在上一篇 LLM 应用开发全栈指南[1] 中,我们介绍了 FSDL 的新课程 LLM Bootcamp 中的内容。本周他们又把几个 guest talk 的录像放了出来,看了下也挺有收获,在这里做个补遗。
How to train your own LLM
首先是来自 Replit 的 Shabani 介绍他们自己训练一个代码生成的大语言模型的经验,非常有信息量,可以结合 WandB 的 How to Train LLMs from Scratch[2] 来一起看。
技术栈
Replit 用到的训练技术栈主要包括:
-
Databricks,用于做各种数据处理与分析,也是整个 stack 中最复杂最重要的一部分。 -
HuggingFace,用于获取数据集,模型,tokenizer,inference 工具等。AI 时代的 GitHub,也是人人必备了。 -
MosaicML[3],提供模型训练的基础设施,除了 GPU 这类硬件资源外,也能自动帮你做分布式训练,各种训练加速,并提供训练 LLM 的典型参数配置等,非常容易上手。
整体的架构图如下图所示:
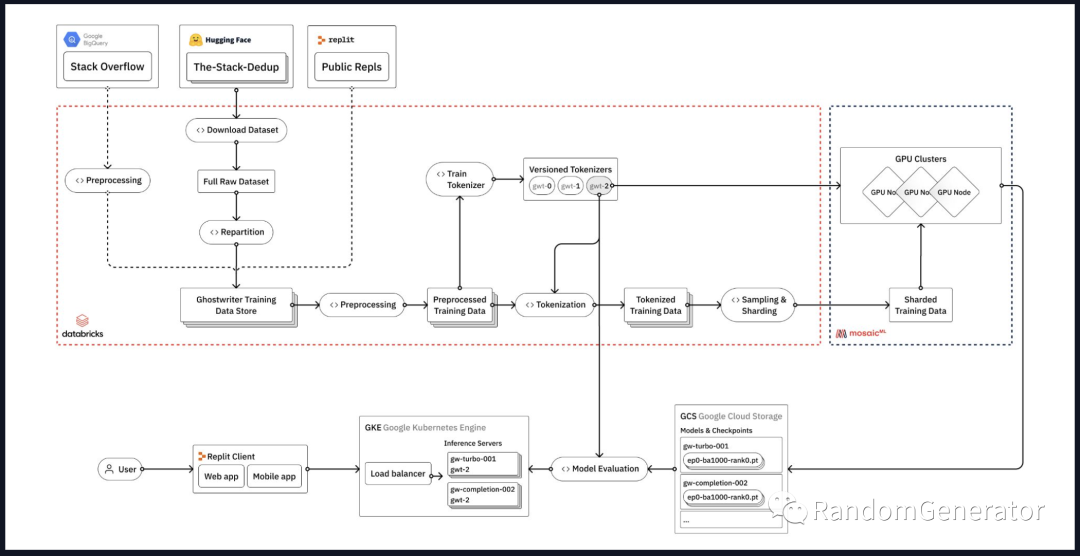
数据集
他们因为是训练代码生成模型,所以训练数据集主要是跟代码相关的内容,包括 StackOverflow 中的问答,来自 BigCode 的 The-Stack-Dedup[4] 数据集,以及 Replit 自己的一些公开 repo。现在大家应该也都知道了,训练一个高质量大模型的主要秘诀都集中在数据清洗上,从这个分享中也可以学到很多他们的一些具体做法,例如:
-
通过一些正则表达式和人工规则判断并移除自动生成的代码。 -
将一些敏感信息移除,如邮箱,IP 地址,各种密码密钥等。 -
移除没法编译通过的代码,不过只能在部分语言做这个操作(例如 Python 就比较好做一些),而且还挺耗时的。 -
通过平均行长度,最大行长度,字母和数字类型的字符数占比等指标来进行一些过滤。比如典型的应该过滤掉一些 minified 或者混淆过的代码。 -
还可以通过 issue 数,star 数等指标来过滤一些质量不高的 repo。
由于数据量非常大(原始代码数据这块就有 3TB 左右),加上处理和分析工作非常多,所以他们使用了 Databricks 作为框架来处理,有更好的 scalability 和性能,也能引入很多其它数据源,而不仅限于 HuggingFace 上的数据集。
Tokenizer
因为是代码生成任务,所以通用的 tokenizer 可能表现并不好或者性能不佳。很多在回答问题,日常交流或者写文章时用的 token 可能很少在 coding 中用到,所以他们也是自己根据代码数据使用 SentencePiece[5] 自己训练了一个 BPE tokenizer 词表出来。这个 tokenizer 后续会在训练和 inference 中使用,提升训练推理效率,也能增加模型捕捉到的信息量。
模型训练
训练部分看起来相对比较简单,一方面可能是用了比较成熟的云服务,另一方面也是模型参数量差不多在 30 亿以内,好像并没有提到训练过程中 babysitting 的问题。简单的 yaml 配置通过 CLI 触发就跑起来了。MosiacML 帮你精心挑选了合适的参数,各种自动重启等,非常省心(虽然我没用过)。作者也表示他们之前都是自己搞,后来切换到 MosiacML 提升了很多效率。
同时他们也用了 WandB 来做训练的 logging 和监控,也是非常标准的做法。
测试与评估
前面也提到大模型的测试评估是个很困难的事情。因为是代码相关任务,感觉可以评估的手段会更丰富一些。比如可以实际执行代码来查看结果是否正确,或者通过一些代码分析工具来评估生成的代码的质量等。
他们使用的评估数据集主要是 HumanEval[6],使用 HuggingFace 的 code inference tool 来快速执行测试。像 Python 这类相对比较好搞定,但对于其它语言和场景,例如一些前端界面的代码就不是很容易做测试验证。
另外也需要注意测试用例最好是模型训练时没有见过的,避免 overfitting/memorization。还有很重要的一点是这些用例要与真实的使用场景尽可能一致,比如是不是跟补全场景是类似的输入和输出形式,测试用例与真实用户的使用场景是否一致等。
部署
他们使用了 FastTransformer[7] 和 Triton[8] 来做 inference 的部署,以提供更好的性能和吞吐。例如像 Triton 中支持部署多个模型 instance 的部署和并发执行,能够做请求动态 batching 等,看起来非常的方便。不过之前也听说当前训练框架跟 inference 框架还是有一些“隔阂”,如果在训练中用了一些特殊的操作,可能在 inference 框架中不一定支持,需要格外注意。
在 auto-scaling 方面,他们复用了 Replit 现有的 k8s 基础设施。不过还是有很多特殊的挑战,例如模型的规模要大很多,对 GPU 也有特殊的要求,还要处理一些云上的区域出现 GPU“缺货”的问题等。
经验教训
最最重要的还是“以数据为中心”,从前面架构图也可以看出,数据 pipeline 这块所占的内容也是最多的,需要有一个稳定的流程来支持快速迭代实验。另外过程中要尽可能深入去了解你的训练数据。看来 80%时间花在数据上仍然是个不变的真理。
模型评估也是一个开放性的问题,作者认为目前更多是一门艺术而不是精确的科学。即使有 HumanEval 这样的评测数据集,也只是一种参考,还是需要真正把模型部署到实际使用场景中,让最终用户来测试体验模型的效果、延迟等,并尽可能全面地收集用户反馈、系统监控数据。这一点 GitHub Copilot 的 telemetry 就做得很好,值得参考学习。
协作也是很重要的一点,像之前 OpenAI 也分享过他们的团队设置,不光是个软件系统工程,也是对组织设计的考验。作者举例说一些新的模型训练特性可能在 FastTransformer 中不支持,就会大大提升 inference 的延迟,所以需要各个团队中的同事一起协同来避免此类问题。
招聘环节
最后作者还聊了聊什么才是一个好的 LLM 工程师,感觉也是个各种交叉技能的“稀有物种”。既要懂 research,engineering 的 sense 也不能差;数据探索清洗要深入且有耐心,又擅长各种软件工程的实践……大概意思就是我们这里项目有趣,挑战又大,赶紧来一起做一番大事业吧 :)
Agents
LangChain 的创始人 Chase 来聊了聊近期超火的 Agents。这部分提到几个工作正好跟之前我写的 AutoGPT 与 LLM Agent 解析[9] 这篇文章完全重合,这里就简单介绍一下。
概念
Agent 的核心是把 LLM 当作一个“推理引擎”,赋予其各类外部工具以及自身的长期记忆,能够让其自行生成灵活的决策步骤,完成复杂任务。而像 LangChain 里的 Chain 的概念则是由人工来定义一套确定的步骤来让 LLM 执行,更像是把 LLM 当成了一种强大的多任务工具。
典型的 agent 模式如 ReAct 中,一般的逻辑是:
-
由 LLM 选择工具。 -
执行工具后再将输出返回给 LLM。 -
不断重复上述过程,直到达到停止条件(一般也是 LLM 自己决定或者通过一些规则设定)。
挑战
作者列举了当前 agent 的一系列挑战,应该也是深入看过很多 agent 应用得出的结论。
如何让 agent 选择合适的工具
常规的做法是通过指令,工具描述来引导。此外在复杂场景下:
-
当工具多了之后也可以针对工具做 retrieve。 -
可以 retrieve 相关示例来做 few-shot prompt。 -
也可以进一步 fine tune 特定模型,例如之前的 Toolformer。
近期正好有篇来自伯克利和微软的工作 Gorilla[10],正好是结合了 retrieval,fine tune 等几种方法,在 LLaMA 模型的基础上做到了接近 GPT-4 的效果,值得借鉴。
不必要的工具使用
例如用户只是跟模型闲聊时,可能就没必要都使用工具了。除了在 prompt 里进行说明外,Chase 还给了个很有意思的想法,就是把“Human Input”也写成一种工具,让模型来主动发起对人类的提问。具体可以参考 LangChain 文档中的例子[11]。
Agent 返回的格式不稳定
在程序使用工具时,需要 agent 按照特定格式返回内容,以便提取其中的工具操作信息。但 LLM 的随机性导致这部分可能会出现很多不稳定的情况。这里常见的做法是让 LLM 按照 json 这类常见的 schema 来返回,一般稳定性会高一些(相比“Action:”这种)。此外自动修复重试也很实用,可以利用 LangChain 里的 output parsers 来帮助完成。
记住之前的操作,避免重复
如果没有长期记忆,agent 很容易“忘掉”之前做过的操作,导致不停在原地打转或者效率低下。常见的解决办法还是通过 retrieval 结合近期操作记录来克服,例如 AutoGPT 中就用了类似的手段。
处理超长的 observation
有些工具生成的 observation 很长,超出了 context length 的限制,这时候就需要用一些工具从中提取有用信息,或者放到外部存储中再借助 retrieval 来使用。
这里引出很有趣的一点是我们未来在考虑 API 设计时也需要主动拥抱 LLM 的特性。除了有清晰的接口设计和说明,能让 LLM 更好地生成调用动作外,调用结果是否精简也很重要,可以避免上述 observation 过长的问题。
专注于目标
像 AutoGPT 这类尝试中往往任务执行链路很长,agent 很容易做着做着就“迷失了目标”。简单的做法是在 prompt 结尾处再把目标加上,引起 agent 的注意。另外像 BabyAGI,HuggingGPT 这种把 planning 和 execution 分开的做法也是很有用。拆分的比较细的任务往往步骤比较短,也不容易丢失目标。
结果评估
评估 agent 也是比较困难的。除了评估最终结果是否正确外,我们还可以做过程的细化评估,例如:
-
选择的中间步骤是否正确。 -
生成 action 的 input 是否正确。 -
生成的步骤序列是否合理高效。
记忆系统
前面的挑战部分可以看到有很多都是跟 retrieval 相关,而且从 agent 的本质出发,其最大的优势之一也在于能够记住之前的操作,成为一个可以不断自我演进的智能体,或者实现不同用户的个性化应答,而不是固定的逻辑链路。所以 memory 这块的处理显得越来越重要。
Agent 的记忆主要是跟用户的交互和跟工具的交互,当然一些项目中也基于这两类基础信息衍生出了很多复杂操作,例如 LangChain 中类似知识图谱的记忆模式;LlamaIndex 中复杂的外部记忆索引设计;Generative Agents 中的“自我反思”环节等等。
Agent 项目速评
-
AutoGPT:实现的任务比起 ReAct 中的例子来说会更发散更需要探索,因此步骤也更长。所以需要通过外部记忆系统来获取 agent 之前的操作步骤信息等。 -
BabyAGI:将计划和执行分开,在较长任务执行过程中保持 agent 的目标感。 -
Camel:给多个 agent 赋予不同的人格、记忆等,模拟 agent 之间的交互。 -
Generative Agents:更复杂的 memory retrieval 机制。自我反思并更新系统状态。或许未来还可以自己触发 fine tune 更新模型参数?
Fireside Chat with OpenAI VP Product
跟 Peter Welinder 的一个简短访谈。很多信息可能关注 OpenAI 的同学应该都比较了解了,例如他们早年在强化学习方面的探索,包括打游戏,玩魔方之类,后来大力押注了语言模型方向。从产品角度有几个故事还挺有意思:
-
他们在有了 GPT-3 之后也不知道有什么产品场景可以应用,一般来说拿着技术找场景并不是一个好主意,但对一家以 AGI 为目标的研究型公司来说也可以理解。后来他们干脆就开放 API,看看用户是不是能自己找到一些有趣的应用场景来。 -
在 GPT-3 推出时他们就想过做个 Chatbot 推出来,但鉴于之前微软,谷歌等公司的失败尝试,他们觉得技术还不成熟就没有这么做。 -
推出 ChatGPT 之前大家也很忐忑,不少人觉得也会跟以往的产品一样被发现一些严重的回复问题导致很快下线。而且他们当时找了 1000 来个用户内测,也没收到特别正面的反馈。但上线之后一方面模型表现的确可以,另外大家可能迅速挖掘出了很多实用场景,导致很快爆火全球。 -
ChatGPT 的成功中是交互方式起到的因素更大还是模型因素更大?其实他们在之前开放 API 时就发现有很多人会在 playground 模拟交互来实现一些场景,聊天这个形式加上免费注册开放大大降低了大家的尝试门槛,所以起到了至关重要的作用。当然 instruct tuning,RLHF 对齐这些也是很重要的保障。
近期工作 highlight
最近还有不少激动人心的优秀工作,也一并在这里分享一下。
Gorilla
前面讲 agent 的环节已经提到了这个工作,相比之前的 Toolformer,一大进步是 开源了代码[12],不过目前(2023.05.28)还没放出比较关键的训练这块的内容。Gorilla 主要实现的是可以通过用户提供的 API 文档,自己 fine tune 出一个模型,然后可以接受用户的任务指令,由这个模型生成一系列 API 调用代码实现任务。看了下论文,具体的做法是:

-
通过 API 文档,向 GPT-4 提问,让它针对每个 API 生成若干个任务指令来,而且还要求这些指令里不要显示的提到 API 的名字。这些 self-instruct 生成的指令与 API 调用对就形成了模型 fine tune 的数据集。 -
在 fine tune 过程中,他们也“植入”了 retrieval 的信息,让模型明白后续在使用时可以结合相关文档信息来生成 API 调用的代码。不过他们发现这种增强方式并不一定总是有效,在当前 LlamaIndex 这类 retrieval 表现下很多反而会起到负面作用。 -
在 inference 时,模型可以按需要启用 retrieval。从文中的结果来看,他们测试的几个库不使用 retrieval 的 zero-shot 效果反而更好。当然 retrieval 在 API 文档持续变化的情况下可能会有优势。

总体来说还是非常有意思的一个工作,让 LLM 来写代码真的是一个拥有无限想象力的方向。
Voyager
又是一篇探索 agent 方向的重磅文章。之前我们就介绍过他们团队推出的 MineDojo[13] 项目,当时还以为下一步应该会搞个多模态大模型出来,或者在 LLM 的基础上去更多使用 RL 方式来训练具有“世界知识”,能够做复杂推理玩游戏的 agent。没想到这次发的文章却是“无梯度更新”的路线,而且效果也是非常惊艳,有些出人意料。
这篇工作总体实现的效果是让 GPT 在不需要任何传统 fine tune 更新参数的情况下,通过 in-context learning 的方式逐渐学会各种“技能”,探索 minecraft 这个虚拟世界。这个 agent 的形成玩游戏的动作主要就是“执行代码”,而其自我学习提升过程就是不断地去写代码,执行获取反馈,调试改进,以及 retrieve 之前写的代码。从整体实现效果来看,比之前的各种 agent 方法(ReAct,AutoGPT 等)强多了。更可贵的是项目代码也全公开了,非常值得深入研究学习。
整体的项目结构如下:
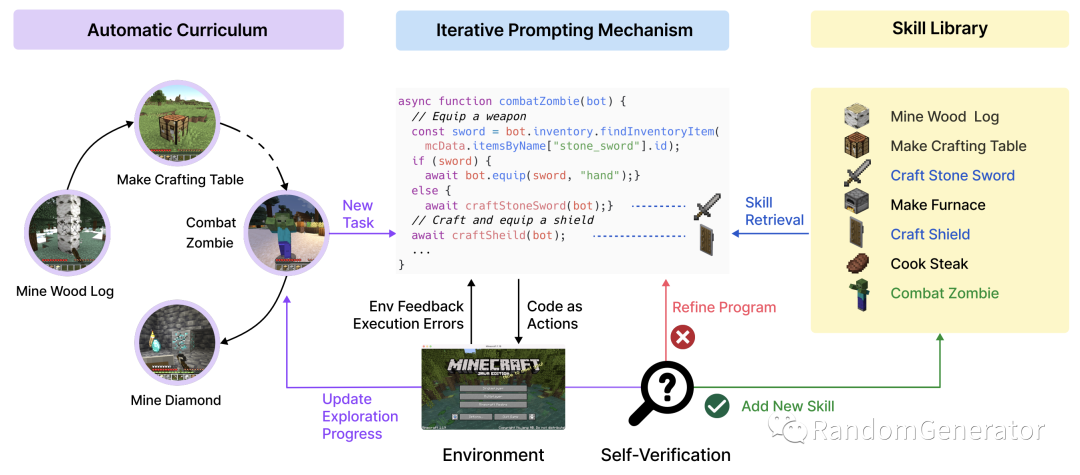
几个模块的作用分别是:
-
中间的 iterative prompting 模块中,agent 会根据游戏环境状态,代码执行报错,当前任务等信息,输出模型的 reasoning,计划和具体的代码,并可以不断 refine 优化达到正确的代码。 -
执行成功的代码程序,会向量化后存到 skill library 中,后续在写代码过程中可以根据 context 来 retrieve。都会写 library 了有没有,离失业又近了一步。 -
最左边的模块也是把当前探索状态发给 agent,并让其以最大化探索空间为目标自己挖掘新的任务目标。我琢磨着让 GPT 做科研是不是也不远了。 -
除了全自动化执行,作者们也在 critic 和 curriculum 两个模块引入了可选的人工介入机制,帮助 agent 更好地处理程序错误,以及引导他们一步步做更复杂的任务。Human as a tool 可能也会成为一种流行模式。
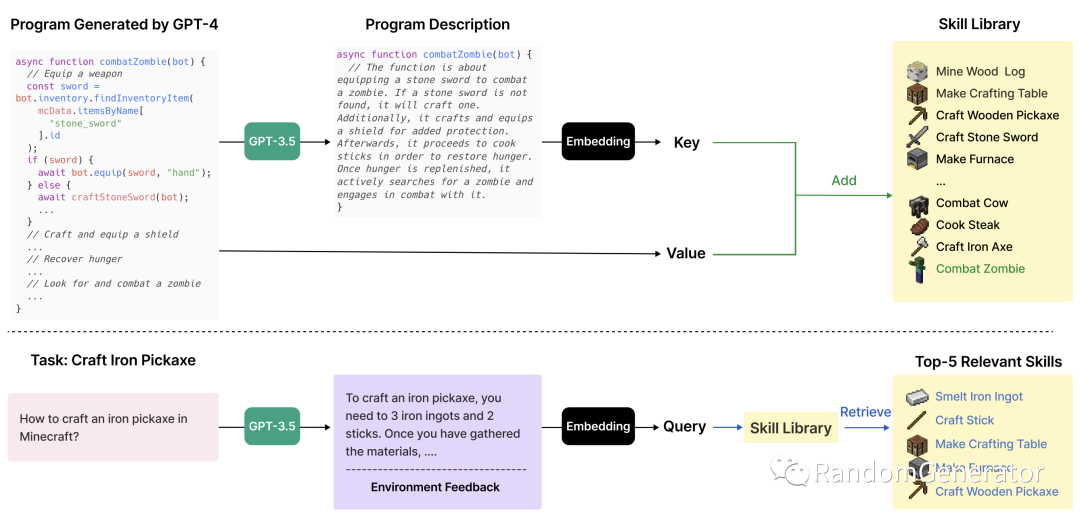
这几个模块结合起来就达到了上面的效果,看起来都没有用 MineDojo 里收集的额外数据,也不用做任何训练,非常神奇。
在 limitation 环节,作者提到了 agent 会出现无法实现正确的代码以及 hallucination 的问题,未来或许能通过 GPT 自身能力的提升或者通过微调开源 LLM 来克服。我的一个感觉是好像整个项目还没有把 minecraft 相关的文档以及其它用户经验分享利用起来,这些知识应该可以减少一些出错和 hallucination 的问题?
还有一个思考是,这类无梯度架构的能力边界会在哪里?有哪些效果是必须通过模型的参数训练更新才能达到的?目前看起来很多 fine tune 提供的优势好像主要是效率角度的提升。例如无梯度架构的模型每次都要从小本本里去翻找相关记忆,但训练过的模型可以直接从参数中找出 context;或者本来要用工具去跑一下代码才知道结果,训练过的模型可以直接给出结果;或者原先的任务做的不熟练,经常做错需要订正,训练过后就能一次做对了。是否有无梯度架构完全做不了的,而一定要用数据训练后才能做到的事情(例如扩展词表)?
不过即使从提升效率,增加准确性的角度来看,这两者也是可以考虑结合起来的。比如 Generative Agents 里就有“自我反思”的步骤来沉淀重要的事件信息。我们是不是也可以延展一下,把“自我反思”改成调用自我 fine tune 的工具。其中的训练数据就可以根据上面提到的无梯度架构的局限性角度出发,将出错最多的代码,retrieve 频率最高的信息,调用最频繁的工具及其结果,人工介入最多的 workflow,以及模型自认为最重要的信息等等,都作为训练数据,来训练一个 fine tune 的模型。这样就可以在无梯度架构的基础上,通过 fine tune 来进一步提升 agent 的进化。
Tree of Thought
ReAct 作者“尧舜禹”大佬的新作,前两天又刷屏了。作者延展了 chain-of-thought 的思路,模拟人类在解决复杂问题时的提出多个可能方向,思考深挖,根据可行性选择路径,碰到问题时回溯到之前其它想法等思维过程,构建起了一棵自主探索生长的“思维树”。在算 24 点等一系列复杂的任务上,tree-of-thought 的表现都大大超过了之前的 chain-of-thought。
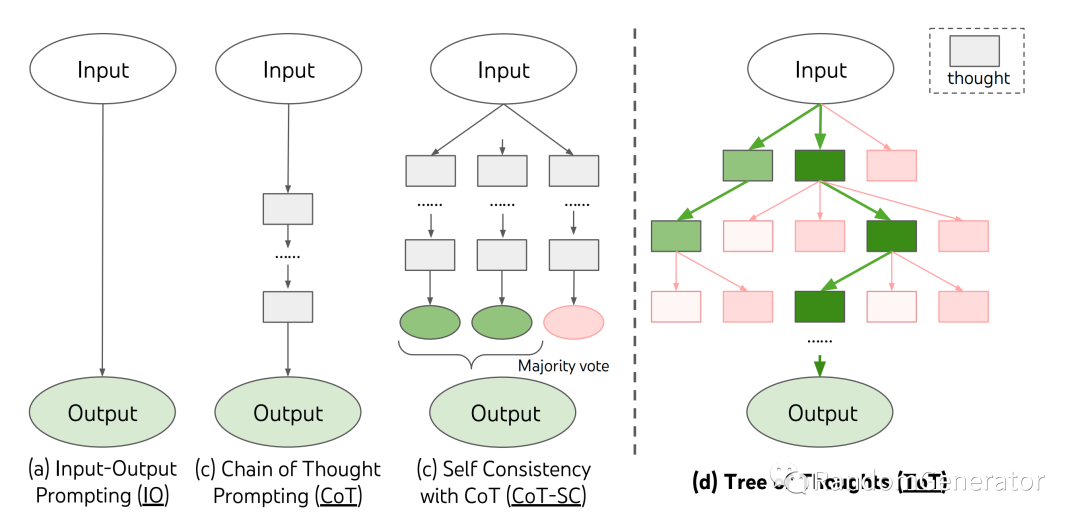
作者也将代码公开在了 GitHub 上,感兴趣的同学可以深入学习研究。个人看下来感觉目前构建 tree 的 proposal/value prompt 需要针对具体任务来设计,需要比较深入的领域知识。不知是否有可能通过更加自动化的方式,结合 LLM 和相关外部工具来自动生成这些 prompt,那样或许会有更广的应用场景。
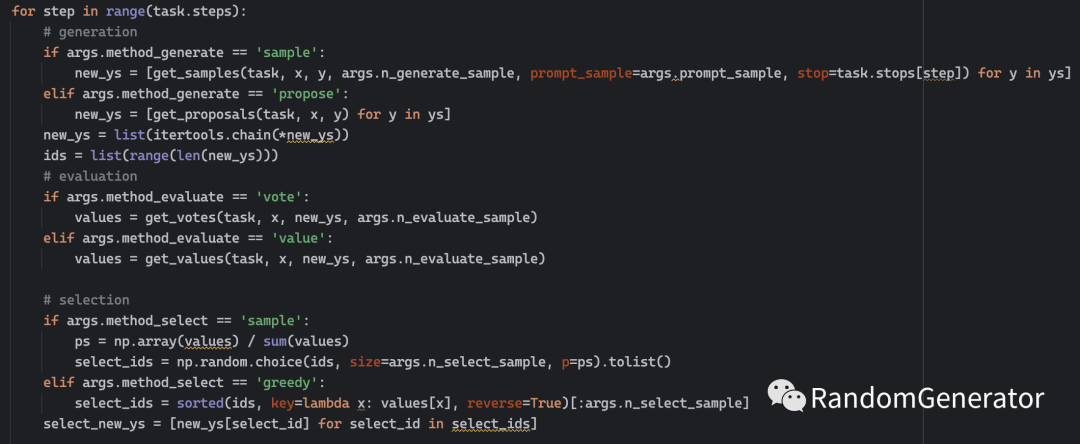
这个工作的设计思路还是挺有趣的,有种把 LLM 作为 CPU,在上面跑了更高级的树搜索算法的感觉。很多经典算法都是这类对人类系统性思考解决某类问题的高度抽象,或许未来会有更多这个方向上的探索,甚至真的把 Prompt 设计成一种编程语言[14]。
Status of GPT
最后再推荐一下推特第一人工智能网红 Karpathy 在微软 Build 大会上的演讲,如果你没怎么跟进 LLM 方面的进展,那么这个演讲绝对是最好的总结视频之一。表述非常清晰易懂,覆盖了各类主要进展,有细节也有 intuition,真是不可多得的佳作。个人感觉收获比较多的几个点包括:
-
为什么需要 RLHF,直观来看就是效果更好。一个可能的原因是要生成一个高质量的文本,比判别一下几个文本质量的好坏要难得多。“我虽然不会写,但点评下别人的作品还是容易的” :) -
模型 fine tune 会损失多样性,这个之前 Karpathy 也在推特上分享过。包括之前的“灾难性遗忘”感觉也没有很好的解决办法。 -
人工生成的文本跟 LLM 生成文本的比较非常精彩,一定要看。人类在产出最终文本前其实涉及了很多中间过程,可能包括问题拆解,资料查阅,反思,撰写,润色等等,而模型没有各种内在的心理活动,它的所有思考过程都需要一个一个 token 显示地生成出来。所以上面看到的很多工作也都是利用 prompting 和模型生成的交互来重建人类的 system 2 思考过程。 -
LLM 只想模仿,不想成功。所以提醒一下模型模仿高智商的思考者很重要,让它记得需要完成的任务目标也很重要。举例:Let's work this out in a step by step way to be sure we have the right answer。 -
提到了微软的 Guidance[15] 项目,实现了 constrained prompting,让模型能够更稳定地按照特定的格式进行输出。 -
Fine tune 方面提到了各种 PEFT 技术[16],这方面最近最火热的应该是这个 QLoRA[17],可以在 48GB 显存上 fine tune 一个 65B 的模型,着实惊人。

参考资料
[1] LLM 应用开发全栈指南: https://zhuanlan.zhihu.com/p/629589593[2] How to Train LLMs from Scratch: https://wandb.ai/site/llm-whitepaper
[3] MosaicML: https://www.mosaicml.com/
[4] The-Stack-Dedup: https://huggingface.co/datasets/bigcode/the-stack-dedup
[5] SentencePiece: https://github.com/google/sentencepiece
[6] HumanEval: https://huggingface.co/datasets/openai_humaneval
[7] FastTransformer: https://github.com/NVIDIA/FasterTransformer
[8] Triton: https://github.com/triton-inference-server/server
[9] AutoGPT 与 LLM Agent 解析: https://zhuanlan.zhihu.com/p/622947810
[10] Gorilla: https://arxiv.org/pdf/2305.15334.pdf
[11] LangChain 文档中的例子: https://python.langchain.com/en/latest/modules/agents/tools/examples/human_tools.html
[12] 开源了代码: https://github.com/ShishirPatil/gorilla
[13] MineDojo: https://minedojo.org/
[14] Prompt 设计成一种编程语言: https://lmql.ai/
[15] Guidance: https://github.com/microsoft/guidance
[16] PEFT 技术: https://github.com/huggingface/peft
[17] QLoRA: https://github.com/artidoro/qlora