作业①:
1)、要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内容。
▪ 使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
题目1链接:题目1
代码如下:
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import sqlite3
class Database:
def create_table(self):
self.conn = sqlite3.connect("stock.db")
self.cursor = self.conn.cursor()
try:
self.cursor.execute('''
CREATE TABLE stock (
s1 TEXT,
s2 TEXT,
s3 TEXT,
s4 TEXT,
s5 TEXT,
s6 TEXT,
s7 TEXT,
s8 TEXT,
s9 TEXT,
s10 TEXT,
s11 TEXT,
s12 TEXT,
s13 TEXT
);
''')
except:
self.cursor.execute("delete from stock")
def insert_data(self,s1,s2,s3,s4,s5,s6,s7,s8,s9,s10,s11,s12,s13):
self.cursor.execute("insert into stock (s1,s2,s3,s4,s5,s6,s7,s8,s9,s10,s11,s12,s13) values (?,?,?,?,?,?,?,?,?,?,?,?,?)",
(s1,s2,s3,s4,s5,s6,s7,s8,s9,s10,s11,s12,s13))
def show(self):
self.cursor.execute("select * from stock")
rows = self.cursor.fetchall()
print("{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}".format("序号", "股票代码", "股票名称","最新报价","涨跌幅","跌涨额","成交量","成交额","振幅","最高","最低","今开","昨收"))
for row in rows:
print("{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}".format(row[0],row[1],row[2],row[3],row[4],row[5],row[6],row[7],row[8],row[9],row[10],row[11],row[12]))
def close(self):
self.conn.commit()
self.conn.close()
def get():
time.sleep(1)
s1 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[1]")
s2 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[2]/a")
s3 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[3]/a")
s4 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[5]/span")
s5 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[6]/span")
s6 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[7]/span")
s7 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[8]")
s8 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[9]")
s9 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[10]")
s10 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[11]/span")
s11 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[12]/span")
s12 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[13]/span")
s13 = driver.find_elements(By.XPATH, "/html/body/div[1]/div[2]/div[2]/div[5]/div/table/tbody/tr/td[14]")
for i in range(len(s1)):
db.insert_data(s1[i].text, s2[i].text, s3[i].text, s4[i].text, s5[i].text, s6[i].text, s7[i].text, s8[i].text,s9[i].text, s10[i].text, s11[i].text, s12[i].text, s13[i].text)
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
driver.get(url)
db = Database()
db.create_table()
get()
driver.find_element(By.XPATH,"/html/body/div[1]/div[2]/div[2]/div[3]/ul/li[2]/a").click()
db.insert_data("","","","","","","","","","","","","")
get()
driver.find_element(By.XPATH,"/html/body/div[1]/div[2]/div[2]/div[3]/ul/li[3]/a").click()
db.insert_data("","","","","","","","","","","","","")
get()
db.show()
db.close()
运行结果如下:
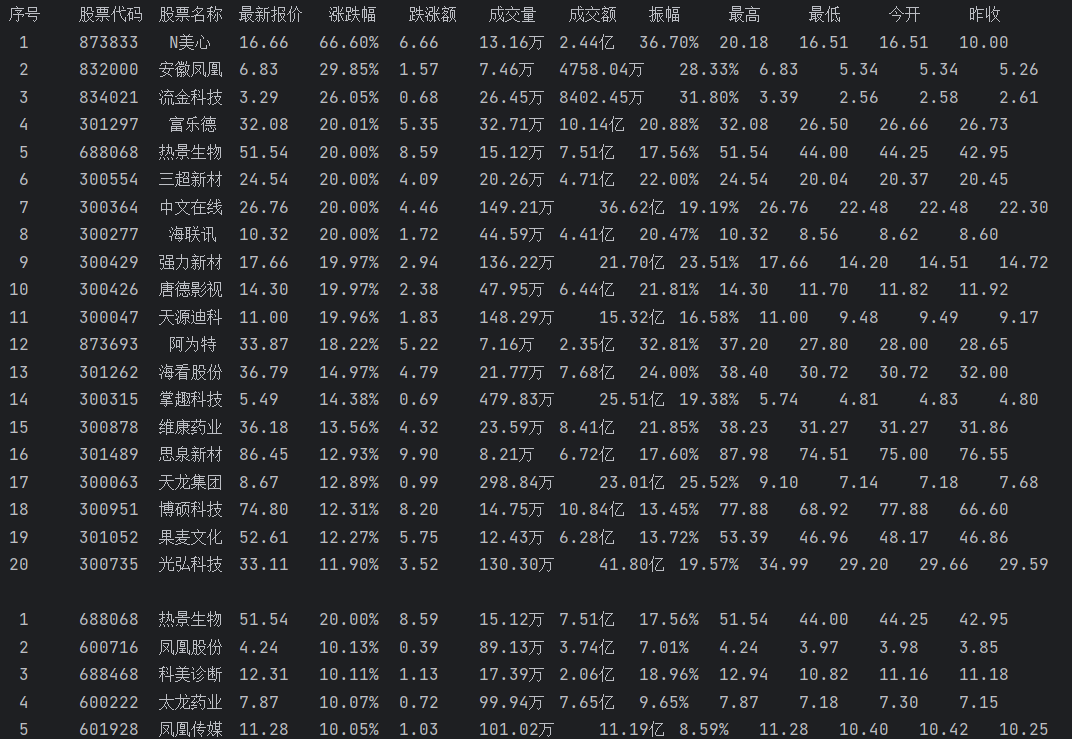
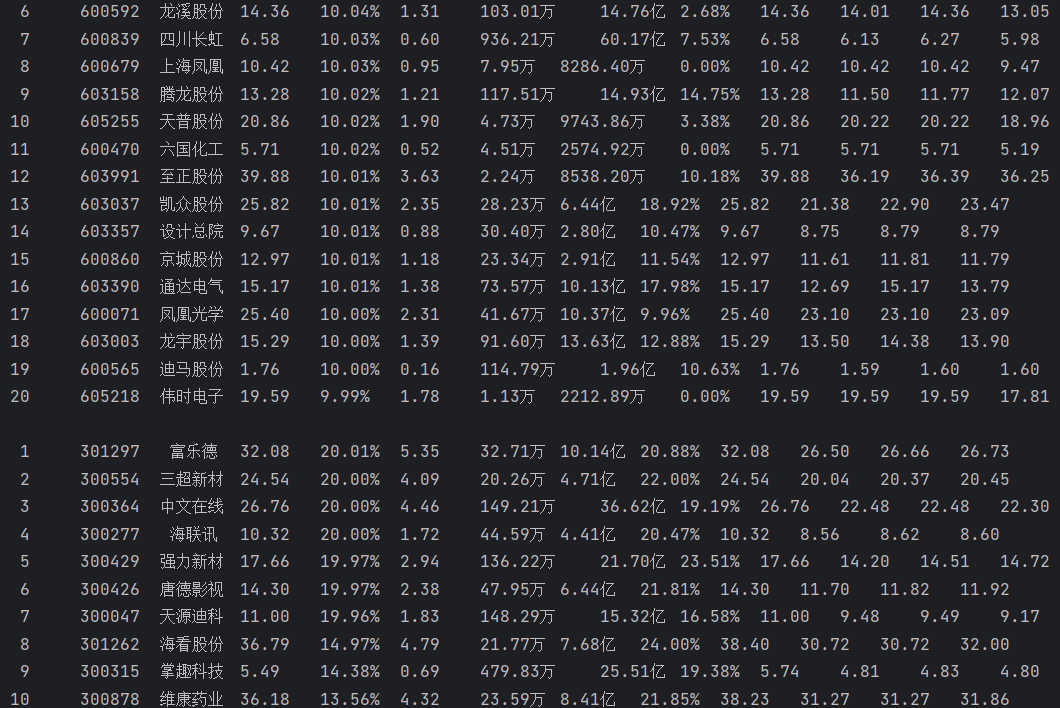
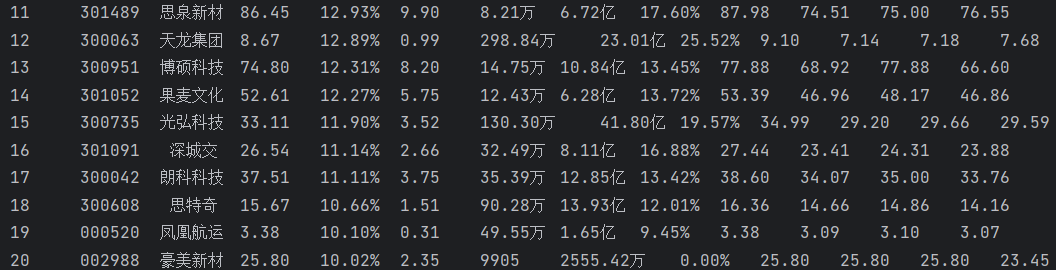
2)、心得体会
通过本题我掌握了如何使用Selenium爬取股票数据信息,对Selenium框架有了一定的了解。
作业②:
1)、要求:
▪ 熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、等待 HTML 元素等内容。
▪ 使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
题目2链接:题目2
代码如下:
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
import sqlite3
class Database:
def create_table(self):
self.conn = sqlite3.connect("course.db")
self.cursor = self.conn.cursor()
try:
self.cursor.execute('''
CREATE TABLE course (
num TEXT,
s1 TEXT,
s2 TEXT,
s3 TEXT,
s4 TEXT,
s5 TEXT,
s6 TEXT,
s7 TEXT
);
''')
except:
self.cursor.execute("delete from course")
def insert_data(self,num,s1,s2,s3,s4,s5,s6,s7):
self.cursor.execute("insert into course (num,s1,s2,s3,s4,s5,s6,s7) values (?,?,?,?,?,?,?,?)",
(num,s1,s2,s3,s4,s5,s6,s7))
def show(self):
self.cursor.execute("select * from course")
rows = self.cursor.fetchall()
print("{:^5}\t{:^15}\t{:^15}\t{:^15}\t{:^15}\t{:^15}\t{:^15}\t{:^15}".format("Id", "cCourse", "cCollege","cTeacher","cTeam","cCount","cProcess","cBrief"))
for row in rows:
print("{:^5}\t{:^15}\t{:^15}\t{:^15}\t{:^15}\t{:^15}\t{:^15}\t{:^15}".format(row[0],row[1],row[2],row[3],row[4],row[5],row[6],row[7]))
def close(self):
self.conn.commit()
self.conn.close()
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)
driver.maximize_window()
url = "https://www.icourse163.org"
driver.get(url)
driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[1]/div/div/div[1]/div[3]/div[3]/div").click()
time.sleep(1)
window = driver.find_element(By.XPATH,"/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe")
driver.switch_to.frame(window)
time.sleep(5)
driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input").send_keys("")
driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]").send_keys("")
driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a").click()
driver.switch_to.default_content()
time.sleep(10)
driver.find_element(By.XPATH,"/html/body/div[4]/div[3]/div[3]/button[1]").click()
time.sleep(1)
driver.execute_script("window.scrollTo(0,2560)")
time.sleep(1)
window = driver.current_window_handle
courses = driver.find_elements(By.XPATH,"/html/body/div[4]/div[2]/div[1]/div/div/div[8]/div[2]/div/div")
db = Database()
db.create_table()
for i in range(len(courses)):
time.sleep(1)
num = i+1
s1 = driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[1]/div/div/div[8]/div[2]/div["+str(i+1)+"]/div/div[3]/div[1]/h3").text
s2 = driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[1]/div/div/div[8]/div[2]/div["+str(i+1)+"]/div/div[3]/div[1]/p").text
s3 = driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[1]/div/div/div[8]/div[2]/div["+str(i+1)+"]/div/div[3]/div[1]/div").text
s4 = driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[1]/div/div/div[8]/div[2]/div["+str(i+1)+"]/div/div[3]/div[2]/span").text
course = courses[i]
course.click()
windows = driver.window_handles
driver.switch_to.window(windows[-1])
time.sleep(1)
s5 = driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[1]/div/div[3]/div/div[2]/div/div[1]/div/div/span[2]").text
s6 = driver.find_element(By.XPATH,"/html/body/div[4]/div[2]/div[2]/div[2]/div[1]/div[1]/div[2]/div[2]/div[1]").text
s7 = driver.find_elements(By.XPATH,"/html/body/div[4]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/div/div[2]/div/div//h3")
list = []
for j in s7:
list.append(j.text)
s7 = ",".join(list)
db.insert_data(num,s1,s2,s3,s7,s4,s5,s6)
driver.close()
driver.switch_to.window(window)
db.show()
运行结果如下:
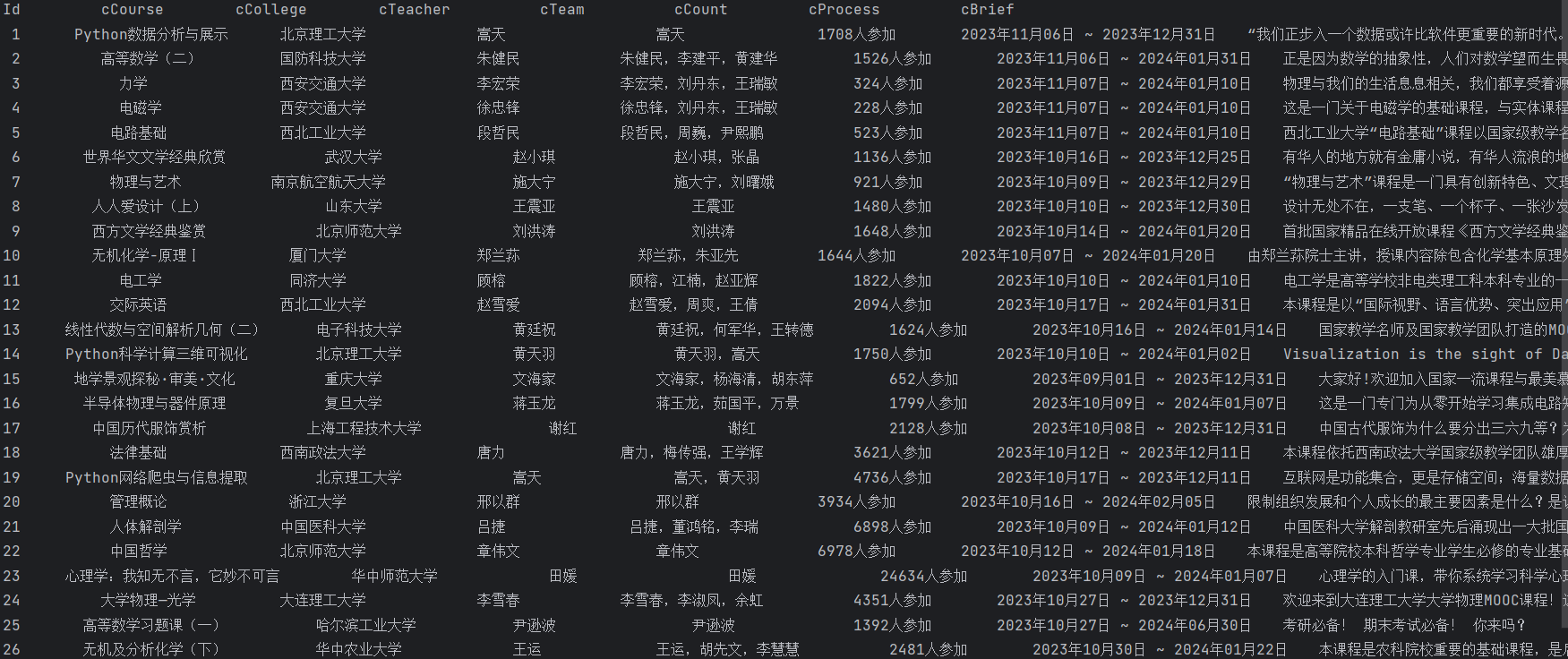
2)、心得体会
通过本题我对Selenium的使用更加熟练,并且掌握了实现用户模拟登录的方法。
作业③:
1)、要求:
• 掌握大数据相关服务,熟悉 Xshell 的使用
• 完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
• 环境搭建:
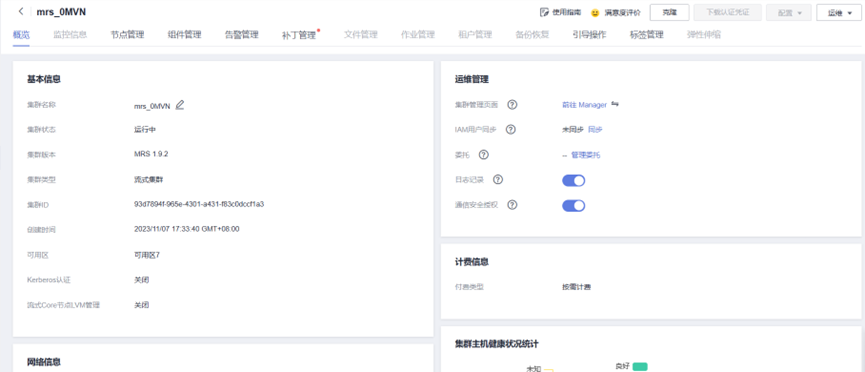
·任务一:开通 MapReduce 服务
• 实时分析开发实战:
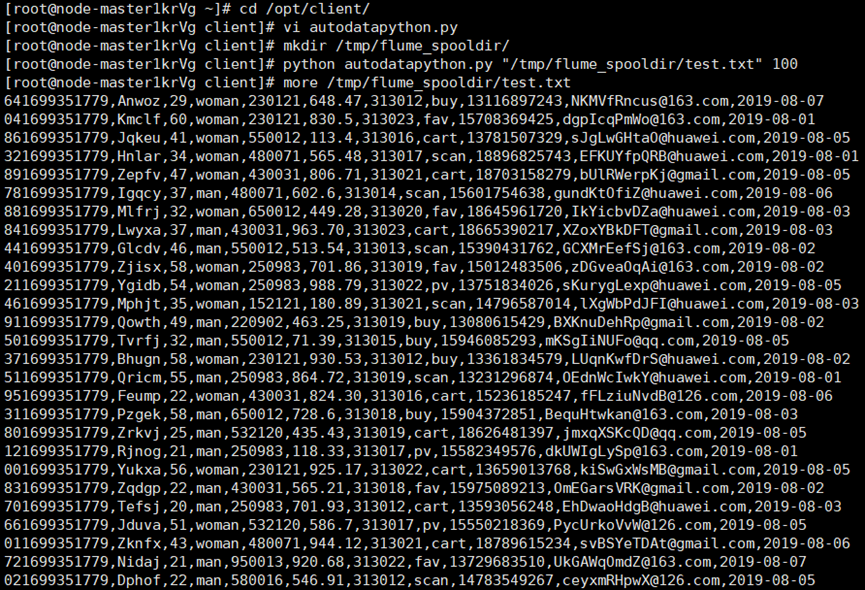
·任务一:Python 脚本生成测试数据
·任务二:配置 Kafka

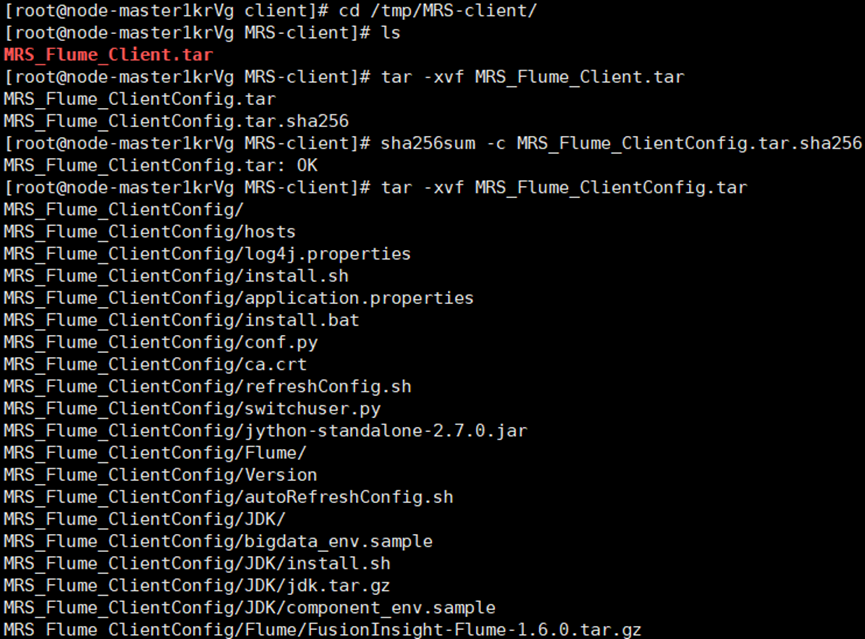
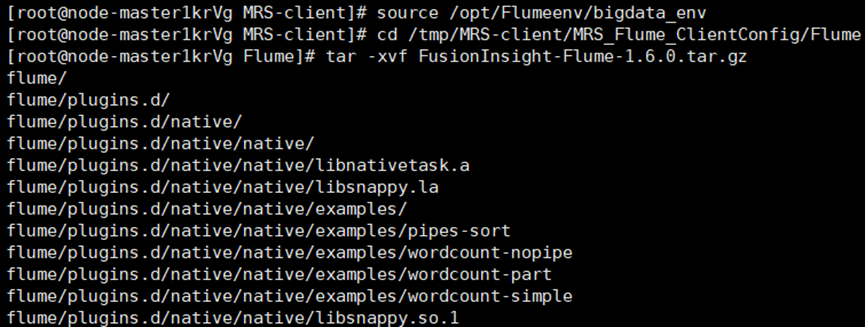
·任务三: 安装 Flume 客户端



·任务四:配置 Flume 采集数据

2)、心得体会
通过本题我在华为云中开通了MapReduce服务并且完成了题目所要求完成的任务。