最近ChatGPT很火,让更多的人意识到未来利用机器的深度学习来完成事情,做出一些决策,将会成为未来的一个趋势。基于深度学习的数据训练这些技能将成为程序员必备的专业技能之一。所以我们有理由持续的关注深度学习与机器训练这个领域,今天给大家说明白目前主流深度学习的一些基本的流程原理,以及目前深度学习的一些主流的工具。
1:深度学习与数据训练
机器学习指的是 如果一个程序在任务T上,随着处理经验的E增加,效果P也可以随之增加,则称这个程序可以从经验中学习,我们就可以称为机器学习。
传统的机器学习是准备好输入的数据, 人工提取一些有明显标记的特征, 对这些特征加一些权重来预测这个结果。比如条码识别,根据条码的宽度比例特征来识别这个条码代表的数据结果。
深度学习是准备好输入的数据,提取一些最基本的特征, 经过多层复杂的特征提取,然后对最后的特征做一些权重处理,来预测这个结果。这里得多层复杂特征提取,就可以通过部署多层次的神经网络结构来实现,同时通过大量的数据训练,来训练神经网络的参数,从而达到”自动多层提取特征”。参数训练出来以后,只要将输入丢入到神经网络,就可以预测到你想要的结果。深度学习中的深度,就取决于你神经网络的层次与深度。
总结以下,在深度学习的过程中开发者主要要处理的点如下:
(1) 准备好训练数据(原始输入数据与正确结果), 准备好测试数据,最后测试。
(2) 结合问题本身,构建基于多层神经网络的网络结构。
(3) 机器开始大规模的数据训练,基于反向传播算法等来更新神经网络参数(自动多层特征提取)。
(4) 训练结束后测试数据,微调神经网络的结构,反复训练达到生产环境所需的要求。
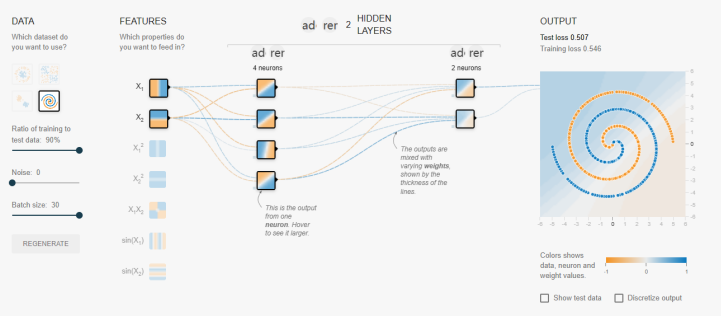
(注:截图来自: http://playground.tensorflow.org, 海外网站,需要梯子)
2 深度学习与深层神经网络主要问题与解决方案
(1)激活函数实现去线性化
很多模型都是线性的,及模型为输出是输入的加权和,如下:
y=a1*X1 + a2*X2 + …an*Xn+常量
而线性模型很难解决非线性的问题,所以引入了激活函数f,
y = f(a1*X1 + a2*X2 + …an*Xn+常量), 这样就把模型变成了非线性的模型。
常用的激活函数有:
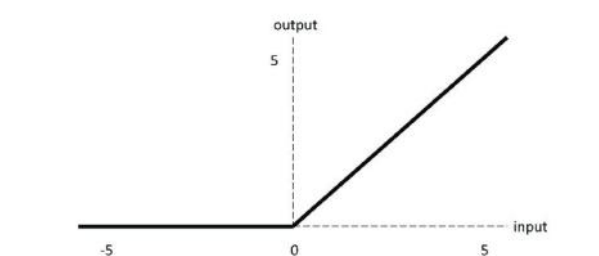
ReLU函数: f(x)=max(x, 0)
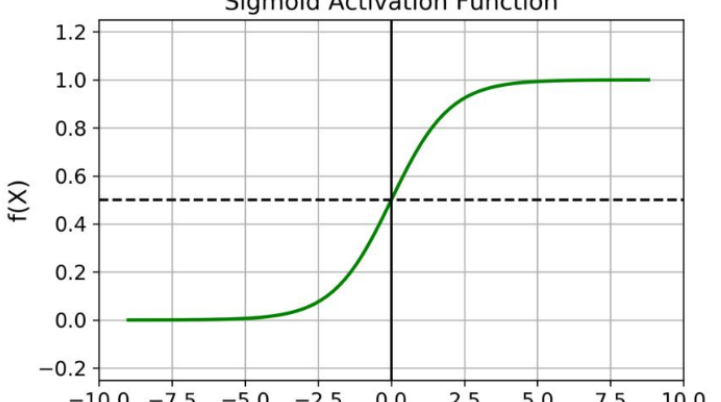
sigmoid函数: f(x)=1/(1+e^(-x))
tanh函数: f(x)=(1-e^(-2x))/(1+e^(-2x))

还有很多其它的激活函数,可以根据问题的模型情况来选择符合问题的函数模型。
(2) 深层神经网络提取更高维度的特征
解决实际问题的时候,我们可以构建多层次的深层神经网络,多层的神经网络,能够从输入的特征中提取更多维度的特征。多层次的深层神经网络有组合特征的功能,这个特性对于不容易提取特征值向量的问题(图像识别,语音识别等)有很大的帮助,所以最近深度学习在图像识别,声音识别上取得了突破性的进展。
(3)损失函数来评定训练结果
神经网络的训练与优化的目标需要来结果进行评定, 而训练结果的好坏评定直接影响了训练的效果。我们需要定义损失函数来判定结果。比如,手写数字识别,我们把一个28x28像素的图片数据要识别成0, 9的数字。我们可以构建一个这样的神经网络,把向量[784个像素的数据维度(28x28=784)], 变成10个数据的维度[a0, a1, a2, a3, a4, a5, a6, a7, a8, a9],然后来做损失判定,看看当前的数据结果与哪个数字的数据向量最接近。
比如数字1对应的标准向量为[0, 1, 0, 0, 0, 0, 0, 0, 0, 0], 我们需要定义一个函数,来描述输出向量与哪个标准的向量更接近。这样就可以预测出输入的图片是对应的哪个数字,这个函数我们叫做损失函数。在深度学习中经典的损失函数的算法是用交叉熵的算法。
比如向量A(0.5, 0.4, 0.1) 向量B(0.8, 0.1, 0.1)与标准向量(1, 0, 0) 哪个跟接近时,我们可以用交叉熵来判定
HA = -(1*log0.5 + 0 * log0.4 + 0*log0.1) = 0.3
HB = -(1*log0.8 + 0 * log0.4 + 0*log0.1) = 0.1
所以向量 0.8, 0.1, 0.1 更接近(1, 0, 0)
我们也可以根据实际的情况自定义损失函数,来让训练到达更符合实际的效果。
(5)动态调整学习率
学习率指的是参数更新的速度与幅度,参数更新的幅度越大,那么可能导致参数在最优解的两侧来回移动,不会得到或接近最优解,学习率幅度过小,更容易接近最优解,但是会提升运算量,降低训练的速度。所以学习率不能过大,也不能过小需要进行动态的调整,所以一般会对学习率做一个衰减, 开始的时候我们可以快速的接近最优解范围,后面我们就会稳定收敛在最优解附近来进行训练,获得很好的效果。
(6)样本噪声带来的过度拟合
有时候由于样本的噪声,本来噪声点是要丢弃的,但是后期训练拟合的时候,把噪声点也拟合进去,产生过度拟合。解决这类问题我们需要在损失函数中加入刻画模型复杂度的指标权重,来解决噪声点对拟合的污染,避免产生过度拟合。

(左图欠拟合, 中图拟合合适,右图过度拟合)
3 主流的深度学习开源工具
深度学习有很多开源的工具可以帮助我们快速的完成神经网络的构建与训练。其中比较著名的有:
TensorFlow(谷歌维护);
Microsoft Cognitive Toolkit(CNTK)(微软维护);
PaddlePaddle(百度维护);
目前大部分深度学习的工具都采用了TensorFlow。比如最近爆火的ChartGPT,就是使用TensorFlow训练出来的。上面提到的神经网络相关的工具完整的实现了,数据读取,神经网络的构建,神经网络的训练,以及在深度学习中要用到的函数的实现,大大的降低了我们自己做AI训练的难度。同时Tensorflow 有一些经典的数据集,帮助我们来快速的学习。深度学习主要的研究领域包含如下:
(1) 计算机视觉与图像识别;
(2) 人类语音的识别
(3) 人类自然语言的处理
(4) 人机对站博弈
对于程序员而言,学会深度学习与机器训练,是未来的必备的技能之一,希望大家后续都关注这块。对于做游戏开发而言,高效的产生数字内容,是未来的一个趋势,产生数字内容的工具,往后很大一部分会被AI取代或AI制作+人为干预的模式。今天的分享就到这里,关注我们学习更多深度学习的知识。