一、理论
1、CAP
- C:一致性:所有节点访问同一份最新的数据副本
- A:可用性:非故障的节点在合理的时间内返回合理的响应,不是错误或者超时的响应
- P:分区容错性:分布式系统在出现网络分区的时候,依然能够对外提供服务
网络分区:分布式系统中,多个节点之间的网络原本是联通的,但是由于某些故障导致某些节点不连通,整个网络分成了几块区域,这就叫网络分区。
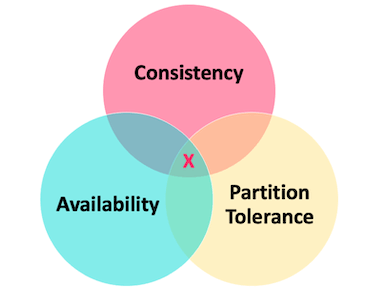
一个分布式系统必须要满足分区容错性,然后在此基础上,只能满足可用性或者一致性。三者不能同时满足,只能满足AP或者CP。
为什么不能有CA架构呢?因为如果系统出现“分区”,系统的某个节点正在进行写操作,为了保证C一致性,必须禁止其他节点的读写操作,这就和可用性A发生冲突了。如果保证可用性A,其他节点的读写正常的话就与一致性C发生冲突了。
如果网络分区正常的话(系统在绝大部分时候所处的状态),也就说不需要保证 P 的时候,C 和 A 能够同时保证。
2、CAP实际案例
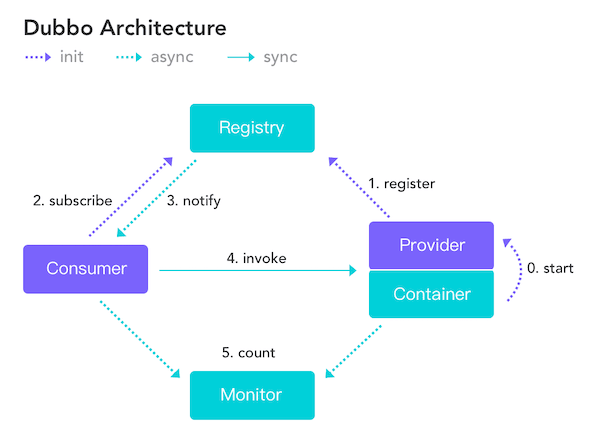
以下是Dubbo(高性能、轻量级的开源RPC框架)架构图,由注册中心、服务提供者、服务消费者、服务运行容器、监控中心五部分组成。
注册中心的作用:负责服务地址的注册与查找,相当于目录服务,服务提供者和服务消费者只在启动的时候与注册中心交互,注册中心不转发请求,压力较小。
常见的可以作为注册中心的组件有:ZooKeeper、Eureka、Nacos...。
zookeeper只满足CP,nacos不仅支持CP也支持AP架构。
- zookeeper采用了 Paxos 算法来实现分布式一致性和分区容错性,但是当leader选举过程中半数以上的节点不可用时,zookeeper服务暂时不可用。
- Nacos 是阿里巴巴开源的服务发现和配置管理平台。Nacos 不仅支持 CP 架构,也支持 AP 架构。在 CP 模式下,Nacos保证强一致性和分区容错性;而在 AP 模式下,Nacos追求高可用性和分区容错性。Nacos提供了服务注册和发现、配置管理、动态配置刷新等功能,被广泛应用于微服务架构中。
3、BASE理论
是对AP方案的补充,AP方案是在系统发生分区的时候放弃一致性,而不是永远放弃一致性,在分区故障恢复后,系统应该达到最终一致性。
1、BA:基本可用:指的是分布式在出现分区故障后允许损失部分可用性。时间以及系统功能的损失。
- 响应时间上的损失: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。
- 系统功能上的损失:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
2、S:软状态:允许分布式系统中的数据存在中间状态,即允许系统在不同节点的数据副本之间进行数据同步的过程中存在延时
3、E:最终一致性:系统中的所有数据副本在经过一段时间的同步后最终能够达到一致的状态。
分布式一致性的 3 种级别:
-
强一致性:系统写入了什么,读出来的就是什么。
-
弱一致性:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
-
最终一致性:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
- 读时修复 : 在读取数据时,检测数据的不一致,进行修复。
- 写时修复 : 在写入数据,检测数据的不一致时,进行修复。
- 异步修复 : 这个是最常用的方式,通过定时对账检测副本数据的一致性,并修复。
3、paxos算法
分布式系统的共识算法,在分布式系统中进行多个节点之间的协调与通信,以达到一致性的目标。
拜占庭将军问题:假设多位拜占庭将军没有叛军,但是信使有可能被暗杀的情况下,将军们如何达成是否要进攻的一致性决定?
在共识算法中,一般会选举出一个或多个节点作为领导者(Leader),领导者负责协调节点之间的通信和决策。常见的共识算法包括 Paxos、Raft、ZAB(ZooKeeper Atomic Broadcast)等。
paxos算法主要包含2部分:
1、basic paxos 算法:描述的是多节点之间如何就提案达成一致
2、multi-paxos算法:执行多个basic paxos算法,就一系列提案达成共识。
3.1 basic paxos 算法
有三个重要的角色:
1、提议者(proposer):负责接收客户端的请求并发起提案
2、接受者(acceptor):负责对提议者的提案进行投票
3、学习者(learner):如果有超过半数的接受者就某个提议达成共识,那么学习者就接受这个提议,并就该提议做出运算,将运算结果返回给客户端。

4、Raft 算法
Raft 是 Multi-Paxos 的一个变种,其简化了 Multi-Paxos 的思想,变得更容易被理解以及工程实现。
4.1节点类型
1、leader:负责发起心跳,响应客户端,创建日志,同步日志
2、candidate:leader选举过程中的临时角色,由follower转化而来,发起投票参与竞选
3、follower:接受leader的心跳和日志同步数据,投票给candidate
在正常的情况下,只有一个服务器是 Leader,剩下的服务器是 Follower。Follower 是被动的,它们不会发送任何请求,只是响应来自 Leader 和 Candidate 的请求。
4.2 任期
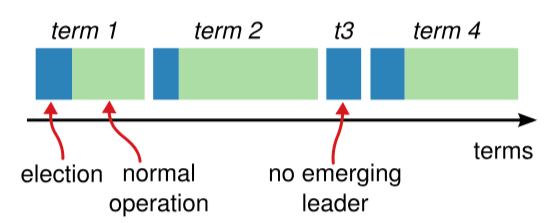
raft 算法将时间划分为任意长度的任期(term),任期用连续的数字表示,看作当前 term 号。每一个任期的开始都是一次选举,在选举开始时,一个或多个 Candidate 会尝试成为 Leader。如果一个 Candidate 赢得了选举,它就会在该任期内担任 Leader。如果没有选出 Leader,将会开启另一个任期,并立刻开始下一次选举。raft 算法保证在给定的一个任期最少要有一个 Leader。
4.3 日志
entry:每一个事件成为 entry,只有 Leader 可以创建 entry。entry 的内容为<term,index,cmd>其中 cmd 是可以应用到状态机的操作。log:由 entry 构成的数组,每一个 entry 都有一个表明自己在 log 中的 index。只有 Leader 才可以改变其他节点的 log。entry 总是先被 Leader 添加到自己的 log 数组中,然后再发起共识请求,获得同意后才会被 Leader 提交给状态机。Follower 只能从 Leader 获取新日志和当前的 commitIndex,然后把对应的 entry 应用到自己的状态机中。