对其进行微调后,可以在许多 NLP 任务中产生 SOTA 结果的论文之一。
ULMFit 建议的语言模型微调过程分为三个阶段:
- 1. 在大量的文本语料库上训练语言模型;
- 2. 根据任务特定的数据对预训练的语言模型进行微调,使其能够适应文本的特定风格和词汇;
- 3. 微调特定任务数据上的分类器,通过逐步解冻各层来避免灾难性遗忘。
在大型语料库上训练语言模型,然后在下游任务上对其进行微调的这种方法,是基于 Transformer 的模型和基础模型 (如 BERT、GPT-2/3/4、RoBERTa 等) 使用的核心方法。
然而,作为 ULMFiT 的关键部分,逐步解冻通常在实践中不进行,因为 Transformer 架构通常一次性对所有层进行微调。
Gopher 是一篇特别好的论文(https://arxiv.org/abs/2112.11446),包括大量的分析来理解 LLM 训练。研究人员在 3000 亿个 token 上训练了一个 80 层的 2800 亿参数模型。其中包括一些有趣的架构修改,比如使用 RMSNorm (均方根归一化) 而不是 LayerNorm (层归一化)。LayerNorm 和 RMSNorm 都优于 BatchNorm,因为它们不局限于批处理大小,也不需要同步,这在批大小较小的分布式设置中是一个优势。RMSNorm 通常被认为在更深的体系架构中会稳定训练。
除了上面这些有趣的花絮之外,本文的主要重点是分析不同规模下的任务性能分析。对 152 个不同任务的评估显示,增加模型大小对理解、事实核查和识别有毒语言等任务最有利,而架构扩展对与逻辑和数学推理相关的任务从益处不大。
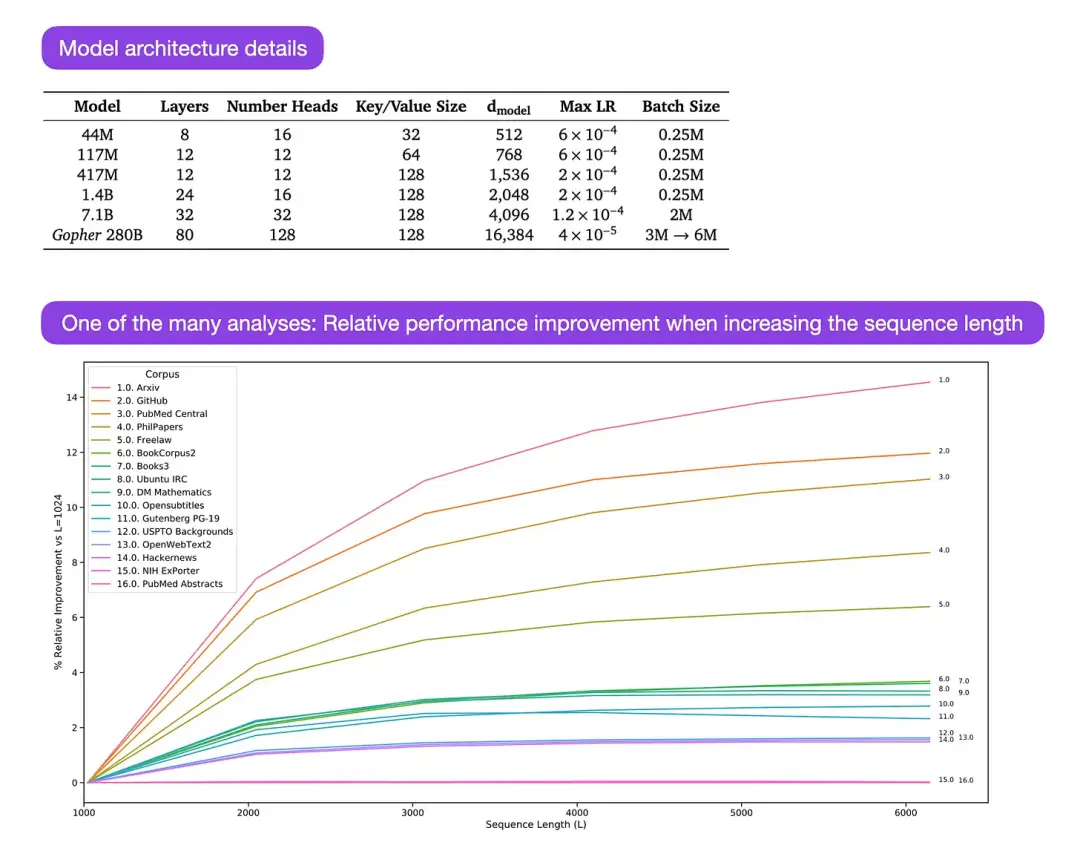
图注:图源 https://arxiv.org/abs/2112.11446
原文链接:https://magazine.sebastianraschka.com/p/why-the-original-transformer-figure
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
ICLR 2023 | RevCol:可逆的多 column 网络,大模型架构设计新范式
CVPR 2023 | 即插即用的注意力模块 HAT: 激活更多有用的像素助力low-level任务显著涨点!
ICML 2023 | 轻量级视觉Transformer (ViT) 的预训练实践手册
CVPR 2023 | 神经网络超体?新国立LV lab提出全新网络克隆技术
即插即用系列 | 高效多尺度注意力模块EMA成为YOLOv5改进的小帮手
即插即用系列 | Meta 新作 MMViT: 基于交叉注意力机制的多尺度和多视角编码神经网络架构
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
6G显存玩转130亿参数大模型,仅需13行命令,RTX2060用户发来贺电
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary